
At Hot Chips 34, Intel discussed Ponte Vecchio, XMX, caches, and perhaps most importantly its vision for oneAPI and D++. Instead of kicking off the “chips” conference with silicon discussions, Intel instead has a heavy focus on the software side. That is important for entering a market dominated by NVIDIA and CUDA. We also get some new details about the upcoming Ponte Vecchio GPU.
Note: We are doing this piece live at HC34 during the presentation so please excuse typos.
Intel Ponte Vecchio with oneAPI Detailed at HC34
Intel started the talk with oneAPI. Intel’s biggest bet is perhaps that oneAPI will fulfill its promise. As Intel moves from a CPU company to an xPU copy, it needs to make it easy for developers to build software that can run on different CPU architectures.
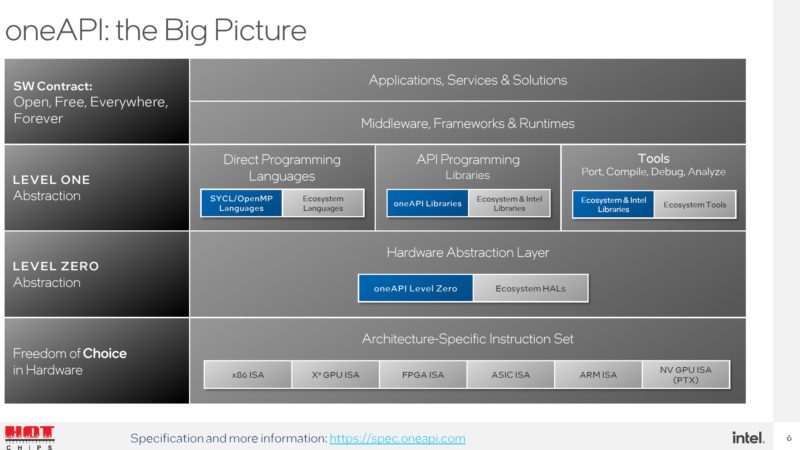
Intel has its low-level API’s designed for performance, but it also has Level-Zero APIs as part of the GPU driver.
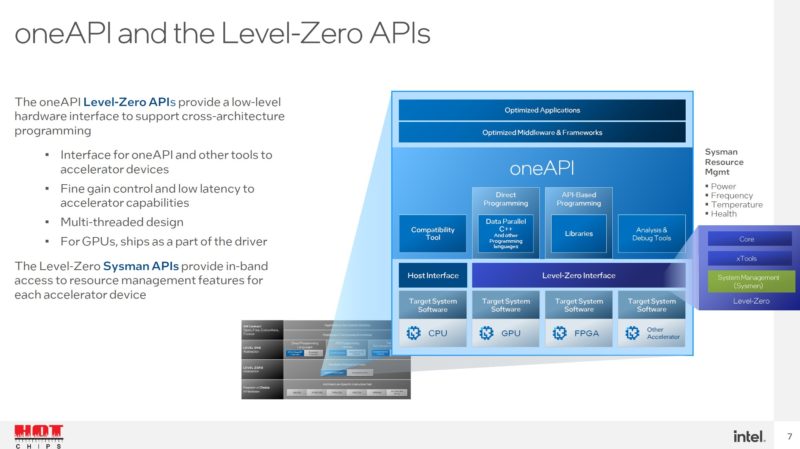
Intel DPC++ is a tool that migrates CUDA code to SYCL. There is so much GPU compute code written in CUDA, that companies like Intel and AMD are focusing on migration tools to help bolster their software compatibility. Intel says 90-95% of code will migrate without intervention.

Intel says the code generated is human readable. Make no mistake, Intel needs to get the software right, not just the hardware so this is a big deal.
Intel Ponte Vecchio at HC34
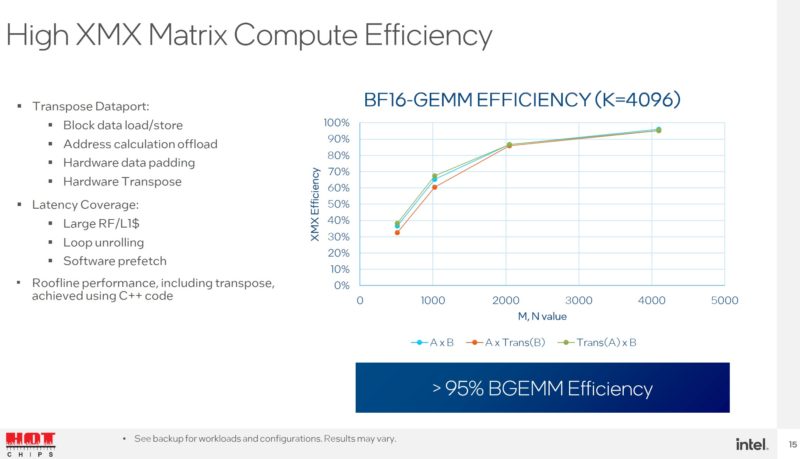
Intel published some throughput figures for Ponte Vecchio. XMX is a feature that is going to scale beyond just this GPU and is the company’s matrix operation engine. Intel said that these were being presented at 1.6GHz clock speeds. Intel also said Ponte Vecchio’s OAM is designed to be a 600W part.

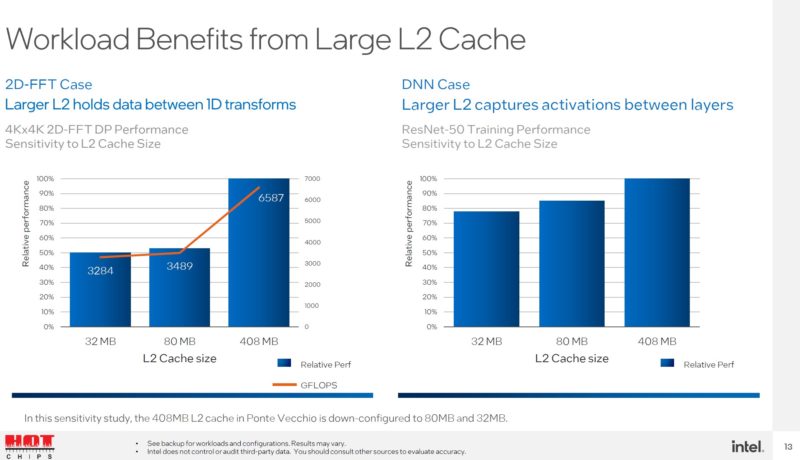
Ponte Vecchio has a lot of cache. Just looking at the cache sizes, Intel has huge register files and L1 caches. Each Xe Core gets 512KB Register File and L1 cache. The 408MB L2 cache is also relatively enormous for a modern GPU. The NVIDIA H100 has a 50MB L2 cache. These caches provide even more bandwidth. Intel is able to get to 408MB L2 cache because it is using Rambo cache tiles.

Below is a table with efficiency techniques that Intel is employing to efficiently use all of these caches and memory.

Intel is showing the performance benefits of the L2 cache. 2D-FFT uses a ton of memory bandwidth, and that is where Ponte Vecchio with more L2 cache shows a lot of benefits. The 32MB and 80MB numbers are from Intel tuning Ponte Vecchio to smaller cache sizes.
XMX is one to keep an eye on for future Intel processors. That is part of the Intel Xe HPC GPU and here are some of the efficiency techniques used in the GPU’s Xe Cores.

Here is an example of the efficiency due to the offloading.
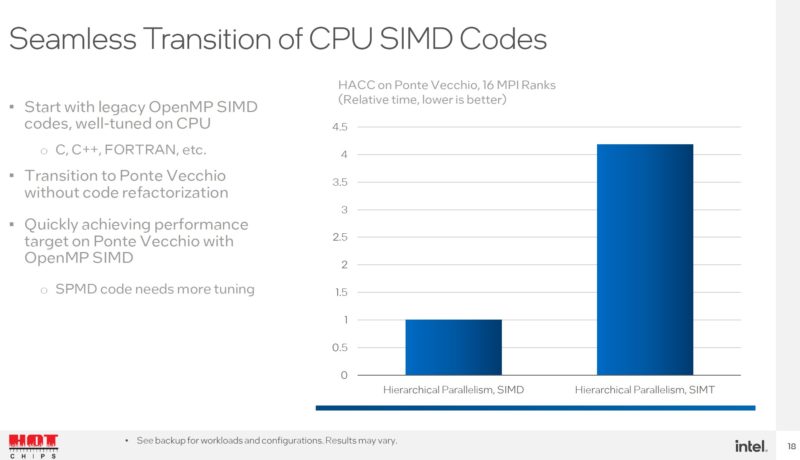
Ponte Vecchio supports both SIMT and SIMD. SPMD/SIMT are common for GPUs, while SIMD is more common for CPUs. There is a key at the bottom of this slide. Intel is using its SIMD model to help migrate HPC code from CPU to GPU.

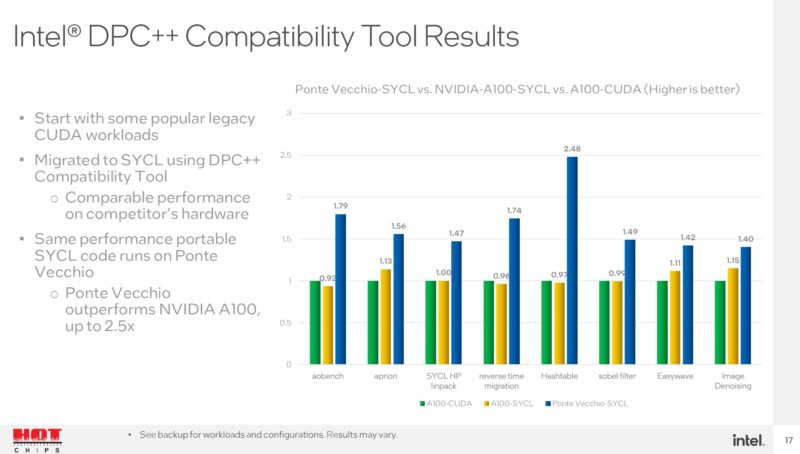
Transitioning back to the software side, Intel has a DPC++ compatibility tool. It says that running SYCL with an NVIDIA A100 gives similar performance to CUDA. Using that as a SYCL reference, with Ponte Vecchio, Intel has more performance. We will note that Ponte Vecchio is going to be in-market with the H100 more than the A100 at this point.
This is Intel showing SIMD codes.
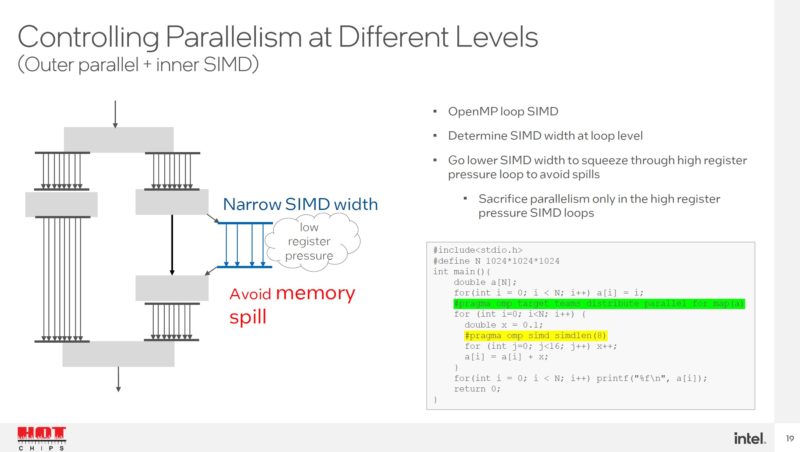
Intel can also lower SIMD width to lower register pressure and overall yield better performance.
The theme is again software.
Intel Ponte Vecchio XMX with oneAPI Performance at HC34
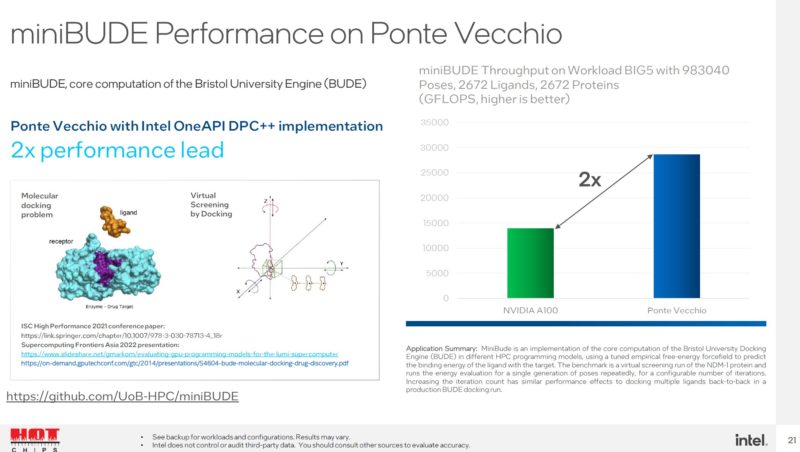
miniBUDE is a drug discovery application. Intel says it can be 2x the speed of a NVIDIA A100.
This is a major exascale project application. Intel says it is ~1.5x an A100.
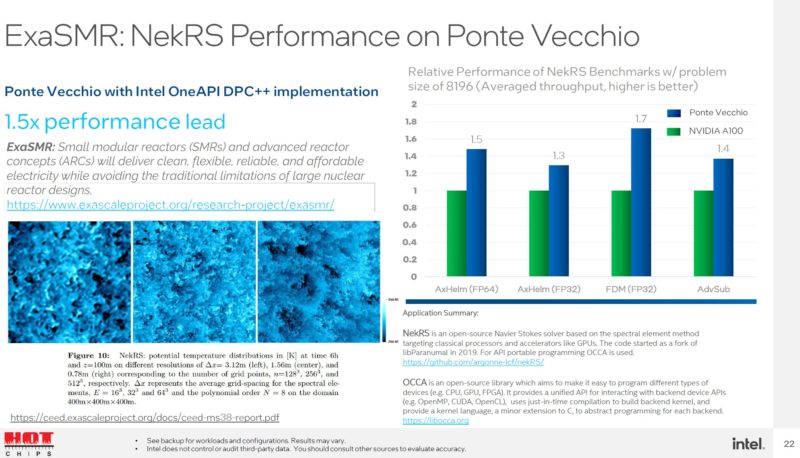
This is another exascale application, a Monte Carlo simulation. Here Intel says it can 2x an A100.
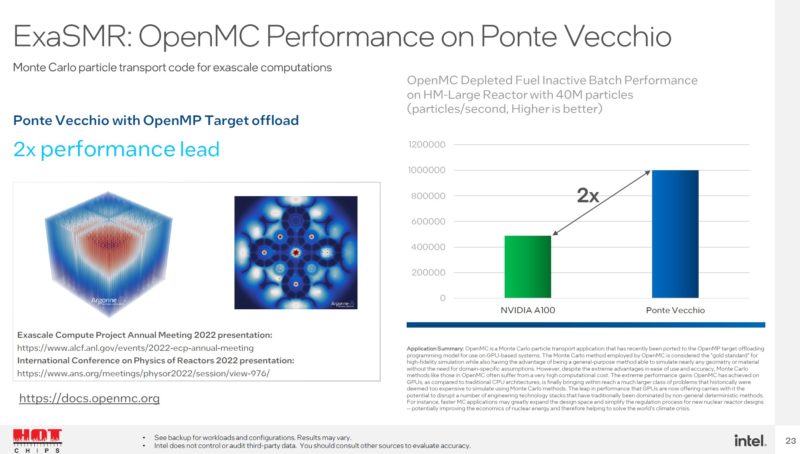
Perhaps the most interesting part of this section is the comparison. Intel is comparing Ponte Vecchio to the NVIDIA A100. Until the H100 arrives, the A100 is the industry standard. At the same time, with HPE and AMD Powered Frontier making a huge splash at #1 and with other systems in the recent Top500 June 2022, perhaps the MI250X is the top competitor for comparison at this point.
Final Words
At this point, I have held an Intel Ponte Vecchio GPU, but I really want to use one.

Intel needs Sapphire Rapids to come out for its PCIe Gen5 platform so that it can launch Ponte Vecchio. We have been seeing chips and proof points, but these need to come out in order to get Intel’s first exascale system running. At least Intel is putting a lot of focus on the software side since that is a huge component of bringing a new GPU to market in the data center space.


{kind=link}
“Intel DPC++ is a tool that migrates CUDA code to SYCL”
The CUDA translation utility is called the “Compatibility Tool”.
The DPC++ is a C++ compiler based on clang/llvm tools + SYCL + Intel extensions to SYCL.
One more typo in the very first sentence.
“At Hot Chips 34, Intel discussed Ponte Vecchio, XMX, caches, and perhaps most importantly its vision for oneAPI and D++. ”
D++ -> DPC++
Comments are closed.