
Server CPUs have gone from the doghouse to becoming ultra-important pieces of infrastructure, and agentic AI is the reason. This is one of those topics that I have been talking about with organizations for months, and I thought I might just put a broader discussion piece. Right now, much of the online discussion is simply on running agents as a new class of workload, and for good reason. It is net new demand on the compute infrastructure. Still, that is at best a part of the equation. On June 3, 2026, Cloudflare CEO Matthew Prince said that AI bot traffic has eclipsed human traffic on the Internet. You can pretend that trend is not real, but it impacts everyone who runs servers, and it is only going to get worse as agentic platforms become part of everyday workflows. Server CPUs are heating up for a reason, and the companies that get ahead now will have a real advantage. Since we have been doing server CPUs for a decade and a half-plus, I figured that I should give folks a broader framework to use.
We have a video for this one. We are going to use AMD EPYC and Dell servers here. AMD sent the CPUs. Dell paid for my travel to Dell Tech World. We have to say this is sponsored. Still, if you read the STH Substack, it is pretty clear why we will be talking a lot about AMD EPYC in the next year and change.
Why Agentic AI is a CPU Story
In the data center, CPUs are everywhere. They sit alongside GPUs to process data and attach extra memory pools to those accelerators. They run storage nodes, control planes, Kubernetes workloads, network switches, and even some network adapters. Whenever you build a cluster, CPUs are the common denominator.

Agentic AI changes how those CPUs get used. Platforms like OpenClaw, Hermes, and similar agent frameworks do not run on GPUs. These agent frameworks run on CPUs, and they need to stay alive and responsive so they can react whenever something happens. OpenClaw makes that straightforward to set up currently with just:
curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard --install-daemon
Then you are off and ready to go.
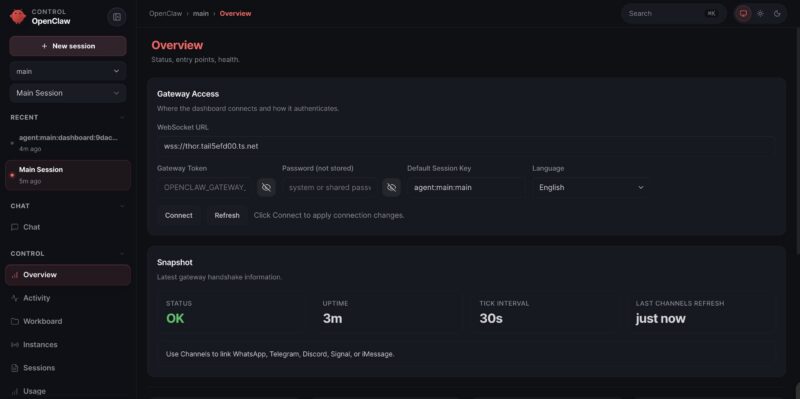
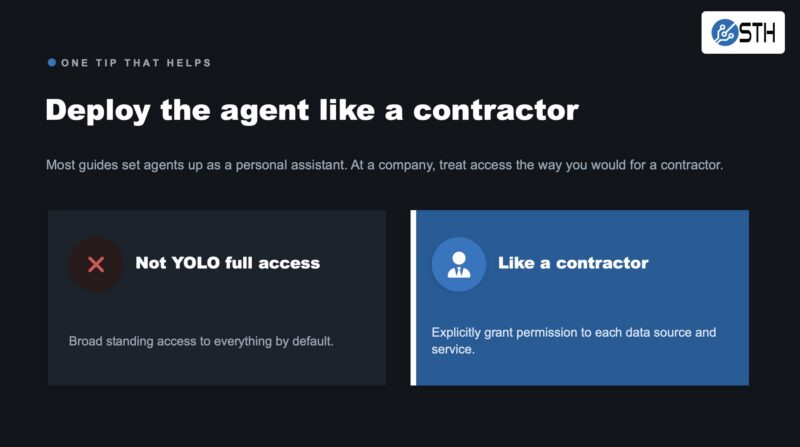
From there, you add security layers and manage access. For company deployments, most guides online cover setting up OpenClaw as a personal assistant. When you deploy at a company, think about it more like bringing on a contractor. Grant constrained access to data and services, not open all access privileges. The “let Hermes or OpenClaw have access to everything” is what I have been calling a YOLO AI agent.
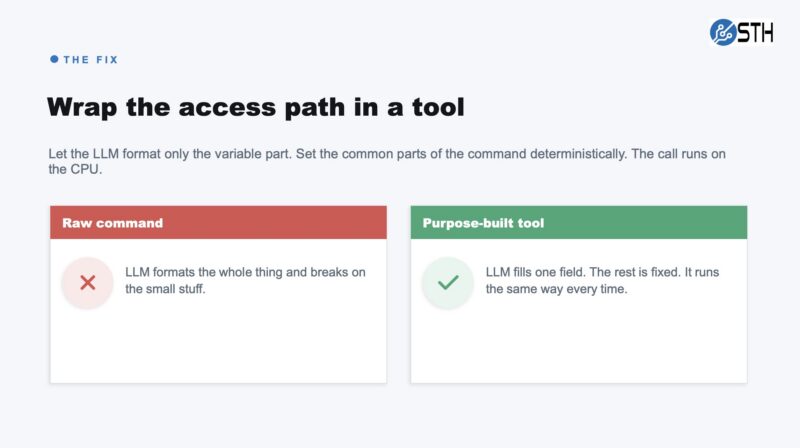
LLM inference usually runs over APIs to GPUs. CPU-side infrastructure handles everything else. If you want deterministic, reproducible results, ask the LLM to generate scripts that run tasks deterministically on the CPU rather than relying on raw LLM output to execute commands directly.
Here is a practical example. Set up a VM with a password-authenticated SSH user that has sudo access, then feed that to an LLM. Make 100 calls through that workflow, and even powerful models like GPT-5.5, Qwen3.5-397B, Fable-5 (if we get access again), and Opus-4.8 will error out on a significant number of calls due to missing or malformed quotations. We ran experiments on this. It used to be around 40 percent of initial calls that failed. With newer models, we still see 25 percent of workflows looping to fix broken SSH commands from simple formatting errors. Those errors burn tokens even when the agent is fixing them without user intervention.
Building a tool for that specific access path fixes much of the problem. The LLM formats the call, while the common parts of the SSH command get handled deterministically by the tool. That call runs on the CPU, and the agent stays on track. Most folks who have worked with agents are accustomed to this. New users generally have no idea. Many folks in the middle may see it and not realize how much it costs in terms of token usage and time, even if the agent realizes its mistake and quickly fixes the issue.
There are different ways to call and host tools, and many people have deployed agentic AI on smaller bare metal machines or cloud VPS instances. We are now seeing short-lived sandboxes being built, issuing commands, and torn down. The key factors that determine how well your agents perform have nothing to do with the LLM itself.

The reason this is important, and why CPUs are becoming a big deal in the data center, is that agents running and issuing commands is a net new workload that is moving from humans being the operators to machines being the operators. Since you want to eventually push things to a deterministic path, the way you do that is to push more to CPUs. When we talk about the Cloudflare Radar for Bot vs. Human traffic, one way to think about it is that running those bots consumes CPU horsepower. That is really what folks in the industry are focused on now.
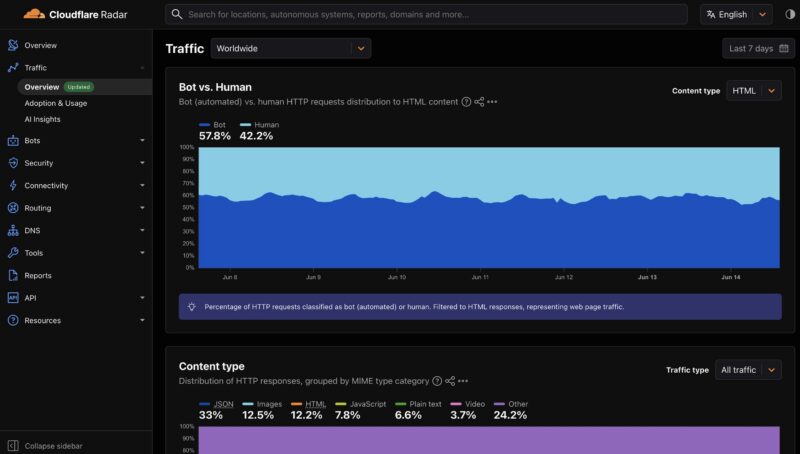
If you are an STH reader, you probably know that this is only part of the equation. Those bots are hitting Cloudflare’s endpoints and other endpoints. Web servers have to handle the load. Databases and other applications have to support those sessions. While everyone is focused on where to run agents, more CPU compute can be used to provide deterministic responses to the AI agent queries.

When agents make requests, they often hit front-end applications. Those applications may have license fees if you are running Oracle or SQL Server, for example, on the backend. The industry has not started talking about it yet, but eventually, there will be firms that go out and optimize licensing for the era of agentic AI with legacy applications. Databases run on servers and have storage back-ends. Everything is serviced over the network. All of the devices providing these services have CPUs. That is one of the reasons agentic AI is creating so much CPU demand in the market.
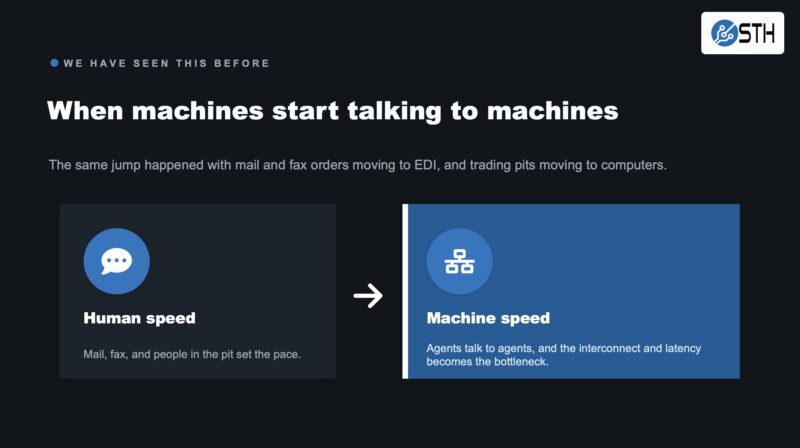
I usually use a version of the slide above to illustrate this point. Today’s infrastructure is optimized for a population of just over 8B people. The new infrastructure has people and likely significantly more agents making requests. As a result, applications need to be optimized for machine-to-machine traffic, not just human-to-machine traffic.
When I was at PwC in the 2010s, I had a team of 30 people working on the order-to-invoice process for a medical devices company. They had a cadaver lab, which was frankly a bit freaky for me to see. The other thing I remember was the day we saw a kind woman who would take orders from the fax machine (thank HIPAA), walk them to her desk, and type them into the company’s ordering system. A project a few quarters prior, I led a team overhauling a large storage provider’s pricing, discounting, and deal management workflow so that they could go from a very slow manual process, which was losing both direct and channel sales simply due to speed. We automated a huge part of the workflow, and by the time we were done, the company was turning quotes, deal pricing, and winning deals over its competitor just based on speed. Its channel partners could get an approved quote with per-deal pricing almost instantly, whereas its competitor still required manual approvals.
I always think of that when I think of agentic AI. Agents will have timeout windows, just like channel partners and customers did. They are not going to wait days for quotes. The infrastructure must evolve, which brings us to the kind of server CPU you need for the agentic AI era. Let us get to that next.



{kind=link}