
This is a Friday afternoon release if I have ever seen one. In a news brief today, Intel made major changes to its HPC efforts until at least 2026. Or more succinctly, Intel has announced that the current Xeon Max, based on Sapphire Rapids with HBM, and its Ponte Vecchio OAM GPU are effectively the last of that legacy “pre-XPU” HPC platform architecture (Please see the update).
Intel Announces it is 3 Years Behind AMD and NVIDIA in XPU HPC
Intel did not say the above, or put it in a new roadmap, but parsing the announcements:
- Rialto Bridge is discontinued
- The next Max Series XPU/GPU will be Falcon Shores in 2025
What this effectively means is that Intel will not have a new GPU offering between now 2023 and 2025.
Update: Intel contacted us to clarify its roadmap. Falcon Shores 2025 will be a GPU architecture, not with CPU cores. Intel told us that the vision for Falcon Shores is still XPU, but 2025 Falcon Shores is GPU focused. The “traditional” part is a GPU-only offering, Falcon Shores will offer different IP blocks as part of an overall XPU offering, but that will not be the 2025 generation.
In 2025, we get Falcon Shores which was supposed to co-package CPU cores, GPU cores, memory, and other IP, potentially other accelerators, and even Lightbender silicon photonics. Intel has also shown plans for CPU tile only with co-packaged memory Falcon Shores.

Taking stock of what that means for the traditional HPC architecture of CPUs sitting in sockets attached to accelerators like GPUs, that model is effectively discontinued, except at Intel.
AMD Instinct MI300 (2023) will have CPU, GPU, and memory co-packaged.

NVIDIA Grace Hopper (2023) will have CPU, GPU, and memory co-packaged and the ability to have CPU-only packages.

Intel’s next-gen HPC part Falcon Shores (2025) was supposed to have CPU, GPU, and memory co-packaged.

It still may, but not at Intel by 2025.
The subtext to today’s announcement is that Intel and its customers see the need for this co-packaged architecture, to the point where Rialto Bridge was not set up to be a big winner. Intel is instead focusing on GPU-only Falcon Shores for 2025. That means until 2026 NVIDIA and AMD are ahead in that next-gen architecture.
For those wondering about the benefits of co-packaging memory, CPU, and GPU, it is the same that is occurring with the Apple M1/ M2 in many ways.

Moving data from CPU memory to GPU memory and vice versa requires potentially duplicating data leading to more wasted memory, but more importantly, is the power. Last week we featured AMD Talks Stacking Compute and DRAM at ISSCC 2023. The power used to move data between sockets and even between CPU sockets and DIMMs while also increasing speeds is a major challenge.
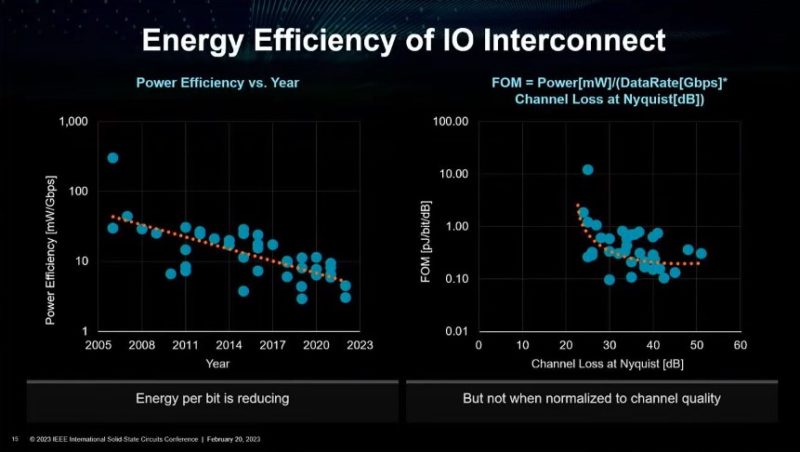
As a result, co-packaging CPU, GPU, accelerators, and memory using more advanced methods is seen as a way to increase interconnect speeds at a different power curve than traditional separate components.
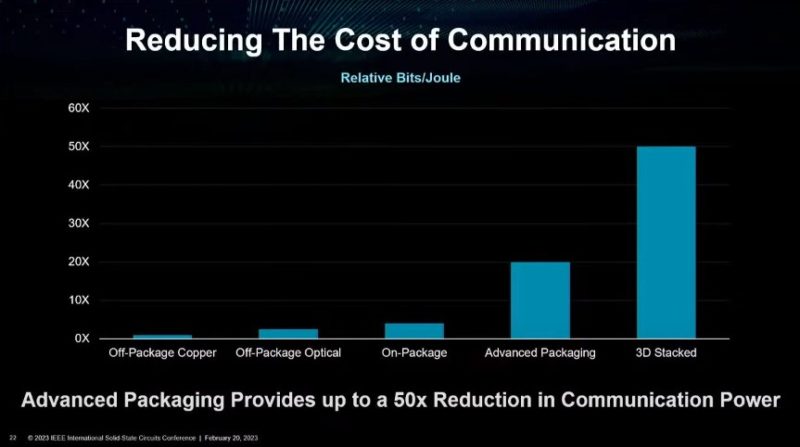
In large-scale HPC systems, a huge amount of power is used simply moving data around within nodes, and externally. The reason we have AMD, NVIDIA, and now Intel saying next-gen HPC GPU architectures will have co-packaged components is to minimize this “wasted” power use. That in turn allows for more of the power budget to be used for doing computation, rather than moving data around.
Final Words
The HPC market is sizable, but it is also only a portion of the overall computing market. We still expect there to be PCIe and OAM GPUs and so forth for years to come. It just seems like this trend is accelerating for the HPC space to the point that Intel is going to skip a generation. That will save development resources, but it also means that Intel will be using Ponte Vecchio to compete against the NVIDIA H100, NVIDIA Grace-Hopper, and AMD Instinct MI300 for the next two years until Falcon Shores is hopefully ready in 2025. This announcement also means that it is planning its 2025 Falcon Shores XPU to really be a GPU with the possibility of having customized IP blocks in the future.

In addition, Intel announced that it is discontinuing Lancaster Sound, the next-gen Flex series GPU, making the next-generation of record Melville Sound.


{kind=link}
XPU, reads like another cyclical rehash of i286 with i287 coprocessor, reduced to i386DX with built in FP unit, a sort of return of the CISC/RISC comingling/hybrid effort. Perhaps a decade from now, a fresh idea will arise using a separate CPU and FPU/GPU/… what is old, new again.
So essentially we will not see any more Xeon Max Series CPUs for a few years? They will only release a Max Series GPU in 2025 (Falcon Shores)? And then move to co-packaging memory, CPU, and GPU for the next release, maybe in 2027 (2 year cadance from 2025)?
If I understand that right there won’t be a new Max Series CPU until 2027, but please correct me if I am wrong…
“…will not have a new GPU offering between now 2023 and 2025”
Do they need one? Looks like Ponte Vecchio is leading in the tiled architecture and the 408MB L2 cache. When will the competition catch up with that?
Emerald Rapids will reportedly have Raptor Cove cores. Intel announced they will have an HBM version of it. Whether that will be an upgraded HBM is still a mystery.
I read some articles saying the HPC guys want to move away from the heterogeneous nodes to disaggregated CPU and GPU nodes, then tie everything together with DPUs. I understand the power concerns when you go off chip, but eventually you have to go off chip … right? Looks to me like there could also be a good case from the compute in memory proponents that what you really need in each package is a processor surrounded by as much memory as you can get in there.
JayN with his typical buzzwords trying to bamboozle people. PV is losing in power perf to two year old products from nvidia and amd and you are still bloviating about how Intel is ahead in roadmaps and paper specs. Pathetic.
So they’re turning the XPU into a GPU but still calling it the XPU. They’re just lying now. Rialto was doomed by PV delays. There’s no execution now.
I don’t see this as a big issue. A lot of customers are sceptical of putting all their eggs into the Grace:Hopper ecosystem and paying thr Green Tax, or that of MI300 and having unreliable operations.
Just looking at public benchmarks, it’s a 3 horse race for HPC, and the two front runners are still Intel and AMD due to the nature of workloads not always being suitable for GPU acceleration – a huge portion of HPC workloads are single threaded and not parallelised, and that’s because of the data and scientific workflow, not code inefficiency.
If Intel rushes their next-gen GPU, then are they really going to benefit from it, when their first task should really be building the software ecosystem?
I think this is a great call.
Lol so tldr of it —
they’re saying next is XPU.
STH says XPU 2025
Intel says our XPU 2025 is now GPU only
STH says so you’re 3yrs behind Nvidia and AMD
Nice by STH to use an announcement of a discontinued product to pry confirmation that Intel’s XPU schedule slipped to 2026. I know we’re set to deploy MI300 in a few quarters.
I’m always more scared that they’re going to have Patrick run Xeon and we lose STH. Pat G’s gotta clean that side first.
“The two front runners are still Intel and AMD due to the nature of workloads not always being suitable for GPU acceleration”
Way to completely miss the point of HPC platforms.
Very strange.
Why was Rialto Bridge canceled? Why is Falcon just a GPU? No good explanation.
Will potential Intel GPU customer develop for/with oneAPI if first party hardware roadmap is changed like this and third party HW support is not that good?
On one hand, an XPU can be viewed as the result of adding HBM to an APU. This seems totally reasonable, as memory bandwidth is often the limiting factor. Moreover, HBM is meant to be integrated closely with a CPU.
On the other hand, an XPU can also be seen as a Xeon Max mushed together with a GPU. Since a GPU is designed to run independently of the CPU the advantage of placing both on the same package is less of a win. This is more like what happened when an x86 CPU was combined on chip with an x87 FPU to obtain the 486DX. Tighter integration of floating point into the instruction set in the form of SSE and AVX was needed later for performance.
I’ve seen little presented on Ponte Vecchio’s performance, but the 839 TFLOPS BF16 matrix processing number in this IXPUG presentation doesn’t seem insignificant to me, since FB promoted this format for training.
https://www.ixpug.org/resources/download/keynote-new-era-for-intel-hpc-acceleration-architecture-systems-software
Meanwhile H100 from Nvidia hits 2000TF using a fraction of the power and has been on the market for years, you clown.
JayN, go back to Reddit and WCCFTech, where trolls like you chat.
@JayN While the 839 TFLOPS BF16 are all fine and dandy, there are multiple issues with Ponte-Vecchio as is. As n7pdx rightfully points out, the H100 provides ~2000 TFLOPS BF16, while consuming much less energy, and providing the more mature programming model (CUDA). On FP64 performance (which is what counts in HPC) Ponte Vecchio seems to be just ever so slightly faster than AMD’s 1 year old Mi250x, while at the same time consuming roughly 200 Watts more.
Ponte Vecchio in general is an absolute power-guzzler, and is hence not a competitive arch compared to NVIDIA’s and AMD’s solutions in the market. If you compare Frontier, the AMD-based Exascale machine in Oak Ridge, to the unfinished Aurora, the Ponte-Vecchio based exascale machine at Argonne National Laboratory, then Aurora requires a power envelope of 60MW!!!! whereas Frontier only needs 30, while just being slightly behind in performance.
My understanding is that the footnote on the H100 saying
* Shown with sparsity. Specifications are one-half lower without sparsity.
https://www.nvidia.com/en-us/data-center/h100/
means the SXM H100 reaches 989.5 BF16 TF (PCIe card 756 TF) on dense arithmetic.
There is no similar footnote for Ponte Vecchio. However, the observed performance of a system as a whole when doing a particular customer’s work is anyway much more relevant.
In general real performance is not easily discerned from GPU specs but rather by trying out evaluation hardware (for example, in a vendor-run cloud) and the kind of testing done on STH. Along these lines, having a greater variety of application-based GPU benchmarks that illustrate 16, 32 and 64 bit float and integer sizes would be a great addition to the current test suite.
In my opinion it would also be nice to include CPU results in the comparison as there appears to be some overlap between a CPU with HBM compared to a GPU.
Ponte Vecchio compute tiles are built on TSM N5, so performance per watt should be comparable to other chips built on the same node.
Aurora incorporates PCIE5, DDR5, Optane, CXL, in-package HBM on the CPUs… and so you would expect the higher data rates to use more power than, for example, the Frontier PCIE4/DDR4 computer.
Argonne also estimates the performance to be >2EF FP64.
H100 is the Hopper box, right? It entered production last Sept, so how has it been on the market for years?
NVIDIA’s Ampere architecture has been out for years and here you are bragging about a product that has not even been released.
And as usual you are totally clueless on power/perf metrics: it is performance NORMALIZED. If Ponte Vecchio was able to achieve higher performance with same power, it would be ahead of competition. Alas, it is behind on performance with higher power.
“Ponte Vecchio compute tiles are built on TSM N5”
Delusion Intel bag-holder still clinging onto the myth that fabrication technology is the only differentiator.
thw reporting comments from Wang Rui that Intel 20A and 18A are doing well and have been moved up to 1H 2024 an 2H 2024, respectively.
Article says these both incorporate PowerVIA and GAA.
When will NVDA and AMD move to 18A?
Intel isn’t even achieving HVM for Intel 4 until the very end of 2023 and here you are regurgitating their roadmap slides. Sad.
Meanwhile, from that article: “This does not mean that the production nodes are ready to be used for commercial manufacturing, but rather that Intel has determined all specifications, materials, requirements, and performance targets for both technologies.”
Translation: they wrote their paper spec for 20A. Nice try. Got any more FUD today?
While Ponte Vecchio’s peak FP64 is comparable to AMD’s Frontier chip, the IXPUG article I posted shows the sustained performance advantage of the 408MB of L2 cache, courtesy of the Foveros 3D fabrication.
It’s a nice advantage, perhaps comparable to AMD’s 3d V-Cache feature, but with 288MB of it going in the base tile, instead of being mounted on top.
One other feature mentioned in the IXPUG presentation is the ability of Ponte Vecchio to optionally execute SIMD code. The implication was that it could effectively run CPU AVX code, with little modification, on the GPU.
I’d like to see some coverage of this feature, whether or not it performs well when moving code from CPU to GPU.
@JayN The watt-specifications for AMD’s Mi250x, and Intel’s Ponte Vecchio are public, so it is a fact that Intel’s PV consumes 200 Watts more. As is the fact that Aurora is slated to consume 60MW, while Frontier gets away with 30MW.
Re all the fancy tech in Aurora, it is all cool tech on slides, but the machine is a) not deployed, and b) no one really cares that much about the fancy tech but about the performance a machine delivers, and how easy it is to adapt applications onto such a large machine. The rest is just marketing slides, which are irrelevant to HPC practitioners (the people who actually use this machine).
And no, Aurora is NOT >2EF FP64, Aurora is >2EF PEAK. Which are two completely separate metrics. Frontier has 1.7EF Peak while consuming half the energy btw.
The A100 GPUs have been out for years. They only execute 312 TF BF16.
The H100 full production was announced by NVDA last Sept. It was also announced at 700W TDP for their fast one… not a power sipper.
Actually, their 2000TF BF16 is “effective” performance, apparently counting pruned operations. Looks like their estimated peak 1000TF BF16 would be the number to compare with Ponte Vecchio’s 839TF, from the IXPUG presentation.
https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
Re the SIMD execution, yes Ponte-Vecchio is able to “single-pump” across its entire vector units, while AMD for example is “double-pumping” across the two compute complexes on the Mi250x. This is apparently a driver restriction on AMD’s side, which they could patch away, but for now Intel is the only one who is single-pumping.
the thw article on 18A says “Intel’s 18A manufacturing process will further refine the company’s RibbonFET and PowerVia technologies, as well as shrink transistor sizes. Development of this node is apparently going so well that Intel pulled in its introduction from 2025 to the second half of 2024.”
I read that as a 6 month pull-in on their 18A schedule …
“One other feature mentioned in the IXPUG presentation is the ability of Ponte Vecchio to optionally execute SIMD code. The implication was that it could effectively run CPU AVX code, with little modification, on the GPU.”
You have no clue what you are talking about. Chopping up GPU registers into smaller pieces to run smaller data formats to reduce register pressure has nothing to do with AVX whatsoever. Get a clue.
The IXPUG presentation on PVC refers explicitly to
“Common CPU Programming Model”
“Seamless transition from well-tuned
CPU code”
This is under the SIMD heading on p22.
This is the feature I’m interested in.
Quit pretending to have any idea what you are talking about and go back to your buzzword soup.
@ n7pdx you literally have no clue of the HPC industry, and you clearly don’t work in the industry, and have never designed or deployed one.
Everything you say is just data from spec sheets. Leave the computer science up to us, and go play Crisis in your parents basement.
One thing I love about working in HPC for 2 decades is that it’s rare to come across losers like you in the wild….
@L.P. The TDP of an MI250x is 560W (they actually republished this above the initial 500W in their early tech notes), and the TDP of a Ponte Vecchio is 600W on their higher end Intel Data Center GPU Max 1550.
The TDP of H100 SXM is 700W. I think you’re mistaking the chips…
Additionally, the rMax of Frontier is 1.1 EFLOPS, and we do not know the rMAX of Aurora – please, don’t try to use rPeak as a justification as that’s ignorant and system dependent.
Frontier has a 1:4 CPU to GPU ratio, and a 68% efficiency ratio for HPL scaling.
Aurora has a 1:3 ratio, and this would be one factor to lead to higher power consumption and also the potential for higher efficiency ratings – it’s more likely this could be driven by the greater network bandwidth feeding the nodes.
One other thing with Aurora, which everyone is forgetting, is the eight DAOS points ‘per node’ which uses Optane Memory – that’s a lot of power there, and it’s essential for exascale systems to use this for a burst buffer to improve application IO (nobody knows the effect this has on a synthetic HPL benchmark).
Aurora could and will do different science to Frontier.
All in all, the MI250x is phenomenal for HPC, so is Intel Ponte Vecchio based on the benchmarks Argon presented at SC22, and the H100 is too.
Performance per Watt is easy to calculate. Maybe do that first?
One last thing – It’s obvious that NVIDIA is focused on FP8 and BFLOAT16 as this is great for DL and your energy consumption per calc. While it’s fantastic for AI workloads, and will drive their growth with non HPC customers, Supercomputer facilities will lean into this for using AI to predict variables in simulations, and make a scientists life easier (and more energy efficient).
Intel: ” ‘Falcon Ridge’ means exactly what we say it means, and it will continue to do so as we change what it means.”
I expect that Intel stock will reprise AMD’s stock performance between 2009 and circa 2021. Money to be made. But it looks like the bottom won’t be reached for a while yet.
The SC 2023 announcements include Rick Stevens saying Aurora is the perfect environment for running training and inference for the 1 trillion parameter AuroraGPT llm for science.
Comments are closed.