ASUS RS520QA-E13-RS8U Topology
Originally when I was in Taipei we were using 32GB DIMMs.

Later we got to use the system with 64GB DIMMs. That gave us 64GB x 12 directly attached DDR5 DIMMs for 768GB. Then there were 64GB x 8 CXL attached DDR5 DIMMs for an additional 512GB. That is a total of 1280GB of memory in a single channel AMD EPYC 9005 platform, without having to resort to using 2DPC memory configurations or 128GB DIMMs.
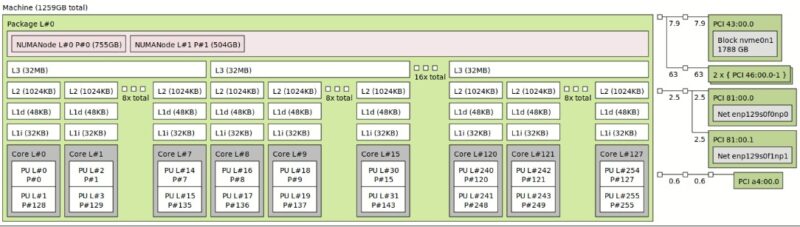
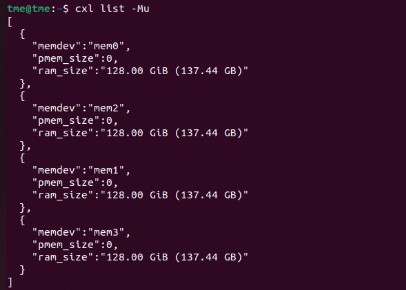
The four Montage controllers each reported having 128GB of memory with the two 64GB DIMMs attached.
The rest of the PCIe side is perhaps the less exciting part, but this is just a neat system.
ASUS RS520QA-E13-RS8U Management
The ASUS RS520QA-E13-RS8U utilizes an ASPEED AST2600 as its BMC.

Running on this we get the ASUS ASMB12-iKVM based on the industry standard MegaRAC SP-X.
We checked, and you can see the Montage controllers in the web interface, so those are being exposed to the BMC.
The BMC also has access to the telemetry data.
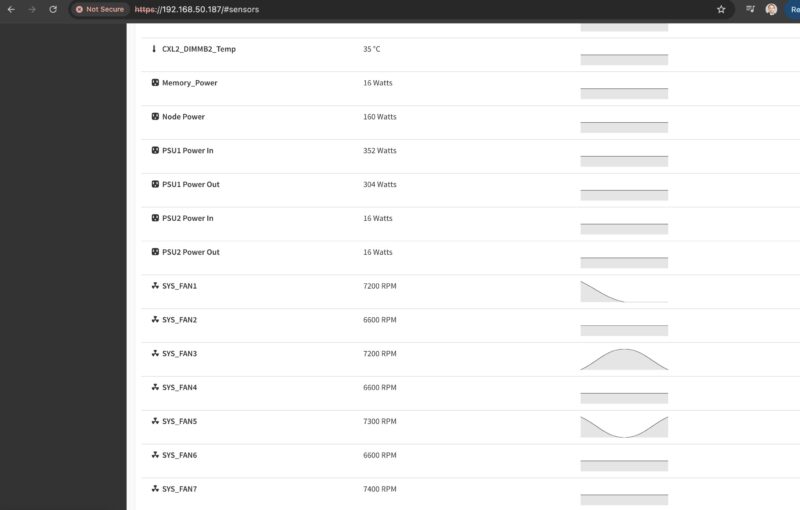
Of course, we also get the HTML5 iKVM and other standard BMC features.
Next, let us get to the performance.
ASUS RS520QA-E13-RS8U Performance
Here we have AMD EPYC 9755 128-core processors installed in this node.
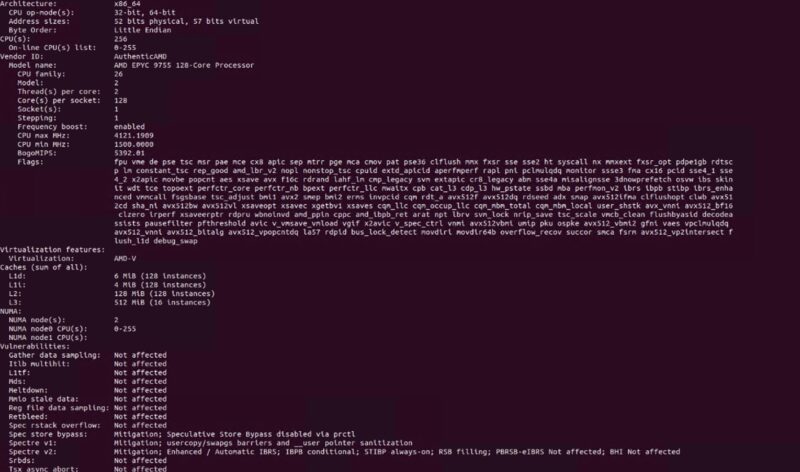
Our first question was, without CXL, does the system cool the processors enough so that we are not losing any CPU performance with the 2U 4-node design.
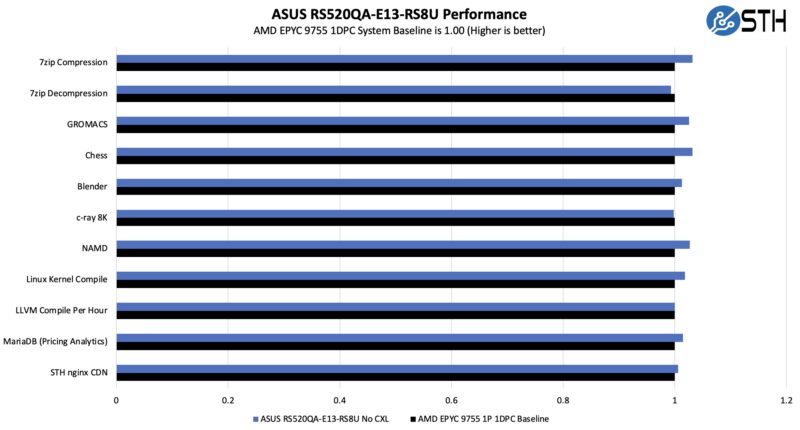
There is always a test run-to-run variation, but we would say that this is roughly the same performance as a 1U AMD EPYC 9005 single-node server.
The next question is with CXL. Something that you can see here is that the CPU has its local 768GB attached to NUMA node 0. NUMA node 1 is a 512GB node without CPU cores associated.

While there is a latency hit of around accessing memory on a remote CPU socket (e.g. CPU0 accessing CPU1’s memory), there is a lot more at play here. If you have 24 DIMMs per socket, in most AMD EPYC platforms that decreases the memory clock speed even if only 12 are filled. If you fill all 24 slots, then you get more memory capacity, but you lose even more performance. Using CXL memory one gets the benefit of being able to expand capacity while retaining 1DPC speeds. The added benefit is that CXL memory bandwidth does not use the direct DDR5 channel bandwidth, effectively adding capacity and bandwidth at a higher latency. This is not dissimilar to adding another CPU socket solely to have more memory in a system, except it is much less expensive than adding another CPU to a system.
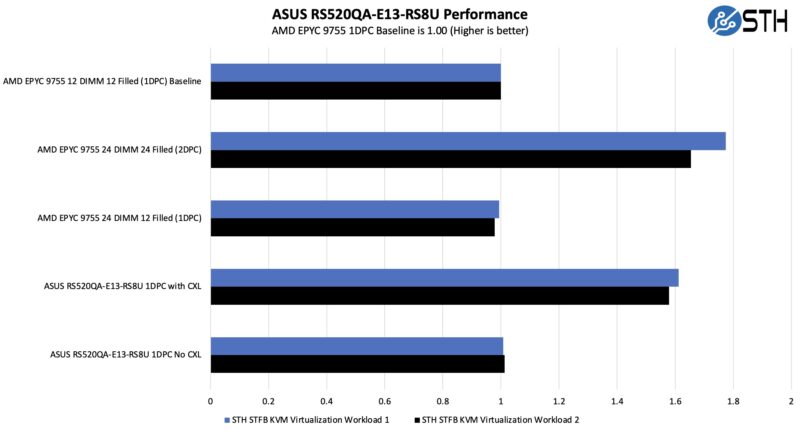
That is a bit complex, but here is what we came up with to show that. We set up both 12-DIMM and 24 DIMM platforms and ran two of our KVM virtualization workloads on it. Since we are using the number of VMs that can be supported, the memory capacity matters quite a bit. For our normal Workload 1, we are more memory capacity than memory bandwidth bound. For Workload 2, we are still constrained by capacity but are also memory bandwidth bound. The way to interpret the chart above is that the main DDR5 speeds on the system continue to operate at full speed.
Running at a higher capacity with 2DPC means we can get 24 DIMMs installed in a system which gives us more capacity than running 20 DIMMs (12 direct and 8 CXL.) At the same time, we lose performance due to downclocking memory with 2DPC which is why the delta between Workload 1 and Workload 2 is bigger in that case versus the CXL setup.

The other practical challenge is that you cannot fit 24 DIMMs across a half-width node, so you would halve your node density using 2DPC full-width servers.
That is why this server is so cool. We get memory capacity and bandwidth without requiring a second CPU while maintaining density.
Next, we are going to get to our key lessons learned.



{kind=link}
It’s nice, but I much prefer CXL memory expansion to be sharable between all the CPUs in a box instead of being a much simpler expansion, where a block of memory (8 DIMMs per node times 4) is not fully shared (32 DIMMs splittable (dynamically allocated) between 4 nodes). Examples in STH articles: “Lenovo Has a CXL Memory Monster with 128x 128GB DDR5 DIMMs” and “Inventec 96 DIMM CXL Expansion Box at OCP Summit 2024 for TBs of Memory”.
what kind of application need so much memory but very few storage & PCIe extension ?
Comments are closed.