
2017 is by far going to be one of the most exciting years for server compute since the early days of STH over 8 years ago. The machine learning/ AI wave is the new “killer app” driving a race for faster processing servers with a voracious pace. Over the past five years Intel has dominated compute. AMD made some strategic mistakes with its Opteron 6000 server chips and by the time Sandy Bridge-EP was over, Intel essentially erased AMD from x86 server relevancy as well as taking out many of the more exotic RISC architectures. The last five years of software development were done mostly on x86 servers from Intel. The next five we expect to be much different. We wanted to offer some thoughts on the upcoming inflection point we will see in 2017. While there are sure to be more, we wanted to highlight a few we can talk about publicly.
The Who Cares Web Server
Perhaps one of the largest applications in the last five to ten years has been the web server. Over the past few years we have seen in-memory caching become commonplace which, in turn, has made web servers less exciting. Most visitors will have no idea if they are visiting a properly cached WordPress site on a $500 Avoton era (2013) Atom based server or a $50,000 2016 Broadwell-EX server like the Dell PowerEdge R930 we reviewed.
With cached web server reads, RAM capacity and disk speed for databases become a significantly larger piece of the overall performance puzzle, as does networking and payload sizes. The fact of the matter is that you can run a “decent” web server off of a Raspberry Pi, an excellent web server off of a Cavium ThunerX machine or a modern Intel server. For dynamic content, you still do need single threaded performance and we are set to see more challengers to Intel in that space in 2016.

At the end of the day, the major web firms such as Facebook and Google have the ability to get custom chips from Intel. For most of the smaller web firms, making a web hosting tier is not going to get that much better. Take a look at the StackExchange hosting stack. As of this publishing, they are pushing 1.3 billion monthly page views with dynamic content (posts that must be saved in databases) using around 23 servers. A dynamic, top 200 website now uses 23 servers which is a big reason we are seeing many alternative architectures (e.g. ARM) target the web server market. It is low hanging fruit.
vCPU / ECU “Gravity”
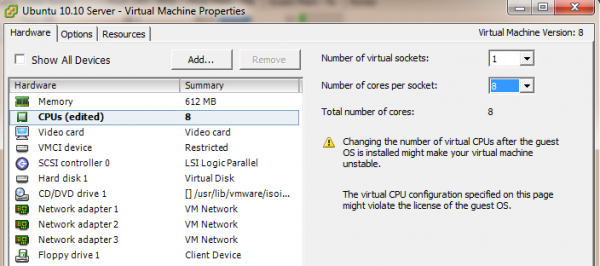
One of the other major trends we are seeing is the gravity associated with vCPUs or ECUs denominated in Intel x86 cores. If you expect a vCPU to be Intel Haswell generation, then a Sandy Bridge core with about 15% less performance or a Broadwell core with about 7% more performance is “close enough” for many administrators to not care when they provision.
Perhaps the hardest aspects we see alternative players will have in the virtualization market is that most virtualization tools are denominated in Intel x86 cores. Drawing a parallel between server compute and currency, imagine how much harder it would be going to Morgan Stanley and getting a loan in goats rather than USD. A lot of infrastructure is setup for USD loans but much less banking infrastructure is denominated in goats. While the general tech press sees claims of high ARM core counts as meaning they will automatically be better than lower core count Intel offerings, there are two problems the ARM crowd faces. First, they still do not have per-core performance on par with Haswell chips. Second, they are not using common denominations for virtualization administrators.
We do see AMD Zen as a very intriguing alternative in this space if they truly can deliver solid performance. AMD has a great chance to capture 10-15% market share just by hitting Intel-like x86 performance and becoming the alternative vendor to Intel in the virtualization space.
Machine Learning/ AI
If web hosting and virtualization workloads are the inglorious portions of server compute, machine learning and AI are the new “it” in IT. NVIDIA has had CUDA in the marketplace for around a decade and much of the machine learning/ AI work is being done on NVIDIA GPUs. In fact, we recently published a how-to guide on building your own Starter CUDA Machine Learning / AI / Deep Learning server. Beyond NVIDIA, there is still a ton of data processing and analytics happening on Intel x86 servers. We are also seeing the interest in FPGAs and ASICs soar.

The machine learning/ AI space is one where we are seeing alternative architectures gain multiples of compute performance in certain workloads. To say that the machine learning/ AI/ deep learning space is workload or perhaps even problem dependent is an understatement. As we noted during our coverage of Intel AI day 2016, this is the application class that is going to drive server spend beyond lifecycle replacement for compute servers. Although companies will use new platforms to get NVMe Optane and other storage technologies, the big driver on traditional spend will be consolidation. When one wants to replace a 16 core/ 32 thread Sandy Bridge-EP platform with one-third (or fewer) Skylake-EP platforms, that is a fairly straightforward task. Moving to the machine learning realm what is good in Q1/ Q2 of 2017 may not be what is demanded in Q4 of 2017. That has IT departments in a spin trying to anticipate where to invest.’
Our take is that 2017’s safest bets will be in x86, CUDA and FPGAs with other architectures working to break-through. One significant advancement on an alternative architecture may be enough to change the balance of power.
Notes on Key Vendors and Architectures
We wanted to take a few moments to add highlights on a few vendors we think STH readers should watch in 2017 for compute. We are going to link the sub-pieces here to keep the size of each page manageable.
Note the above list will link to the sub-pieces once each is published.



{kind=link}