
At Hot Chips 33, Samsung had a few disclosures. The first that we covered was the Samsung Unveils 512GB DDR5 Memory En Route to TB Scale poster that we covered. The other was perhaps that it is the fab for the new IBM Z Telum Mainframe Processor. At the end of the conference’s first day, we have a talk on Samsung HBM2-PIM and Aquabolt-XL. This is the ninth piece of the day or about a week and a half of STH coverage just today so please excuse typos as this is being done live at the end of the day.
Samsung HBM2-PIM and Aquabolt-XL at Hot Chips 33
The presentation was interesting as we took a quick preview. The title of the PDF for the slides was “AXDIMM for Facebook DLRM Annual Summary.” We know the AXDIMM was presented at the 2021 Global Semiconductor Alliance (GSA) Memory+ keynote. It had not been presented alongside Facebook before this.

Continuing to increase memory bandwidth is not increasing alongside the speed and scale of CPU/GPU/ Accelerators.
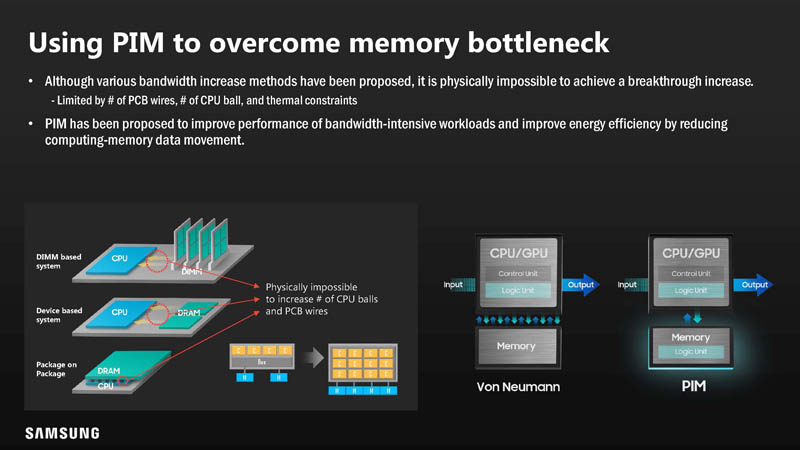
This slide is absolutely fascinating.
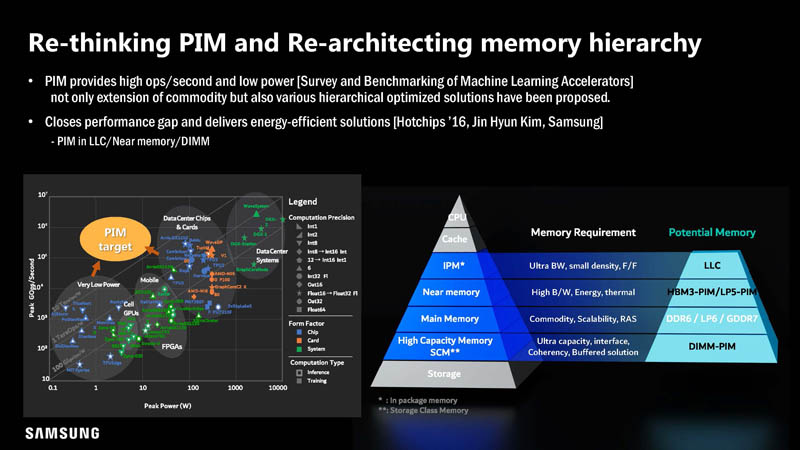
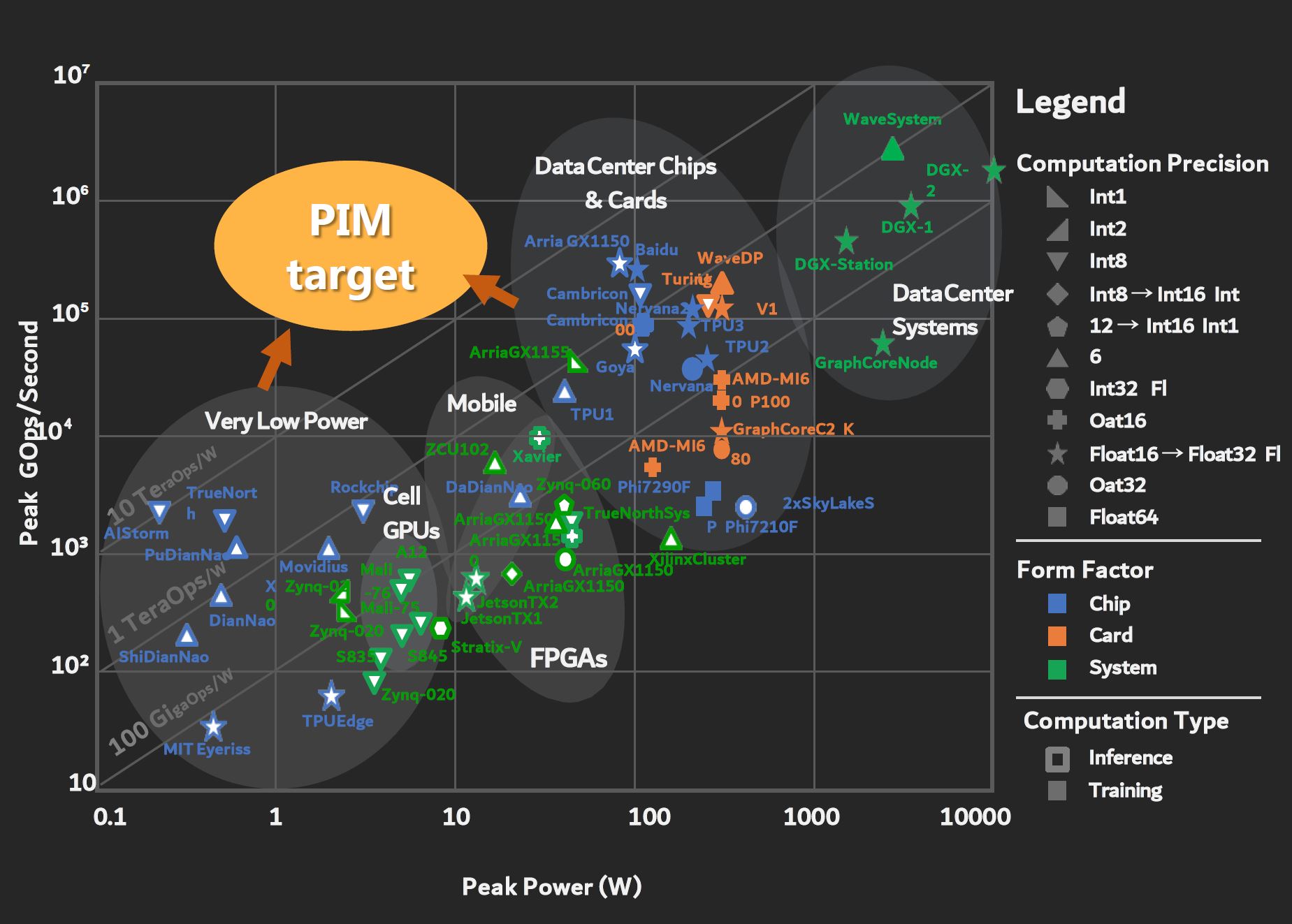
The reason is that it has the performance and power consumption of several architectures that have not been disclosed beyond this slide. For example, Nervana/ Nervana2 were never disclosed to this detail.
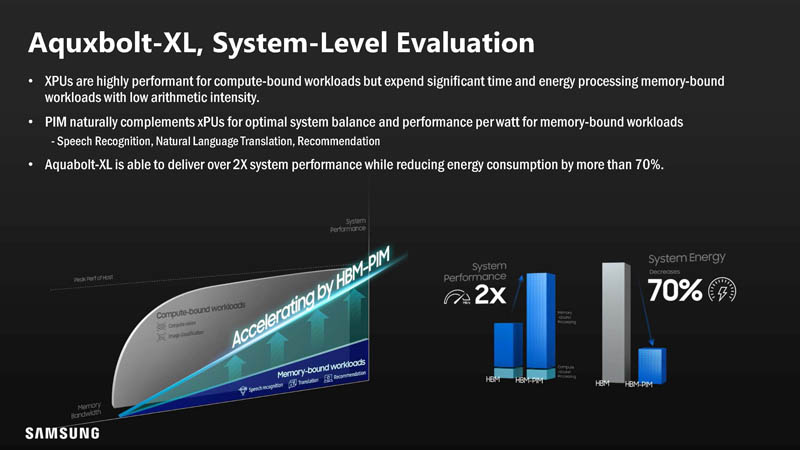
Let us make PIM a bit easier to understand. Samsung is advocating that performing computation in the memory die is faster and more efficient than taking the data back to a CPU, GPU, or accelerator.

Part of the benefit is that data does not need to move as far with PIM. As a result, there is power saved and the potential for more performance by not having to move data. More on that as we get to some of the results.
The basic idea is that the execution units are just outside the I/O boundary of HBM2 but on the actual HBM die. Samsung said that for the HBM2 demonstration it had to turn off ECC but it should be possible to add in future versions.

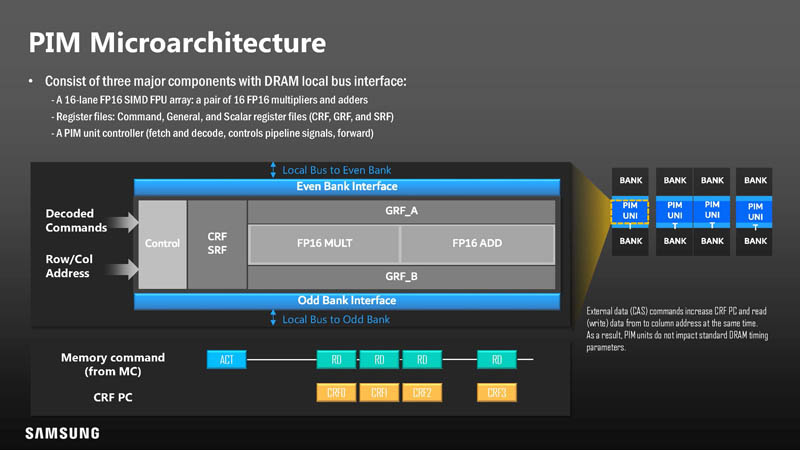
Here is what the microarchitecture looks like. As a quick note, Samsung says that even with this, it still needs to support JDEC standards for performance/ latency as normal memory. Think of this as added functionality.
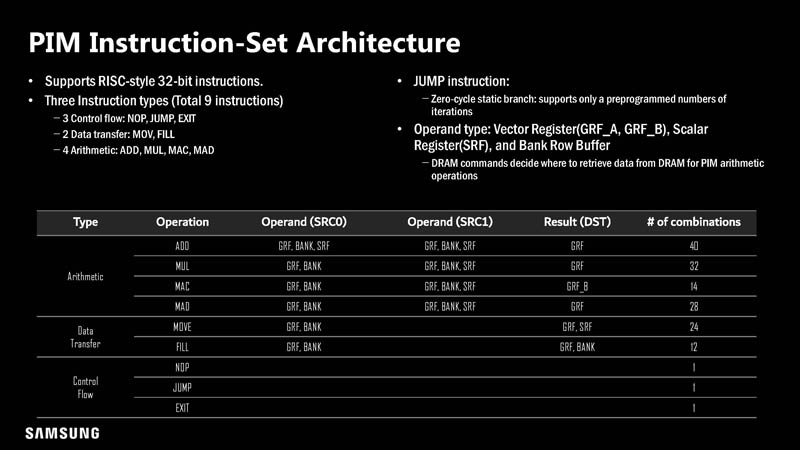
The PIM has typical RISC 32-bit instructions.
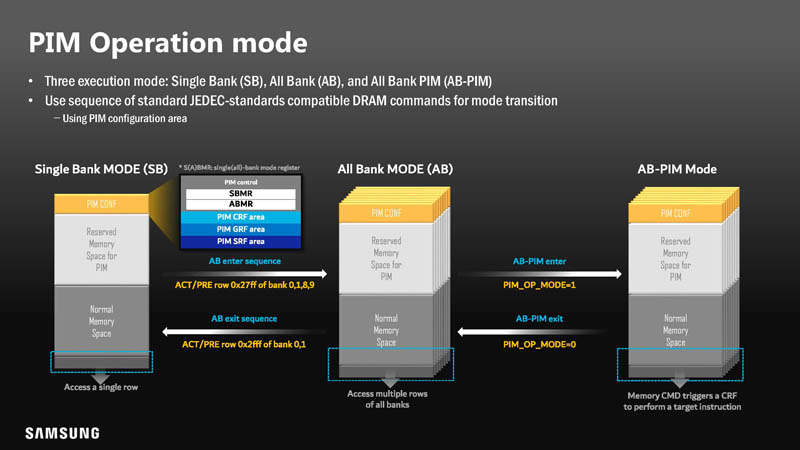
This is the PIM Operation mode on how PIM functions can be implemented in DRAM.
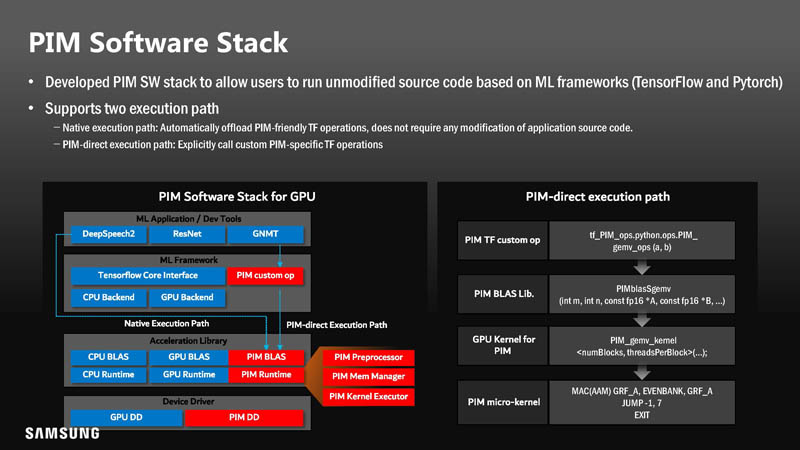
The software stack needs to change with PIM. In the below, red is additive to the existing software stack. Samsung also developed custom operations.
The initial implementation uses HBM2 design to gather more data on utilizing PIM. Here, the four bottom DRAM dies were replaced with PIM-DRAM dies in an 8-die stack.

Performance with PIM could be 3.5-11.2x in Samsung’s testing.
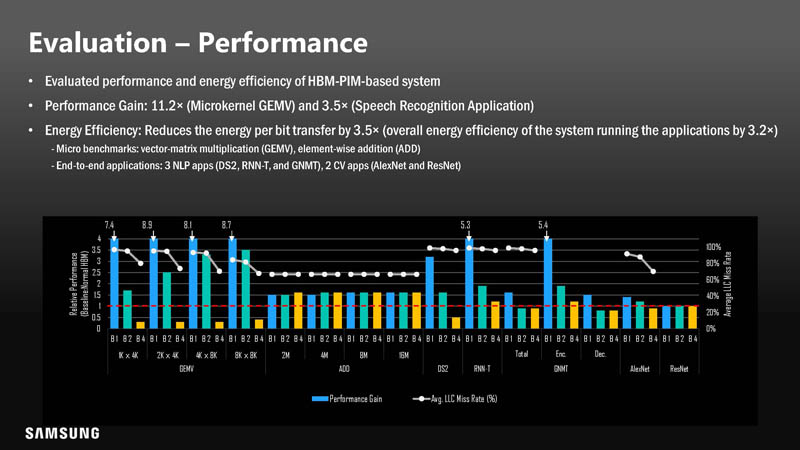
Adding the logic to the bottom four DRAM dies added only 5.4% power. 5.4% may sound like a lot, however, overall, performance per watt went down because of increased performance and less data movement.

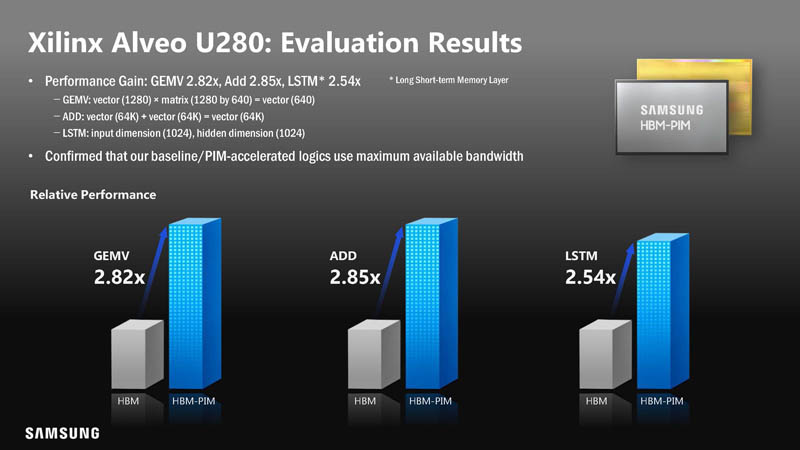
Samsung also created a version on the Xilinx Alveo U280 for PIM evaluation. We covered the Alveo U280 here.
With this, there was a smaller performance gain, but 2.5-2.9x is still a very large gain.
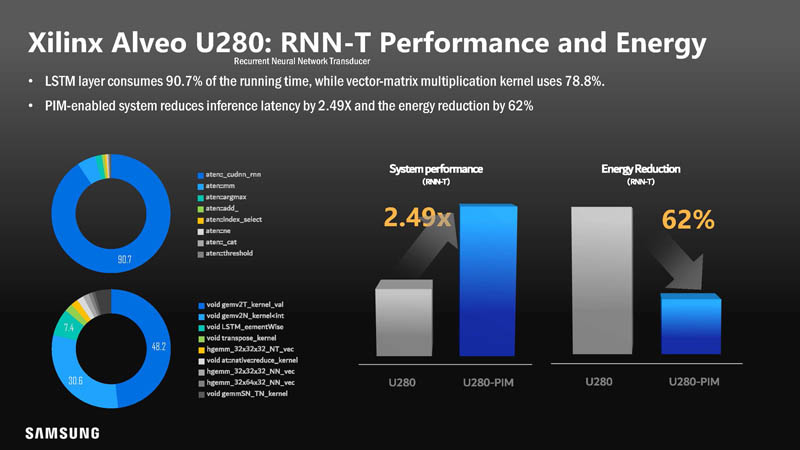
With the better performance, the net energy usage went down making it more power-efficient.
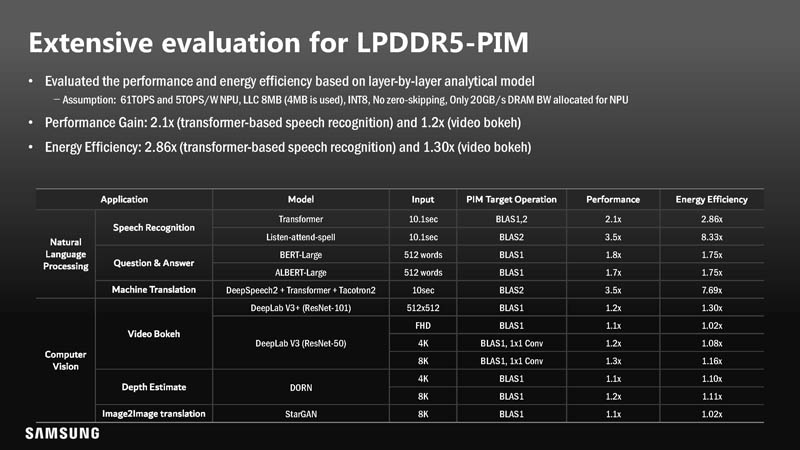
Beyond the FPGA and HBM2 implementation, Samsung is also looking at LPDDR5-PIM. LPDDR5 is used in a number of applications such as in mobile client devices.
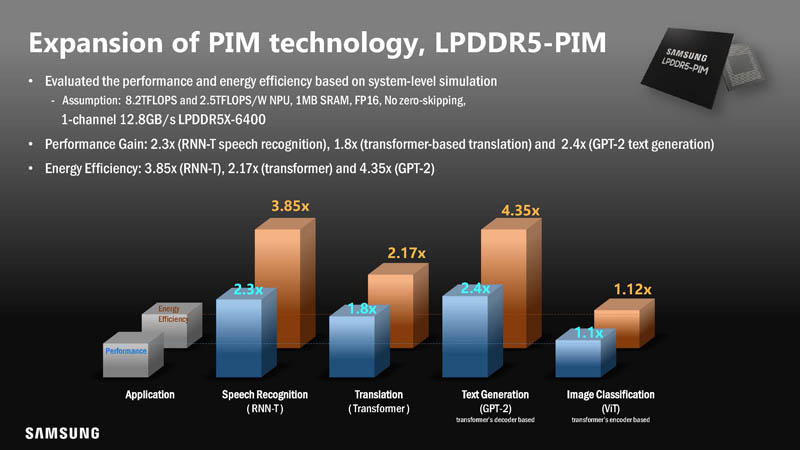
Performance was not necessarily as good, but there was still a net energy efficiency gain.
Samsung, as one may imagine, is suggesting an AXDIMM format for an accelerated DIMM-PIM.

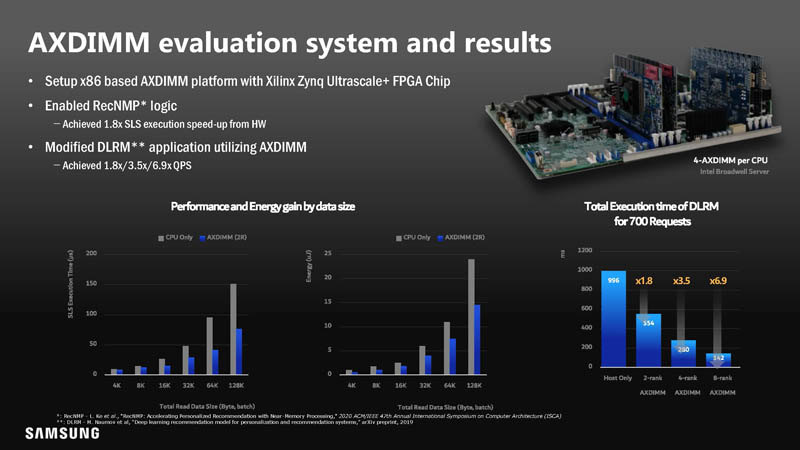
On the AXDIMM evaluation side, Samsung used a Broadwell-based system. That is actually important because speedup and efficiency gains in some of these comparisons may be impacted by new generations of CPUs and new instructions they have.
Samsung suggests this computational memory is built with different types of acceleration depending on the type of memory and the target applications.
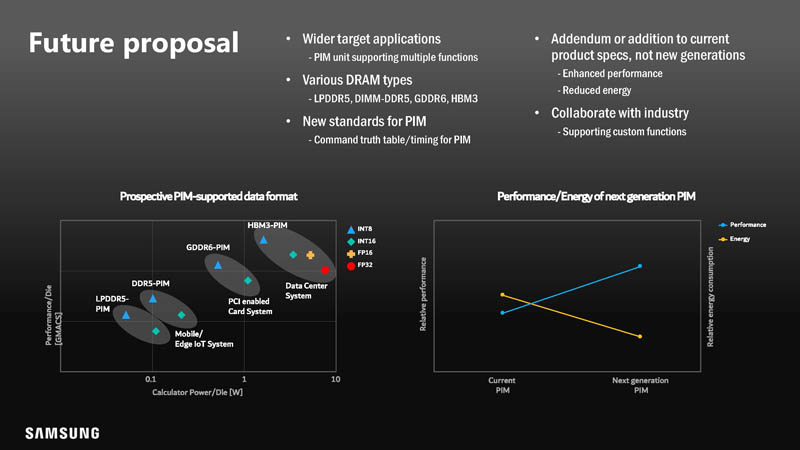
There is certainly a lot going on here.
Final Words
Overall, this is one of those efforts that will require a lot of industry collaboration and effort to deploy. Samsung has toolkits that make PIM offload transparent to users. Still it creates a new class of devices and a new accelerator with new implications for security. This is one of those presentations that we would normally say would not happen overnight. At the same time, it is quite interesting that we saw the title of the presentation with a hyper-scaler’s name on it. For STH readers, if nothing else that AI accelerator performance per watt chart should be fascinating.



{kind=link}