AMD EPYC 9754 Performance
We are in a transition period between benchmarking CPUs. We still have some single instance workloads, but realistically, there are increasingly fewer CPUs that run single workloads across 60 or 96-core processors. HPC may be an example, but in virtualization, a majority of VMs are 8 vCPUs or less. Containers and microservices have further increased diversity. Later in 2023, we will switch over to a more mixed environment than we even have today, as scaling single workloads is a challenge as they get more complex.

Bergamo is a great example of where many older workloads designed to scale across all cores on a system simply fail because of having a 256-core / 512-thread system.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
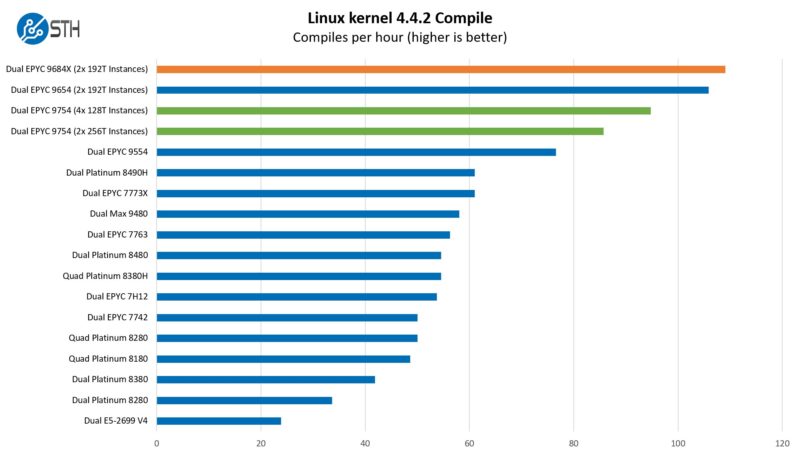
This is a great example of where scaling has become a challenge. With the larger 96 and 128-core AMD EPYC chips we get an enormous benefit, especially in dual-socket systems by splitting the workload up by CPU. While Genoa-X’s extra fast cache puts it ahead of the EPYC 9654 here, the short single-threaded points in the workload are not friendly towards Bergamo. That is one of the reasons we get such a large jump by splitting the workload up into 64-core/128-thread segments on Bergamo. The AMD EPYC 9754 is built to be a cloud-native processor running many tasks simultaneously, not a chip running one task across all 128 cores that can get stalled by a single-threaded operation.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. Here are the 8K results:
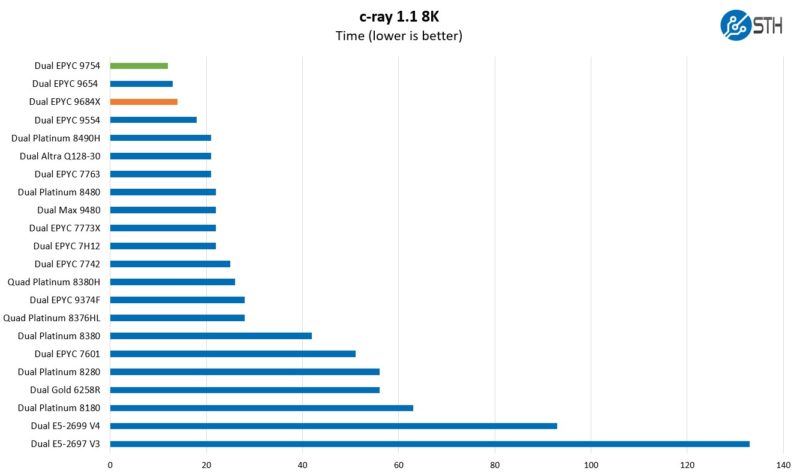
Our c-ray 8K benchmark behaves much like a Cinebench on Windows. It is somewhat amazing to think that this was a benchmark that would take minutes to run on most systems when we started. Now it completes so fast that seconds are not a high enough resolution. Here, the AMD EPYC 9754’s cores are filled, so we get better performance. This is not a benchmark that needs more cache, so we see the EPYC 9648X as having a clock speed deficit and the 1.1GB of 3D V-cache is not helping.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench. We are using our legacy runs here to show scaling even without hitting accelerators.
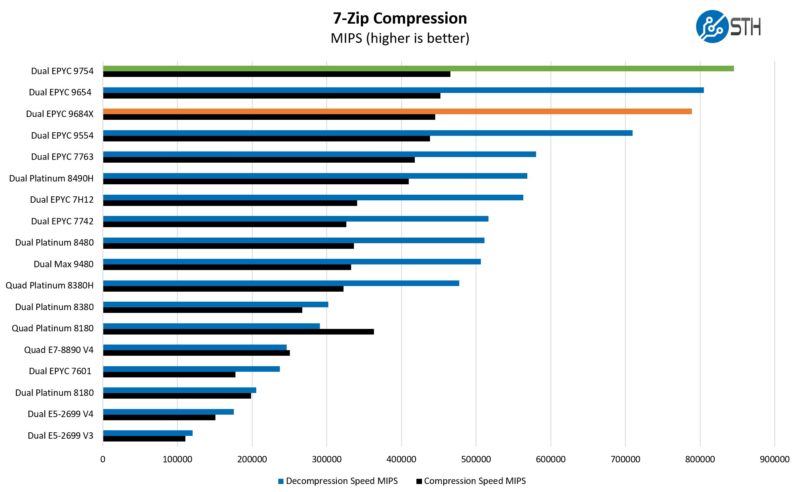
If you are still running Intel Xeon E5 V3/ V4 chips or even Skylake generation Platinum 8180’s, we are now at the point where we are seeing 4x-7x consolidation ratios possible. Even with the higher power consumption of these modern servers, the total power consumption is much less.
SPEC CPU2017 Results
SPEC CPU2017 is perhaps the most widely known and used benchmark in server RFPs. We do our own SPEC CPU2017 testing, and our results are usually a few percentage points lower than what OEMs submit as official results. It is a consistent ~5% just because of all of the optimization work OEMs do for these important benchmarks. This is a bit different than a normal launch since OEMs have already published performance numbers, so it feels right to use the official numbers if we are talking about a benchmark. On some of the new chips in these charts like the Intel Xeon Max 9480 and AMD EPYC 9648X and EPYC 9754, we were a consistent ~5% lower than published top scores.
First, we are going to show the most commonly used enterprise and cloud benchmark, SPEC CPU2017’s integer rate performance.
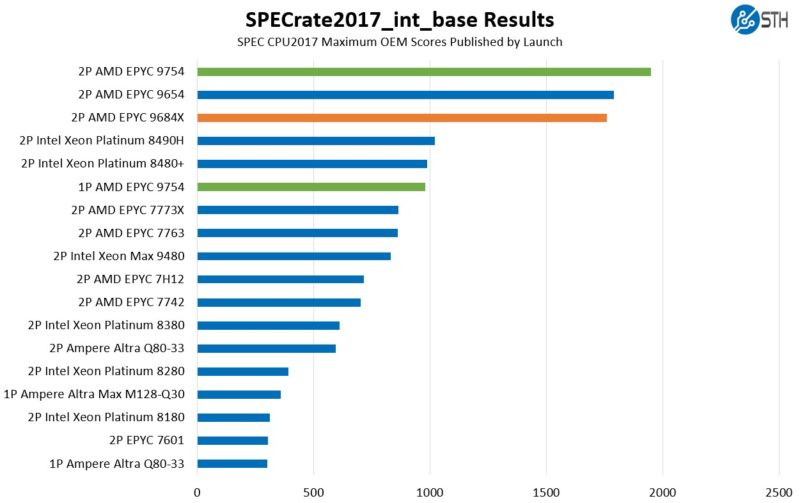
SPEC CPU2017 is designed to scale across all cores in a system. As a result, 128 cores performs predictably well.
Here is the floating point chart:
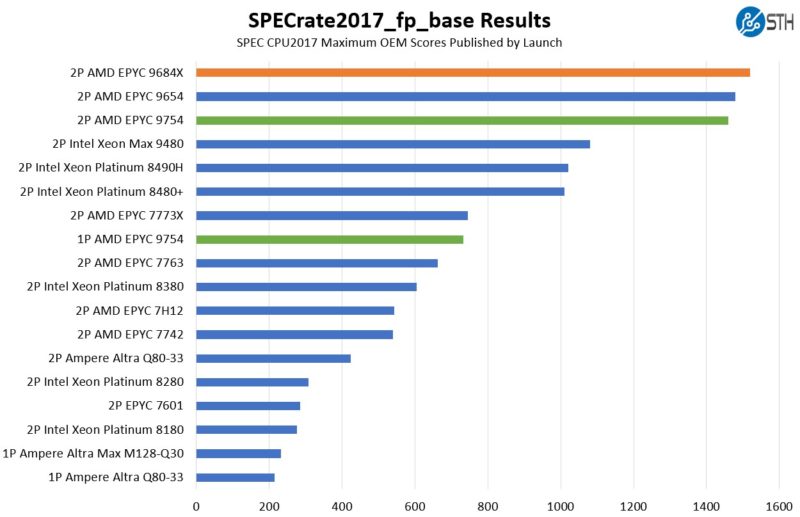
When we saw our internal “estimated” figures, we thought that we had an anomaly. Then we checked what OEMs were getting and they saw the same thing. While Intel is saying its customer workloads no longer mirror SPEC CPU2017, these are still important figures. There is a very valid point that things like QAT crypto/ compression and AMX for AI inference are not represented in these figures. In the enterprise and government space, this is a common RFP metric.
Something else that we wanted to call out here, is the “cloud native” segment. Since OEMs focus on the best possible optimizations when they submit, there is not a gcc baseline. On one hand, gcc will decrease performance for Intel and AMD. On the other hand, with the push for AI everywhere, we have been seeing STH readers that ask for consultations talk about using more proprietary compilers and accelerators. Three years ago, the chatter was pushing for gcc-only. Perhaps with NVIDIA CUDA and other proprietary optimization technologies, maybe the pendulum is swinging the other way. It has been an enormous change that we have seen recently. The gcc figures still matter, but in a world where folks are talking about switching to liquid cooling to get 12-15% lower power consumption, getting 20%+ performance by simple software optimizations seems like low-hanging fruit.

That is important because the Arm-based Ampere Altra Max is quite a bit behind the AMD EPYC 9754. AMD’s performance on SPEC CPU2017 is roughly 3x the Altra Max at 128 cores. When we get to power, keep this in mind because AMD is nowhere near 3x the power consumption. To be fair, Ampere has its AmpereOne shipping to hyper-scalers, so an Altra Max 128 core to a Bergamo 128 core is roughly a 2-year gap in chip releases.
STH nginx CDN Performance
On the nginx CDN test, we are using an old snapshot and access patterns from the STH website, with DRAM caching disabled, to show what the performance looks like fetching data from disks. This requires low latency nginx operation but an additional step of low-latency I/O access, which makes it interesting at a server level. Here is a quick look at the distribution:
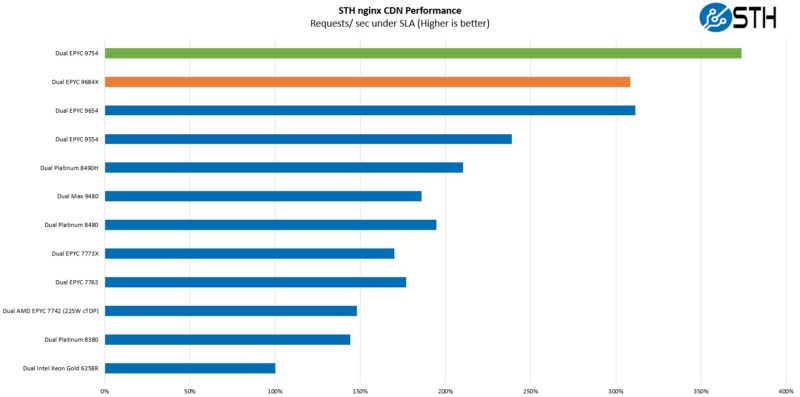
Transitioning to a more real-world workload, this is one that hits home for us. We are using STH’s actual website data to see how new chips perform. We were slighly surprised with our Genoa-X results. They seem to be lower based on clock speed. Then again, it was a similar picture with Milan and Milan-X.
This feels like a very cloud-native workload, running the STH main site. Here the AMD EPYC Bergamo is awesome.
MariaDB Pricing Analytics
This is a personally very interesting one for me. The origin of this test is that we have a workload that runs deal management pricing analytics on a set of data that has been anonymized from a major data center OEM. The application effectively is looking for pricing trends across product lines, regions, and channels to determine good deal/ bad deal guidance based on market trends to inform real-time BOM configurations. If this seems very specific, the big difference between this and something deployed at a major vendor is the data we are using. This is the kind of application that has moved to AI inference methodologies, but it is a great real-world example of something a business may run in the cloud.
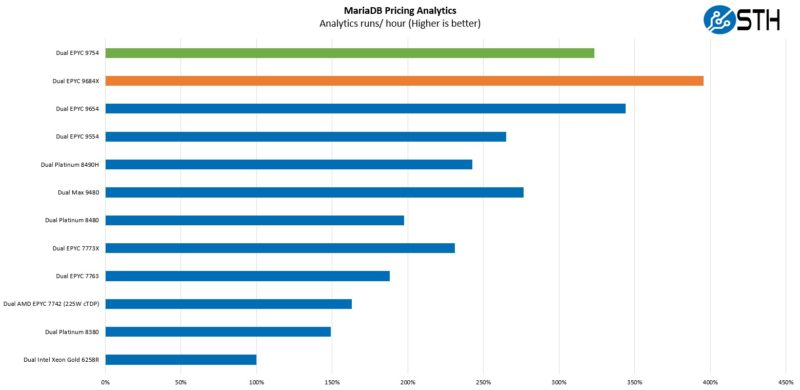
As with Milan-X, Genoa-X is a monster here. Conversely, this is a workload where the smaller caches and lower clock speeds of Bergamo do not do this any favors. Giving some sense, the genesis of this application was something that was saving a large OEM several millions of dollars per year in sales operations/ pricing overhead. While we think that high-end chips may be expensive, this is the type of application where you are getting payback on hardware costs in a matter of hours.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker. This is very akin to a VMware VMark in terms of what it is doing, just using KVM to be more general.
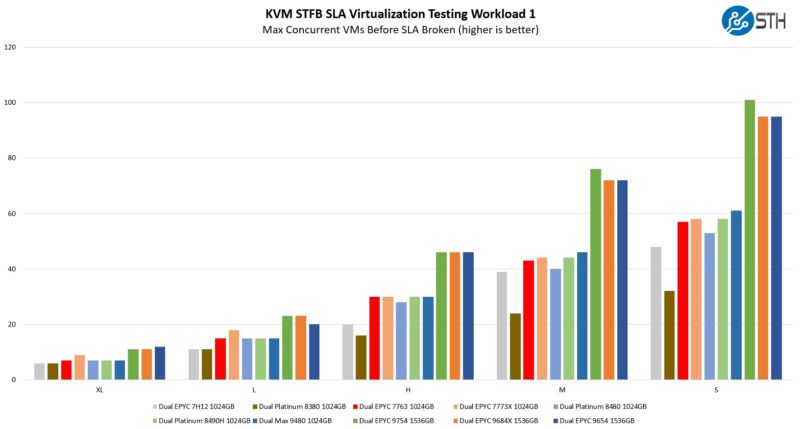
Many of the larger VM sizes are actually memory bound. Since we fill all memory channels for each platform, Intel is at a disadvantage on the larger VM sizes simply due to having 1TB of memory using 64GB DIMMs (8 channels, 2 processors, 64GB per channel), whereas AMD has 1.5TB in 12 channels.
When we get to the smaller VM sizes, Bergamo shines.
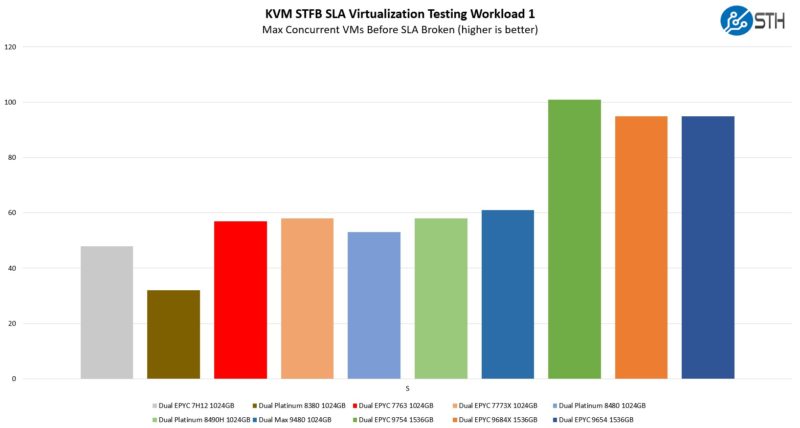
The 128-core AMD EPYC 9754 is simply awesome. This is perhaps the test that we were most concerned about for Bergamo. We saw the ability of the chip to sustain all core 3.1GHz, and this is where we would have seen that falter. Instead, the cloud-native Bergamo notched another win. Perhaps that should not have been surprising given that the chip was designed for heavy virtualization workloads.
Next, let us get to the power consumption.
AMD EPYC 9754 Power Consumption
AMD’s latest SP5 chips use power that is fairly close to the TDP specs. In that way, they tend to behave more like NVIDIA GPUs and CPUs from Ampere. For a 360W AMD EPYC 9654 we would expect around a 450-550W single socket maximum power consumption. Dual socket is often in the 800W to around 1.1kW depending on a configuration. With the AMD EPYC 9754, we saw very similar while Genoa-X was a bit higher.
Power consumption is perhaps the most shocking. We often hear that Arm servers will always be better on power consumption than x86, but in the cloud native space, that is only part of the story. With our AMD EPYC 9754, we had SPEC CPU2017 figures that were roughly 3x its only 128-core competitor, the Ampere Altra Max M128-30. Power consumption was nowhere near 3x. In our recent HPE ProLiant RL300 Gen11 Review, we were seeing a server maximum of around 350-400W. In our 2U Supermicro ARS-210ME-FNR 2U Edge Ampere Altra Max Arm Server Review we saw idle at 132W and 365W-400W. We tested the Bergamo part in several single-socket 2U Supermicro servers that we have including the Supermicro CloudDC AS-2015CS-TNR and we saw idle in the 117-125W range and a maximum of 550-600W.

The impact of this is that AMD is now offering 3x the SPEC CPU2017 performance at similar idle but only around 50% higher power consumption. We fully expect Ampere AmpereOne will rebalance this, but for those who have counted x86 out in the cloud native space, it is not that simple.
Next, let us get to our key lessons learned and final words.


{kind=link}
Nice review.
I noticed that you put chose the CPU carrier colors in the performance graphs ;-)
Somehow the reduced cache reminds me of an Intel Celeron. Does anyone really want a slower processor aside from marketing types selling CPU instances in the cloud?
If so, then since the AmpereOne has 2MB L2 cache per core, a competitive x86 design should have 4MB L2 per dual SMT core rather than Bergamo’s 1MB.
Eric, Having the full size cache that doesn’t make use of it in the cloud doesn’t count for anything if it isn’t being made use of (i.e spilling out of cache anyway or fitting into the reduced L3)
And also, less cache on this one also means lower latency. It sure isn’t slower, it has Zen 4 IPC still and is better optimized for lower clocks.
It sure ain’t no Intel Celeron that’s for sure.
Also every CPU arch is different, it’s useless to say a competitive x86 needs a big L2 cache
Because of course the Bergamo walks all over the Altra Max anyway. While being far more efficient
@Dave
Historical perspective on why the cache does and doesn’t matter.
Celeron 300A – 128k cache @ 300mhz vs Pentium 3 with 512k cache @ 450mhz
You could overclock that Celeron to 450mhz and 95% of your applications would function identially to the 3x cost Pentium III.
The 5% use case where cache does matter – was almost always a Database, and this shows clearly in the benchmarks here – MariaDB does much worse compared to the large-cache parts. And I saw this decades ago with the 300A as well, we were regularly deploying OC’d 300A’s to the IT department, but the guys doing a “data warehouse” coding a sync from an AS400 native accounting app to SQL servers that would be accessible for Excel users and a fancy front end …they in the test-labs were complaining. Sure enough cache mattered there. It ran, well enough really, but we bought a couple P3’s and it increased performance ~20% on the SQL’s in lab – end of the day the Xeon’s in the servers were plenty fine for production as they had the cache.
The AMD product sku’s are really really straightforward compared to Intel – I don’t think anyone is going to be confused on use-cases. Besides those big DB players are going to sell them pre-built or SaaS cloud solutions on these, they’ll do their homework on caches.
When there’s a new CPU release day, there’s 2 processes
a) Go to Phoronix look at charts, then come to STH for what the charts mean
b) Go to STH get the what and why, and if there’s something specific I’m going to Phoronix
I started 3 years ago on a) but now I’m on b)
“To me, the impact of the AMD EPYC Bergamo is hard to understate” Did you mean overstate?
I’m really wondering if those AI and AVX-512 instructions are worth the die area. I think for typical cloud workloads one really should optimize for workloads that are more typical, e.g. encryption is something that pretty much everyone does all the time while AI is a niche application and usually better served with accelerators.
Many, including me does CPU inference in the cloud on cheap small instances. Having access to AVX-512/VNNI is a huge benefit as it decreases inference latency. The advantage on doing this on the cpu is that you don’t need to copy the data to and from an “accellerator” which improves inference time for smaller models.
Nils, once avx-512 cat is out of the bag for cloud, it’ll get used. Even today gcc (C compiler) may optimize simple library operations (memcpy & co.) using avx-512. And what about for example json parser which is kind of cloud thing right? See for youself: https://lemire.me/blog/2022/05/25/parsing-json-faster-with-intel-avx-512/
@MDF
Thanks for the input. Indeed, having more cache is only useful if you can use it.
AMD has tailored the core specifically for the market and this could pay dividends especially on the consumer side which we might see soon (Phoenix 2 apparently?)
Although technically Phoenix APU cores are already Zen 4c without the optimization for the lower clock speeds (it’s already higher than 7713 mind!) But AMD could indeed take these cores and stick a smaller vcache on them and use it as a second CCD thus spawning a 24 core Zen heterogenous monster
I’m excited. More than can be said for intel’s bumbling efforts.
@MDF, the (Katmai) Pentium III’s 512kb L2 cache wasn’t full speed though. Started at half speed and as CPU freqs rose, the cache speed dropped to a third clock speed. Then we got Coppermine PIIIs around 700 MHz, which settled on 256kb on-die full speed cache.
Comments are closed.