
At ISSC 2023, Dr. Lisa Su, CEO of AMD, discussed stacking components and why advanced packaging is needed to achieve Zettascale computing in the future. Part of the discussion centered around memory. Given we just published a few pieces on memory, we wanted to cover this briefly on STH.
AMD Talks Stacking Compute and DRAM at ISSCC 2023
One of the big limiters to building bigger systems has become memory access power. This has come in two forms, primarily from higher-speed interfaces as well as just simply adding more channels of memory to servers. Here is AMD’s chart from 2007 or so to 2023.

We recently discussed the increase in Memory Bandwidth Per Core and Per Socket for Intel Xeon and AMD EPYC over the last decade and did a DDR5 server RDIMM piece where we showed why the jump above from 8-channel DDR4 to 12-channel DDR5 was such a big jump in performance.
One of the biggest challenges is on the I/O side where power efficiency is getting better, but the channel loss is becoming a bigger challenge.
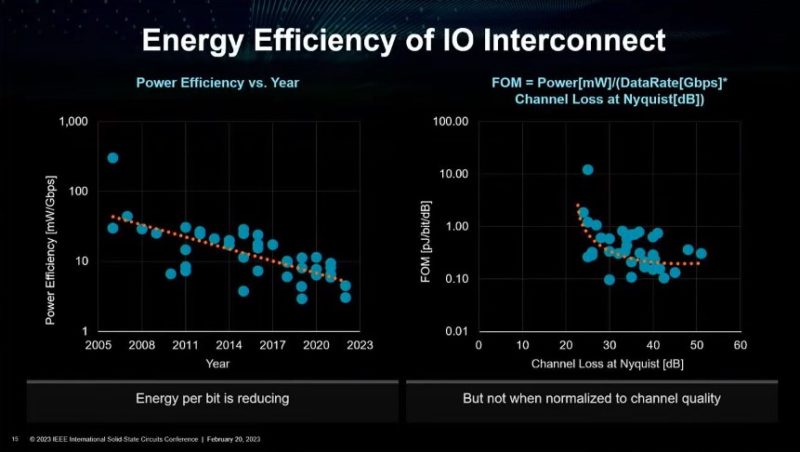
The net impact of this is that going off-package to DRAM is becoming increasingly costly from an energy perspective. We have already seen cases where HBM has been integrated on package for CPUs and GPUs, but there are other technologies. Those include using co-packaged optics and 3D chip stacking.
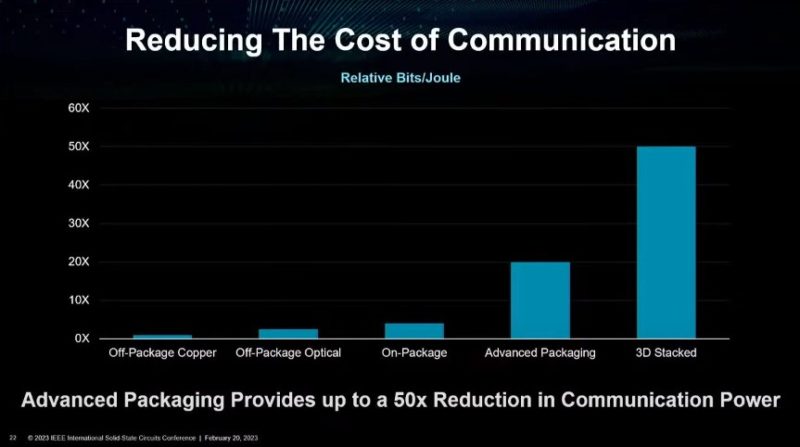
At ISSCC 2023, AMD showed the concept of bringing memory closer to compute by using a silicon interposer (similar to how GPUs integrate HBM today), to the future of stacking memory on compute. Moving data through a 3D stack uses much less power than trying to drive signals to DDR5 DIMM slots.

In the talk, the upcoming AMD Instinct MI300 was discussed. One of the interesting bits in this presentation was the 3D stacking of Infinity Cache and Infinity Fabric dies below the CPU and GPU cores in the MI300.

For some reference, the 3D SRAM stacking we see in the current Milan-X and soon the Ryzen 7000X3D series, places the SRAM above the CPU die. The MI300 would change this and place the cache below the CPU die. Cooling is a major challenge so getting the hot compute tiles closer to a liquid cooling block makes sense.
Another quick topic discussed during the talk was processing in memory. We covered the Samsung HBM2-PIM and Aquabolt-XL at Hot Chips 33 and AMD said it is working to research computing in memory with Samsung. The idea here is even more dramatic by not having to move data off the memory to do some compute on it.
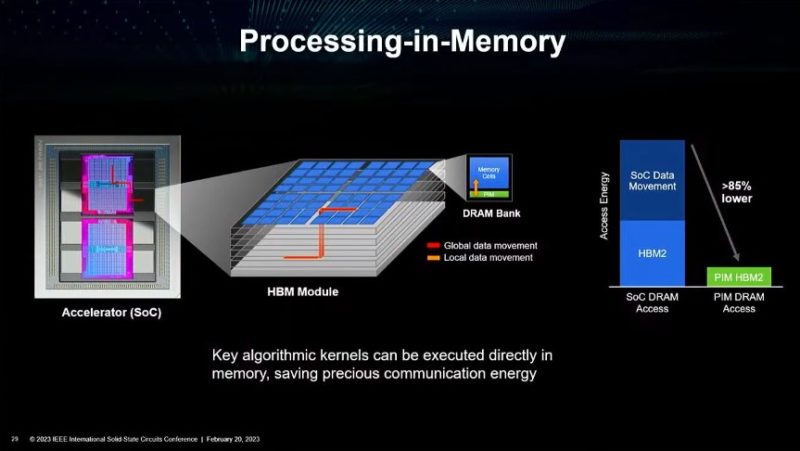
That still seems a bit further off than some of the packaging advancements for memory.
Final Words
Moving data around within a system, and within a rack, is becoming an acute point of focus for the industry. That data movement energy and performance cost detracts from the overall efficiency of a system. As a result, the entire industry is working to evolve beyond the typical CPU with attached DRAM model and move to new architectures. Since the talk happened earlier this week, we just wanted to share it with STH readers this weekend as something to think about.



{kind=link}
Lol this has been in intels roadmap for years
LOL, this is what Apple already achieved with their M-series.
Apple co-packaged but didn’t stack like AMD’s onto here.
Not sure if that’s a good idea even if the concept is sounds, as you’ll limit the expansion down the road. At least for the consumer side, I can see the idea (Apple does it well with their M-series) but servers, workstations and DIYers?
As long as expansion is retained with the associated “costs” being decided by the end users, I don’t see this being an issue. An example is like current CXL, this would place memory stacked on the chip (closer) with slower/more costly far access options: in system DIMMs and remote/CXL memory pools.
Comments are closed.