What Makes Good CPUs for Agentic AI?
CPU performance starts with instructions per clock, clock speed, and core count. IPC determines how much work a core can do per cycle. That depends on core architecture, on-chip cache, and memory access speed. If the cores cannot get data fast enough, the whole system waits on memory. Fast memory access helps with initial loads and any fetches. PCIe to NICs and storage sit roughly at on-chip speeds on modern CPUs, though individual implementations vary.
Higher clock speeds help in two ways. First, the time to the next clock refresh, where a task can start, is shorter. Second, if a job is a fixed number of instructions, more cycles per second means faster answers. More cores mean more cores cycling, which means more requests can be serviced simultaneously.
At a high level, CPUs take data and instructions and turn them over millions of times per second per core. The goal for running AI agents is to get them onto the fastest cores available and scale out across many agents.
Once you start running real agentic AI workflows, you quickly see that very few workloads actually use all cores at once. Or better said, on today’s modern multi-core CPUs, the performance of an individual agentic AI workload is not really running workload X over 64, 128, or 192 cores per system. Instead, the likely case is that both the side issuing commands (the AI agent side) and the side receiving commands (the application side) are running many CPU cores on different workloads simultaneously. With AgentSTH, not only are we looking at the entire socket and single-core performance, but we are also running Agentic workloads spanning different numbers of cores. To be clear, there are actually workloads that, if you use them across an entire CPU, run slower because they are completely single-thread limited. Having a massive number of cores waiting for one core to finish is silly.
One way folks have traditionally looked at this is by looking at things like single-core performance.
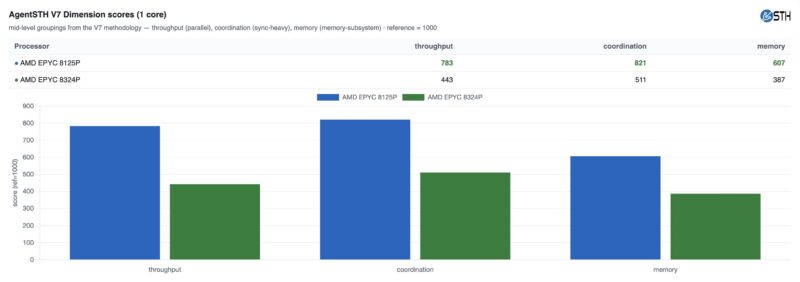
That has led to a lot of interesting philosophical questions in the industry around how to measure performance. With AgentSTH V7 we are using throughput, coordination, and memory bandwidth as our high-level dimensions of CPU performance, but there are a few worth watching out for.
Performance Per Core and Memory Bandwidth
Performance per core is a strangely defined metric. AMD and Intel both define a core as two threads on one physical core, and that distinction gets abused in marketing. Single-core performance often means a benchmark running one copy on one core, which does not leverage the SMT thread and can leave 30 percent or more of the performance on the table. Performance per thread divides total performance by total thread count, which distorts the picture because an SMT thread is typically a 20 to 30 percent adder, not a full core. Sockets dominate infrastructure cost because each one goes into a machine with NICs, SSDs, chassis, motherboard, and power delivery.

Per-core performance is very important, without a doubt. That is what gates many agentic workflows as well as legacy applications. At the same time, performance per socket is also hugely important. Sockets affect the number of NICs, motherboards, SSDs, and so forth required for a system. The more we looked into it, the more we kept coming back to simple advice. You want as many fast CPU cores per socket and per rack as you can get for the agentic AI era. Lots of slow cores are probably not as useful because they might be too slow. Few fast cores are interesting, but you end up needing to pack a lot of sockets into a rack to scale that model. Having fewer cores per socket has one advantage you hear a lot about. The same number of memory channels and fewer cores means you have more memory bandwidth per core, and that is often why many HPC workloads actually favor lower core count parts.
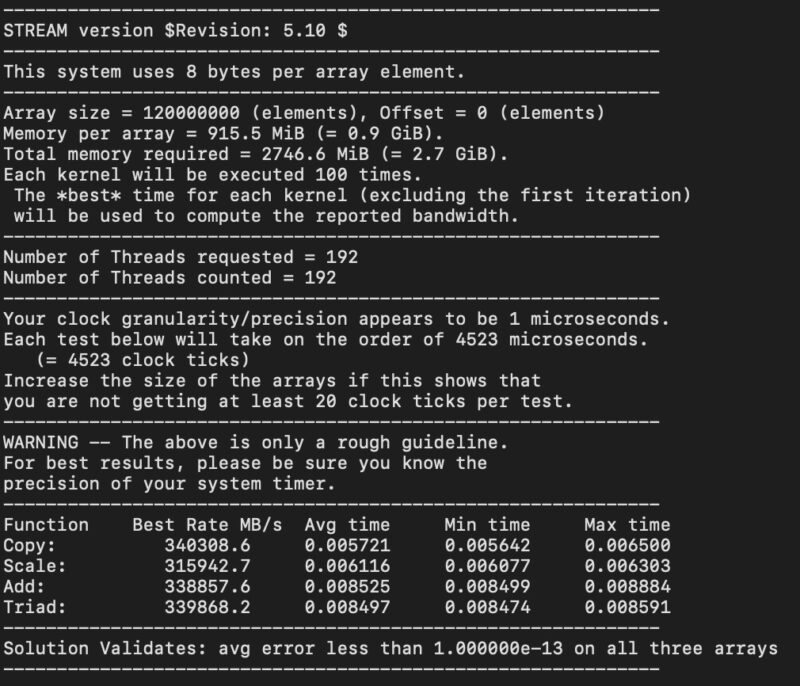
Memory bandwidth is a major factor. We now have an entire bucket for mostly memory-bandwidth-sensitive workloads in AgentSTH V7. Some agentic AI workloads, such as in-memory databases and HPC workloads, are heavily memory-bandwidth-bound. We found this in several AgentSTH benchmark sub-tests during months of profiling. STREAM remains the industry’s go-to memory bandwidth benchmark, and it shows up in marketing for every new processor generation as the generational high-water mark. Companies commonly use the STREAM Triad score, though some include additional tests in a geometric mean to further boost the new generation. Note, I am not talking about one company doing this. Everyone does it because it is a high-water mark.
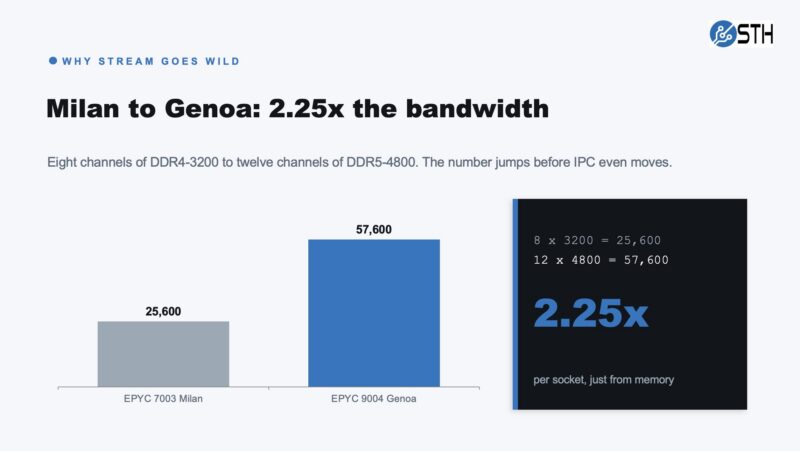
Memory bandwidth roughly equals the speed of each memory module multiplied by the number of channels. Moving from AMD EPYC 7003 Milan with 8-channel DDR4-3200 to EPYC 9004 Genoa with 12-channel DDR5-4800 gives you 57600 divided by 25600, which is 2.25 times the memory bandwidth per socket. That makes STREAM scores go up significantly, even if IPC does not improve as much per core. It also means the geometric means of benchmark results trend higher when one or more tests are memory bandwidth bound. That is generally. If you want to see this in action, here is Why You Should Fully Populate Memory Channels on CPUs featuring AMD EPYC Genoa. We showed the scaling as we scaled the number of installed DIMMs:
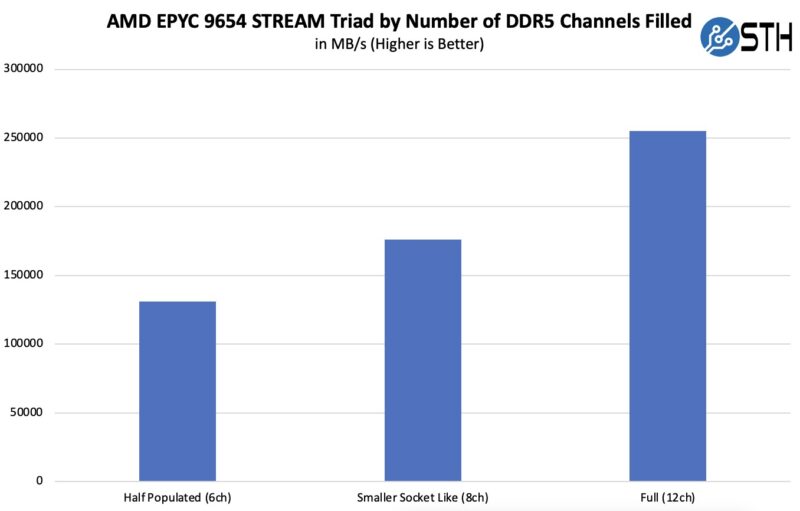
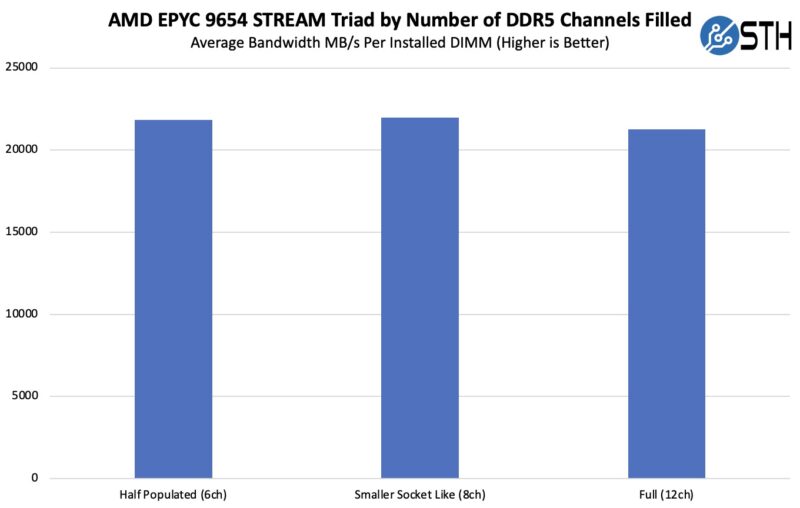
If you want to see the pattern, here is what the incremental bandwidth per DIMM we got when adding more memory. That is a fairly flat line showing why STREAM largely scales with the number of memory channels and the throughput of each device.
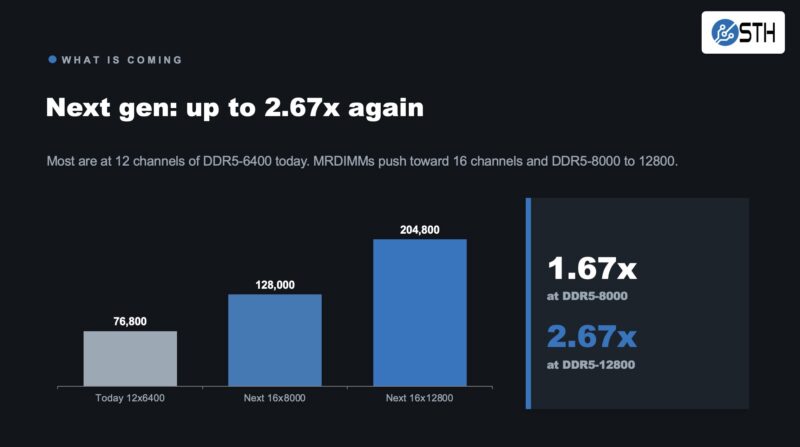
Next-generation processors will support DDR5-8000 to DDR5-12800 with up to 16 memory channels. Most current systems have 12 channels at DDR5-6400. Moving to 16 channels at DDR5-8000 gives 128000 divided by 76800, which is 1.667 times faster on certain workloads. With 16 channels at DDR5-12800, which reaches 204800 divided by 76800, or 2.667 times faster. Next-gen CPUs using MRDIMMs instead of LPDDR5X can deliver substantial gains in memory bandwidth on the right workloads. That is going to be across vendors, but it is mostly just a function of having faster memory and more channels in the new generation.
Agentic AI workflows have legitimate areas that will be memory bandwidth-limited as tools get called. Compression workloads can be memory bandwidth-bound as well, and that is one thing folks often overlook. Other areas are CPU-bound. Compiling source code is often CPU-bound. Legacy applications with databases face CPU constraints and potentially per-core licensing costs. The interesting part is that, on the agentic AI CPU side, there is a net-new workload that looks like the traditional server CPU compute side, albeit with slight adjustments to the weighting.
For STH readers, a strong consulting engagement would be moving companies to newer, faster servers or off per-core license databases, since agentic AI is going to put more pressure on existing applications. Next however, let us quickly take a look at what “good” looks like if you are deploying today.



{kind=link}
Very useful Friday read. I run a MSP and we’ve got a customer where we’ve seen 18% of our inventory systems’ load is now coming from a dedicated openclaw server we’ve setup. They’re still on epyc 7003 but it’s true there’s important load on the trad apps as well.