AMD EPYC 7F72 Performance
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. Starting with our 2nd Generation Intel Xeon Scalable refresh benchmarks, we are adding a number of our workload testing features to the mix as the next evolution of our platform.
At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
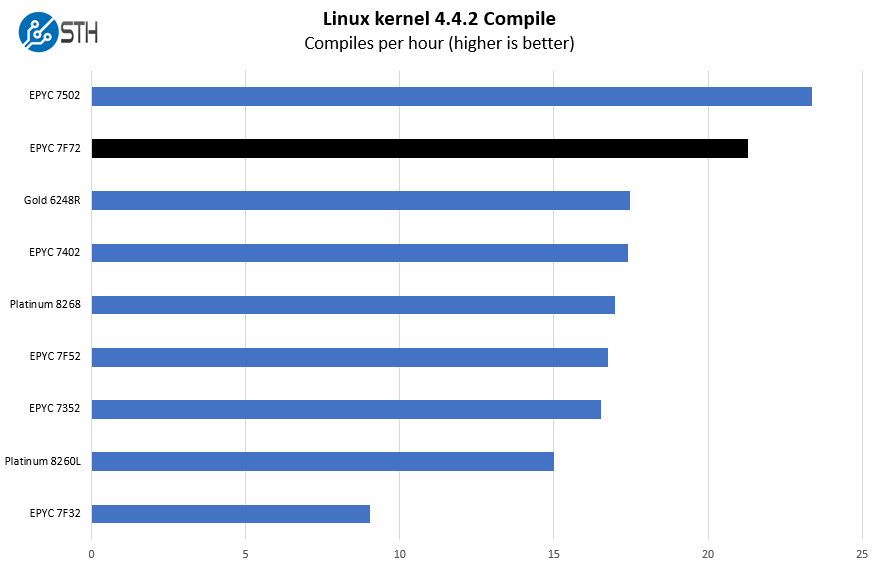
High frequencies, big caches, and a solid number of cores is a good recipe for compile benchmarks. As a result, the AMD EPYC 7F72 performs extremely well here.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
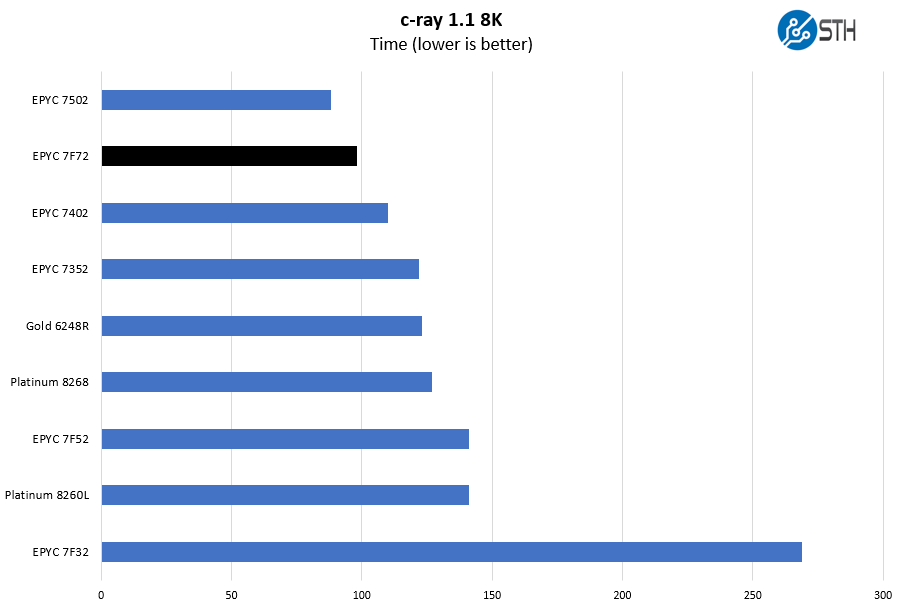
This is a benchmark that we started to use several years ago. There are architectural reasons the AMD Zen and Zen 2 chips perform extremely well here. Instead of looking at AMD versus Intel, it is best to look at AMD v. AMD here. As we can see, the extra clock speed bump really helps our c-ray 8K results. We do not hit the level of a 32-core chip, but the performance is still very good.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
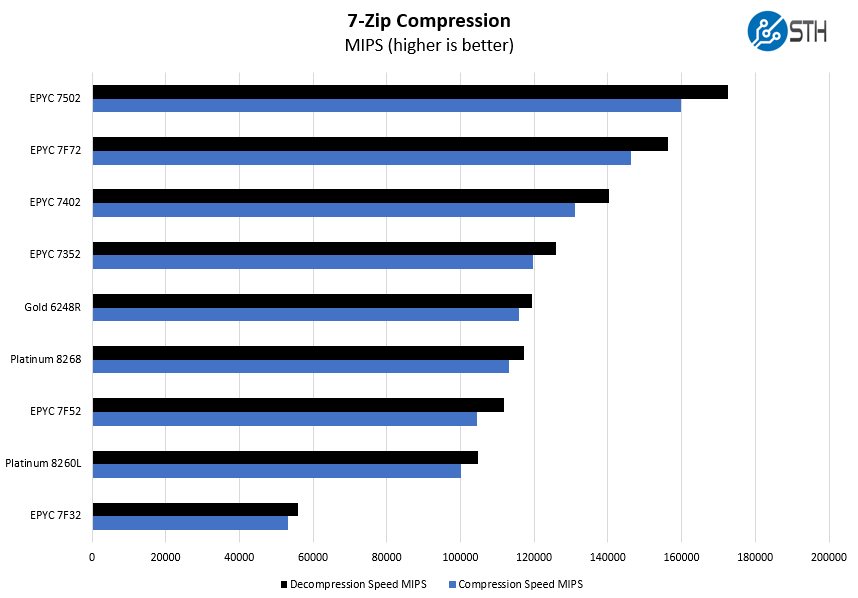
We should note here that Intel has compression accelerators with its QAT. We are starting to see Intel use compression benchmarks that utilize offload capabilities with either Lewisburg PCH, embedded, or add-in card accelerators. Still, this is a workload that the EPYC chips are performing well in.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. With GROMACS we have been working hard to support AVX-512 and AVX2 architectures. Here are the comparison results for the legacy data set:
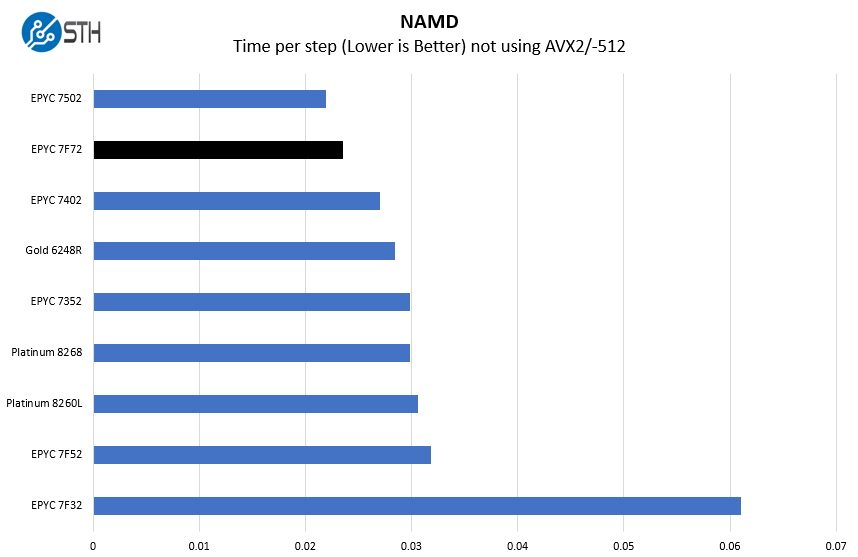
We decided to include all three frequency optimized “F” SKU parts for AMD. The 8-core AMD EPYC 7F32 distorts some charts like this due to having drastically lower core counts.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
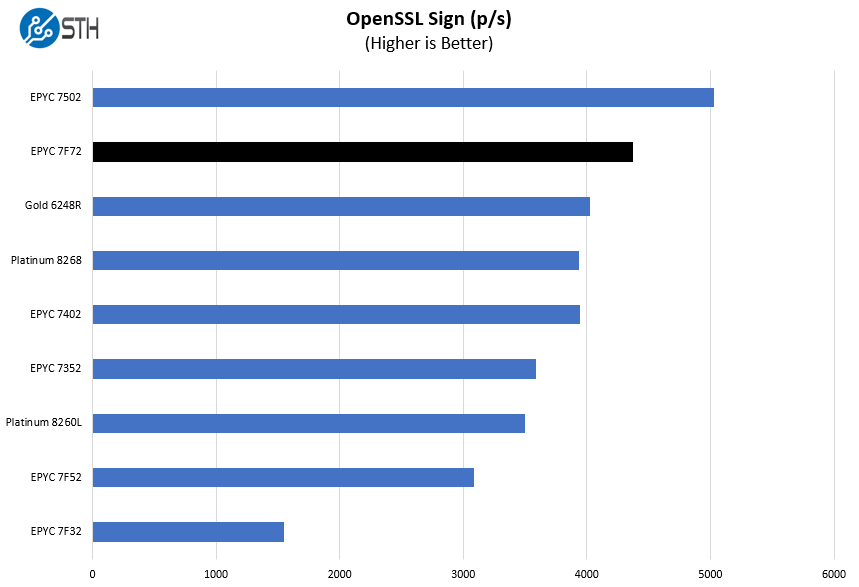
Here are the verify results:
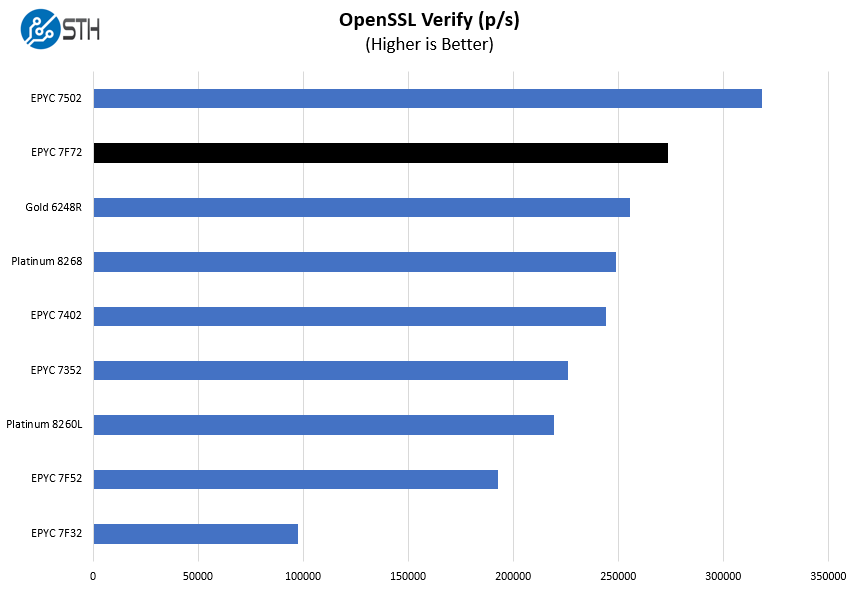
This is another classic workload that can be offloaded to QAT accelerators. While Intel generally does well on this benchmark using CPU cores, AMD simply has a bigger and faster CPU.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
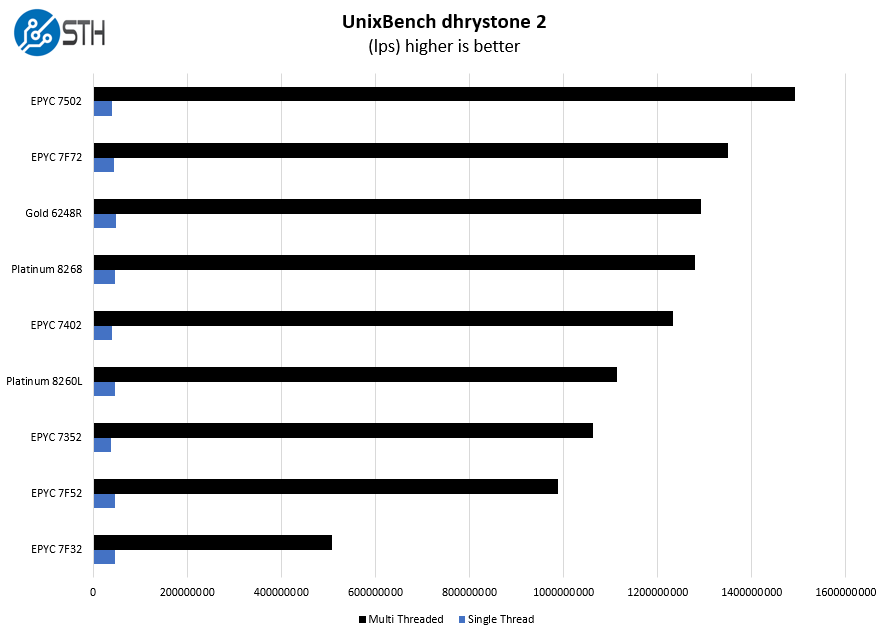
Here are the whetstone results:
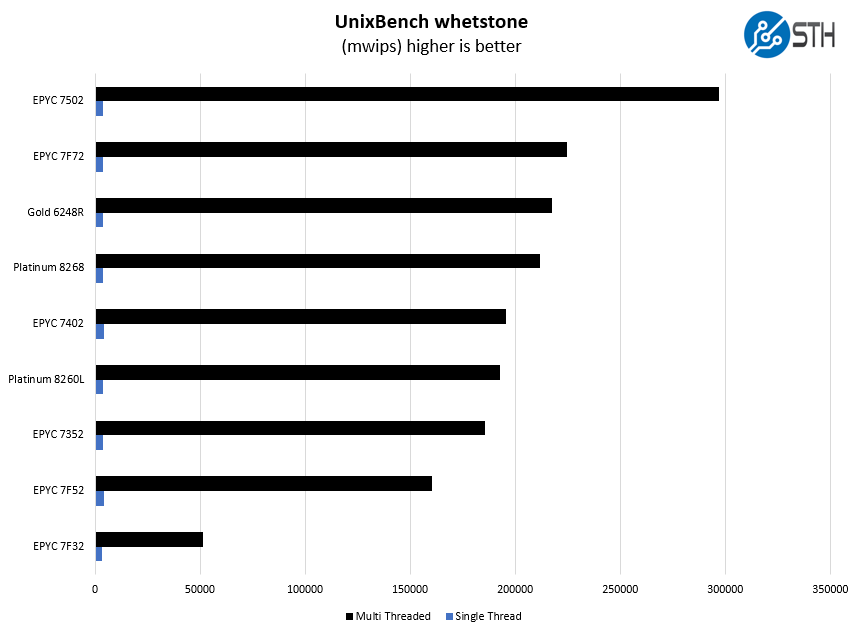
We wanted to point out the significance of the Platinum 8260L here. With the Big 2nd Gen Intel Xeon Scalable Refresh we got new Xeon Gold SKUs denoted with an R. Those SKUs are 2x UPI only and they do not have high-memory capacity support. As a result, the Platinum 8260L is a 24-core part that ends up in competition with the EPYC 7F72 if one is focused on memory configurations over 1TB.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and now use the results in our mainstream reviews:
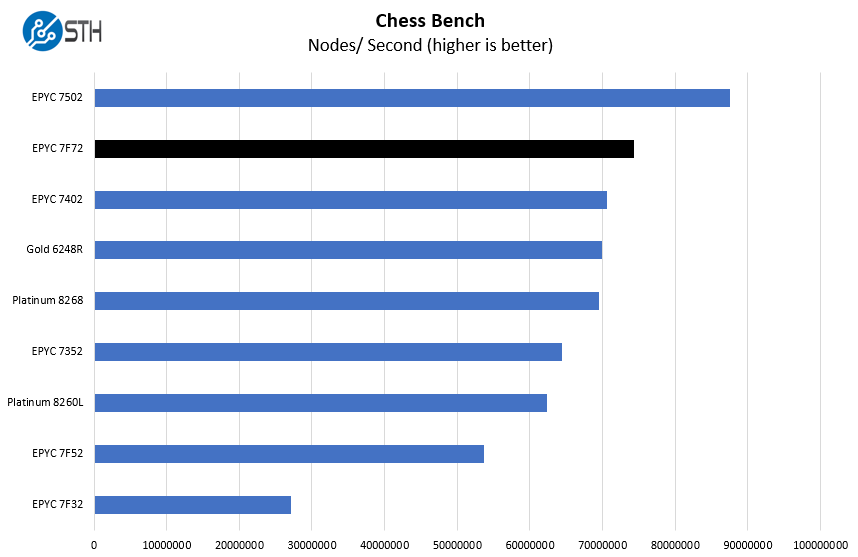
Here again, we see strong performance just ahead of the Intel Xeon Gold 6248R which will be a primary competitor. The AMD EPYC 7F72 is slightly less costly up-front. It has a much higher-TDP (240W v. 205W) which will hinder the EPYC part in dense dual-socket 2U 4-node configurations. Still, when it comes to per-core performance, the EPYC 7F72 performs extremely well compared to its most direct Intel Xeon competition.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker.
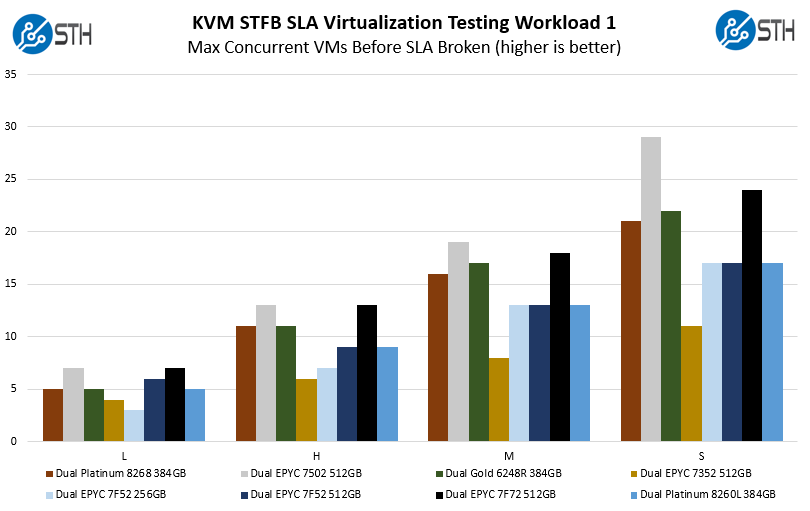
Here we can see the EPYC 7F72 performs slightly better than the 24-core high-end Xeon Gold 6248R. It cannot match the 32-core AMD EPYC 7502. This brings up an important aspect which is that if you do not need per-core performance, and can scale to more cores, then there are other better parts in the AMD EPYC 7002 Series.
SPECrate2017_int_base
The last benchmark we wanted to look at is SPECrate2017_int_base performance. Specifically, we wanted to show the difference between what we get with Intel Xeon icc and AMD EPYC AOCC results.
Server vendors get better results than we do, but this gives you an idea of where we are at in terms of what we have seen:
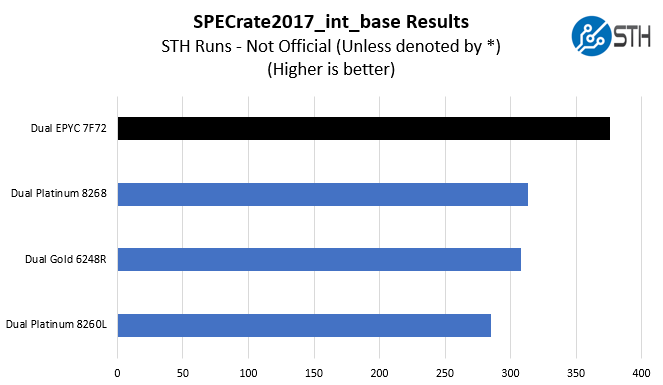
A few quick and important notes here:
- These are not vendor official results. For official results, see the official results browser.
- We are about 1.5-2% behind where AMD is with their estimates in marketing materials. That is close enough that we think that AMD is likely near what server vendors will publish.
- We are closer to 1% behind some of the vendor published results for Intel Xeon CPUs.
- Overall, we think this is a directionally correct view for comparison.
This is perhaps the biggest metric server buyers use in the space and AMD is performing very well here which seems to match the results we saw in our test suite. We wanted to point out something that you can see if you browse results on the SPEC website along with what we are seeing. Despite the slightly increased clock speeds, the Intel Xeon Platinum 8268 is actually faster than the Xeon Gold 6248R. There are cases where the Xeon Platinum 8268 still makes more sense than the Gold 6248R despite the latter being effectively similar but at a drastically reduced price. An example is in GPU servers where one would want a 3x UPI link Xeon CPU rather than a 2x UPI link refresh Xeon.
Whether you look at the similar price competition (Xeon Gold 6248R), the 3x UPI link direct competition (Platinum 8268), or the greater than 1TB of memory competition (Platinum 8260L) the EPYC 7F72’s recipe of high clock speeds, large caches, and high TDP allow the AMD part to provide great performance.
Next, we are going to get into the “so what” and discuss market positioning for the processor before giving our final words.



{kind=link}
I know STH dont normally write anything on stocks and quarterly reports. But I do wish STH write a pieces that suggest why EPYC is doing as good as most of us expected it to be. It has yet to break the 10% shipment barrier, all while Intel is making record quarter YoY in DC and HPC. That is all in the time when Intel 14nm is operating at full capacity and one node behind.
Most have been suggesting these things takes time, but it is already a year of Zen 2 and shows no signs of improvement.
Can we have the single threaded results for the UnixBench Dhrystone 2 and Whetstone Benchmarks on a separate axis or chat?
For a part that is specifically targeting better single threaded performance, it would be nice to have a little more focus on that aspect. A lot of problem domains enjoy multi-threaded environments, there are still others which focus on raw single threaded performance. A comparison here to Intel’s similar offerings would be very beneficial.
A great article as usual and I very much enjoy reading STH content, hopefully the feedback will be helpful. Thanks
@Stephen,
Given that this and the rest of the CPUs are intended for use in server system, why would single threaded performance matter?
Servers are purchased/justified on the basis that they provide resources for a number of tasks, so they are never running “one thing”. Further, single threaded processes would not be representative of real usage, since each CPU has there own inherent trade offs — higher base clocks vs. more cores/threads vs. TDP.
wow this is beast wondering how it will feel like setting this 24 core cpu as gaming pc by adding rtx 280 gpu along it.
Again an irrelevant review of a core frequency optimized part.
All your benchmarks shows that more cores are better than fewer but frequency optimized cores.
I sound like a broken record player repeating the same request over and over….
Please add variations of the benchmarks where there are 4 – 8 threads active!
That will show what these parts are made for and will also show the value of turbo modes, high TDP.
It may also show the only remaining performance reason to pick Intel in 2020.
@BinkyTo,
Latency sensitive applications care about single-threaded performance. We run multiple processes per server, there is of course a trade off between singled-threaded performance and number of cores available that we have to make. However doubling the number of cores while taking 20% off the clock speed is going to make us go slower, not faster.
Details about turbo modes, all-core and subset core would also be very interesting and information is often difficult to find.
@zack – it would feel expensive.
As a frequency part, should not there be more database related benchmarks?
This processor is for use with Oracle or SQL Server, too. THAT is what datacenter servers do. In those scenarios, doubling cores while dropping GHz could-very-well be a WIN.
Comments are closed.