Why the AMD EPYC 9754 is Fantastic
While today we have both the AMD EPYC “Genoa-X” and “Bergamo” launches, Bergamo is clearly the more impactful of the two. That is a lot to say given we know that Microsoft Azure is very fond of Milan-X and Genoa-X. Let us put together a few key points:
- The primary change for Zen 4c cores from Zen 4 is a halving of L3 cache.
- The AMD EPYC 9754 is showing performance ~3x a 128-core Arm competitor at 1.5x the power.
- An AMD EPYC 9754 is often twice the performance of 2019’s AMD EPYC 7002 “Rome” 64-core parts.
- On most non-HPC-focused workloads, expect the AMD EPYC 9754 to be 15-20% faster than the AMD EPYC 9654. That is not a straight 33% as we would expect due to the core count increase, but AMD is getting scaling from the increased core count even with a drastically reduced L3 cache size.
- AMD seems to have figured out an elegant way to reduce turbo clock jitter, especially at maximum load. That helps a lot with SLA on a loaded system.
- Cloud-native processors will make up a huge segment of the market.
The one image that is burned into my mind testing the AMD EPYC 9754 is this:
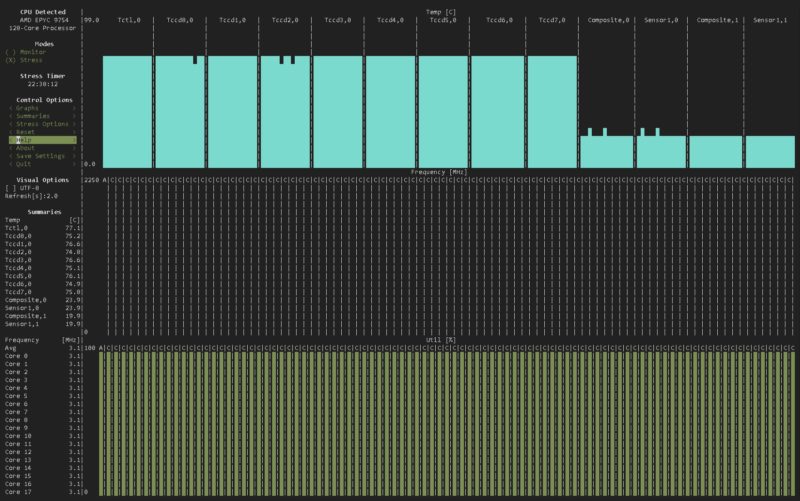
That is every core, 3.1GHz running 256 threads of stress-ng, fully heat soaked, but the clocks were constant even at high CPU temps. In the world of cloud-native where there is a focus on lowering performance variations, this image shows that every core can provide the same maximum clock speed at the same time. This is not common for EPYC and Xeon processors.

We expect that within five years, 25% or more of the CPU market will be for high-core count cloud-native CPUs. That number is low single digits today for some frame of reference. AMD’s approach is crazy in many ways. For example, why AMD EPYC 9754 need AVX-512 extensions? Other cloud-native processors have given up on floating-point performance and focused on integer performance. AMD’s difference is just cache size.

Looking ahead, Zen 4c should have the industry-shaking with fear. AMD’s chiplet strategy is very easy to follow. We have Genoa, and then Genoa-X with stacked 3D V-Cache. We now have Bergamo. In the next generation, imagine high core count, but lower L3 cache cores packed onto a package, with 3D V-Cache stacked above. It takes an embarrassingly small logical leap to see that as a way to greatly increase core counts in future generations.

One point that needs to be made clear is the density side. Ampere, with AmpereOne is doing something very smart. It has 192 cores without SMT. That means cloud providers can offer 192x single vCPU instances on a chip (minus some for overhead.) In AMD’s case, since there are two threads per core on the chip, AMD can offer up to 128x dual vCPU instances per chip. If there is one knock on Bergamo, it might actually be too fast because of AMD’s power-hungry I/O die. Cloud providers like Microsoft, Oracle, Google, and others gave Ampere a target performance figure for the Ampere Altra Max. As a result, Ampere tuned its chips to that target, plus some overhead. AMD is out with its part that is at ~3x the performance per core. It might actually be significantly more than what the performance target is for a cloud-native processor.
One will notice, there is not a lot of Intel Xeon talk in this section. That is because Intel is still focused on full-performance cores and has yet to launch its Intel Sierra Forest E-Core Xeon slated for 2024. If you want an off-the-shelf cloud-native processor today, you are buying either an Ampere Altra Max (soon AmpereOne) or an AMD EPYC Bergamo. This will change over time, but it is the state of this emerging segment. To be clear, I cannot wait for an E-core-only Xeon.
Final Words
As good as the new AMD EPYC Genoa-X part is (we included data in the charts here), Bergamo is the chip that will put the industry on notice. This is a drop-in replacement for other x86 chips. There is no discussion on having to port to Arm. AMD’s lower 3.1GHz limit has reduced clock speed ramping while providing solid and fair performance. Frankly, cloud-native processors are also the bigger market segment, which almost by definition makes Bergamo more impactful.

To me, the impact of the AMD EPYC Bergamo is hard to understate. An organization can deploy mainstream 32-core and 64-core Genoa parts for mainstream x86 applications. Specialized 16-core Genoa-X SKUs with 48MB of L3 cache per core or 96 core parts with 1.1GB of L3 cache per core can be added to a cluster for extreme software licensing or HPC workloads. For the sea of 4 and 8 vCPU VMs the AMD EPYC 7954 provides a meaningful upgrade in terms of density and lowering the cost per VM from a power and footprint standpoint. That portfolio all runs the same Zen 4 flavor of ISA which is different than Intel’s P-core and E-cores today, and especially swapping to Arm.

AMD now has an ecosystem of high-end chips that are fully compatible. That is a powerful message and one that we have not seen in the industry.
Where to Learn More
We have a video for this one that you can find:
We cover both the AMD EPYC 9754 “Bergamo” and the AMD EPYC 9684X “Genoa-X” in the video. As always, we suggest watching in a dedicated YouTube tab, window, or app for a better viewing experience.


{kind=link}
Nice review.
I noticed that you put chose the CPU carrier colors in the performance graphs ;-)
Somehow the reduced cache reminds me of an Intel Celeron. Does anyone really want a slower processor aside from marketing types selling CPU instances in the cloud?
If so, then since the AmpereOne has 2MB L2 cache per core, a competitive x86 design should have 4MB L2 per dual SMT core rather than Bergamo’s 1MB.
Eric, Having the full size cache that doesn’t make use of it in the cloud doesn’t count for anything if it isn’t being made use of (i.e spilling out of cache anyway or fitting into the reduced L3)
And also, less cache on this one also means lower latency. It sure isn’t slower, it has Zen 4 IPC still and is better optimized for lower clocks.
It sure ain’t no Intel Celeron that’s for sure.
Also every CPU arch is different, it’s useless to say a competitive x86 needs a big L2 cache
Because of course the Bergamo walks all over the Altra Max anyway. While being far more efficient
@Dave
Historical perspective on why the cache does and doesn’t matter.
Celeron 300A – 128k cache @ 300mhz vs Pentium 3 with 512k cache @ 450mhz
You could overclock that Celeron to 450mhz and 95% of your applications would function identially to the 3x cost Pentium III.
The 5% use case where cache does matter – was almost always a Database, and this shows clearly in the benchmarks here – MariaDB does much worse compared to the large-cache parts. And I saw this decades ago with the 300A as well, we were regularly deploying OC’d 300A’s to the IT department, but the guys doing a “data warehouse” coding a sync from an AS400 native accounting app to SQL servers that would be accessible for Excel users and a fancy front end …they in the test-labs were complaining. Sure enough cache mattered there. It ran, well enough really, but we bought a couple P3’s and it increased performance ~20% on the SQL’s in lab – end of the day the Xeon’s in the servers were plenty fine for production as they had the cache.
The AMD product sku’s are really really straightforward compared to Intel – I don’t think anyone is going to be confused on use-cases. Besides those big DB players are going to sell them pre-built or SaaS cloud solutions on these, they’ll do their homework on caches.
When there’s a new CPU release day, there’s 2 processes
a) Go to Phoronix look at charts, then come to STH for what the charts mean
b) Go to STH get the what and why, and if there’s something specific I’m going to Phoronix
I started 3 years ago on a) but now I’m on b)
“To me, the impact of the AMD EPYC Bergamo is hard to understate” Did you mean overstate?
I’m really wondering if those AI and AVX-512 instructions are worth the die area. I think for typical cloud workloads one really should optimize for workloads that are more typical, e.g. encryption is something that pretty much everyone does all the time while AI is a niche application and usually better served with accelerators.
Many, including me does CPU inference in the cloud on cheap small instances. Having access to AVX-512/VNNI is a huge benefit as it decreases inference latency. The advantage on doing this on the cpu is that you don’t need to copy the data to and from an “accellerator” which improves inference time for smaller models.
Nils, once avx-512 cat is out of the bag for cloud, it’ll get used. Even today gcc (C compiler) may optimize simple library operations (memcpy & co.) using avx-512. And what about for example json parser which is kind of cloud thing right? See for youself: https://lemire.me/blog/2022/05/25/parsing-json-faster-with-intel-avx-512/
@MDF
Thanks for the input. Indeed, having more cache is only useful if you can use it.
AMD has tailored the core specifically for the market and this could pay dividends especially on the consumer side which we might see soon (Phoenix 2 apparently?)
Although technically Phoenix APU cores are already Zen 4c without the optimization for the lower clock speeds (it’s already higher than 7713 mind!) But AMD could indeed take these cores and stick a smaller vcache on them and use it as a second CCD thus spawning a 24 core Zen heterogenous monster
I’m excited. More than can be said for intel’s bumbling efforts.
@MDF, the (Katmai) Pentium III’s 512kb L2 cache wasn’t full speed though. Started at half speed and as CPU freqs rose, the cache speed dropped to a third clock speed. Then we got Coppermine PIIIs around 700 MHz, which settled on 256kb on-die full speed cache.
Comments are closed.