NVIDIA Titan RTX Compute Related Benchmarks
Running two GPUs with NVLink enabled is a well-understood configuration. Still, while most software scales well with two GPUs, some programs will work with only one GPU. Some of our benchmarks scale very well and show excellent numbers, while some do not take advantage of dual GPUs. Users will find better results if they research which workloads they will be using that can benefit from two GPUs in NVLink. Our first two workloads are going to show that stark contrast.
Geekbench 4
Geekbench 4 measures the compute performance of your GPU using image processing to computer vision to number crunching.
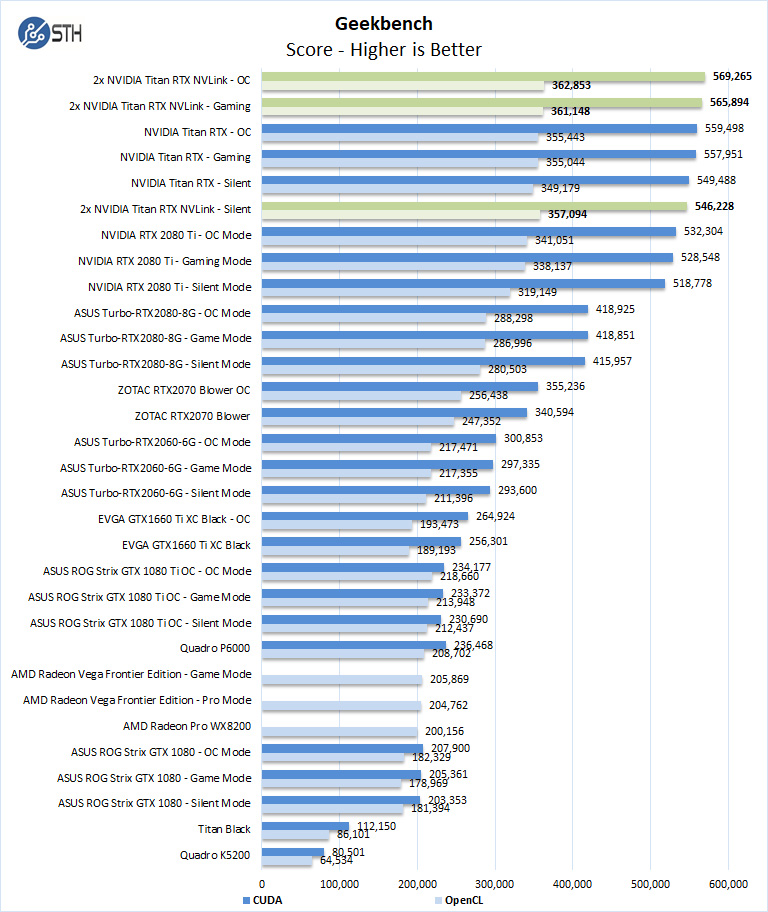
Our first compute benchmark we see the 2x NVIDIA Titan RTX NVLink shows that Geekbench does not benefit from these two cards. One could run two instances, one per GPU, however, we wanted to show what poor usage looks like. Our next benchmark LuxMark will be on the other end of the spectrum.
LuxMark
LuxMark is an OpenCL benchmark tool based on LuxRender.
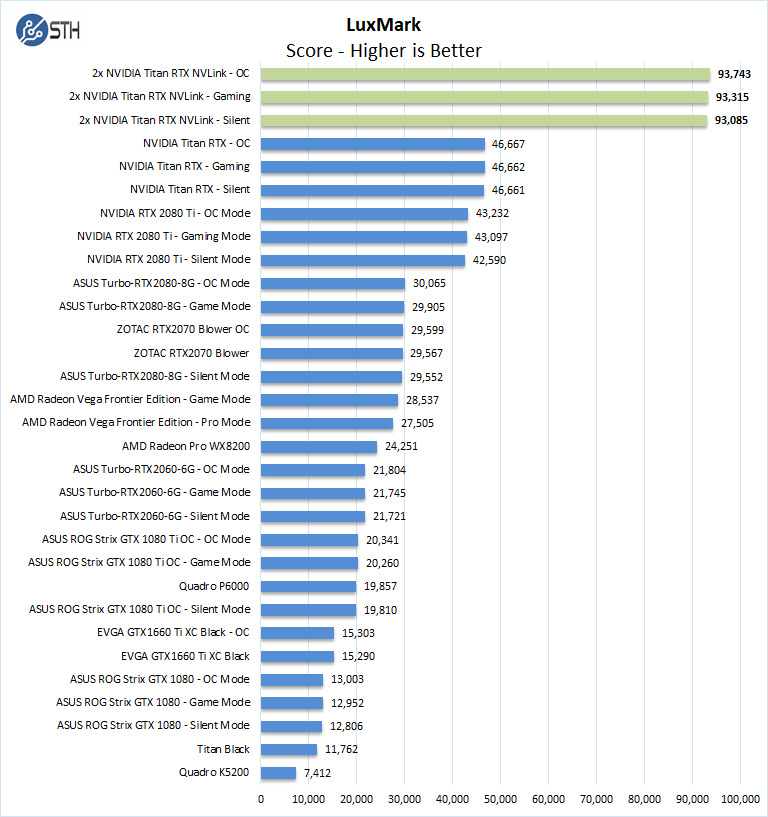
Here we see performance take a massive jump as Luxmark uses both NVIDIA Titan RTX to significant effect. There is almost linear scaling from one to two GPUs.
Most other workloads will fall somewhere between great scaling we see with LuxMark and Geekbench’s poor scaling.
AIDA64 GPGPU
These benchmarks are designed to measure GPGPU computing performance via different OpenCL workloads.
- Single-Precision FLOPS: Measures the classic MAD (Multiply-Addition) performance of the GPU, otherwise known as FLOPS (Floating-Point Operations Per Second), with single-precision (32-bit, “float”) floating-point data.
- Double-Precision FLOPS: Measures the classic MAD (Multiply-Addition) performance of the GPU, otherwise known as FLOPS (Floating-Point Operations Per Second), with double-precision (64-bit, “double”) floating-point data.
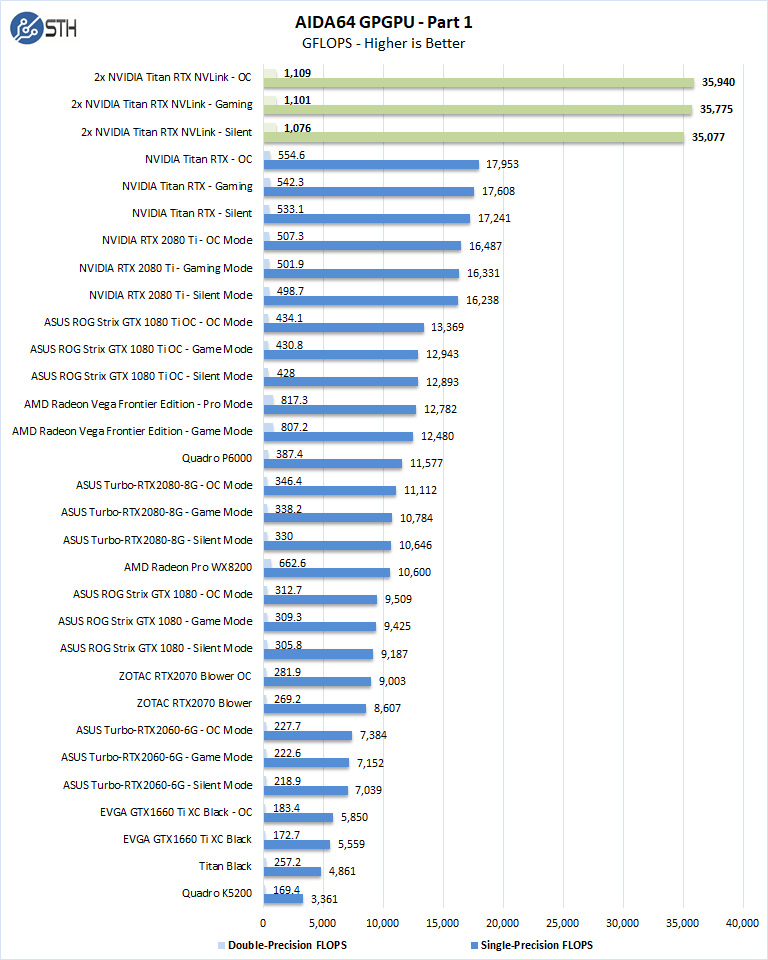
AIDA64 GPGPU runs on each NVIDIA Titan RTX separately; we added the results together to get the final results shown here.
The next set of benchmarks from AIDA64 are:
- 24-bit Integer IOPS: Measures the classic MAD (Multiply-Addition) performance of the GPU, otherwise known as IOPS (Integer Operations Per Second), with 24-bit integer (“int24”) data. This particular data type defined in OpenCL on the basis that many GPUs are capable of executing int24 operations via their floating-point units.
- 32-bit Integer IOPS: Measures the classic MAD (Multiply-Addition) performance of the GPU, otherwise known as IOPS (Integer Operations Per Second), with 32-bit integer (“int”) data.
- 64-bit Integer IOPS: Measures the classic MAD (Multiply-Addition) performance of the GPU, otherwise known as IOPS (Integer Operations Per Second), with 64-bit integer (“long”) data. Most GPUs do not have dedicated execution resources for 64-bit integer operations, so instead, they emulate the 64-bit integer operations via existing 32-bit integer execution units.
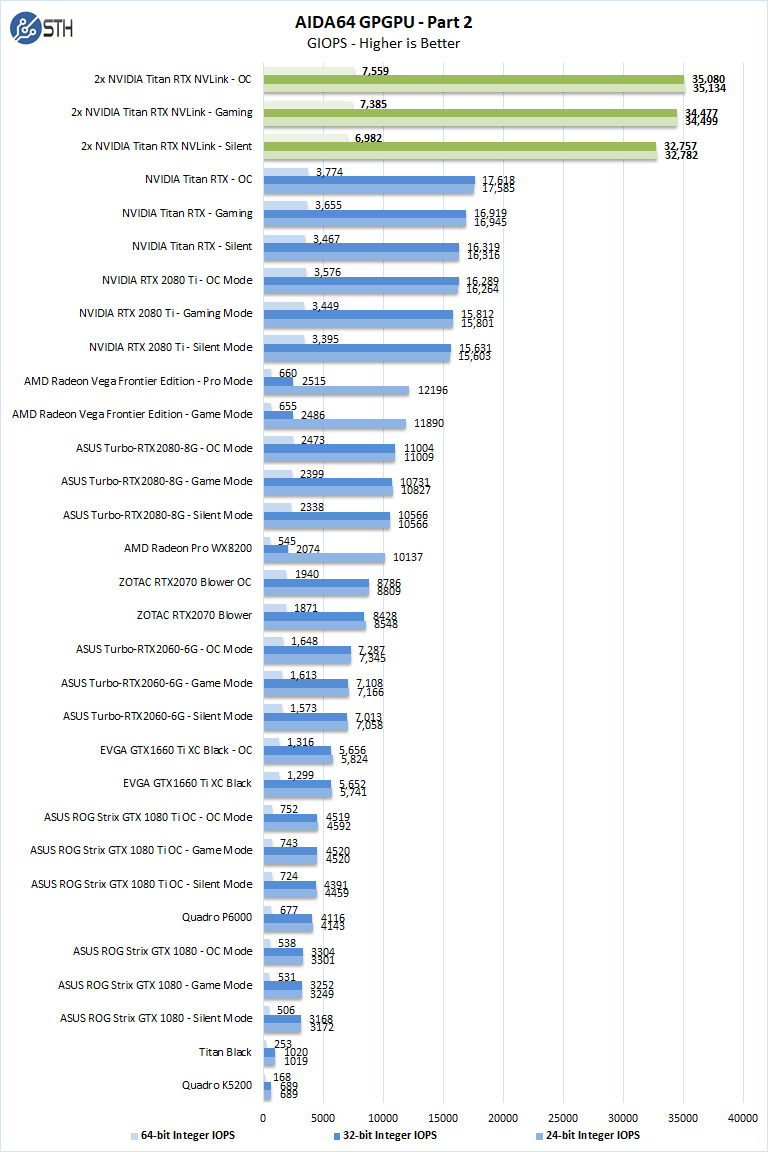
As one may expect, the dual NVIDIA Titan RTX system shows excellent results. On the Integer side, two NVIDIA Titan RTX cards are essentially doing the work that we would see from an 8x GPU box like our DeepLearning10: The 8x NVIDIA GTX 1080 Ti GPU Monster.
SPECviewperf 13
SPECviewperf 13 measures the 3D graphics performance of systems running under the OpenGL and Direct X application programming interfaces.
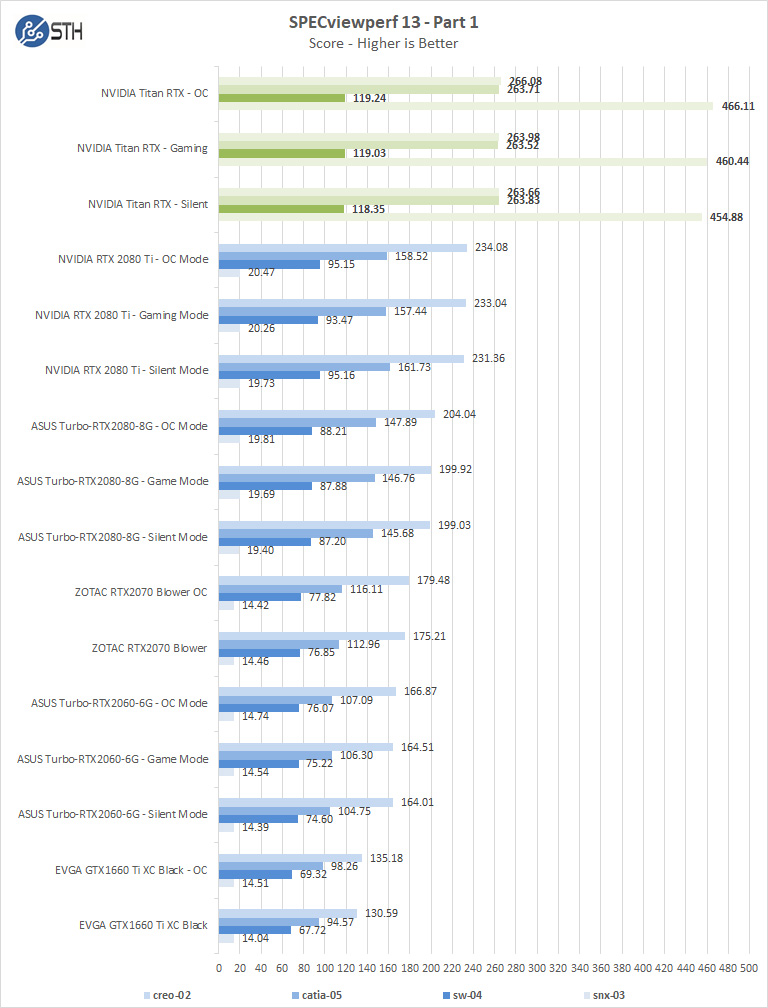
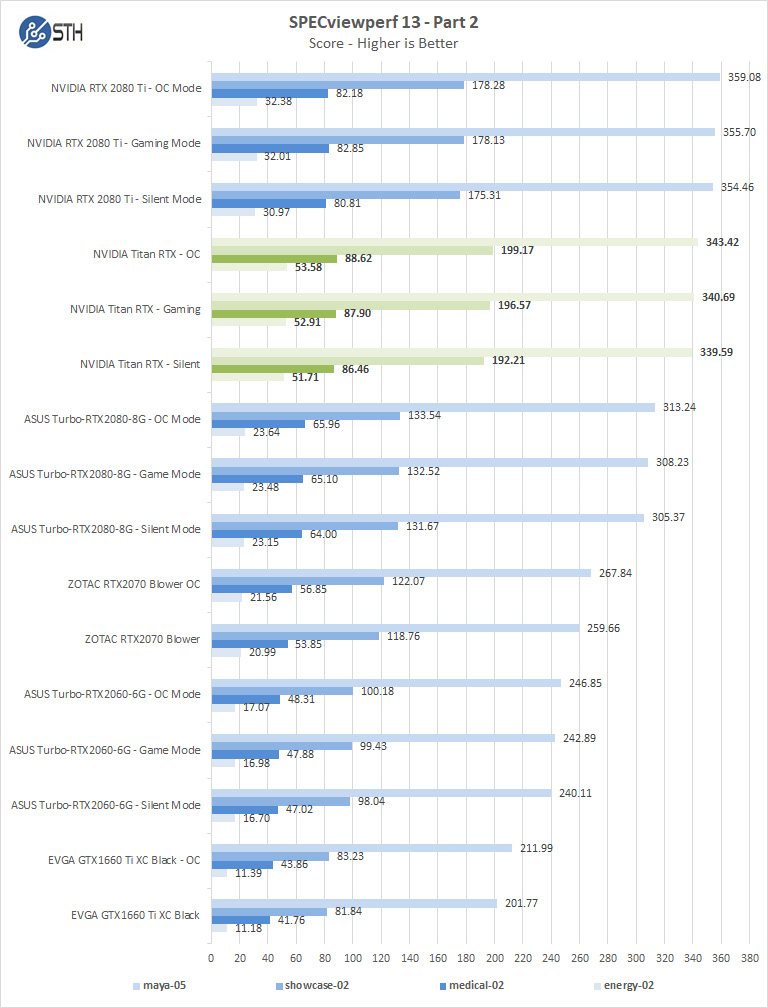
SPECviewperf 13 does not use both Titan RTX’s; it only sees one, so we will show past results here from our NVIDIA Titan RTX Review.
SPECworkstation 3
SPECworkstation3 measures the 3D graphics performance of systems running under the OpenGL and DirectX application programming interfaces.
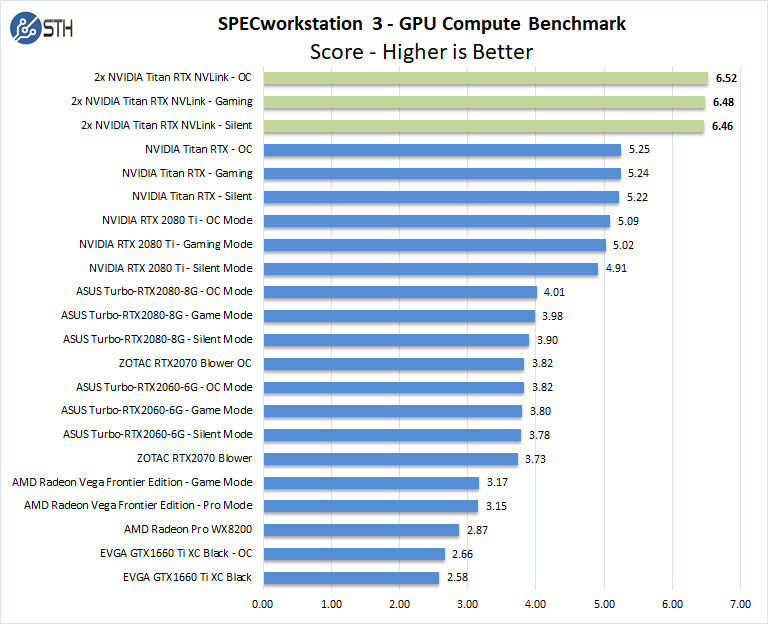
With the highest price tag and the most compute resources, we can clearly see the Titan RTX’s with NVLink boost the scores by over a full point which is impressive. Scaling is not linear. On the other hand, if your time is valuable, $2500 to go 19% faster can make sense.
Let us move on and start our new tests with rendering-related benchmarks where we will see much better scaling.



{kind=link}
Incredible ! The tandem operates at 10x the performance of the best K5200 ! This is a must have for every computer laboratory that wishes to be up to date allowing team members or students to render in minutes what would take hours or days ! I hear Dr Cray sayin ” Yes more speed! “
This test would make more sense if the benchmarks were also run with 2 Titan RTX but WITHOUT NVlink connected. Then you’d understand better whether your app is actually getting any benefit from it. NVLink can degrade performance in applications that are not tuned to take advantage of it. (meaning 2 GPUs will be better than 2+NVLink in some situations)
I’m kind of missing the: NAMD Performance.
STH is freaking awesome. Great review William. You guys have got a great dataset building here
Great review yes – thanks !
2x 2080 Ti would be nice for a comparison. Benchmarks not constrained by memory size would show similar performance to 2x Titan at half the cost.
It would also be interesting to see CPU usage for some of the benchmarks. I have seen GPUs being held back by single threaded Python performance for some ML workloads on occasion. Have you checked for CPU bottlenecks during testing? This is a potential explanation for some benchmarks not scaling as expected.
Literally any amd GPU loose even compared to the slowest RTX card in 90% of test…In int32 int64 they don’t even deserve to be on chart
@Lucusta
Yep the Radeon VII really shines in this test. The $700 Radeon VII iis only 10% faster than the $4,000 Quadro RTX 6000 in programs like davinci resolve. It’s a horrible card.
@Misha
A Useless comparison, a pro card vs a not pro in a generic gpgpu program (no viewport so why don’t you say rtx 2080?)… The new Vega VII is compable to rtx quadro 4000 1000$ single slot! (pudget review)…In compute Vega 2 win, in viewport / specviewperf it looses…
@Lucusta
MI50 ~ Radeon VII and there is also a MI60.
Radeon VII(15 fps) beats the Quadro RTX 8000(10 fps) with 8k in Resolve by 50% when doing NR(quadro RTX4000 does 8 fps).
Most if not all benchmarking programs for CPU and GPU are more or less useless, test real programs.
That’s how Puget does it and Tomshardware is also pretty good in testing with real programs.
Benchmark programs are for gamers or just being the highest on the internet in some kind of benchmark.
You critique that many benchmarks did not show the power of nvlink and using pooled memory by using the two cards in tandem. But why did you not choose those benchmarks and even more important, why did you not set up your tensorflow and pytorch test bench to actually showcase the difference between nvlink and one without?
It’s a disappointing review in my opinion because you set our a premise and did not even test the premise hence the test was quite useless.
Here my suggeation: set up a deep learning training and inference test bench that displays actual gpu memory usage, the difference in performance when using nvlink bridges and without, performance when two cards are used in parallel (equally distributed workloads) vs allocating a specific workload within the same model to one gpu and another workload in the same model to the other gpu by utilizing pooled memory.
This is a very lazy review in that you just ran a few canned benchmark suites over different gpu, hence the rest results are equally boring. It’s a fine review for rendering folks but it’s a very disappointing review for deep learning people.
I think you can do better than that. Pytorch and tensorflow have some very simple ways to allocate workloads to specific gpus. It’s not that hard and does not require a PhD.
Hey William, I’m trying to set up the same system but my second GPU doesn’t show up when its using the 4-slot bridge. Did you configure the bios to allow for the multiple gpus in a manner that’s not ‘recommended’ by the manual.
I’m planning a new workstation build and was hoping someone could confirm that two RTX cards (e.g. 2 Titan RTX) connected via NVLink can pool memory on a Windows 10 machine running PyTorch code? That is to say, that with two Titan RTX cards I could train a model that required >24GB (but <48GB, obviously), as opposed to loading the same model onto multiple cards and training in parallel? I seem to find a lot of conflicting information out there. Some indicate that two RTX cards with NVLink can pool memory, some say that only Quadro cards can, or that only Linux systems can, etc.
I am interested in building a similar rig for deep learning research. I appreciate the review. Given that cooling is so important for these setups, can you publish the case and cooling setup as well for this system?
I only looked at the deep learning section – Resnet-50 results are meaningless. It seems like you just duplicated the same task on each GPU, then added the images/sec. No wonder you get exactly 2x speedup going from a single card to two cards… The whole point of NVLink is to split a single task across two GPUs! If you do this correctly you will see that you can never reach double the performance because there’s communication overhead between cards. I recommend reporting 3 numbers (img/s): for a single card, for splitting the load over two cards without NVLink, and for splitting the load with NVLink.
Comments are closed.