
With the launch of the new Graphcore GC200, the company’s second-generation part, we have next-gen AI silicon which is always exciting. Beyond the silicon, Graphcore also put forward its system and cluster design. At the same time, there were a few strange bits about the announcement. We wanted to cover both what was announced, and what was not announced.
Graphcore GC200 IPU
The 7nm (TSMC) Graphcore GC200 is a 59.4B transistor design specifically for the AI space. With that transistor count, the company calls it the “most complex chip” with more transistors “than any other single processor die.” (Source: Nigel Toon, Graphcore CEO.) STH readers will note that the Cerebras wafer-scale chip is at 1.2T transistors. Coming to market later with a chip 1/20th of what is now the biggest AI chip and calling it the most complex seems a bit strange. For comparison, the NVIDIA A100 is around 54B transistors.

The chip is known as the Colossus MK2. Some of the other key specs are 250 TFLOPS of AI-Float. Powering this is 900MB of in-processor memory (another approach we discussed in our Interview with Andrew Feldman CEO of Cerebras Systems.) There are 1472 independent processor cores that power 8832 parallel threads. Graphcore says that this is an 8x performance improvement over the first-generation product. If you want to see the first-gen, check out our Hands-on With a Graphcore C2 IPU PCIe Card at Dell Tech World and Graphcore at SC19 Dropping Eye-catching Feature for Production.
What is very interesting about the announcement is the packaging. We did not see an OCP Accelerator Module (OAM) that many see as the way the industry is moving. We also did not see the PCIe version we saw in the MK1 product:

Instead, we see a system specifically designed with the AI accelerators in mind. This is the Graphcore IPU Machine M2000. As one can see here, there are four Graphcore GC200 IPUs that are BGA packaged onto a PCB.

This design has a large cavity for providing thermal transfer to a large heatsink/ heat pipe array to cool the chips.

Just for reference, here is the overview:
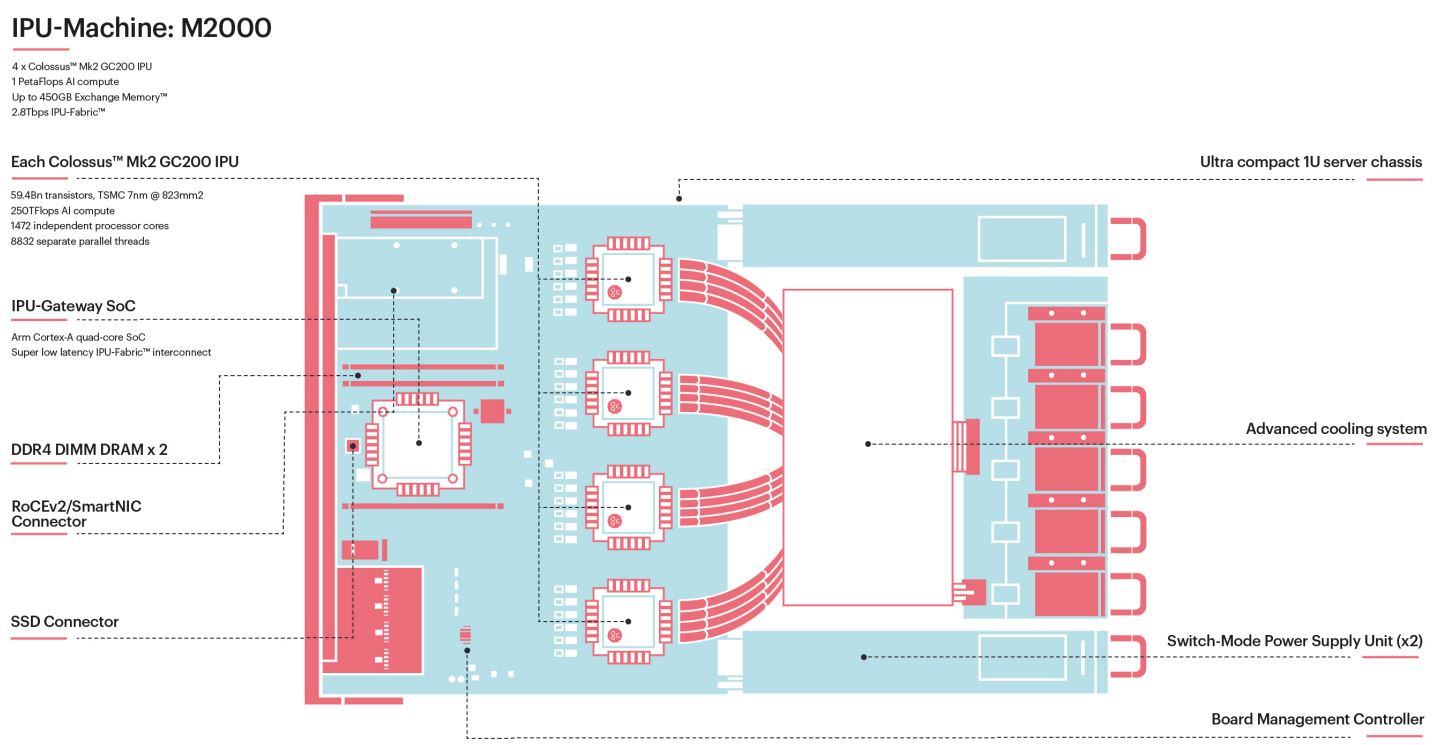
In the front of the PCB there is a quad-core ARM CPU along with a PCIe x16 slot on the front left. In front of the Arm SoC we get RJ45 network ports, likely for management, and to the right front, we get what looks like QSFP28 ports.

Graphcore has its own networking stack with two primary responsibilities. First, one gets a 3D Torus mesh type of solution where nodes can be directly attached together via its IPU fabric. Further, one gets the ability to put the nodes directly on 100GbE fabric to integrate into existing data centers. Today’s AI solutions need this type of flexibility and scalability. When published Favored at Facebook Habana Labs Eyes AI Training and Inferencing one of the key factors was 100GbE support.
Looking at the SoC, Graphcore highlighted the ability to use two DDR4 DIMMs for “up to 450GB” of off-processor Streaming Memory. Judging by the DIMMs, these are Samsung DDR4-2933 modules so that seems like it acts as a local cache.

As one will quickly note, there is a third DIMM slot here, even though Graphcore is calling out only two. It is somewhat strange to show three and say there are two in your materials.
Graphcore noted that one can add a SmartNIC to the box. For large hyper-scale organizations many are using SmartNICs and FPGAs for data center networking, a key reason we saw Xilinx acquired SolarFlare and even Intel purchased Altera. Graphcore showed this several times but did not mention it. The NIC installed in this demo system is a NVIDIA-Mellanox NIC.

As we discussed years ago, NVIDIA to Acquire Mellanox a Potential Prelude to Servers, and more recently in the SmartNIC NVIDIA EGX A100 Launched Tesla Plus Mellanox Vision, NVIDIA is investing heavily in top-shelf networking IP for both InfiniBand and Ethernet. NVIDIA knows this is the future and that EGX A100 is a good example of what is coming.
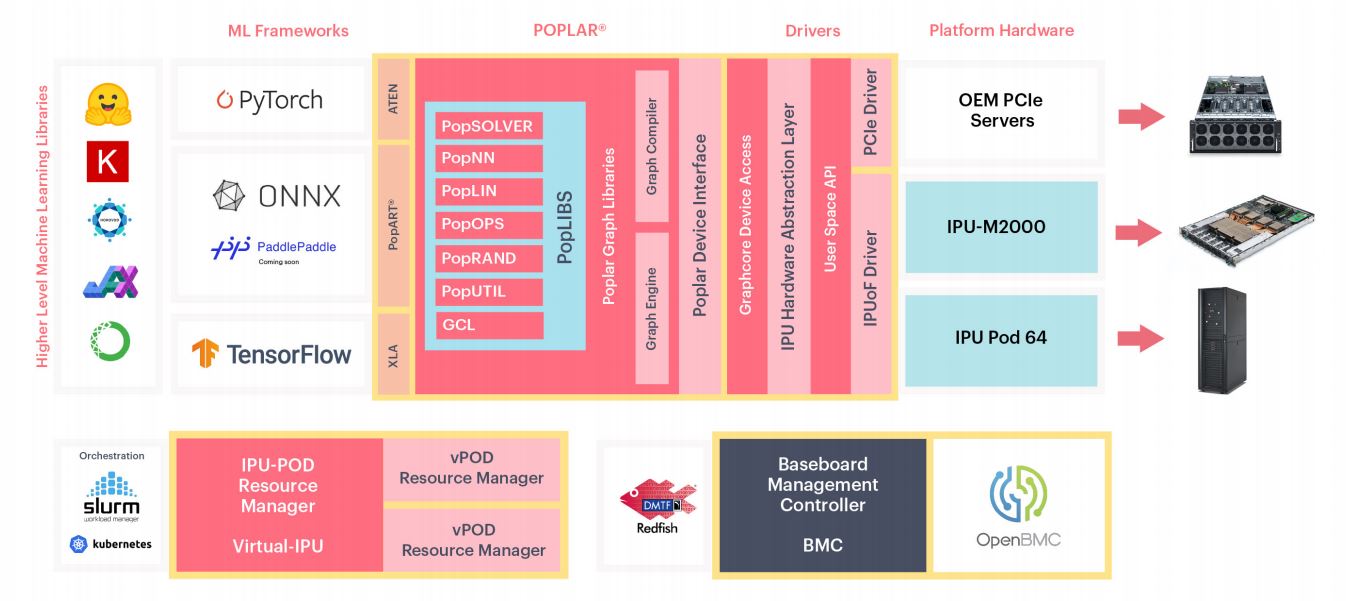
Using Graphcore’s Virtual-IPU, service providers can provision IPUs to hosts. For example, a server/ customer may need 8x IPUs in one instance and 4x GC200 IPUs in another.
Aside from the obvious engineering feat of bringing a new chip, system, and scale-out solution to market on the hardware side, the software is interesting too. To make all of this work, and take advantage of both multiple IPUs along with the massive memory bandwidth and sparsity for the Graphcore IPUs, the company has its Poplar SDK. Realistically, the hardware is what we cover, but all of the AI companies need to have great software. NVIDIA CUDA has been around for a long time and there is little doubt one will be able to easily find an NVIDIA CUDA developer in 2 years time. For the AI hardware startups, that is a big hurdle. One company misstep can spell trouble for a startup while NVIDIA has a clear track record. To be sure, big hyper-scalers such as Google (Tensorflow), Facebook (Pytorch), and Baidu (PaddlePaddle) all know there is a vendor lock-in risk and that is why we have today’s frameworks.
We also wanted to give Graphcore credit for naming a list price of $32,450. The previous life of doing storage pricing and deal management makes me want to see a $32,499 / $32,500 or $33,999/ $34,000 price. Still, putting a public price out there is a great setp.
What Was Glaringly Missing
The announcement was extremely strange for a few reasons. Perhaps the biggest was the customer list.
Dell EMC servers were featured in the various product cluster shots. That makes sense. Dell is a big investor in Graphcore. Beyond that here are the names in the press release:
- Graphcore’s technology is being evaluated by J.P. Morgan
- Oxford Nanopore – “We have been testing Graphcore IPUs for some time now”
- EspresoMedia – We are delighted to be a lead customer for their Mk2 IPU platforms
- Lawrence Berkeley National Laboratory “By leveraging the Azure IPU preview…”
- University of Oxford – “Our early work with Graphcore’s IPU has resulted in dramatic performance gains…”
- Simula Research Laboratory – “…at the end of 2019 Simula became an early access customer for their IPU-POD scale out platforms.” and “Simula, as host of the national research infrastructure eX3, is delighted to announce that our IPU compute cluster will soon be available for research projects at the interface of HPC and AI.”
- ATOS – “We are partnering with Graphcore to make their Mk2 IPU systems products, including IPU-Machine M2000 and IPU-POD scale-out systems, available to our customers specifically large European labs and institutions. We are already planning with European early customers to build out an IPU cluster for their AI research projects.”
(Source for above quotes: Graphcore)
If we break that down the customer statements are basically:
- Comments of testing:
- J.P. Morgan
- Lawrence Berkeley National Laboratory (via Microsoft Azure)
- University of Oxford
- Comments of deployment:
- EspresoMedia
- Simula Research Laboratory
- ATOS (partner)
Conspicuously absent were Dell EMC and Microsoft, both big investors in Graphcore. Here is a quick look at the investor list from Graphcore’s website as of the announcement.

One has to ask, where is the announcement of Microsoft Azure as a major product? That may be coming, but why is it not at launch? The relationship is public so one would expect that. Further, what about BMW, Bosch, and Samsung? Other investors are huge. Just taking one example, Sequoia is one of the most well-known venture firms in Silicon Valley that counts investment companies such as Apple, Electronic Arts, GitHub, Google, NVIDIA, Instacart, Instagram, NetApp, Oracle, PayPal, reddit, ServiceNow, WhatsApp, Yahoo!, YouTube, Zoom among dozens of others. Graphcore is extremely well funded and has great connections so to see that sparse of a customer roster for this generation of product is borderline shocking.
Another bit that was strange is that Dell EMC and Inspur were the two systems partners for Graphcore’s first-generation product. On the same day that Graphcore launched MK2 we had a first hands-on look at the Inspur AIStation for AI Cluster Operations Management where we asked Liu Jun about using other accelerators. He said that it would support others in the future, but he did not mention Graphcore even though they were an early partner. Of note, we coordinated the release of our AIStation hands-on piece with Inspur’s press launch of the AIStation product so it may have been a matter of timing, but the MK1 work was public.
Final Words
Graphcore is perhaps one of the best-funded AI startups. Their product looks very cool indeed. At the same time, something seems off with customer announcements. Graphcore was being considered at Facebook, but we know that Facebook balked at bout Intel’s Nervana-based solutions as well as Graphcore’s solutions before deciding on Habana Labs. That decision was enough to see Intel Acquire Habana Labs. We know that Google Cloud already has NVIDIA A100 instances Launched and every other major hyper-scale provider (save Facebook) has announced plans to deploy NVIDIA A100.
Personally, I have been extremely excited about Graphcore’s technology and when people ask, they have been on my list of AI hardware companies to look at. At STH, we normally do not focus on customer statements, and neither Cliff nor I usually include them. With the Graphcore GC200 launch, the lack of customer commitment for a company with the investor backing Graphcore has is stunning. This is similar feedback that I gave the Ampere Altra team recently with their MAX announcement. Hopefully, these are timing matters.
Perhaps the lesson is that the hardest part about being an AI hardware startup is getting customers willing to be named in your launch releases. Time will tell.



{kind=link}
THAT is some critical thinking. Nice overview and critique of their launch. Maybe they’re just hoping to get bought by microsoft or dell now.
You are raising an interesting question Patrick:
Is the secrecy around the AI supercomputers of bleeding edge shops like OpenAI, DeepMind, etc. hurting the actual hardware suppliers as they are unable to speak about their customers?
Nice customer list breakdown with the investor list. Maybe as LP says there’s companies that don’t want to be listed. You’d think BMW or Microsoft or another on that list would step up and say they’re buying the GC200’s.
You didn’t talk about the PCIe as much as I wanted. No PCIe is important for many performance apps, but PCIe is the king in many regions
Isn’t the 900 MB of, albeit superfast, memory not limiting the kind of AI workload you can run. I thought a big chunk of fast GDDR6/HBM2 (+8GB) memory was necessary for a lot of applications (image recognition for example) ?
Pretty sure the third “DIMM” slot is for the SSD. It’s the inbetweener.
Comments are closed.