Inspur NF5468M5 Power Consumption
Our Inspur NF5468M5 test server used a quadruple power supply configuration, and we wanted to measure how it performed using the Intel Xeon Gold 6130 CPUs provided in the configuration we were sent.
- Idle: 0.71kW
- STH 70% Load: 2.5kW
- 100% Load: 2.8kW
- Maximum Recorded: 3.2kW
We wanted to note here that even with a more robust configuration than our 8x Tesla P100 GPU based-Gigabyte G481-S80 8x NVIDIA Tesla GPU Server, we saw lower power consumption across the board with the Inspur Systems NF5468M5 and with more performance. For deployments with high operational costs, the Inspur NF5468M5 delivers better performance per watt.
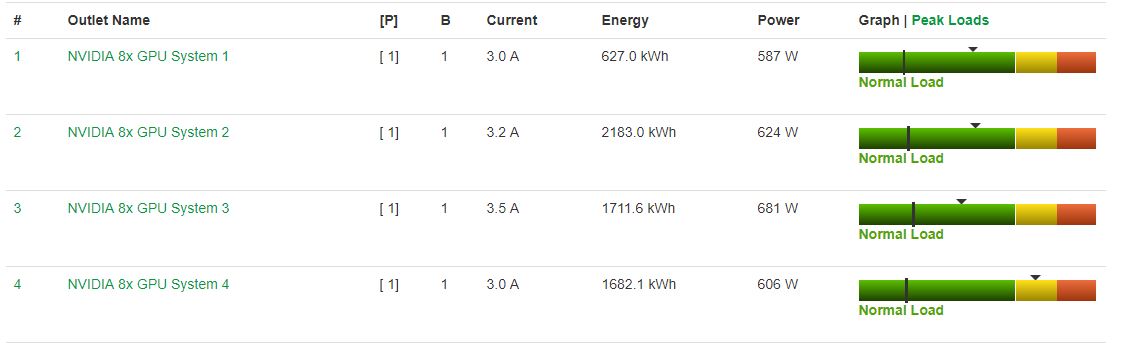
Note these results were taken using a 208V Schneider Electric / APC PDU at 17.7C and 72% RH. Our testing window shown here had a +/- 0.3C and +/- 2% RH variance.
STH Server Spider: Inspur NF5468M5
In the second half of 2018, we introduced the STH Server Spider as a quick reference to where a server system’s aptitude lies. Our goal is to start giving a quick visual depiction of the types of parameters that a server is targeted at.
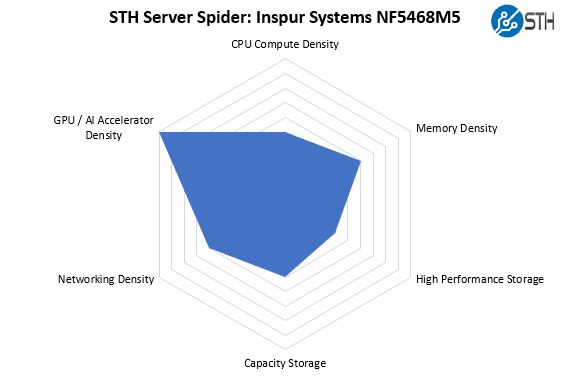
As you can see, the Inspur Systems NF5468M5 is designed for GPU compute. We also wanted to note here that unlike some of the other offerings in the market, the Inspur NF5468M5 has a fairly large number of 3.5″ bays for a GPU chassis. We have heard companies that are looking for more local storage for video often prefer having 3.5″ bays in-chassis. That is something that the Inspur solution addresses.
Final Words
In this review, we have covered many aspects of the Inspur Systems NF5468M5. We gave an in-depth hardware overview. We showed the system topology as well as the web management interface. We hit various aspects of performance including CPU, GPU, networking, storage, and power consumption.
Inspur Systems has a reputation for being the largest deep learning systems provider in China. A big part of this is supplying large CSPs. The Inspur Systems NF5468M5 is designed primarily to address the needs of large CSP customers and those looking to build large training and inferencing clusters and is tailored for that purpose.



{kind=link}
Ya’ll are doing some amazing reviews. Let us know when the server is translated on par with Dell.
How wonderful this product review is! So practical and justice!
Amazing. For us to consider Inspur in Europe English translation needs to be perfect since we have people from 11 different first languages in IT. Our corporate standard since we are international is English. Since English isn’t my first language I know why so early of that looks a little off. They need to hire you or someone to do that final read and editing and we would be able to consider them.
The system looks great. Do more of these reviews
Thanks for the review, would love to see a comparison with MI60 in a similar setup.
Great review! This looks like better hardware than the Supermicro GPU servers we use.
Can we see a review of the Asus ESC8000 as well? I have not found any other gpu compute designer that offers the choice in bios between single and dual root such as Asus does.
Hi Matthias – we have two ASUS platforms in the lab that are being reviewed, but not the ASUS ESC8000. I will ask.
How is the performance affected by CVE?2019?5665 through CVE?2019?5671and CVE?2018?6260?
P2P bandwidth testing result is incorrect, above result should be from NVLINK P100 GPU server not PCIE V100.
Comments are closed.