
Update 2019-11-06 3:50PM Pacific: Update to the Intel Xeon Platinum 9282 GROMACS Benchmarks Piece – Please Read.
Today something happened that many may not have seen. Intel published a set of benchmarks showing its advantage of a dual Intel Xeon Platinum 9282 system versus the AMD EPYC 7742. Vendors present benchmarks to show that their products are good from time-to-time. There is one difference in this case: we checked Intel’s work and found that they presented a number to intentionally mislead would-be buyers as to the company’s relative performance versus AMD.
Background
For years, even through the 2017 introduction of Skylake Xeon and Naples EPYC parts, on the server side, the company has been relatively good about getting a balanced view. In late 2018, the company brought on a new team, allegedly to look over the performance benchmarks the company produced. That has culminated in the “Performance at Intel” Medium blog. This is described as:
“Intel’s blog to share timely and candid information specific to the performance of Intel technologies and products.” In only its seventh post, it has betrayed that motto.
Here is the post in question. HPC Leadership Where it Matters — Real-World Performance
Just to be clear, I know and personally like the Intel performance labs folks as well as the folks on their new performance strategy team. This is just a gaffe that needed to be pointed out since, in theory, Intel has taken to do more diligence now than when they were doing a good job in 2017.
Misleading with Benchmarks and Footnotes
First, here is a chart Intel produced as part of the story to show that it has superior performance to AMD, and we are going to highlight one of the results, the GROMACS result:
The reason we highlighted this result is because it looked off to us. A 400W 56 core part seemed a bit strange that is was 20% faster here.
The footnote on configuration details we followed eventually leading us to the referenced #31 corresponding to this result. Here is the configuration for the test:
GROMACS 2019.3: Geomean (5 workloads: archer2_small, ion_channel_pme, lignocellulose_rf, water_pme, water_rf):
Intel® Xeon® Platinum 9282 processor: Intel® Compiler 2019u4, Intel® Math Kernel Library (Intel® MKL) 2019u4, Intel MPI 2019u4, AVX-512 build, BIOS: HT ON, Turbo OFF, SNC OFF, 2 threads per core;
AMD EPYC™ 7742: Intel® Compiler 2019u4, Intel® MKL 2019u4, Intel MPI 2019u4, AVX2 build, BIOS: SMT ON, Boost ON, NPS 4, 1 threads per core. (Source: Intel)
We split the paragraph on the source page into three lines and will discuss the first, followed by the last two.
Using a Zen 2 Disadvantaged GROMACS Version
The first line is damning. Intel used GROMACS 2019.3. To be fair, they used the same version which makes it a valid test. GROMACS 2019.3 was released on June 14, 2019, just after the 2nd Gen Intel Xeon Scalable series. On October 2, 2019 the GROMACS team released GROMACS 2019.4. Keep in mind that it is over a month before Intel published its article.
In GROMACS 2019.4, there was a small, but very important fix for the comparison Intel was trying to show aptly called: Added AMD Zen 2 detection. Which says:
The AMD Zen 2 architecture is now detected as different from Zen 1 and uses 256-bit wide AVX2 SIMD instructions (GMX_SIMD=AVX2_256) by default. Also the non-bonded kernel parameters have been tuned for Zen 2. This has a significant impact on performance. (Source: GROMACS Manual)
In the industry, it is or should have been well known that older versions of GROMACS were not properly supporting the new “Rome” EPYC architecture. We cited this specifically in our launch piece since we found the issue. We even specifically call it out on every EPYC 7002 v. Xeon chart we have produced for GROMACS since the results did not meet expectations:
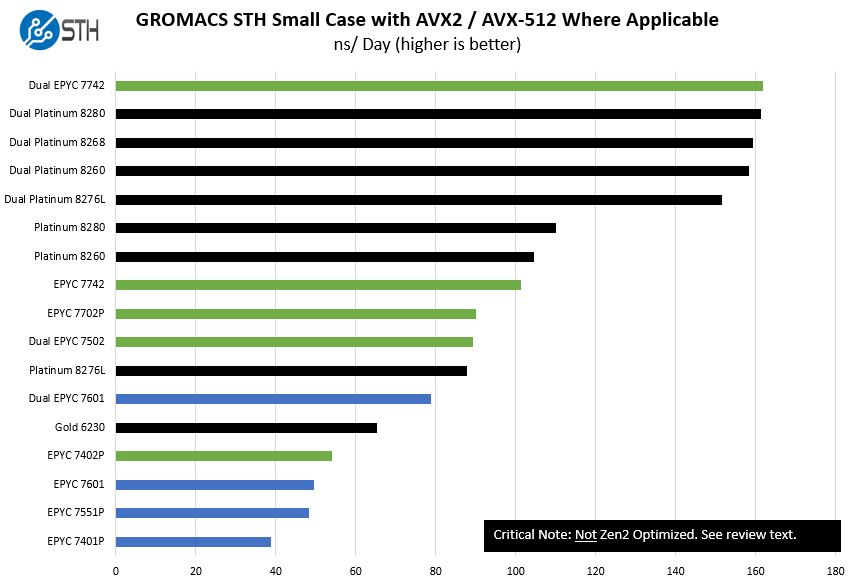
That is just one of our test cases which is considered a “small” case which is frankly too small for the size of these nodes. Still, the data was very easy to spot something was awry.
What Intel perhaps did not know, is that we also had one of the lead developers on GROMACS, a popular HPC tool, on our dual AMD EPYC 7002 system to address some of the very basic optimizations for the 2019.4 release. I believe there may be more coming, but this is one where we found the lack of optimization, and actually helped ever so slightly in getting it fixed.
By Intel using the post-2nd generation Intel Xeon Scalable version of GROMACS but the pre-AMD EPYC 7002 series which had been out for over a month, Intel’s numbers are highly skewed for the Platinum 9282 which only has a 20% lead.
Again, technically this was a valid test by using the same version. On the other hand, Intel specifically used a version that was prior to the package getting any AMD Zen 2 optimizations.
Test Configuration Discussion
Moving to the test configuration lines for Intel and AMD, here are the lines in table form for easier comparison:

Intel used its compiler, MKL, and MPI for this test. In the 2017 era, Intel tested Xeon and EPYC with a variety of compilers and picked the best one. We are going to give their lab team that runs the tests the benefit of the doubt here that Intel’s compiler and MKL/ MPI implementation yield the best results. Indeed, it is better that AMD does well than Arm for Intel since a customer staying on x86 is a much easier TAM to fight back against in 2021 for Intel.
The AVX status we addressed in the section above. Using AVX2 on GROMACS 2019.3 would have disadvantaged the AMD EPYC parts.
On both CPUs we see that there are two threads per CPU which means 56 cores/ 112 threads on the Platinum 9282 and 64 cores/ 128 threads on two AMD EPYC 7742 CPUs.
Then things change. Turbo was enabled on the EPYC 7742, but not on the Xeon Platinum 9282. In GROMACS, transitions in and out of AVX-512 code can lead to differences in boost clocks which can impact performance. We are just going to point out the delta here.
SNC is off for Intel but NPS=4 is set for AMD. Sub-NUMA clustering allows for each memory controller to be split into two domains. On a standard Xeon die, that means two NUMA nodes per CPU. Assuming it works the same on the dual-die Platinum 9282, it would be four NUMA nodes per package.
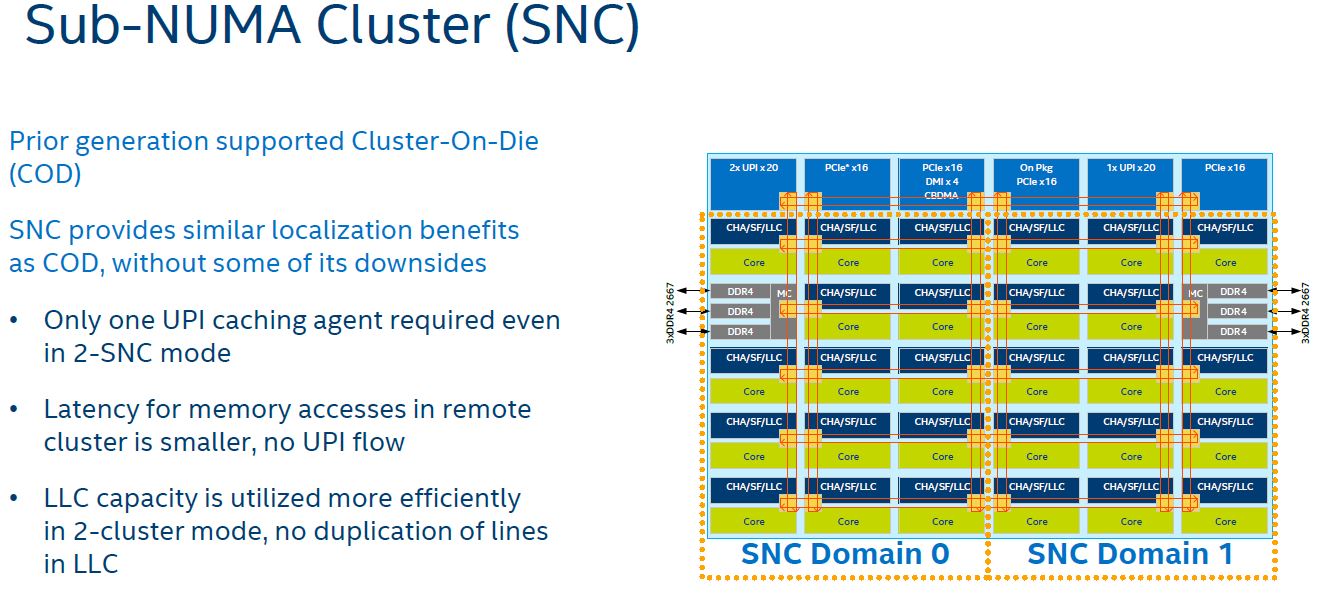
The AMD EPYC NPS setting is very similar as it allows one to go from one NUMA node per socket and instead select two or four. Here, Intel is running four NUMA nodes per socket, or eight total for the dual AMD EPYC 7742 system versus only two NUMA nodes per socket or four total on the Platinum 9282 system. SNC/ NPS usually increases memory bandwidth to cores by localizing memory access. What is slightly interesting here is how Intel characterizes GROMACS as being compute versus-memory bound.
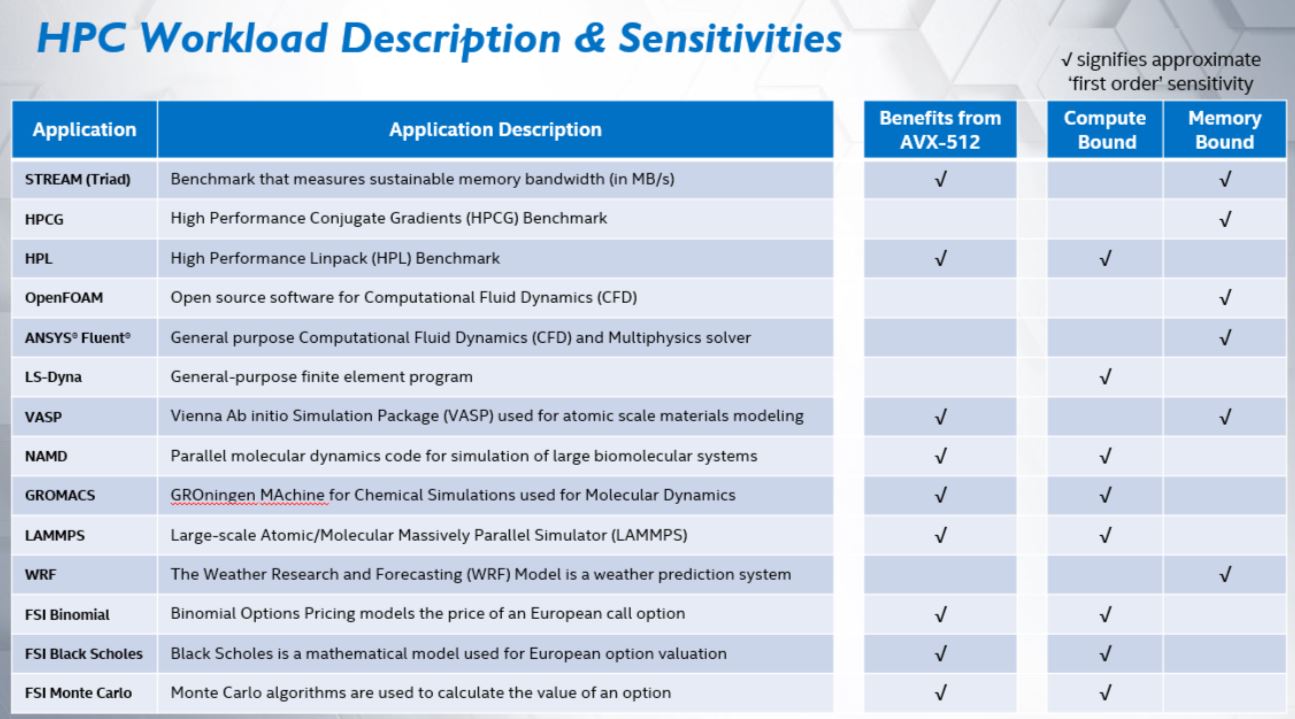
Finally, threads per core. On the Intel platform, it is 2. On AMD, it is 1. That means Intel is using 224 threads on 112 cores for the Xeon Platinum 9282 and 128 threads on 128 cores with 256 threads on the system. Putting the translation of configuration words into a table this is what Intel did with the test configurations:

What we do not know is whether Intel needed to do this due to problem sizes. GROMACS can error out if you have too many threads which is why we have a STH Small Case that will not run on many 4P systems and is struggling, as shown above, on even the dual EPYC 7742 system. It does require very solid thread pinning in this scenario of one GROMACS thread on a two-thread core otherwise performance can go poorly quickly with this configuration.
Even assuming that Intel software tooling is superior, Intel changed the boost setting, added more NUMA nodes for AMD, and used fewer threads per core than with Intel. Perhaps that is how Intel got the best results using an older version of GROMACS, but that is a fair number of changes.
Interesting Test Configuration Points
One of the other, very interesting points here is that Intel tested on a Naples generation test platform.
Here is the Intel configuration:
Intel® Xeon® Platinum 9282 processor configuration: Intel “Walker Pass” S9200WKL platform with 2-socket Intel® Xeon® Platinum 9282 processors (2.6GHz, 56C), 24x16GB DDR4-2933, 1 SSD, BIOS: SE5C620.86B.2X.01.0053, Microcode: 0x5000029, Red Hat Enterprise Linux* 7.7, kernel 3.10.0-1062.1.1. (Source: Intel)
Here is the AMD EPYC configuration:
AMD EPYC™ 7742 processor configuration: Supermicro AS-2023-TR4 (HD11DSU-iN) with 2-socket AMD EPYC™ 7742 “Rome” processors (2.25GHz, 64C), 16x32GB DDR4-3200, 1 SSD, BIOS: 2.0 CPLD 02.B1.01, Microcode: 830101C, CentOS* Linux release 7.7.1908, kernel 3.10.0-1062.1.1.el7.crt1.x86_64. (Source: Intel)
Intel is using 16GB DIMMs versus 32GB DIMMs for EPYC. They have different numbers of memory channels so we can let that pass. One item was very interesting, the test server. Intel used its S9200WKL which we covered in Intel Xeon Platinum 9200 Formerly Cascade Lake-AP Launched.

What is more interesting is the AMD EPYC 7742 configuration. Here, Intel is using the Supermicro AS-2023-TR4 that it shows is built upon the Supermicro HD11DSU-iN which is similar to the motherboard we reviewed in our Supermicro AS-1123US-TR4 Server Review server.

Most likely, it has to be a Revision 2.0 motherboard to support the EPYC 7002 generation and DDR4-3200 speeds. Being a H11 platform, it will only support PCIe Gen3, not Gen4. Again, this is an off-the-shelf configurable system that the socketed EPYC 7742 allows for versus the Intel-only Platinum 9200 solution. We explained why that is an extraordinarily important nuance in Why the Intel Xeon Platinum 9200 Series Lacks Mainstream Support.
The base cTDP of the EPYC 7742 is 225W as Intel notes in its article. Technically, the Supermicro server using a Rev 2.0 board is capable of running the AMD EPYC 7742 series at a cTDP of 240W. If someone was to compare, on a socket-to-socket basis, an EPYC 7742 to a 400W Platinum 9282, one may expect that pushing the cTDP up to 240W would be a common setting. Of note, in our testing, even with a cTDP of 240W the power consumption to TDP ratio for EPYC 7742 chips is much closer than the Platinum 8280’s AVX-512 power consumption to TDP ratio is. Extrapolating, there is a 100% chance that the EPYC 7742 is using considerably less power here to the point that cTDP should have been set to 240W.
In the main article’s text, Intel states 225W for the part and cTDP was not mentioned in the #31 configuration details. We are also going to note that there is a 280W AMD EPYC 7H12 part available, but it is unlikely Intel had access to this for internal lab testing at this point (STH has not been able to get a pair either.) That would have at least been a somewhat better comparison.
Finally, Intel is using a 3.10.0-1062.1.1 CentOS/ RHEL kernel. Newer Linux kernels tend to perform better with the newer EPYC chips but it is valid that Intel is being consistent even if it potentially disadvantages AMD.
Final Words
That was around 1800 words on a single benchmark that Intel presented. Should the text leave any doubt, personally I tend to give the benefit of the doubt to the folks in Intel’s performance labs since they did a fairly good job in the 2017 era. However, now those folks have a performance strategy team sitting above them that is publishing articles like this that have misses that a reasonably prudent performance arbiter should see.
One can only conclude that Intel’s “Performance at Intel” blog is not a reputable attempt to present factual information. It is simply a way for Intel to publish misinformation to the market in the hope that people do not do the diligence to see what is backing the claims. Once one does the diligence, things fall apart quickly.
The fact that Intel documented their procedures means that they had valid tests. It is just that the tests presented, and validated by the Performance at Intel team were clearly conducted in a way to misinform a potential customer about the current state of performance. This GROMACS example has been publicly known for almost four months and has not been current state for over a month. AMD does the same things as part of marketing e.g. AMD EPYC Rome NAMD and the Intel Xeon Response at Computex 2019 so it is, perhaps, par for the course. So perhaps the best course of action is to ignore these claims.
It was once told to me, “you only lose your reputation once in the valley.” With this, the “Performance at Intel” blog just had that moment. Perhaps in marketing, one gets multiple attempts.



{kind=link}
TL;DR of this is that Intel did some stuff they probably shouldn’t have, then posted it on a blog. They got caught. Patrick likes the Intel people but he’s calling for these people to stop.
Wow an outstanding article and a lot to digest. Thank you Patrick for your clear and forceful call out in a timely manner when shenanigans are going on. So useful to those considering buying decisions… Going to have to chew on this for a bit….
Let us know when they respond to this.
Server Jesus has spoken. Wowza.
I’m sure an oversight by Intel but if STH didn’t call them out so people would notice, nobody would’ve known the miss here.
I’d say the bigger picture question is what about the other benchmarks?
Patrick,
Can you please run GROMACS 2019.4 on Epyc 7742 (1P or 2P) and show the difference to 2019.3 (or to the version you used on the original Epyc2 review) ?
It would also be interesting to reproduce Intel’s setup/test with GROMACS 2019.3 because then we would have a baseline to compare all the other benchmarks in that slide. If you got X using their setup and X+50% using 2019.4 (with 256 threads and proper setup), then we could extrapolate for the other benchmarks too.
It makes me happy that there are still a few sites that do research and not pr copy-pasta.
So, where are the results?
Intel cheats at benchmarks. Go figure.
The work behind these articles takes some time. I wouldn’t be surprised if the did the benchmarks before Oct 5. I dont know if they keep a constant watch on the software for updates. How often do each of these update? I assume they’ll update it. I wouldn’t consider it misleading. Selling a 20k chip and saying it’s better than an Epyc is though.
James, if you are releasing performance comparisons against competition, then it is your due responsibility and diligence to make sure they are fair and up to date with any native expextations.
If you make a press release or akin and your benchmarks are now woefully out of date then you need to show clearly and up front that your benchmarks are a waste of time because they’re out of date.
This benchmark release is, frankly, flagrant disregard for decency in the comparison. Just because Intel put the footnotes in doesn’t make it any better, they went as far as disabling SMT, how much more is it to expect CCX/cores being disabled, where does it stop?
If the Intel ex-CEO told the world that the security holes were intended in Intel designs and Intel didn’t get sued, what else does matter, just an amazing world, isn’t it?
If the paycheck-collecting judge (might be on Intel’s payroll too) accepted Intel’s deleting its executives’ emails critically related to the lawsuit with AMD and overwriting the backup disk, what else does matter, just a wonderful world, isn’t it?
“On October 2, 2019 the GROMACS team released GROMACS 2019.4. Keep in mind that it is over a month before Intel published its article.”
Just to be clear, the all vendor benchmarks using a version of software older than 31 days is dishonest garbage?
@emile — SMT was enabled on the chip, it was software threads that were set different between the tests, not hardware threads per core.
@human — It might not be dishonest garbage, but it has been no secret that an update was made that added optimizations for AMD. So … at very best, horribly incompetent benchmark abilities from a company that we would expect an aweful lot more expertise from at best, intentional dishonest garbage at worst.
Take a pick.
Server chips are for data centers and enterprises, not consumers without the needed expertise, so if there are problems blame the data centers and enterprises themselves.
There is no complaint from Intel’s data center and enterprise customers, and they agreed with Intel that the security holes aren’t bugs but are intended in the designs and have been enjoying buying more to make up the performance loss caused by the security patches, haven’t they?
@James
> I dont know if they keep a constant watch on the software for updates.
@Human
> benchmarks using a version of software older than 31 days is dishonest garbage?
We can see from the settings that Intel apparently saw odd performance numbers on the 128C/256T Epyc and tweaked them quite a bit. What the first two things you usually do if you see software not performing as expected? 1. You check if there is a newer version 2. You google the problem. If Intel had done either, the resolution would have been obvious.
Intel does not employ amateurs. They knew exactly what they were doing.
“They knew exactly what they were doing.”
Yes, indeed. Using partial addresses benefits the performance, and it’s why according to the ex-CEO, no bug, the security holes are intended since the chips have been designed as intended.
After AMD coming back with competitive chips, people now have competitive choices, and it’s all up people themselves to choose what they like, even being cheated since some people do enjoy being cheated as long as it’s a bigger brand.
The real problem is GROMACS reliance on known unfair code from Intel in the form of the MKL, and other unfair libraries. What Inlet continues to do is illegal and they’ve been cited by the FTC for it and settled a case with AMD over the practice. Here’s a link to Agner’s (very basic) blog about all of this.
https://www.agner.org/optimize/blog/read.php?i=49#1006
I’ll quote Agner on the issue here: “… Intel is supplying a lot of highly optimized function libraries for many different technical and scientific applications. In many cases, there are no good alternatives to Intel’s function libraries.
Unfortunately, software compiled with the Intel compiler or the Intel function libraries has inferior performance on AMD and VIA processors. The reason is that the compiler or library can make multiple versions of a piece of code, each optimized for a certain processor and instruction set, for example SSE2, SSE3, etc. The system includes a function that detects which type of CPU it is running on and chooses the optimal code path for that CPU. This is called a CPU dispatcher. However, the Intel CPU dispatcher does not only check which instruction set is supported by the CPU, it also checks the vendor ID string. If the vendor string says “GenuineIntel” then it uses the optimal code path. If the CPU is not from Intel then, in most cases, it will run the slowest possible version of the code, even if the CPU is fully compatible with a better version.
I have complained about this behavior for years, and so have many others, but Intel have refused to change their CPU dispatcher. If Intel had advertised their compiler as compatible with Intel processors only, then there would probably be no complaints. The problem is that they are trying to hide what they are doing. Many software developers think that the compiler is compatible with AMD processors, and in fact it is, but unbeknownst to the programmer it puts in a biased CPU dispatcher that chooses an inferior code path whenever it is running on a non-Intel processor. If programmers knew this fact they would probably use another compiler. Who wants to sell a piece of software that doesn’t work well on AMD processors?
Because of their size, Intel can afford to put more money into their compiler than other CPU vendors can. The Intel compiler is relatively cheap, it has superior performance, and the support is excellent. Selling such a compiler is certainly not a profitable business in itself, but it is obviously intended as a way of supporting Intel’s microprocessors. There would be no point in adding new advanced instructions to the microprocessors if there were no tools to use these instructions. AMD is also making a compiler, but the current version supports only Linux, not Windows.
Various people have raised suspicion that the biased CPU dispatching has made its way into common benchmark programs. This is a serious issue indeed. We know that many customers base their buying decision on published benchmark results, and a biased benchmark means an unfair market advantage worth billions of dollars. ”
The most generous way to put it is that GROMACS did not do their homework and are seriously underepresenting the performance of AMD Rome chips as a result. A more cynical view is that GROMACS is being positively or negatively “incentivized” by Intel to knowingly publish unfair results from AMD-crippling libraries in a bid by Intel to underepresent Rome’s performance and hold off AMD’s competitive CPU’s from gaining wider market share. Since Intel clearly sees AVX-512 as one of their very few competitive advantages over Rome, the cynical take is sadly very plausible.
Hi! Can someone explain this like I’m five please (ELI5)? Or point me in the direction to learn and understand what this means? I’m generally pretty tech savy but I don’t think I understand all the implications this post is alluding too. Thanks -James (:
James if you’ve read the update as well here’s the short version:
— Intel published benchmarks citations that were off the chart and hard to find describing what they did
— In those benchmarks, Intel was sloppy and had a typo that said they only used half the threads available on AMD. STH got them to update and confirm they really used all the available threads.
— Intel still used its compiler and software stack that is much better tuned for Intel and has a history of de-tuning performance on AMD.
— Intel used an older version of the GROMACS software that didn’t correctly support AMD CPUs but they did some changes to get that performance back with AVX2. They later confirmed in testing that what they did worked, or at least gave similar numbers using Intel software.
— Intel did a lot of changes to boost settings and such on their CPU while doing other changes on AMD like making the chips appear as 8 CPUs instead of just 2.
— Intel is running AMD chips at 225W of power when they’re capable of running at 240W with a BIOS setting.
— Intel is using that not fully tuned AMD 225W CPU against a 400W CPU of its own that it changed boost settings on which is what is impacted by 225 instead of 240W.
— The Xeon Platinum Intel is using in comparison is not socketed, and is sold only affixed to an Intel motherboard. The AMD EPYC is available from systems from almost every OEM.
— The Xeon Platinum costs 3x the EPYC chips they are comparing to.
— They didn’t say they were using it, but they’re using air cooling on AMD and most probably water on the Intel system.
Even with all that they’re getting only like 30% more performance. Now that they’ve updated to fix the mistake they made after these guys pointed it out, and are claiming it’s fair.
The reason that everyone’s still pissed at Intel is really because they’re comparing a 3x the price, hard to get part, that costs more to operate, and requires water cooling to a standard AMD part. In that comparison they only won by 30% including running the AMD chips at 225W instead of 240W that they are capable of.
I contend that the GROMACS 19.4 retest did not properly use AVX2 instructions for the Rome chip, because Intel claimed no performance improvement vs. running 19.3 that does not support AVX2 despite GROMACS and STH indicating performance gains from 19.4. In addition, there’s a lovely little post you may have heard of on Reddit from Nedflanders1976, which indicates that his patch to force the MKL to run in AVX2 mode on Ryzen chips demonstrates 20-300 percent improvement on MATLAB using the MKL indicating that performance improvements are there when forcing Intel’s libraries to behave fairly toward non-Intel chips as required by law. This raises the question of whether Ryzen AVX2 is actually faster than Intel’s AVX512 on latest available chips as some testing had shown.
Thank you again for bringing these shenanigans to the public’s attention, Patrick. Can’t wait to see your GROMACS tests using fair compilers and libraries.
Comments are closed.