
Today Ampere discussed its new server processor roadmap, including the new AmpereOne processors in its annual update. Server CPUs are on the verge of a complete revolution. For more than a decade, the standard server CPU is a big performance core with SMT/ hyper-threading. That core was designed to do everything well from web serving to HPC calculations. We are at the point where that is basically too much, and leading the charge in the opposite direction is Ampere.
AmpereOne with 192 Cores 128x PCIe Gen5 Lanes and DDR5 in 2023
Ampere is focused on offering more physical cores, without SMT, than the x86 players. They also trade-off things like a focus on HPC compute (e.g. AVX-512) to further streamline cores and fit more onto a chip. Ampere is not focused on per-core performance. Instead, it has a bunch of cores and then lets its chips push down the voltage / frequency curve and become more power efficient as a result. Ampere sells this as magic. While it is a smart architecture, it makes a lot of sense for the market Ampere Altra is targeted at.
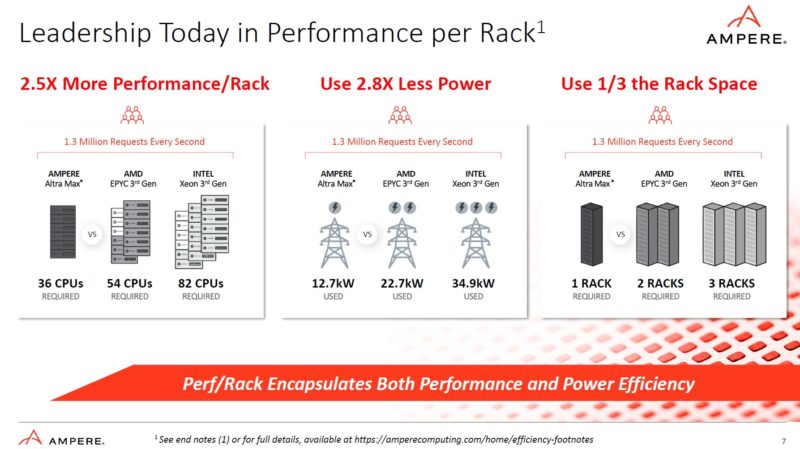
On the performance per rack, this is something a lot of data centers are struggling with. How to get more cores into a rack when power is a major constraint.
While we have looked at the Ampere Altra and Altra Max, Ampere’s next generation is very different.

The AmpereOne no longer uses stock Arm Neoverse cores. Instead, it is a custom core designed by Ampere. It still uses the Arm ISA, but it is Ampere’s core. It also has a host of new features like DDR5 and PCIe Gen5.

Ampere is increasing the core count. AmpereOne will cover 136-192 cores, leaving Altra/ Altra Max to core counts of 128 and below. The cache is doubled. PCIe Gen5 doubles the bandwidth. We asked, Ampere still has 128 total lanes in dual socket configurations, but the focus now is really on single socket since that is how their chips are being deployed. That being said, we saw a dual-socket design at OCP Summit 2022.

Ampere also has a higher TDP in this generation and adds new features like Bfloat16, confidential computing, nested virtualization, and more.
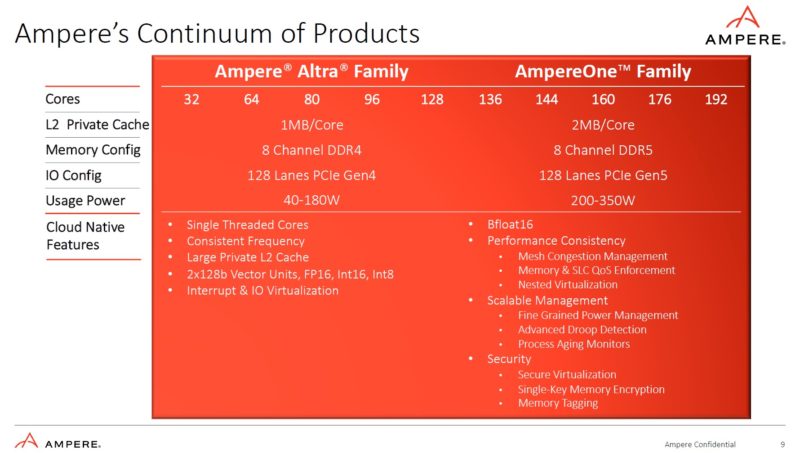
There is still an 8-channel memory controller but it is now DDR5. That means a big bandwidth jump and an increase in theoretical bandwidth to match the increased core count. You can learn more about DDR5 in Why DDR5 is Absolutely Necessary in Modern Servers.
Here is a bit more on the cores. The L1 cache is changed along with the 2MB of private L2 cache. That should help performance significantly. Ampere’s architecture is aligned to its go-to-market. The company is focused on cloud instances where each core has its own private cache and not sharing resources is important.

Ampere also told us they are not just chasing random IPC gains. Instead, it is getting workloads from its customers. It is emulating those workloads on its development cores, then it is picking the most efficient IPC gains to target in each generation.
Ampere’s design also has a sea of cores at the center, then memory and I/O in chiplets on the edge. One can think of Ampere’s design as almost like a reverse EPYC Rome, Milan, Genoa.
On the VM platform side, this is a fairly straightforward one. Since x86 uses SMT/ Hyper-Threading a cloud provider will generally only assign one VM to each core’s two threads (2 vCPU.) Since AmpereOne is a sea of cores with independent resources, it allows for 1 vCPU VMs. Then, Ampere has an architecture designed for a cloud-centric set of workloads versus x86’s larger cores. We will see AMD EPYC Bergamo later this quarter push x86 to 128 cores and we expect 256 threads with still the large high-performance cores but with lower cache per core. Intel will have Sierra Forest allegedly next year.

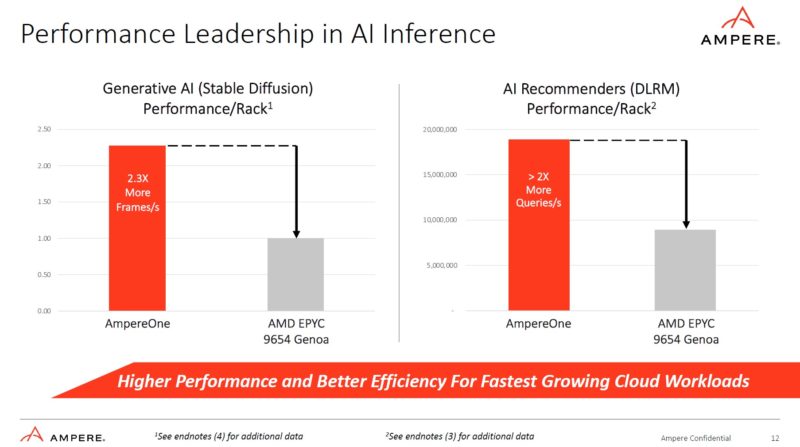
With Bfloat16 and many cores, Ampere can beat AMD EPYC on some AI workloads. This is not looking at Intel Sapphire Rapids with AMX.
Ampere’s list of partners is growing. Notably absent are Dell and Lenovo. We have reviewed systems from companies like Wiwynn, GPU systems from Gigabyte, and even edge GPU systems from Supermicro. Next we will have the HPE ProLiant RL300 Gen11 that we will publish later this month.

The list is growing here.
Reading the End Notes
One bit we always need to do with Ampere and other Arm vendors is look at the end notes. There are often some interesting tidbits. For example, the performance per rack used Ampere Altra MAX at 3.0GHz and 2.6GHz. Usually the x86 vendors would present this comparison with only one clock speed.
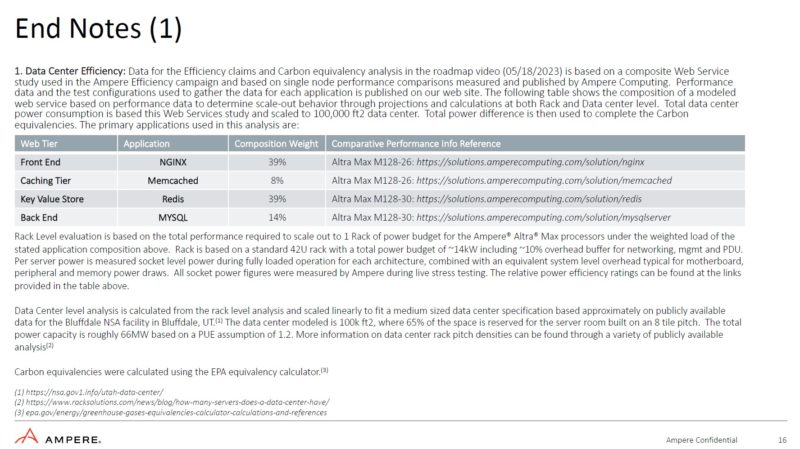
Here, the AmpereOne uses less power than AMD and Intel servers. Clock speed is not shown for AmpereOne which is important for power efficiency.
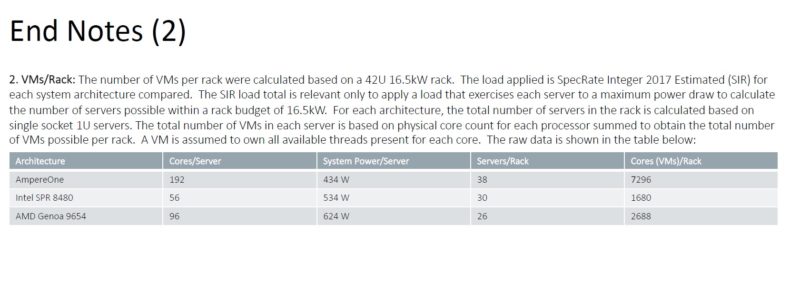
On the AI workloads, however, AmpereOne is using more power, albeit at higher performance. As a quick note: it is unlikely that the AMD system has all 12 memory channels filled with 256GB of memory.

That higher performance at higher power extends to the next end note as well. While the AmpereOne is using more power on the AI workloads than AMD EPYC Genoa, it is using less on integer workloads in End Note 2. Again, we do not know the clock speeds but the AmpereOne in End Notes 3 and 4 is 160 cores while the 192-core version in End Note 2 is a different SKU.
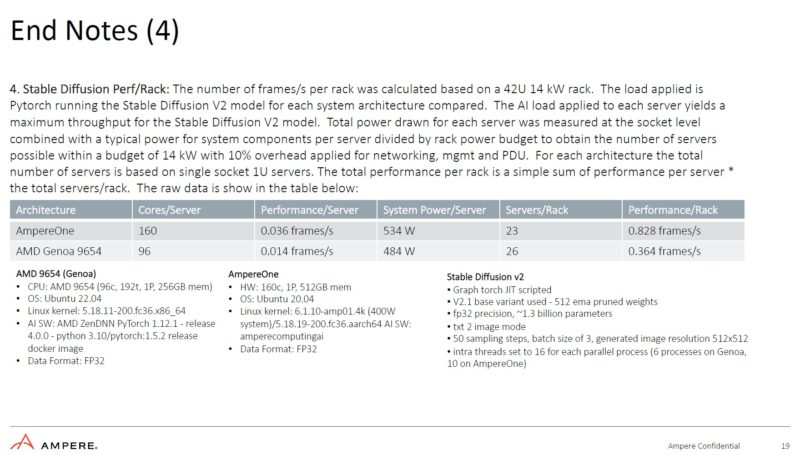
There is a lot going on here, so it is probably worth reading the detail of the End Notes.
Final Words
Overall, we are very excited about AmpereOne. The bigger question is how will the cloud service providers adopt it. Right now, many CSPs seem to be favoring an Altra core count closer to 64 cores, largely driven by AWS Graviton lines. If they can change to 128 or 192 core count chips, they will consolidate servers 3:1 over the initial barrage of Altra-based Arm servers, leading to lower costs.
After the Ampere AmpereOne launch, next will come AMD EPYC Bergamo’s launch. This is going to be a big space as there are a lot of web servers out there.
Now our goal is to find one, and we will find one within the next 14-18 days.



{kind=link}
Those footnotes… betray a lot of their performance claims. I mean, to be honest it kinda makes me wonder what the actual performance is? If they’re having to deceive using benchmarks it may not be particularly competitive.
It’s 2023. People can Google stuff. They should hire Patrick and team to go through these footnotes and pick them apart before they publish them. I thought they’ve got an analyst business. If an analyst isn’t doing this then what are they doing?
AmpereOne is made on a 5nm node. They are only fabbing this on the maximum core layout. There will not be a lesser core SKU.
There will be small window for Ampere because AMD can’t get the EPYC Dense (192 cores) to production because to reach that core count, they need a 3nm node. There isn’t adequate capacity at TSMC for 3nm production (Apple) until next year. I don’t think Samsung is ready for that level of scale.
Intel 18A is still a year away. So Ampere has a small window of opportunity to penetrate the datacenter high density market.
@ Nate77: You’re assuming this is just incompetence not disingenuity. A CPU company that needs an external analyst to tell it how to benchmark correctly is in deep trouble. The audience for these slides are not the technically savvy (their actual customers) but wall street analysts (IPO around the corner!). Endnote 3 has Epyc using FP32 vs their use of FP16. Endnote 4 uses FP32 on both. There may be a valid reason for this discrepancy, but it has not been called out. The Epyc systems are configured with 50% memory capacity compared to Ampere. Patrick opined that all 12 channels are not populated either, which makes it worse. (That’s just what I could glean from a superficial read).
The other thing is timing: Bergamo will launch shortly, and has 256 threads.
@ spuwho: Bergamo (Zen 4 dense) has 256 threads, so in most throughput cases (all of the tests above), I imagine will win. It also has more b/w per core at those high core counts. Ampere loves to highlight the noisy neighbor problem but afaik, nearly everyone runs with SMT on, so it is likely a second-order effect. (And you can have noisy neighbor effects in their design too: the L3, memory, and IO channels are shared).
Random observation: Their L1 I-cache is tiny. 16kB is anemic considering cloud workloads are known to have huge instruction cache footprnt.
I’d agree with Nate77. Everyone is banging on Ampere ‘s numbers. Patrick is one of the analysts that would tell them what the reaction would be to this presentation.
It’s good that they’ve got end notes but they’re lacking an external validation of their presentation.
There are only 2 I trust. Michael Larabel on how to benchmark or automate many benches. Patrick on what numbers are comparable and what they mean. Everyone else is noise in the system.
Comments are closed.