Getting the TITAN RTX’s and NVLink Bridge Setup
Setting up our GPUs is simple. We insert our NVIDIA Titan RTX cards in the appropriate PCIe slots and connect the bridge. We will be using Windows 10 Pro for many of our tests. Once we booted to the desktop we download the latest drivers and install them, at the time of writing the driver version is 419.67. We right-click on the desktop and select the NVIDIA Control Panel.
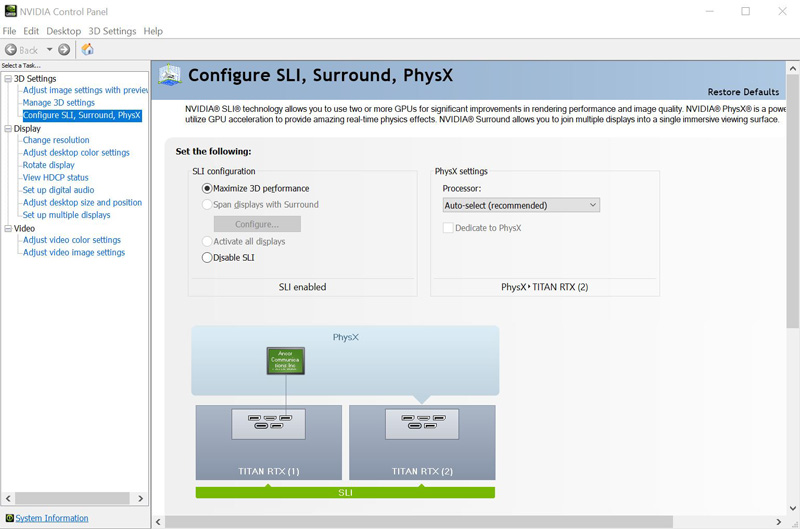
If SLI is not enabled, you can do that here. Years later, we are still enabling SLI for our two $2500 desktop GPUs. As much as things change, they sometimes stay the same.
Confirming everything is in order, we check system information.
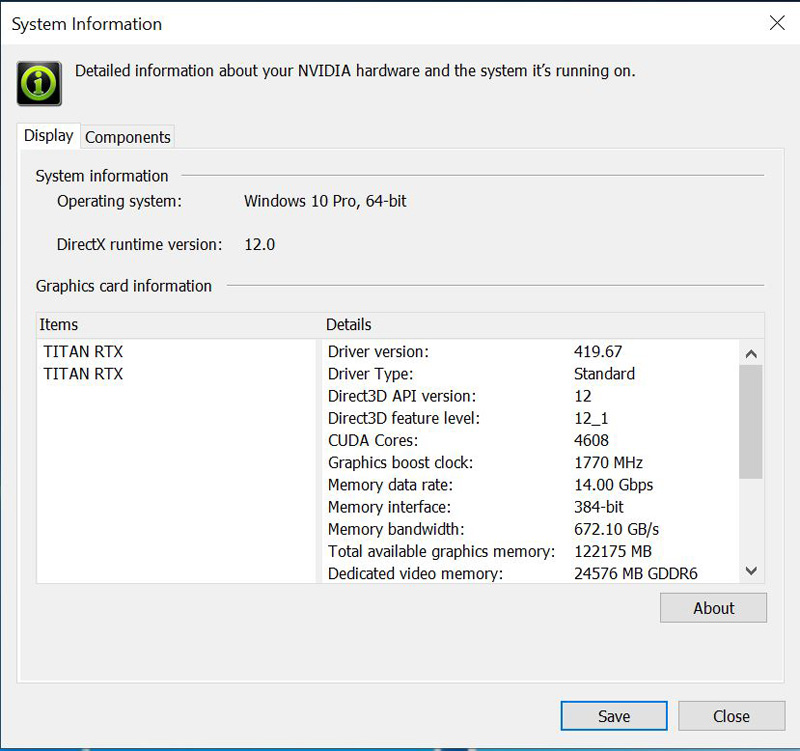
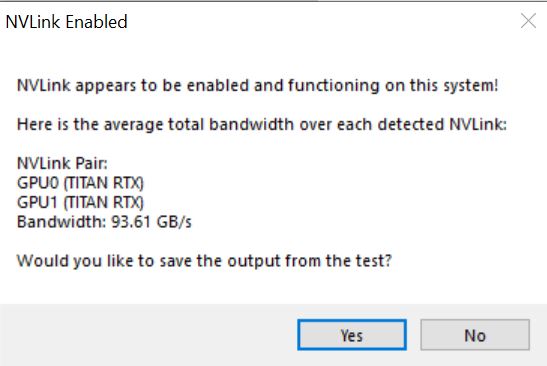
So far everything is looking good. Since we have this setup using Windows, we can validate that it is working using NVLinkTest.
Here this text output for NVIDIA’s p2pBandwidthLatencyTest:

You will notice that this is similar to the Linux p2pbandwidthtest output we saw in Gigabyte G481-S80 8x NVIDIA Tesla GPU Server Review the DGX1.5 and Inspur Systems NF5468M5 Review 4U 8x NVIDIA Tesla V100 GPU Server.
We will use the same software that we have used on all our reviews while on Windows 10 Pro.
Software Used: ASUS GPU Tweak
GPU Tweak II software from ASUS used to set different configs and monitor GPU data for its graphics cards. Although the graphics are relatively large when displayed onscreen, it can be minimized to the taskbar when not needed.
GPU Tweak II was also used on our Titan RTX review; we used the same settings here.
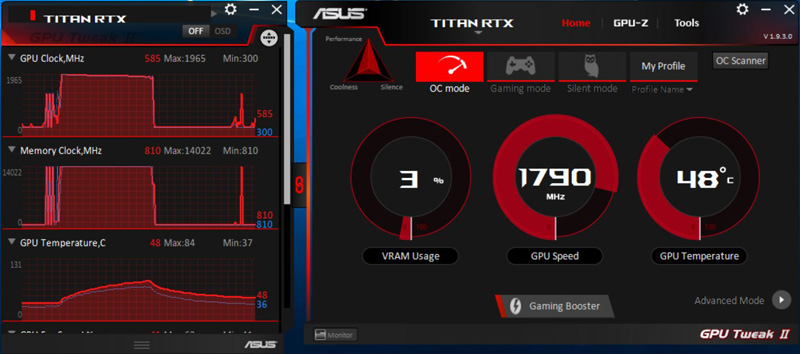
ASUS GPU Tweak sees both Titan RTX’s and applies the different modes to each GPU. You can see the different GPU’s in the graphs where one is colored Red, and the other is colored Blue. The Red part of the graphs is the primary GPU, and we will note that both GPU’s do not show identical numbers. An example for that is while sitting on the desktop GPU #1 (Red) or the primary GPU is doing most of the work while GPU #2 (Blue) idles. We can also see this effect while benchmarks are running GPU #1 (Red) or the primary GPU is doing most of the work while GPU #2 (Blue) ramps up when needed, loads appear to balance back and forth between the GPU’s.
Next, let us take a look at the NVIDIA Titan RTX NVLink specifications and our test setup then continue on with our performance testing.
NVIDIA Titan RTX Key Specifications
Here are the key specifications for the NVIDIA Titan RTX:
- Graphics Processing Clusters: 6
- Texture Processing Clusters: 36
- Streaming Multiprocessors: 72
- CUDA Cores (single precision): 4608
- Tensor Cores: 576
- RT Cores: 72
- Base Clock (MHz): 1350 MHz
- Boost Clock (MHz): 1770 MHz
- Memory Clock: 7000 MHz
- Memory Data Rate: 14 Gbps
- L2 Cache Size: 6144 K
- Total Video Memory: 24GB GDDR6
- Memory Interface: 384-bit
- Total Memory Bandwidth: 672 GB/s
- Texture Rate (Bilinear): 510 GigaTexels/sec
- Fabrication Process: 12nm FFN
- Transistor Count: 18.6 Billion
- Connectors: 3x DisplayPort , 1x HDMI, 1x USB Type-C
- Form Factor: Dual Slot
- Power Connectors: Two 8-Pin
- Thermal Design Power (TDP): 280watts
- Thermal Threshold: 89C
- NVLink: 100GB/s
One will notice that on the previous page we achieved over 93GB/s for our NVLink which is in the ballpark of the 100GB/s quoted in the specs. Combined, the two GPUs have massive compute resources as well as 24GB of memory per card. This is important since we effectively have two cards with P2P enabled and a total of 48GB of memory. This is much more than we would see with older generation desktop parts.
Testing the NVIDIA Titan RTX with NVLink
Here is our test setup for the dual NVIDIA Titan RTX:
- Motherboard: ASUS WS C621E SAGE Motherboard
- CPU: 2x Intel Xeon Gold 6134 (8 core / 16 Threads)
- GPU: 2x Titan RTX’s with NVLink
- Cooling: Noctua NH-U14S DX-3647 LGA3647
- RAM: 12x MICRON 16GB Low Profile
- SSD: Samsung PM961 1TB
- OS: Windows 10 Pro
- PSU: Thermaltake Toughpower DPS G RGB 1500W Titanium

The PCIe layout of the ASUS WS C621E SAGE Motherboard allows for us to use the 4-Slot Bridge with the first Titan RTX in slot #3 and the second Titan RTX in slot #7, this leaves two slots open for air-flow. We would use slot #1 or #2 for a 10GbE network card.
We can see a similar motherboard and setup being used in the bespoke systems that we suspect will house many dual NVIDIA Titan RTX with NVLink systems for the deep learning and creative communities.
Let us move on and start our testing with computing-related benchmarks.



{kind=link}
Incredible ! The tandem operates at 10x the performance of the best K5200 ! This is a must have for every computer laboratory that wishes to be up to date allowing team members or students to render in minutes what would take hours or days ! I hear Dr Cray sayin ” Yes more speed! “
This test would make more sense if the benchmarks were also run with 2 Titan RTX but WITHOUT NVlink connected. Then you’d understand better whether your app is actually getting any benefit from it. NVLink can degrade performance in applications that are not tuned to take advantage of it. (meaning 2 GPUs will be better than 2+NVLink in some situations)
I’m kind of missing the: NAMD Performance.
STH is freaking awesome. Great review William. You guys have got a great dataset building here
Great review yes – thanks !
2x 2080 Ti would be nice for a comparison. Benchmarks not constrained by memory size would show similar performance to 2x Titan at half the cost.
It would also be interesting to see CPU usage for some of the benchmarks. I have seen GPUs being held back by single threaded Python performance for some ML workloads on occasion. Have you checked for CPU bottlenecks during testing? This is a potential explanation for some benchmarks not scaling as expected.
Literally any amd GPU loose even compared to the slowest RTX card in 90% of test…In int32 int64 they don’t even deserve to be on chart
@Lucusta
Yep the Radeon VII really shines in this test. The $700 Radeon VII iis only 10% faster than the $4,000 Quadro RTX 6000 in programs like davinci resolve. It’s a horrible card.
@Misha
A Useless comparison, a pro card vs a not pro in a generic gpgpu program (no viewport so why don’t you say rtx 2080?)… The new Vega VII is compable to rtx quadro 4000 1000$ single slot! (pudget review)…In compute Vega 2 win, in viewport / specviewperf it looses…
@Lucusta
MI50 ~ Radeon VII and there is also a MI60.
Radeon VII(15 fps) beats the Quadro RTX 8000(10 fps) with 8k in Resolve by 50% when doing NR(quadro RTX4000 does 8 fps).
Most if not all benchmarking programs for CPU and GPU are more or less useless, test real programs.
That’s how Puget does it and Tomshardware is also pretty good in testing with real programs.
Benchmark programs are for gamers or just being the highest on the internet in some kind of benchmark.
You critique that many benchmarks did not show the power of nvlink and using pooled memory by using the two cards in tandem. But why did you not choose those benchmarks and even more important, why did you not set up your tensorflow and pytorch test bench to actually showcase the difference between nvlink and one without?
It’s a disappointing review in my opinion because you set our a premise and did not even test the premise hence the test was quite useless.
Here my suggeation: set up a deep learning training and inference test bench that displays actual gpu memory usage, the difference in performance when using nvlink bridges and without, performance when two cards are used in parallel (equally distributed workloads) vs allocating a specific workload within the same model to one gpu and another workload in the same model to the other gpu by utilizing pooled memory.
This is a very lazy review in that you just ran a few canned benchmark suites over different gpu, hence the rest results are equally boring. It’s a fine review for rendering folks but it’s a very disappointing review for deep learning people.
I think you can do better than that. Pytorch and tensorflow have some very simple ways to allocate workloads to specific gpus. It’s not that hard and does not require a PhD.
Hey William, I’m trying to set up the same system but my second GPU doesn’t show up when its using the 4-slot bridge. Did you configure the bios to allow for the multiple gpus in a manner that’s not ‘recommended’ by the manual.
I’m planning a new workstation build and was hoping someone could confirm that two RTX cards (e.g. 2 Titan RTX) connected via NVLink can pool memory on a Windows 10 machine running PyTorch code? That is to say, that with two Titan RTX cards I could train a model that required >24GB (but <48GB, obviously), as opposed to loading the same model onto multiple cards and training in parallel? I seem to find a lot of conflicting information out there. Some indicate that two RTX cards with NVLink can pool memory, some say that only Quadro cards can, or that only Linux systems can, etc.
I am interested in building a similar rig for deep learning research. I appreciate the review. Given that cooling is so important for these setups, can you publish the case and cooling setup as well for this system?
I only looked at the deep learning section – Resnet-50 results are meaningless. It seems like you just duplicated the same task on each GPU, then added the images/sec. No wonder you get exactly 2x speedup going from a single card to two cards… The whole point of NVLink is to split a single task across two GPUs! If you do this correctly you will see that you can never reach double the performance because there’s communication overhead between cards. I recommend reporting 3 numbers (img/s): for a single card, for splitting the load over two cards without NVLink, and for splitting the load with NVLink.
Comments are closed.