
Google today announced its 8th-generation Tensor Processing Units (TPUs), comprising the TPU 8i for inference workloads and the TPU 8t for training. The new accelerators represent Google’s continued investment in custom silicon, though they arrive in a market where NVIDIA maintains a dominant position. Google also discussed why splitting its TPU series is important.
The TPU 8i targets inference deployments with claims of significant performance-per-watt improvements over previous generations. The TPU 8t focuses on training workloads, scaling to large pod configurations for frontier model development. Both chips continue Google’s strategy of vertical integration, designing custom silicon optimized for internal workloads while also offering cloud access through Google Cloud Platform.
Google TPU 8i: Inference-Focused Architecture
The TPU 8i introduces architectural refinements focused on inference efficiency. Google claims improved sparsity support and enhanced matrix multiplication units optimized for common inference patterns, including transformer-based models. The chip supports multiple precision formats, with particular emphasis on INT8 and FP8 operations common in production inference deployments.
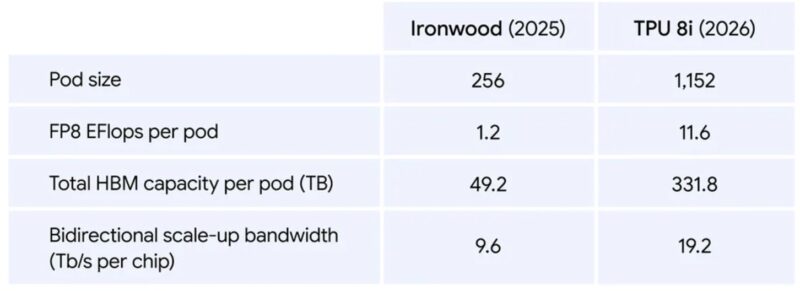
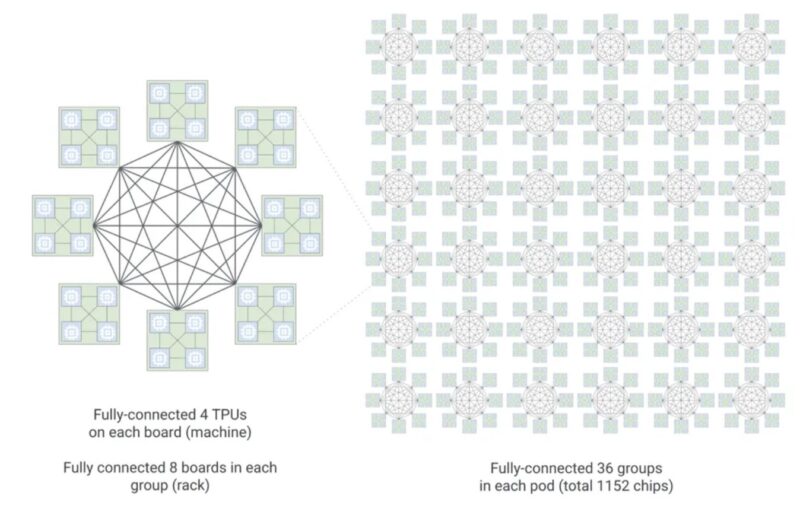
The 8i incorporates Google’s Boardfly hierarchical network topology, enabling efficient scaling from individual boards to large multi-rack configurations. This topology supports up to 1,152 chips organized into 36 groups across 8 boards, facilitating efficient all-reduce operations critical for distributed inference workloads.
The TPU 8i platform integrates Google’s Axion Arm-based CPUs for host processing at a 2:1 TPU-to-CPU ratio.

Previously, Google had been using x86 CPUs for its TPU nodes, so that is a big win for Arm.
Google TPU 8t: Training at Scale
The TPU 8t scales training performance by increasing compute density and enhancing interconnect bandwidth. Like its predecessors, the TPU 8t supports pod-scale deployments where thousands of chips operate as a unified training fabric. Google’s hierarchical network topology enables scaling across multiple rack boundaries while maintaining efficient all-reduce operations critical for distributed training.
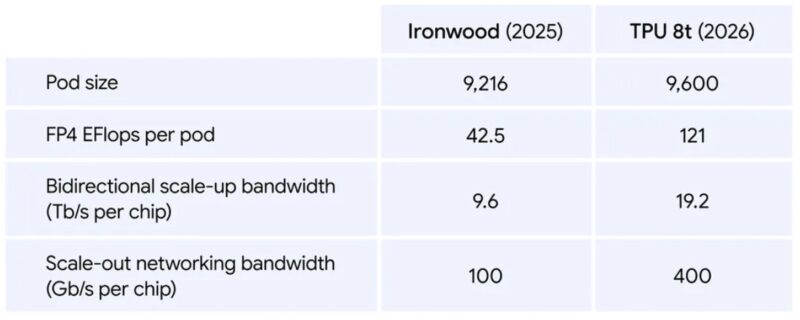
The 8t generation builds on lessons from Ironwood (TPU v7), which introduced expanded precision support and broader cloud availability. The TPU 8t extends these capabilities with improved efficiency metrics and larger pod configurations designed for frontier model training requirements.
Final Words
Google’s TPU program has evolved through multiple generations, expanding from inference-only designs to full training capability with pod-scale networking. The current generation builds directly on the Ironwood architecture:
- TPU v7 (Ironwood): Expanded precision support and cloud availability – See previous ServeTheHome coverage on Ironwood TPU architecture
- TPU v8i/v8t: Specialized inference and training variants with hierarchical scaling
Despite this progression, TPUs remain primarily deployed within Google’s infrastructure and offered through Google Cloud. Unlike NVIDIA’s broad ecosystem spanning enterprise, cloud, workstation, and edge deployments, TPUs serve a narrower market segment. This focused approach enables optimization for specific workloads but limits general applicability. It is really interesting since Google has an alternative to NVIDIA architectures, but one could argue that NVIDIA is more portable because there are so many providers offering GPUs. This space is fascinating.
Google’s TPU 8i and TPU 8t represent continued investment in custom accelerator architecture. The inference-focused 8i targets production deployment efficiency, while the training-oriented 8t scales to frontier model requirements. Google’s hierarchical network topology enables efficient pod-scale operations, though real-world efficiency depends heavily on utilization patterns and software stack overhead. Sundar Pichai showed off the two chips in hand today as well.

The coexistence of TPU deployments with significant NVIDIA Vera purchases suggests that TPUs complement rather than replace general-purpose accelerators. Google remains a major NVIDIA customer despite years of TPU development, purchasing NVIDIA GPU accelerators at scale for workloads where CUDA ecosystem compatibility or specific hardware capabilities are required. Like NVIDIA, Google is utilizing a 2:1 accelerator to Arm CPU design in this generation. Just for some context, TPU 8 will be more of the Vera Rubin generation of hardware than the Grace Blackwell generation.
Google has been running the TPU program for a long time and has been using them in production, making them perhaps the pinnacle of hyper-scale ASIC designs, which makes them interesting. Plus, new hardware is always cool to see.



{kind=link}