
Intel, NVIDIA, and Arm are all competitors, but they are also collaborators. That is what makes the three companies joining together to announce a FP8 format for AI so special. The new numerical format should help increase the performance of modern AI systems with minimal loss over using FP16, but with an added nuance of complexity.
Intel, NVIDIA, and Arm Build a Common FP8 Format for AI
FP8 traditionally struggles with range and accuracy just because it is a smaller format. As a result, companies have offered that FP8 needs two variants E5M2 and E4M3. Here “E” is for the exponent, and “M” is for the mantissa, with the number being the number of bits for each. Here is the table from the joint paper that the three companies published showing the reason for having two FP8 values:
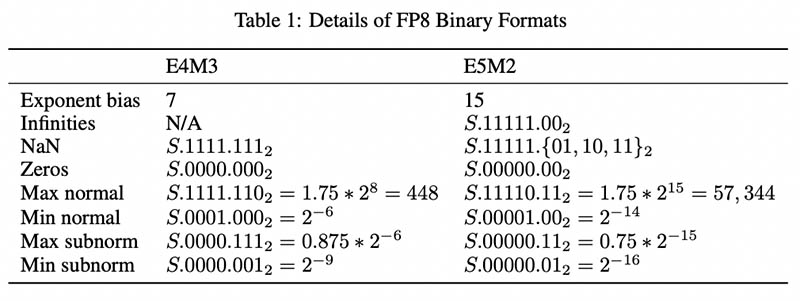
Here is a version explaining the impact, and how NIVIDA chooses between E4M3 and E5M2 mode in its new H100 product line.
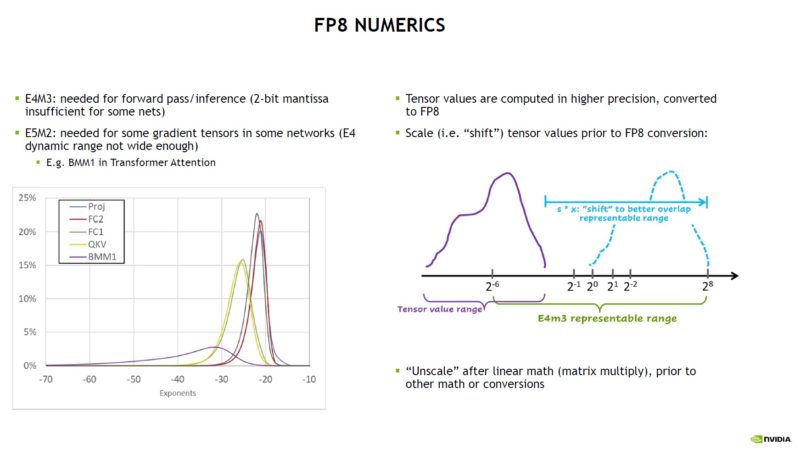
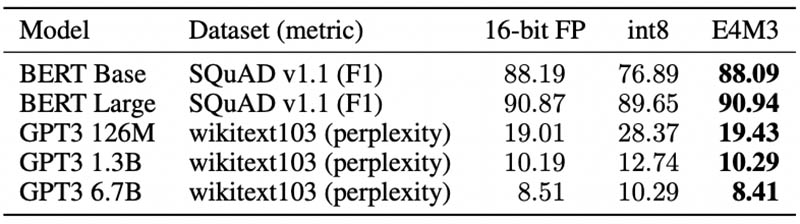
The trio of companies also ran various workloads using the different formats and found that accuracy closely matched FP16, and was certainly closer than INT8. As a result, the idea is that FP8 can be used to more quickly access FP16-like accuracy but with less computational and storage overhead as a smaller number format.
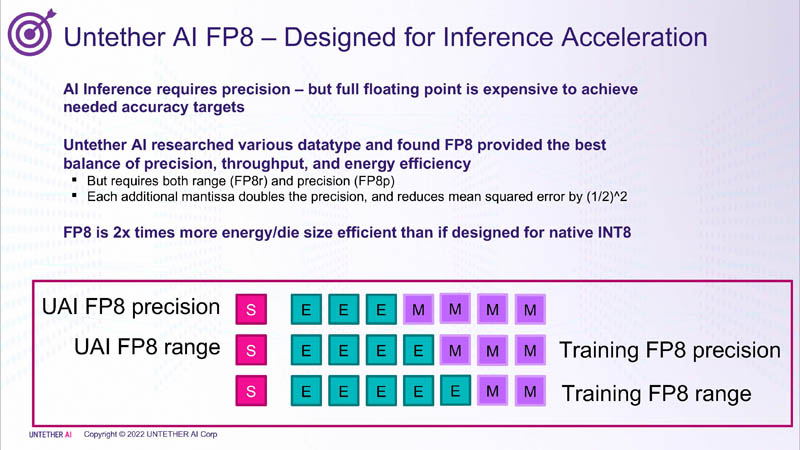
The three companies said that they tried to conform as closely as possible to the IEEE 754 floating point formats, and plan to jointly submit the new FP8 formats to the IEEE in an open license-free format for future adoption and standardization. That is important as we have seen other companies like Untether AI at HC34 tout the benefits of a similar E4M3 and E5M2 format, but with its own spin (e.g. E3M4.) This is a good reason for an interoperable standard so that acceleration can become uniform.
NVIDIA is already using the FP8 in its H100 Transformer Engine and that helped power its latest MLPerf Inference v2.1 results. Intel for its part says it plans to support FP8 in not just Habana Gaudi products, as we covered in Intel Habana Gaudi2 Launched for Lower-Cost AI Training. It also says it will support the format in future CPUs and GPUs. Arm says it expects to add FP8 support to the Armv9 ISA as part of Armv9.5-A in 2023.
Final Words
On one hand, this is new innovation in terms of numeric formats. Just as we found earlier that moving training tasks from double precision to half precision yielded similar results, just with massive speed-ups, FP8 should do the same thing. Part of the benefit is only having to compute on 8 bits of data rather than 16. The other part is really that 8-bit data is smaller to store and to move around in a system. Memory and data movement are expensive in modern systems, so new numerical formats can lessen those as well. This is similar to how the industry decided on bfloat16 as a new format.
We are excited to see this new standard roll out to the industry in the future. Some may ask about AMD, but our sense is that Intel, NVIDIA, and Arm all support a standard, AMD will eventually adopt it as well. We have seen this in other areas in the past.



{kind=link}
At what point does the HAL 9000 just flip a coin? // 1-bit precision
Wow. What an “innovation”.
8 bits is easier to store than 16 bits. Who would have guessed that ?
Have they patented this or perhaps they are waiting for Nobel’s Prize first ?
What is supposed to be innovation here ?
And how much floating can that floating point even do within 8 bits total.
Everyone that has ever written assembly for 8-bit micros can tell you that tailoring the data to fit the problem and available resources is fundamental step.
First you impugn the idea that there is innovation going on and then you turn around and give a reason of why it is in fact innovative. As you noted, the innovation is not in making 8 bit FPUs, but in making software that uses them effectively.
As far as being “first”, again, that’s not the point. The point is there are no established FP8 standards with the features necessary for the task. Different architectures could implement the concept in different ways, complicating frameworks and hindering interoperability.
Is that the same or different from the AMD/graphcore/Qualcomm proposal from a few months ago?
AMD (along with Graphcore) already made a proposal for the standard. I’m not sure what the differences are, though. But they’re not just sitting back and letting Nvidia, ARM and Intel take the lead. https://www.graphcore.ai/posts/graphcore-and-amd-propose-8-bit-fp-ai-standard-with-qualcomm-support
Comments are closed.