AMD EPYC 7002 Microarchitecture Updates
The new generation uses the AMD Zen2 microarchitecture, similar to the Ryzen 3000 series desktop parts in many ways. That is part of how AMD is accelerating its design cycles. We are going to cover a few of the microarchitectural updates in this section.
First, AMD added a number of new architecture features in Zen 2. One we did not see is AVX-512 or VNNI (Intel calls that DL Boost.) AMD is pursuing a “fast follower” strategy. Essentially, it is letting the software ecosystem consume Intel chips to utilize new instructions. AMD then plans to introduce instructions as the software ecosystem integrates them. That way, AMD customers are paying for instructions that are being used widely, rather than instructions that may be used in the future later.

AMD’s Zen 2 is a derivative of the original Zen, but AMD says it has attained around a 15% IPC increase. This is a big deal. The 15% increase is on the higher-end of what we have been accustomed to in generation on generation performance improvements over the last decade. That 15% has not happened in conjunction with doubling CPU core counts. AMD is getting a lot of benefit by moving to 7nm.
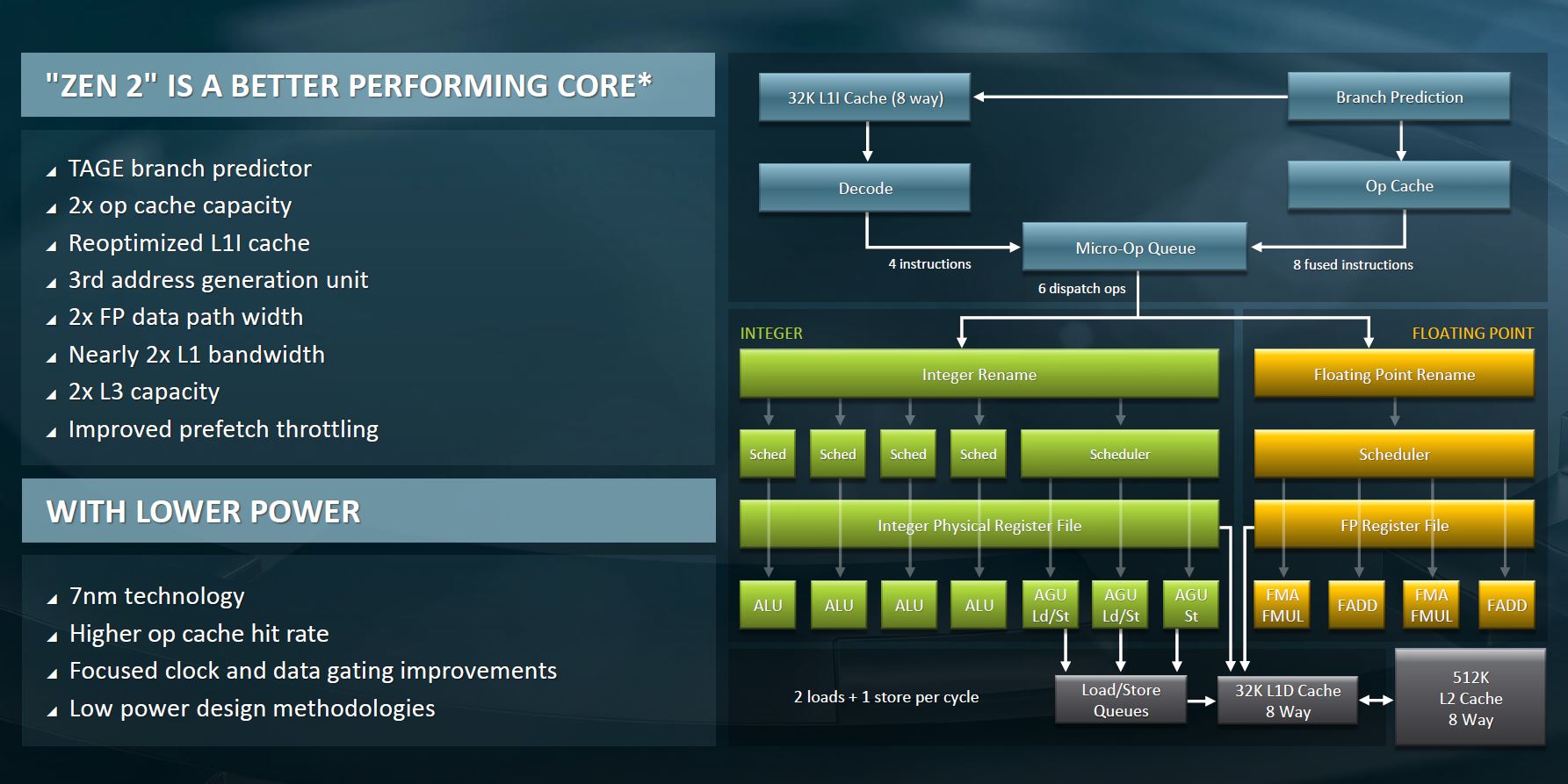
Zen 2 is deeper and wider on the integer compute side than the original Zen architecture. This helps on the integer side of performance. We are going to let you read the slide for more information here.
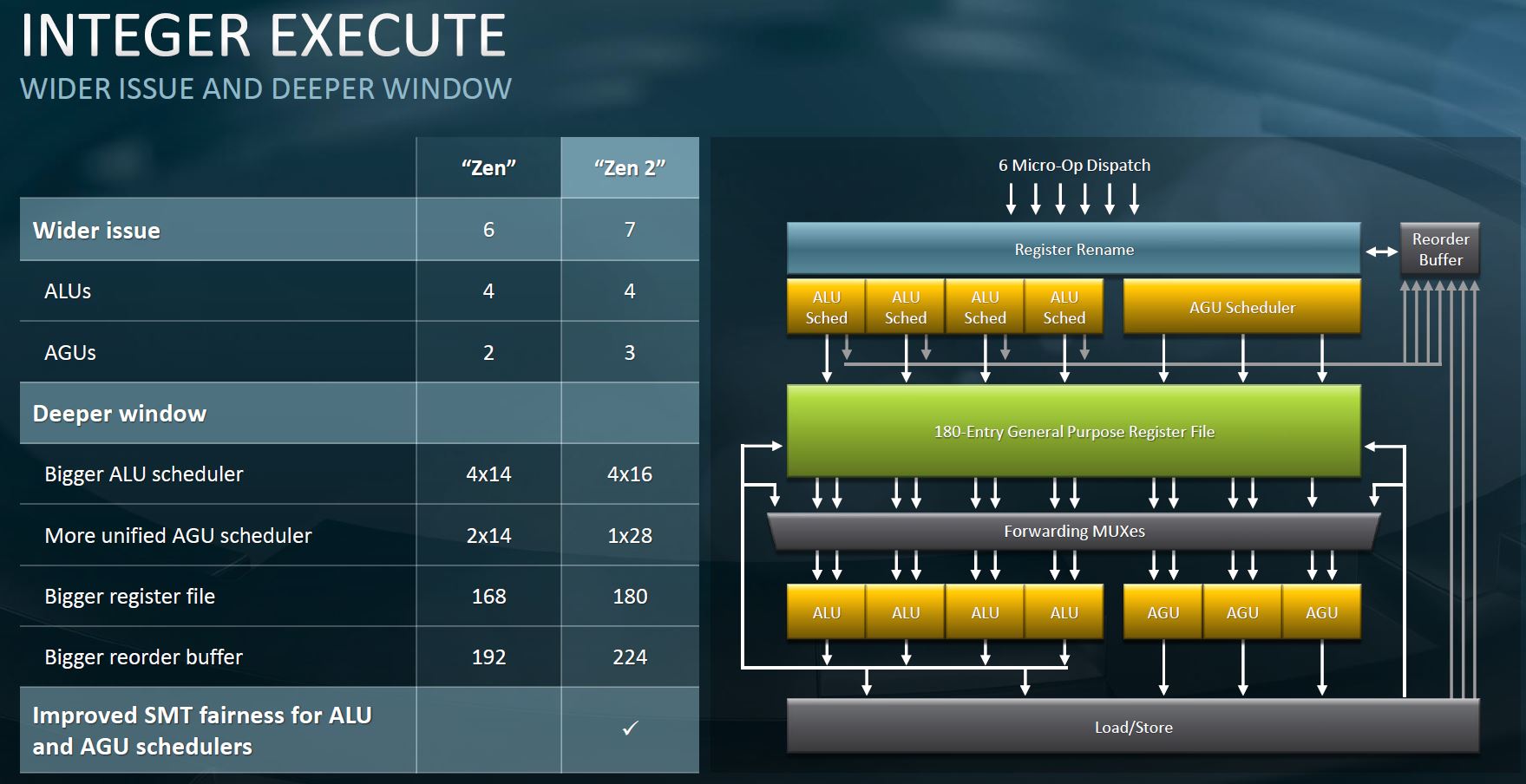
On the floating-point side, AMD also has doubled the execution capabilities. AMD still does not have AVX-512, but between adding more execution per core, and doubling core counts, AMD is on a significant improvement path.
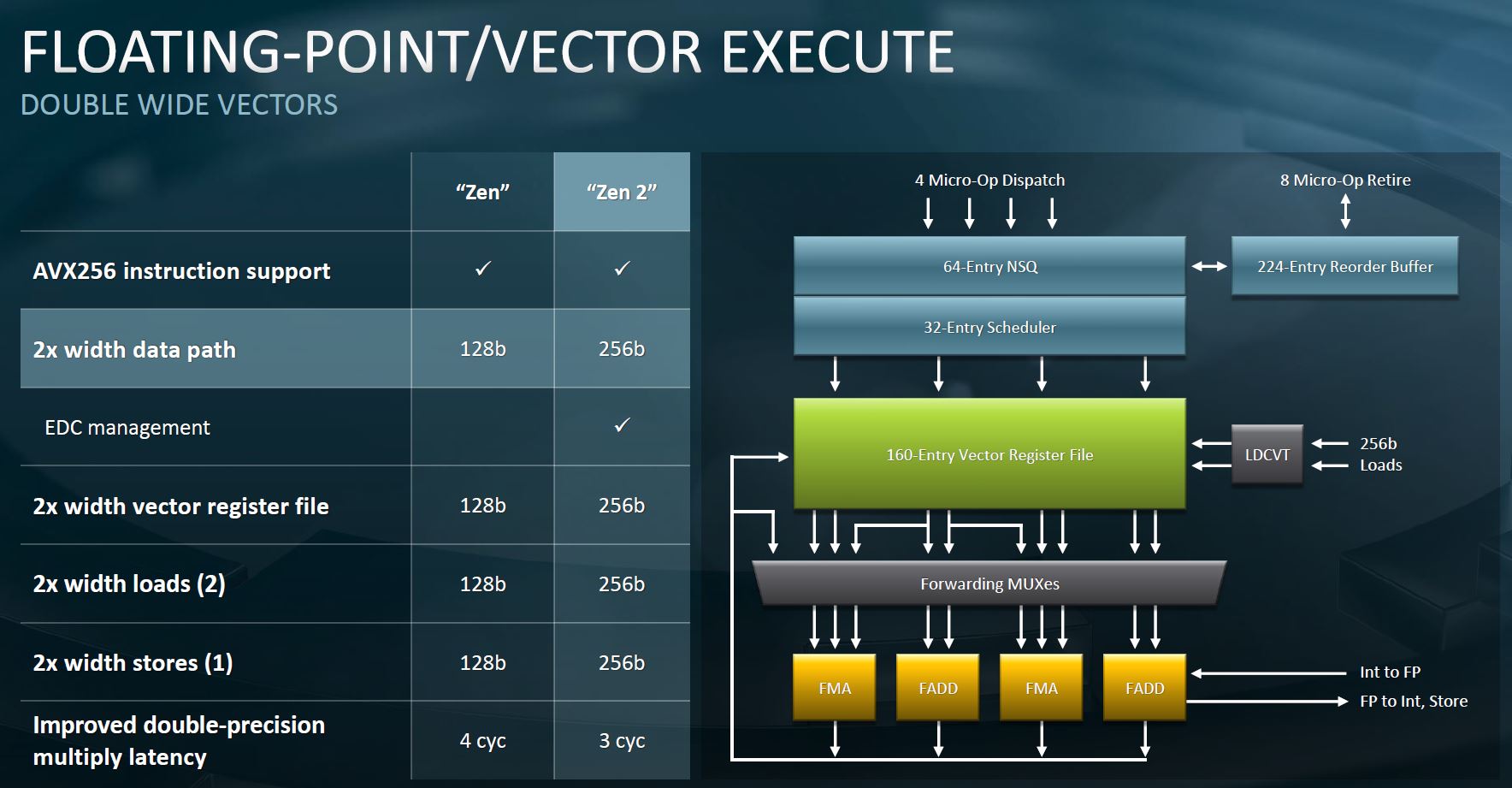
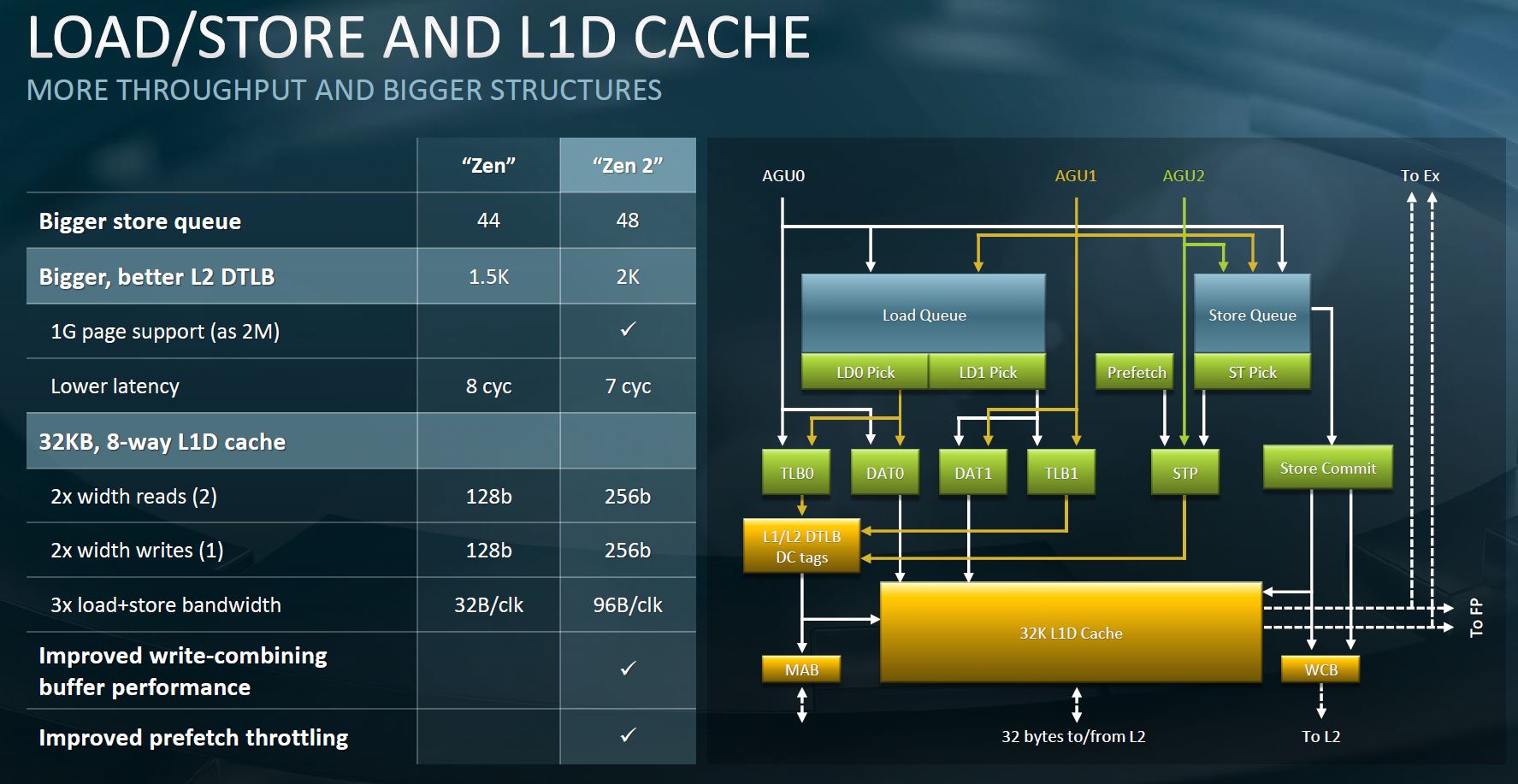
Keeping all of these cores fed is not a simple task. More execution units mean AMD needs to get data from the main memory better than in previous generations. One of the big features is a better branch predictor. AMD actually brought their TAGE branch predictor in from the next-generation codenamed “Milan” into this generation. Better branch prediction means the data pipeline stays primed.
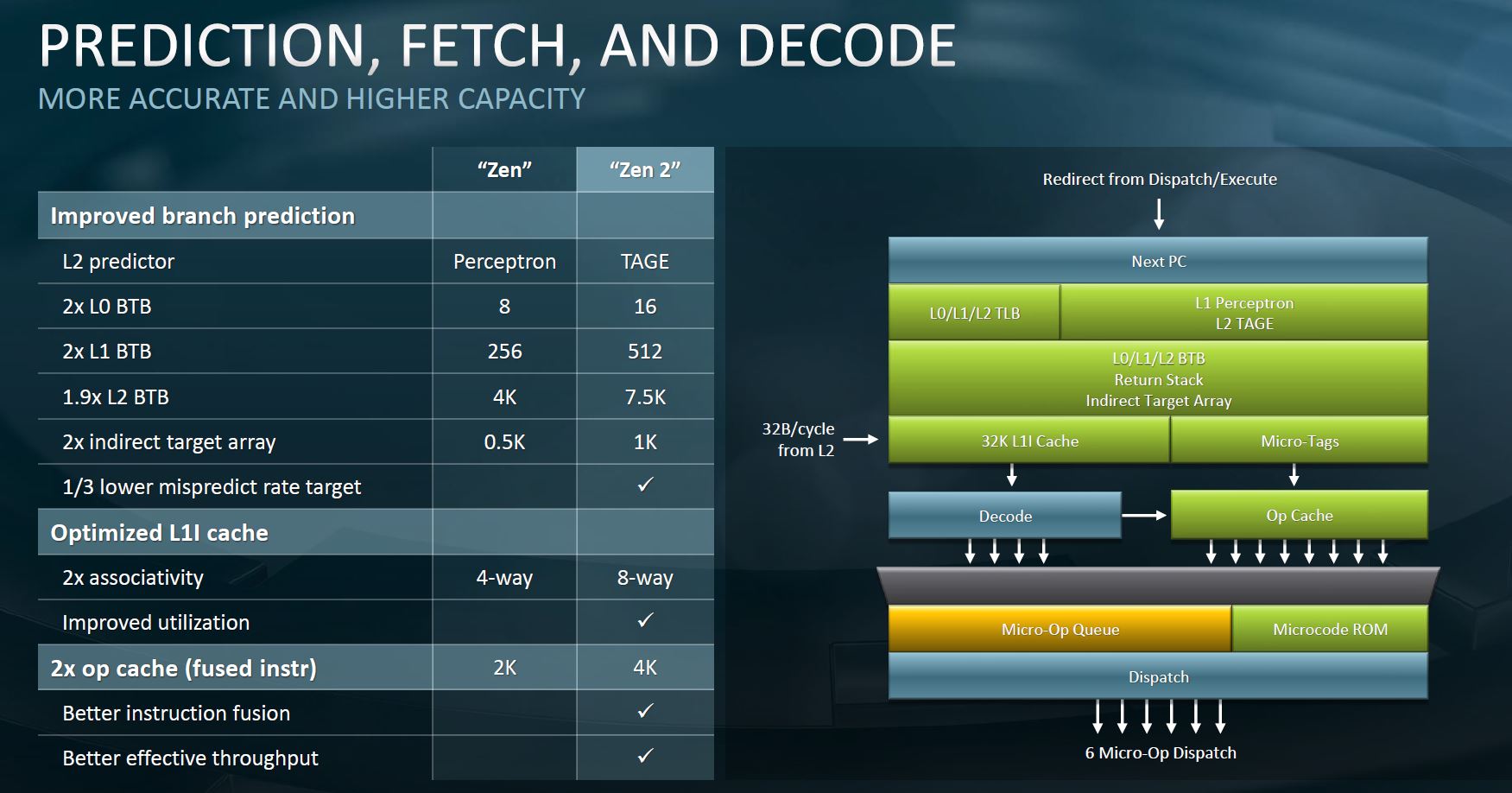
Additionally, caches are bigger with lower latency. This is something AMD could add with the shift to 7nm and the additional density it provides.
To reiterate, AMD’s higher cache parts now have up to 256MB of L3 cache. Combined with 512KB per core means that AMD is putting ~300MB of cache onto chips. That is enormous compared to what Intel is putting on the chip.

We only did a brief microarchitectural overview, but AMD is moving ahead with increasing IPC along with core counts.
Next, we are going to look at some of the topology impacts of this new design.



{kind=link}
This is crazy!!!
Absolutely amazing. I still can’t believe the comeback AMD has made in just a few years. From a joke to toppling over the competitor for the top position in what, 3 odd years?
Definitely going to get this for our next server build. Major props to AMD.
Great job AMD! We’re going to look at 7002 Monday in a team meeting.
Gates. Jobs. Su.
I hope amd has enough stock to satisfy the demand so they could gain market share.
Impressive review ! With Lenovo and Google also on the Rome journey, AMD has a brilliant future.
“Intel does not have a competitive product on tap until 2020.”
Cooper Lake is not remote competitive with Rome, much less it’s actual 2020 competitor Milan.
Highly unlikely Intel will be close to competitive until it’s Zen equivalent architecture on it’s 7nm node.
Wow! I’ve been holding out upgrading my E5 v3-generation server, workstations, and render farms in my post-production studio because what has been available as upgrades seemed so incremental, it was udnerwhelming. And now here comes Rome and the top SKU is performing 5-6X faster than an E5-2697 v3! Maybe a weird comparison, but specific to me. I’m thinking back to some painfully long renders on recent jobs and imagining those done 5x faster…
I would really, really love to see some V-Ray or even Cinebench benchmarks. I know I’m not the target market, but I’m not alone in wanting this for media & entertainment rendering and workstation use. Any chance you could run some for us?
Also, what Rome chip would you need for a 24x NVMe server to make sure the CPU isn’t the bottleneck?
Great work, as always. Thank you!
Intel’s got Ice Lake too. I’d also wager that Patrick and STH know more about Intel’s roadmap than most.
Ya’ll did a great job. Using CPU 2017 base instead of peak was good. I thought it was shady of AMD to use peak in their presentations.
I’d like to see sysbench come back.
Are all the benchmarks done after the applying the fixes for SPECTER and friends?
Most OEMs will have no problems with moving to Rome but Apple is in a tough situation with their Intel partnership, aren’t they? How can they market Xeon generational improvements when others are will be talking about multiplying performance and a substantial relative price decrease?
XENOFF
Partnership gives some discount. I am right?
Take a look at the top of dual socket systems in the SPECrate2017_int_base benchmark here:
Supermicro already posted a 655 base with 7742’s to top the charts.
For render farms, wait for 64core Threadripper.
Wizard W0wy – we applied patches, however:
1. We left Hyper-threading on. I know some have a harder-line stance on if they consider HT on a fully-mitigated setup.
2. We did not patch for SWAPGSAttack. AMD says they are already patched or not vulnerable here. Realistically, SWAPGSAttack came out the day before our review and there was no way to re-run everything in a day.
Tyler Hawes – we have the Gigabyte R272-Z32 shown on the topology page. That will handle 24x U.2 NVMe but that will be a common 2U form factor in this generation. CPU selection will depend on NIC used, software stack, and etc., but that is a good place to investigate.
Awesome article STH
I would love to see some more latency test, Naples had some issues with latency sensitive workloads in part due to the chiplet design. So, will you guys test it out in the future?
And more database tests?
You did mention you would talk more about 3rd Gen EPYC? I don’t think I saw it anywhere in the article. Will it be out to compete with Ice Lake? What are the claims so far?
Thanks for the great article! Best I’ve read so far.
I’m also disappointed in the lack of a second gen 7371 SKU. Our aging HP GL380p G8 MSSQL server is due for a replacement, and I don’t want to have to license any more cores. Per-core performance really shines considering $7k/core. It would feel wrong to deploy without PCIe Gen 4; I might drop a 7371 into one of the new boards (if I can get any vendor support) and swap it when the time comes.
I appreciate the amount of work you have done in compiling all this information. Thank you, and well done.
Also, well done to AMD! What an amazing product they have delivered. Truly one of the greatest leaps in performance-per-dollar we have seen in recent years.
Can we get some C20 scores for the LuLz
Hello Patrick,
There was a Gigabyte converged motherboard layout (H262-Z66) floating out that showed 4 Gen-Z 4C slots coming from the CPU. There were rumors of Gen -Z in Rome going back to the Summer of 2018; Is there anything you can tell us about that?
Hi guys, taking my wife to the hospital in 30 minutes for surgery. Will try to get a few more answered but apologies for the delay later today. She broke her elbow (badly.) Thank you for the kind comments.
Jesper – it is a bit different in this generation. When you are consolidating multiple sockets, or multiple servers, into a single socket, your latency comparison point becomes different as well. We have data but tried to manage scope for the initial review. We will have more coming.
Luke – Milan is coming, design complete, 7nm+ and the same socket. AMD said the Rome socket is the Milan socket.
Billy – I think AMD’s problem is that there is so much demand for their current stack, some of those SKUs did not make the launch. I am strongly implying something here.
Michael Benjamins – 2P 7742 was 27005 without doing thread pinning. There is a lot more performance there. Also, Microsoft Windows Server 2019 needed a patch (being mainlined now) to get 256 threads to boot. I am not sure if I want to show this before we get a better tuned result. Even with this, R20 hits black screen to fully rendered in ~12 seconds. Cores were under 40-98% load for <10 seconds with R20. I actually think R20 needs a bigger test for a 256 thread system.
I’m not sure I understand the paragraph about Intel putting pressure on OEMs. What exactly should not be named/disclosed? Can someone please explain the meaning to me?
Sounds like the typical and shady anti competitive measures Intel is known for.
p.s. I hope this is not a double post, but I got no indication if my previous submit worked or not.
Quick question on the successor to Snowy Owl? Have we got an ETA, or will AMD simply pop Ryzen in its place, like ASRock have done?
From Spain, our best wishes and speedy recovery for your wife. Thank you very much for your work.
This is f@#$ing great work. You’ve covered high-level, deep technical, business and market impact, with numbers and practical examples like your load gen servers that are great. I’ve read a few of the other big sites but you’re now on a different level.
To anyone that’s new I’ll reiterate what I said on the jellyfish-fryer article
Patrick’s the Server Jesus these days.
He’s done all the server releases and they’re reviewing all the servers
Okay. My criticism was this looked really long. I started reading yesterday. Finished today. Why’d AMD have to launch so late????
After I was done reading I was totally onboard with your format. You’ve got a lot of context interjected. I’d say this isn’t as sterile as a white paper, but it’s ultra valuable.
Now get to your reviews on CPUs and servers.
@Youri and another Epyc system from Gigabyte already beat the SuperMicro one at your link ;)
R282-Z90 (AMD EPYC 7742, 2.25GHz)
Great read. Thanks Patrick!
I’m thinking you should submit this to some third tier school and call it a doctoral thesis for a PhD. That was a dense long read. I’ve been reading STH since Haswell and I’ll say that I really like how you’ve moved away from ultra clinical to giving more anecdotes. I can tell the difference reading STH over other pubs. This is deep and thorough.
Cracking review. More SQL (Postgres) when you have recovered :)
What vendor can accept the first orders for the systems with AMD EPYC 7002 (configurator ready) and is able to ship let’s say within next 2-3 weeks?
I am so glad I waited until today to read this, when I could sit down and read at my leisure. Thank you Patrick and team. This is why I read STH.
“2. Customers to change behavior”
This is likely not what AMD can do since there is no medicine or medical operation available to fix stupidity!
Stupidity can’t be fixed by others except people themselves!
Mike Palantir,
During the event, I thought I recalled the HP rep stating they had systems available for order today.
FYI Rumour rag, WCCF claimed to Fact check your statistic’s!
“Warning: some of the numbers below are simply absurd.
ServeTheHome reviewed the top-end 64 core dual socket and found that “AMD now has a massive power consumption per core or performance advantage over Intel Xeon, to the tune of 2x or more in many cases.”
The new EPYC parts have a massive I/O advantage with 300% the memory capacity versus Xeon 33% more memory channels (8 versus 6) and finally 233% more PCIe Gen3 lanes. But what about actual performance?”
We called our rep today at Lenovo after reading this. They said they’re shipping aug 30
This is probably a dumb question but are there any vendors that will be selling individual chips (not systems) within the next quarter or two? And who would the best vendor be?
Thanks
guys.. remember that both AMD and us as customers do owe TSMC a lot. Without TSMC all this would probably be not possible today.
Never mind my previous comment. Newegg is selling the processors and is already on back order to the end of August for most of the desirable SKU’s.
Patrick thank you for the informative article and all the great work you and your team do. Also would like to thank the STH readers for their article comments and posts in the forums. This is one of very few sites where I actually enjoy reading what other people think and say…
And thank you for the nudge nudge wink wink information with regards to the 7371 style skus. I have a application that processes in a very serial fashion and it benefits from higher megahertz vs Core quantity, though 16 cores is perfect for the SQL and other tasks on the machine. I’m excited about the new NUMA architecture and I’m looking forward to whatever is next.
Best wishes and a speedy recovery to your wife!
@Billy
Epyc 7542 would probably match or beat the 7371 in mosts lightly threaded tasks.
@lejeczek
What can TSMC make that Samsung couldn’t?
Amazing writeup Patrick, once again! Beamr is proud to be a Day 1 application partner as the only company focused on video encoding. As a result of this amazing achievement by AMD, on the Gen 2 EPYC we were demonstrating at the launch event 8Kp60 HDR live HEVC video encoding on a single socket of a 7742.
And as a result of having 64 high performance cores, because we are heavily optimized for parallel operation, all cores were utilized at 95% or above! Beamr is super excited to have this level of performance available to our first tier OTT streaming customers and large pay TV operators.
AMD has broken through on so many levels with this new processor generation that I understand why you feel the need to even go deeper with your analysis and review after writing an “epic” 11k word article.
Great look at the next big thing… After it all, I can only ask if with FINALLY a 1 node socket is there any talk of 4P or 8P…
The thought of 512C\1024T in a 4U is like dreams come true… And if the rumors of SMT4 turn out to be true (EUV does give 20% more density and power-savings) 512C/2048T could do most heavy jobs in one box…
And it does change the landscape since the progression from 8C to 64C covers basically 100% of the market.. The market doesn’t care if they need 1P or 8P, they only care about the areas where AMD is excelling…
Another interesting area I’m not seeing a lot of is Edge Computing… This should seal the deal with an 8 or 16C that can have 6 NICs and an Instinct for AI inferencing…
Love the site… Looking at bare metal in the future…
So what they’ve figured out that other sites haven’t yet, is the whole consolidation story. That 4 Xeon E5-2630 V4 to 1 epyc really resonates.
It will be interesting to see how long it is before VMware and other companies start adjusting their licensing to reflect future market trends. Software companies have investors to please too. If Intel doesn’t have anything to compete by the time prices start going up then it could cause a huge wave of companies switching to AMD for the simple fact that their licensing would be too expensive otherwise. The other thing they could do is switch. Everything to per core licensing which would give Intel a slight advantage or possibly just a tie once you factor in the total cost. I bet you big changes are coming though. No company could survive having their revenue cut to 1/6 its original value in a couple of years.
So this is me just thinking about this some more. It will also be interesting to see the impact this could have on interest in open source alternatives. Costs jumping 2-6x are the kind of events that get people to start looking into alternatives.
Colby, vmware changing its licensing to per core after appearing and praising rome on stage together with amd, would be one of the top3 stupidest move this industry has ever seen. Not impossible, but highly improbable.
Yeah but in my experience when it comes to looking like an idiot and having to explain to your investors and wall street analysts why your revenue stream has been cut in half most CEOs would prefer to look like an idiot. After all the CEO owns a good portion of the company as well. I don’t necessarily think it will be all at once but instead of a 3% annual increase we may start seeing 10-15%. They also may be hoping that due to the cost reduction allowed in Rome that they will see more customers coming in looking to virtualize since it will be cheaper. Another thing that could potentially go VMware’s way would be if customers just started giving more resources to each vm since they aren’t as constrained by their licensing anymore. Instead of dual core vms with 4GB of ram now everyone gets
…everyone gets 4 cores and 8GB with the benefit to the company being added productivity. Nothing happens in a vacuum in business but the question is what factors are going to prevail the most.
Rome was rumored to support CCIX. I couldn’t find any confirmation of this. Is that the case?
Just joining in for the thanks. The most thorough and in-depth review on the net I’ve found so far.
Also, Patrick, I wish your wife quick and full recovery. So you can get back to benchmarking, that is ;)
I’m surprised at how inexpensive the lower core count 1P processors are. Are these practical in a high end CFD workstation or for other compute intensive workstations ?
Someone needs to compare the Ryzen 9 3950X ($750) with the soon to be released 16 core Zen2 with the 7302P ($825). Can’t believe a 16 bit Rome EPYC is only $75 more than the R9 ! The 16 core Zen 2 has to be priced between these 2 devices, maybe $800 ?
With the 7502P (32 cores) selling for $2300, I guess we know the upper end of the price on the Zen2 32 bit Threadripper.
Another thing to keep in mind is that Zen3 products will be shipping in 15 months or so. They will surely push down the price/performance curve even further. Zen 3 will be 7nm EUV, which should be 20% higher density, lower power consumption and faster clock speeds. Zen 3 Ryzen should be 32 core, TR should be 128 core, EPYC should be 128 or even 256 core !
@Nobody I’m also really curious about the suitability of these chips for a workstation and how they compare to threadripper. Patrick thought the clock speeds on gen 1 EPYC chips were too slow before the 7371 was released.
Devastating. Adding the fact that second generation is compatible to SP3 and vendors have v2-enabled BIOSes out there already is a serious hit. Good job, AMD
Followed the link back from your article on the 7 and 10nm Intel woes. When you wrote this, you expected Intel to be competitive in 2020. Instead Intel’s process woes have messed up the other parts of the company, and they are considering contracting out CPU and GPU production!
I never thought I’d see Intel mess up so badly on process, and I know I’m not alone on this. It has given AMD a really big doorway, and curiously enough also seems to have opened the doorway further for ARM vendors, due I think to AMD being limited in production capabilities.
Comments are closed.