
A few hours ago, I ran into Raja Koduri at a bar. For those who do not know, Raja is the SVP and GM of Intel’s Accelerated Computing Systems and Graphics (AXG) Group. Given all of the Supercomputing conference activities we are covering this week, it was great to grab a beer (perhaps more than one) with Raja and go into Intel’s HPC strategy. Specifically, Raja detailed for me how Intel plans to go from ExaFLOPS in 2022 to ZettaFLOPS in 2027-2028. For some context, this is Intel’s pathway to roughly 1000x performance of today’s systems in only 5-6 years.
Update: Video Version
As a quick update, we now have a video version of this one:
Of course, we suggest opening it in a new browser, tab, or app for the best viewing experience.
Raja’s Chip Notes Lay Out Intel’s Path to Zettascale
What you are going to see as the artifacts of our discussion are simply a few points on an Office Depot pad. Just for some context, we managed to grab a picture while having this discussion.

Raja explained to me Intel’s path to Zettascale as an enormous improvement to today’s systems, including the Aurora supercomputer slated for 2022. I asked and Raja let me snap a photo of his “chip notes” after the discussion. For those wondering, the bar provided us each with small plates of Cool Ranch Doritos. It was a bit funny since we were there talking about chips. Hence, we are calling these “Raja’s Chip Notes.”

What you can see above is a series of improvements Raja thinks Intel can attain in order to get to Zettaflops, or roughly 500x the Aurora performance of >=2 Exaflops (more on that in a bit.) One of the constraints here was operating within a similar power footprint to Aurora since it would be less of an achievement to say Zettaflops were achieved with a corresponding 500x increase in power consumption.
- One of the big ones and the first on that list is “Architecture” with a 16x improvement. That 16x involves adopting similar math execution to what some others in the market are doing. That number is 16x, but Raja told me that Intel knows the architectural changes to scale well beyond that. The 16x is being used here because going well beyond that might change the future GPUs/ accelerators into double-precision LINPACK optimized chips instead of performing well on other workloads.
Raja noted that while Intel could focus on simple DP execution, instead one of the bigger problems is keeping all of the execution units fed with data and enough memory bandwidth. His position is that Intel would focus on not just DP execution that may get Intel to the Zettaflop era, but also AI math operations, and perhaps most importantly ensuring that memory bandwidth is plentiful and well-utilized. That approach may not give a 1000x improvement for every application, but it should help the Zettascale architecture provide enormous gains for a wider variety of applications. - The next one is labeled as “power/ thermals” and is scoped with a 2x improvement. Since the Zettaflops goal is targeting the same or similar power as Aurora, one other way to get more performance is to do more with less power. Examples of this may be running chips at substantially lower voltages and introducing higher-end cooling. We are going to see the transition happen to liquid cooling, but more significant cooling may be required than just rear door heat exchangers.
- “Data movement” is a 3x opportunity. This is an area that I gave some feedback on to Raja in terms of asking for more detail to be shared. Intel, as one can imagine, has tooling to analyze where power is spent in systems. These days a large amount of power, and it can be a majority of power, is spent moving data around in a system and package. As a result, things like having higher degrees of integration can make a major difference in terms of rebalancing the power that is dedicated to actually performing computations versus moving data. For those following silicon photonics, this is coming, and we will cover that a bit more later.
- The one that I think many folks focus on is process technology. Intel announced a fairly aggressive schedule for new process introduction. That is why there is a “Process” 5x note. One key item here is that, especially on the HPC/ GPU side, Intel is embracing the multi-die or multi-tile design along with advanced packaging. This is specifically designed to be able to allow different types of silicon to be integrated using the correct process technology in order to limit risk as Intel moves forward to new generations.
Now 2EF x 16 x 2 x 3 x 5 is only 960, however Aurora is listed as a >= 2EF peak system. My sense is that it will be well above that. In turn that will allow a bit more margin in the individual items above (rough estimates themselves) to advance and still hit a Zettascale system or roughly 1000x a current-generation 1 Exaflop system.
Now let us get to Intel’s HPC Strategy page:

This is laid out in basically three phases. Each of these phases roughly matches oneAPI versions that you will see on the left side. Raja stressed that taking on architectures as a company was not just building hardware. It is, perhaps more significantly, also maintaining and investing in a hardware-software contract for consistent order of magnitude performance gains.
Phase 1: 2022 – 2023 – Exascale
- Exascale for Intel really starts with its 2022 lineup. This includes Sapphire Rapids and Ponte Vecchio and we will see this in Aurora. Although these are 2022 products, there is a lot out there on them. I have personally seen several Sapphire Rapids systems between OCP Summit 2021 and SC21, so the industry has transitioned from talking about Sapphire as a far-out product to discussing the line more definitively at this point.
- The next generation Raja calls “optimizing Exascale.” It was getting late (around midnight) and neither of us could remember if Intel had disclosed Granite Rapids. I checked and it was noted in the Intel Accelerated Manufacturing disclosure so one can read Xeon-Next here as Granite Rapids. PVC-Next is another bridge that Intel has not publicly disclosed. The overall message I took away from our talk is that this next generation was about enhancing the 2022 architectures.
Phase 2: 2024 – 2025 – Pre-Zetta
- In the Pre-Zetta era, we get Falcon. Falcon is the Xeon + Xe combination that will be more equivalent to NVIDIA Grace. Something that will become increasingly important is integration. Removing more SerDes from systems saves a ton of power and higher levels of integration mean that less power can be spent on moving data around and more power can instead be spent on compute.
- “Lightbender” is what we have all been waiting for. This is silicon photonics integrated into chips. I have some rough idea of the target specs, but since they did not make it to Raja’s Chip Notes let me set it up differently. Intel has stated that it is moving to a chiplet/ tile architecture with increasingly sophisticated packaging. My sense is that this is a silicon photonics tile solution that will be fast enough to do things like move HBM or other types of memory off of GPU/ CPU packages. That opens up the ability for new system design as well as the ability to easily vary capacity and potentially media types. A high-speed photonics interconnect also means that other devices such as processors can be physically more distant but with a high-speed link to the GPUs/ accelerators. That will allow for better system design as well.
Phase 3: 2026 – 2028 – Zettascale
- Since there is not a lot on the notepad on this one, this is the next step in refining all of the different components that Intel is building over the next 4-5 years. One way to think about it is a double-precision Zetaflop in something like a 50MW power envelope. The other way to think about this is that it could lead to the current 50MW Exaflop-class systems down-scaling to be only 50kW systems that can fit in a rack or a few racks. An impact of this is really democratizing large-scale supercomputing. That is what the line “Exascale at the Edge” is referring to on the first sheet.
- Another important note here is that this is the timeframe when the architecture, power and thermals, data movement, and process technologies would need to move up the maturity curve. I asked Raja and he is realistic. A lot of this technology Intel has line-of-sight to, but not everything has been invented yet. He acknowledged that there are risks to the 1000x figure, but he was walking me through the plan. My overarching sense having spent some time with Raja is that he feels some uncertainty and risk but also has a bit of buffer built into parts of the 1000x plan.
- One will notice that the dates here are written a bit oddly with 26 – 27 – 28. I may have suggested adding “28” to give a bit more margin for future technologies.
Now to the final sheet:
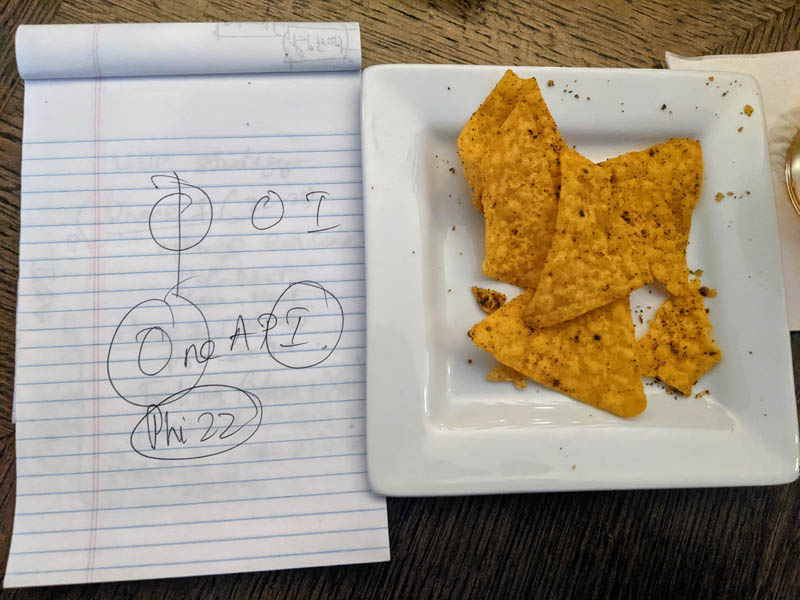
Recently Raja posted this tweet:
? will be back! https://t.co/ZuHNR43Sh5 pic.twitter.com/AfF7qkNZEY
— Raja Koduri (@Rajaontheedge) November 15, 2021
For those who do not know “?” is the 21st letter of the Greek alphabet. More importantly for context, it is also the name of the Xeon Phi line that Intel had in the HPC space for years. Raja noted that the ? symbol looks somewhat like the O and I from oneAPI put together. My suggestion, given that to achieve the 1000x it is likely we will have fewer piecemeal components and instead, a higher level of integration was to use years. So next year’s Sapphire Rapids plus Ponte Vecchio platform becomes Phi22 for Phi and 2022, the year it will debut. Most likely someone at Intel has already said this is a bad idea, but a few beers in that was the suggestion.
Final Words
First off, I just wanted to say thank you to Raja for taking the time out of your evening (and early morning) to have several beers and walk through this. When the initial 1000x Zettascale claims came out, many were very skeptical. Aurora is still not installed and Intel is betting a lot on Ponte Vecchio and its completely new style of chipbuilding. Still, after speaking to Raja, it feels like Intel has what I would call its “Phi22” solution fairly well established and is now looking at how to execute an aggressive plan for the future. Frankly, Intel needs to have an aggressive plan here because if it does not, other companies will. Raja acknowledged the risks, but at least has a plan where there are many pieces the company already has solutions for in order to get to 1000x. Personally, I cannot wait until STH is reviewing 1 Exaflop solutions in our lab at only 50kW.


{kind=link}
What a cool article! Patrick explaining hardcore Intel stuff to mere mortals.
I don’t do chip design, I just buy clusters, but this is fantastic as an explanation for someone like me
Great interview or whatever you’d call this. What’d ya learn that isn’t on the pad?
When Intel originally said Zetta in 5 years I was skeptical. But the fact that Raja could do an impromptu napkin math and have a conversation about how they will get there with someone that knows the industry so well is very reassuring. Clearly Intel and Raja have a plan, and are working towards it. Intel has really started to turn things around, from consumer CPU’s to foundry services, to dGPU’s, doubling Aurora’s performance with ponte vecchio, SPR.
I think I now believe Pat Gelsinger when he said “Intel is back”.
The issue is that some of those boxes seem to be overlapping: “power and thermals”, if the goal is to keep the same power, then means either process or architecture improvements.
Photonics interconnect sounds cool and might get there as Intel is supposed to have PIUMA to try it out a bit before, but won’t give more than 4x throughput and 2x power.
I feel like they are more likely to get 16x total than 960x.
Ziple: I think the point is that they’re doing all of this at different scale than previously done. This doesn’t sound like a company looking to just get to 10-20x.
Do you have a second source for all of this? All I see is a pad and doritos
What does he mean by “16x invoices adopting similar math execution to what some others in the market are doing”? Using FP16 matrix operations as the metric rather than FP64? That is changing the rules of the game. If so, Intel’s Zettascale by 2026 means 64 EF of FP64 by 2026.
Kiko – This is directly from the executive at Intel responsible for developing and executing the strategy. While we may second source a rumor, this is a primary source.
Scott – I was told this is FP64 and not FP16.
Really interesting article. Must have been awesome to have that conversation with Raja!
STH headline in 5-6 yerars: “Exaflop at 50kW: We review the new Intel ‘Cool Ranch’ Platform”
Borris – it certainly was. This is only the part that I was able to print.
Guy – Super title! You are better at this than I am.
I thought, when CXL was announced, that it would play a big part in the Aurora design. Now it seems not so much. The first gen IPUs use pcie4, so apparently also are not going to use the CXL protocol. Any new info on expected contribution from CXL in the coming system architectures? Will we see cache coherence handled at some remote pool of memory, for example?
WOW. Just WOW. Thats STH at its finest!
JayN – I asked Raja about this. He said CXL would be more likely to intercept HPC in the CXL 3.0 generation.
Ok but now we need to see Intel deliver
This absolutely makes sense.
All skeptics should stop mocking Raja and Patrick Gelisinger. So leave all the past failures behind.
Don’t question Intel anymore about Aurora failure.
I’ll believe it when I see it.
Comments are closed.