
With MLPerf v0.5 Results going live this week, it was an opportunity for vendors to showcase their offerings. In the initial results, Google, NVIDIA, and Intel all submitted findings, with AMD as well as a number of well-funded AI hardware startups being conspicuously absent. Alongside the results, the Google TPU v2 Pod was highlighted as a cost-effective alternative to NVIDIA for deep learning training.
Google TPU v2 Pod Training Announcement
When it comes to deep learning training, there are a few major parties to watch. NVIDIA is currently the leader, by far. Its Tesla V100 product has been out for well over a year and its support for Tensor cores means it has opened the gap between it and other CPU and GPU solutions on the market. Intel’s NNP was much hyped, and apparently was delivered to Facebook a year ago, but it has been very quiet since as the first generation was not up to par to be a commercial product.
For its part, we have been covering the Google TPU since details were first released. Some examples are Case Study on the Google TPU and GDDR5 from Hot Chips 29 and Google Cloud TPU Details Revealed. Google has come to the market with its custom TPU architecture. Its value proposition is simple. Google developed Tensorflow and then built the TPU to accelerate its own workloads. It then started releasing the TPU v2 Pod to the public in its cloud as an amazing differentiator to the rest of the market mostly running Intel CPUs and NVIDIA GPUs for deep learning and AI.
With the company’s MLPerf v0.5 results, Google is making a statement. Google now allows users to train on its TPU v2 Pod infrastructure. Many out there may think “so what?” given the fact that GCP, AWS, Azure, and others are using NVIDIA. Google answers that with a tantalizing result:
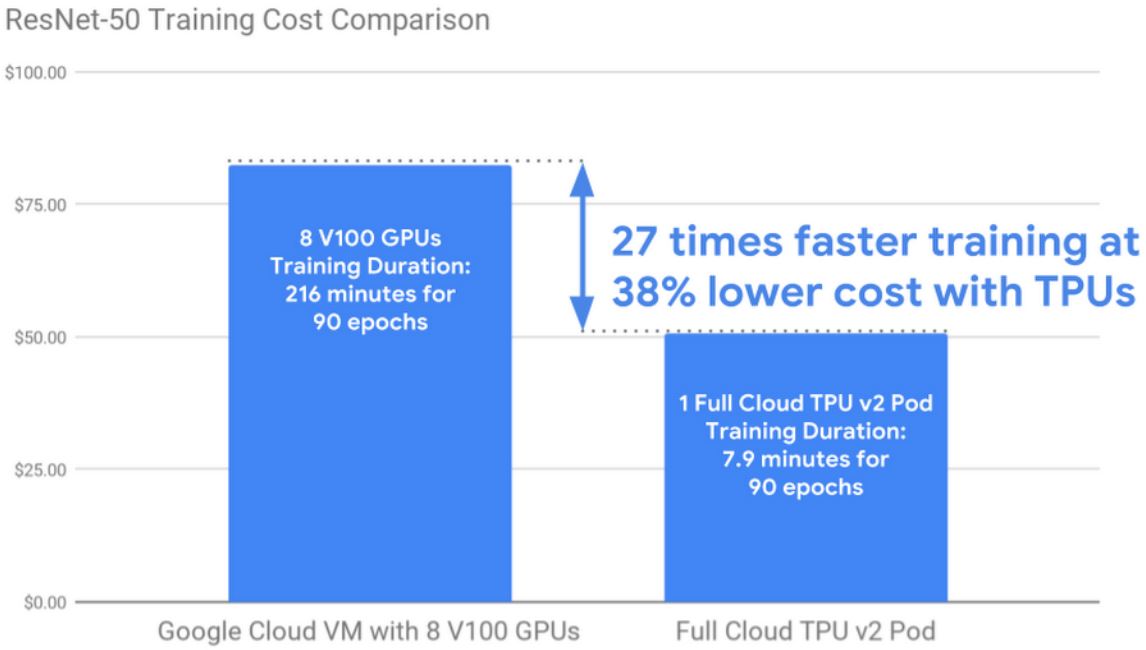
Google is saying it can train 27x faster at 38% lower cost than an 8x NVIDIA Tesla V100 GCP Cloud VM. Those are surely some impressive figures. Reading critically, one would also note that the GCP 8x Tesla V100 Cloud VM is generally lower in performance than a true 8x Tesla V100 machine like an NVIDIA HGX-1 based system. We also note that Google did not do this using NVIDIA’s results for a DGX-1 as a comparison point so this is likely skewed to what those with on-prem hardware are seeing.
Final Words
Only three companies had release day benchmarks for MLPerf v0.5. NVIDIA managed to claim the fastest training time using a cluster that likely costs around $13 million. Google was very close in many workloads and can show a better pricing strategy with the cloud and show the benefits of the TPU v2 Pod integrated into its cloud. You can read more about the announcement here.
The deep learning hardware wars are for those companies with deep pockets. Google has the ability to develop and market products like the TPU v2 Pod at scale along with other industry titans.



{kind=link}