Performance and Optimization
Let us quickly discuss the performance of this setup. The goal was to run Kimi K2.5, but it has run dozens of models, often with many quants per model. Here is the test bed, and also something that we noticed
A quick word on those notes. We were only getting around 140Gbps on the network side. It looks like this is an SMMU ceiling for the platform.
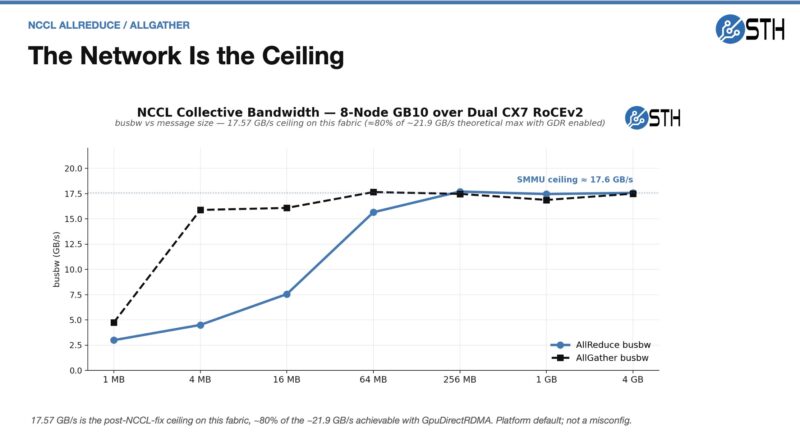
The kernel default on the GB10 is iommu.passthrough=0. NVIDIA’s own RDMA setup guide tells you to leave it alone. The 12.7 Gbps per-port direct-DMA cap is inherent to that mode, not a misconfiguration. NCCL on GB10 does not use GpuDirectRDMA it uses CPU-staged copies, which sidestep the SMMU DMA-FQ cap. That is why the 8-node AllReduce hits 17.57 GB/s despite the per-port direct-DMA number being so much lower. That is constraining our NCCL performance somewhat, so we are probably getting like 80% of the scaling we could if this were not something we ran into.
Taking a quick look at the sustained prefill, here is what we saw just using Qwen3.5-397B as an example:

NVFP4 really helped the GB10 cluster rip through these, albeit this was only at TP=4, so using half of the nodes.
On the generation side, GPT-OSS-120B did really well:
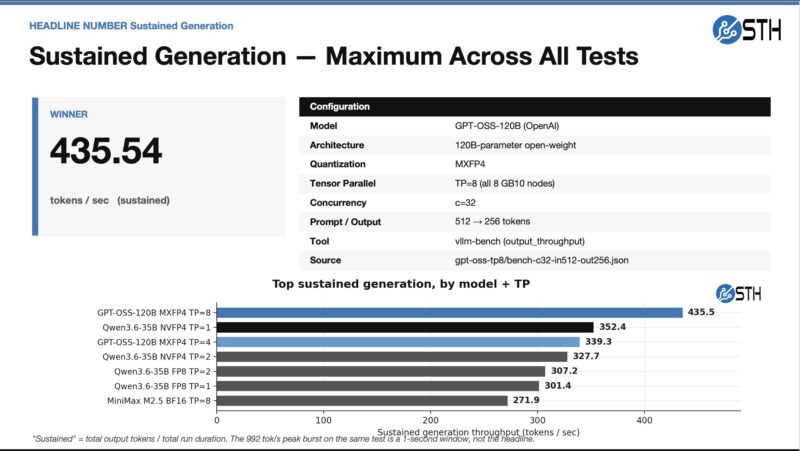
Of course, all of these numbers will change with new software versions and so forth, so take these as a point-in-time snapshot of what is happening. There are also other quantizations available, so again, just take this as a snapshot. Let us move on to some of the more focused results.
Kimi K2.5 and Kimi K2.6 Results
Something that kept this from going live is that we ended up in a cycle where we would be about ready to go live, but then a new model would come up, we would run it through benchmarks for a day, then record that, and have it hit the editing queue. After that was done, another model would come out. Here is an idea of Kimi K2.5 performance and K2.6 using the Moonshotai INT4 quant on HuggingFace:
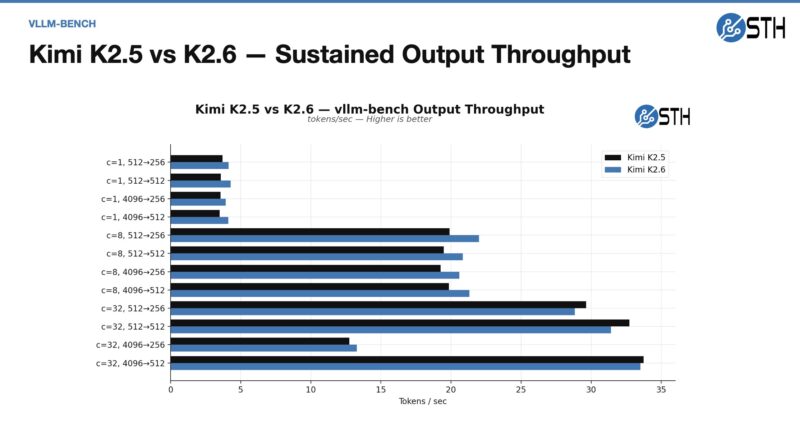
Here is the decode performance:
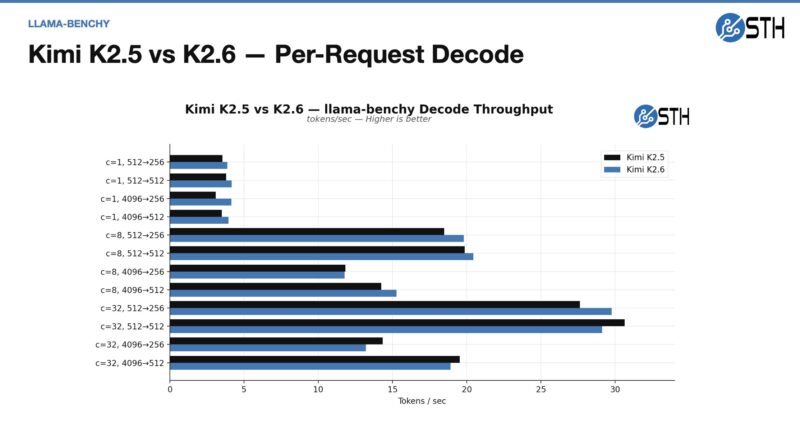
In theory, these should have been the same, or at least closer, but here is the summary of the concurrency of what we saw.

That was an interesting finding, and combined with model advancements, is one reason we will use K2.6 over K2.5 on this cluster, even though the goal was to run K2.5.
Qwen3.5-395B-A17B Insights
I think folks know I am a big fan of Qwen3.5-397B-A17B. Here are the single-user results, which are not super-fast since there are only 17B active parameters.
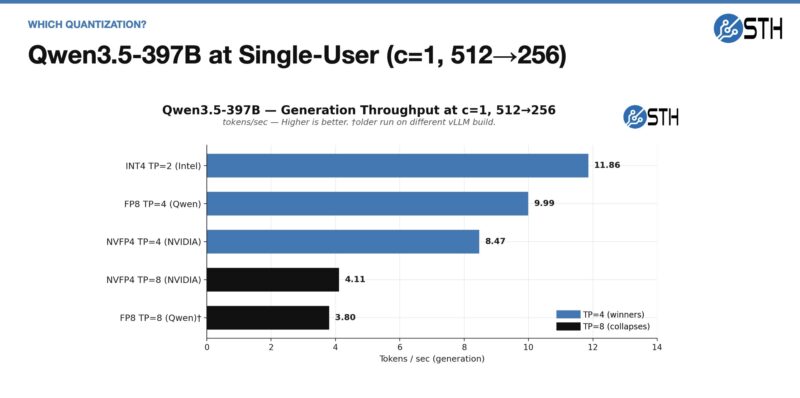
When we crank up the concurrency, however, we can also significantly increase speed.
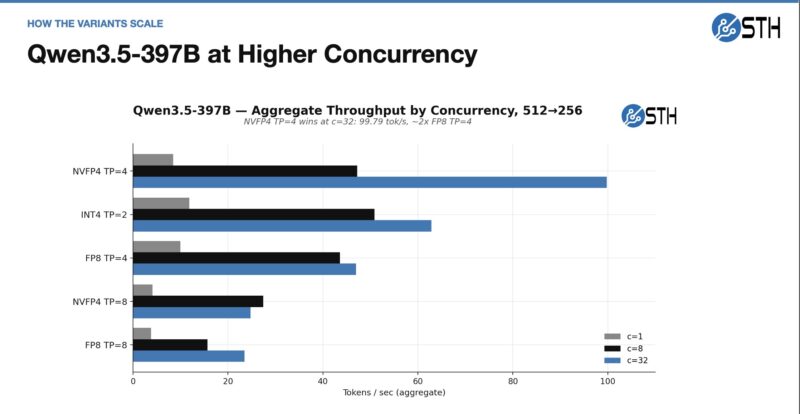
Something we have heard but is not necessarily true is the idea that moving from a model that fits on one node to eight nodes means you get 8x 273GB/s of memory bandwidth and more GPUs, so it will run much faster on eight nodes than on one. That is false. The penalty for going from a single node to an allreduce function, even on the fast 200Gbps networking, is non-trivial. Indeed, the best guidance I can give is that denser models tend to run better on the cluster and to keep models running on as few nodes as possible to avoid the communication performance hit.

Our basic summary here is that since this can fit on 4-nodes, run it on 4-nodes, not eight.
GPT-OSS-120B Insights
GPT-OSS-120B is not the biggest model, and frankly, is one that we were using a lot to end 2025, but newer models have eclipsed it. Still, we wanted to check what would happen if we scaled from a single node to multiple nodes.
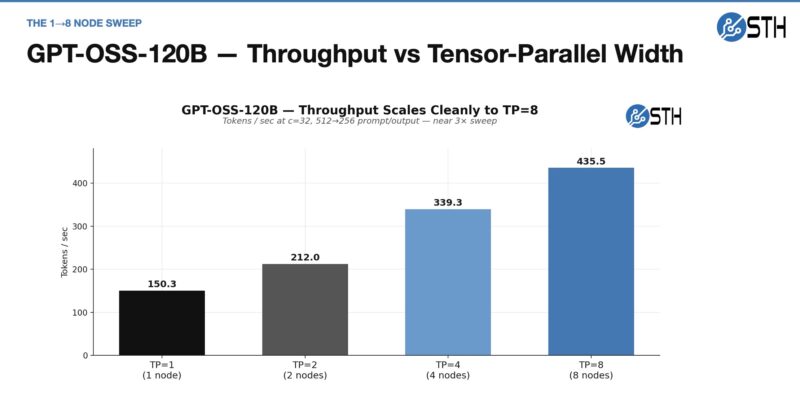
You can see the immediate impact of scaling from the single node to the second node, as we are not getting anywhere near a 100% increase. This is because we are going over the network and taking that performance penalty of moving off-node and coordinating work. We also wanted to see the impact of scaling on concurrency.
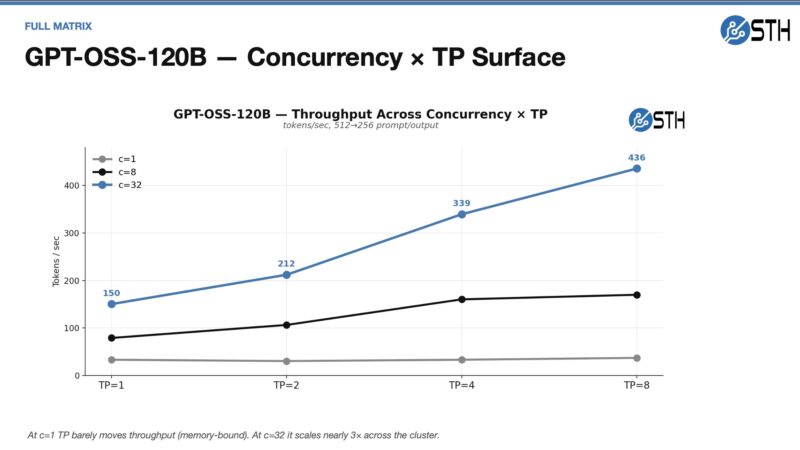
As a quick note here. If you just ran eight separate instances on GB10 nodes at 32 concurrency, that would be around 1200 tokens/ second. For some, that may be a much better option.
My best advice for performance is to check out Spark-Arena. Folks in the NVIDIA GB10 community are working on performance every day. Frankly, because all Blackwell GPUs are not equal, sometimes new optimizations come along for the GB10 platform and can significantly increase performance. That project is great and one that will keep you better informed on the overall performance.
Next, let us get to the power consumption and noise.



{kind=link}
This is f*n awesome. Good on ya bro
BEST piece you’ve done recently. Wow. It makes me only want a 4N not 8N
This is indeed one of your best articles in years. My 2-node cluster will keep me entertained for a long time. Maybe one day I will go up to 4 nodes, we shall see.
The MikroTik CRS804 is perfect for a 4-node cluster, 4x200G for the RoCE, 4x100G for storage, and the last 400G port facing the NAS.
Have you tried implementing TurboQuant on the cluster? I am curious to see how long context windows impact the available vram over time and how TurboQuant might help.
Great article especially showing how you leveraged ai to set everything up!
Repost from the STH Forums, not sure which spot is better for responses:
Fantastic article. I’m running 4N right now, was/am still considering a drop to 2N since the extra 2N arent necessary for all models but your point about the fungibility of having more/spare nodes is excellent.
Very interesting to see the callout on using a flash NAS for shared storage – would love to hear more on best practices for this, especially the situations where a little more GPU in the NAS makes sense. Next click stop for my cluster is the addition of a flash NAS based on the ARR 1U E1S you guys reviewed a while back, but I hadn’t even considered putting a GPU into it. Would love more details on this.
Also if you’re taking requests a network diagram would be fantastic. I’m running 2x 804DDQs to handle the 4N + flash + uplinks + mgmt bit I’m nowhere near settled on the topology, would love to see how you ended up structuring the full cluster network including NAS & DDQ trunks / uplink.
Lastly, WTH was Ubiquiti 10G switch you were showing?! It definitely wasn’t the Pro XG-8 PoE (no screen) and AFAIK there’s no other UI 10G switches that aren’t rack mounted. I’m pretty familiar with the UI lineup and the only unit I know that looks like what you showed was the Enterprise 8 PoE (Vintage) model!
What tool or service did you use to get the stats for all the power and servers
I thought your SM Xeon 6 SOC review was unreal good. This is even better. I think I’m more sold on a 4N not and 8N but the M3 Ultra’s prefill is doggy doo doo. I’m lovin’ your new articles Patrick.
One that I wish you’d done is the QNAP 100G and 25G switch. If you’re only getting 140G then maybe it’d be better to just do 100G
I don’t get the tube comments where they’re so dead set on being the permanent underclass.
Use basic punctuation in your titles. I had a stroke trying to read it.
@El Porto & Peter – Patrick touched on it briefly in the video, but the general idea is the GB10 Connectx7 interfaces (and the CRS804 switch) are purely for inter-node coordination as they are running RoCE.
NAS and management traffic are all on the 10G NICs.
Deviating from that pattern would likely degrade model performance.
Regarding cluster size, I’ve been pretty happy with a 2 node with a simple DAC. An alternative (cheaper) way to scale out could simply be to add a totally separate 2n cluster, and load balance the LLM API requests.
I read about 8. Now I’m ordering a 4-node cluster.
Look at high-capacity DIMM pricing. If you get the 1TB you’re paying for the 128GB, maybe the SSD, but then the CPU, GPU, and NIC are free. These aren’t getting any cheaper. You aren’t going to get a better deal on this much VRAM.
Apple stopped selling the studio 512 because the spot pricing of the memory alone is approaching $15k.
Awesome writeup. STH is crushing it!
Has anyone been able to PXE boot their DGX spark? I want to provision it with MAAS but it always hangs. Is it possible to PXE from the connectx instead of the realtek?
Hi!
“On the MikroTik CRS812 DDQ, set up MTU, PFC, ECN, and all of the QoS bits needed.”
What is your RouterOS version? AFAIK PFC and ECN are not yet supported in v7.21.4 (long term) or v7.22.2 (stable), and are mandatory (?) functions for lossless RDMA connections.
Are you using v7.23b/rc?
Thank you
Amazing work!!
GB10 follow-up: standard RDMA benchmark falsely reports broken fabric on GB10 — characterized with independent probe, 24 GB/s NCCL on 3-node dual-rail MikroTik CRS804 build
Hi STH team,
Your 8x GB10 cluster article and the ConnectX-7 networking deep-dive were the reference points for our 3-node GB10 build (Dell Pro Max FCM1253, dual-rail RoCEv2, 2× MikroTik CRS804 on RouterOS 7.23.1). Along the way we found something your readers building GB10 clusters will hit: ib_write_bw deterministically reports a hard 64 KiB RDMA WRITE ceiling on this platform — responder-side local protection errors, 72/72 failing cells across every node pair and RDMA device — that does not actually exist.
We characterized it fully before concluding: an independent minimal libibverbs probe (with responder-side content verification) passes the identical MR/WR geometry at every size, and NCCL acceptance on the same fabric sustained 24.0 GB/s busbw (3-node all_reduce, full sweep, zero validation errors) with per-MAC byte counters balanced to 0.02% across both rails. Kernel version, IOMMU mode, firmware currency, MR flags, ODP, and relaxed ordering were each eliminated by dedicated experiment. Two unresolved NVIDIA forum threads from 2023 (CX-5) and 2024 (CX-7/KVM) show the same boundary and syndrome — this has been biting people quietly for years.
Full writeup, elimination matrix, and probe source: https://github.com/linux-rdma/perftest/issues/394
Community PSA with GB10 cluster-builder notes (NCCL topology trap, counter methodology, 4-subnet/ARP-discipline config that produced perfectly symmetric MAC loading): [YOUR-FORUM-POST-URL]
Happy to share the dual-rail CRS804/RouterOS 7.23.1 configuration details or run comparison tests if useful for a follow-up piece.
Jacob Johnson