
Earlier this week marked the introduction of SPEC CPU 2026, the latest iteration of the SPEC consortium’s industry defining CPU benchmark suite. The first new release of SPEC CPU in almost a decade, SPEC CPU 2026 brings with it a significant change to the benchmark applications within the suite, and the types of workloads being run on those applications. With three-quarters of the suite being comprised of new benchmarks – and the last quarter using heavily revised workloads – the release of SPEC CPU 2026 has laid out a new rule set for what the next decade of CPUs will be measured by.
One of the more notable aspects of the benchmark suite is that for reasons of architectural portability and fairness, the suite is distributed as source code rather than pre-compiled binaries. This, in turn, means that the software environment and compiler toolchain the benchmark is built against can have an impact on performance – sometimes significantly so – which is unique for CPU benchmarks. It also means that SPEC CPU 2026 is not purely a hardware benchmark: compilers are a major part of the calculus that goes into the performance figures the benchmarks generate.
And this brings us to today’s article. Because of the long amount of time it takes to complete a representative SPEC CPU 2026 run (upwards of 24 hours), for our initial launch coverage of the benchmark suite’s launch we opted to stick with a safe and well-tested software setup. This meant running versions of the suite compiled on LLVM 20.1.8, the current stable branch of the widely used compiler and toolchain. The trade-off to that, however, is that LLVM 20 itself is nearly a year old; bleeding edge development of LLVM is currently on LLVM 22.
So with a bit more time on our hands, we decided to take a deeper look at SPEC CPU 2026. Given the importance of compilers in the benchmark suite’s performance, just what would the performance impact be by living on the edge and using binaries built with LLVM 22? Today we are going to find out.
The Case for Compilers
As we wrote in our initial SPEC CPU 2026 article, compilers play a critical role in the benchmark.
“The corollary is that, rather uniquely, SPEC CPU is as much a benchmark of compilers as it is of hardware. Because the source code is a fully portable, high-level implementation of a program, and thus contains no CPU intrinsics or other architecture-specific code, the benchmark is at the mercy of a good compiler to turn it into fast, efficient machine code. This means that compiler improvements to boost your SPEC CPU scores are fair game (an especially important aspect for hardware vendors who produce their own compilers), but the catch is that those optimizations cannot be for SPEC alone; they need to benefit a wider class of programs.”
This means that as SPEC CPU ages, it is typical to see the performance of the benchmark improve on a given set of hardware. How much performance improves varies greatly from benchmark to benchmark. But as compiler developers are allowed to optimize for the benchmark with restrictions, things do get faster, especially in the period right after the benchmark is released.
Just what optimizations are fair game? As defined in the SPEC CPU run rules, compilers are not allowed to implement “benchmark specials,” which are SPEC’s term for SPEC benchmark-specific optimizations. Specifically: “A “benchmark special” is a performance method, including any magic numbers, that is artificially or narrowly tuned to a SPEC benchmark in a way that does not reasonably apply to independently written, real-world program code segments.”
Consequently, while it is unfair for compilers to narrowly target the SPEC benchmarks for optimization, it is fair game for compilers to optimize around the real-world aspects of a benchmark. Finding a way generate more efficient machine code for the algorithms used in the suite’s benchmarks is valid, for example, because (and so long as) that can be applied to any other program using similar algorithms – and SPEC CPU at its core is all about taking real-world workloads and making deterministic benchmarks from them. All of which to say is that there is a good deal of room for compilers to optimize for SPEC CPU without violating the rules.
SPEC at the Bleeding Edge: LLVM 22
So what kind of a performance improvement does the latest development version of LLVM, LLVM 22.1.4, bring to the table for SPEC CPU 2026 performance? Let us start with a look at the high-level numbers for the complete suite.
Please note that these are unofficial scores, and per the SPEC run rules, should be considered estimates only. All of this testing was conducted under Ubuntu 24.04, using the most recent builds of the LLVM compiler, 20.1.8 and 22.1.4. We are testing the base performance rates, not the peak rates.
| SPEC CPU 2026: LLVM 20.1.8 vs LLVM 22.1.4 | ||||
| System | 1T intrate Uplift | Full intrate Uplift | 1T fprate Uplift | Full fprate Uplift |
| Dell Intel Core Ultra 9 285HX | +3.9% | +4.0% | +1.5% | +1.6% |
| EVO-X2 Ryzen AI Max+ 395 | +5.7% | +5.0% | +5.4% | +2.2% |
| NVIDIA DGX Spark X925/A725 | +5.9% | +6.5% | +6.9% | +7.9% |
As you would expect, performance is up across the board. Every system sees performance improvements in both the intrate and fprate tests. Though it is not all to the same degree.
While the intrate improvements are all relatively close (with the DGX Spark/GB10 eking out the biggest gains), the fprate improvements are more lopsided. The Intel system sees rather small geomean gains on both single-threaded and full-rate testing; under 2% in both cases. Meanwhile the AMD system sees more significant single-threaded gains, but those improvements are pared back with full-rate testing. And finally, the NVIDIA system sees the largest gains throughout, picking up 6.9% in single-threaded fprate testing, and widening that to 7.9% in the full-rate test.
But what is driving these gains? For that, let us go under the hood to the individual subscores.
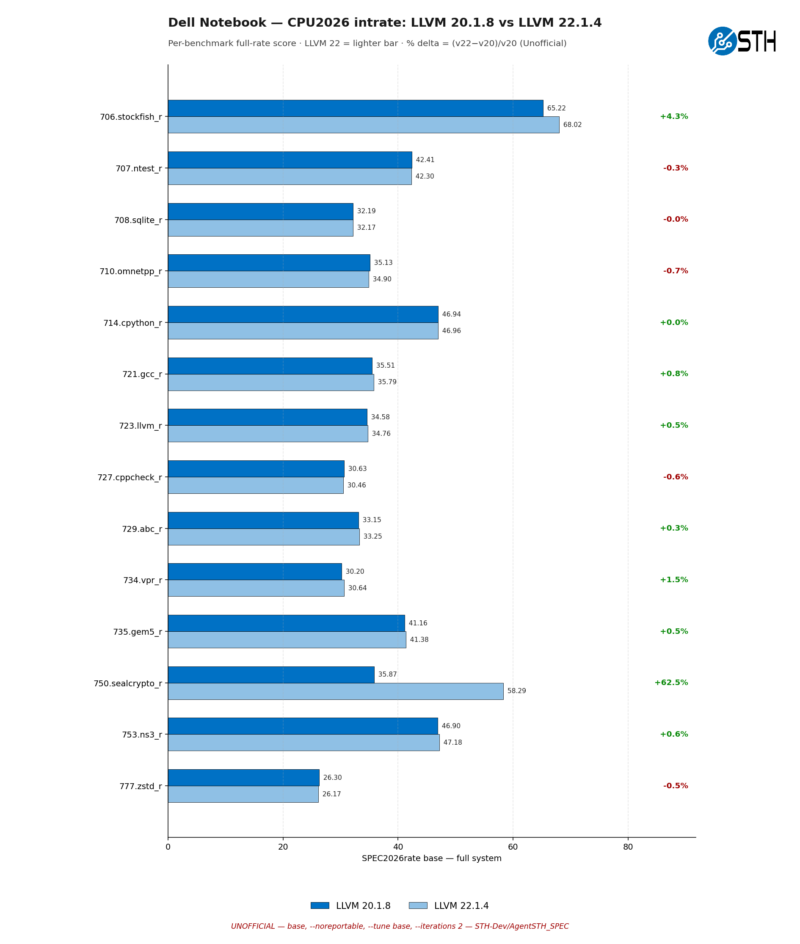
Right off the bat, most of the benchmark results here in SPEC CPU 2026 intrate are relatively unchanged, seeing trivial performance improvements and regressions. However we see two particular outliers that are doing most of the heavy lifting for the performance improvements on the Intel system: 706.stockfish_r, and 750.sealcrypto_r. The latter in particular has improved in performance massively between LLVM 20 and LLVM22, picking up almost 63% more performance.
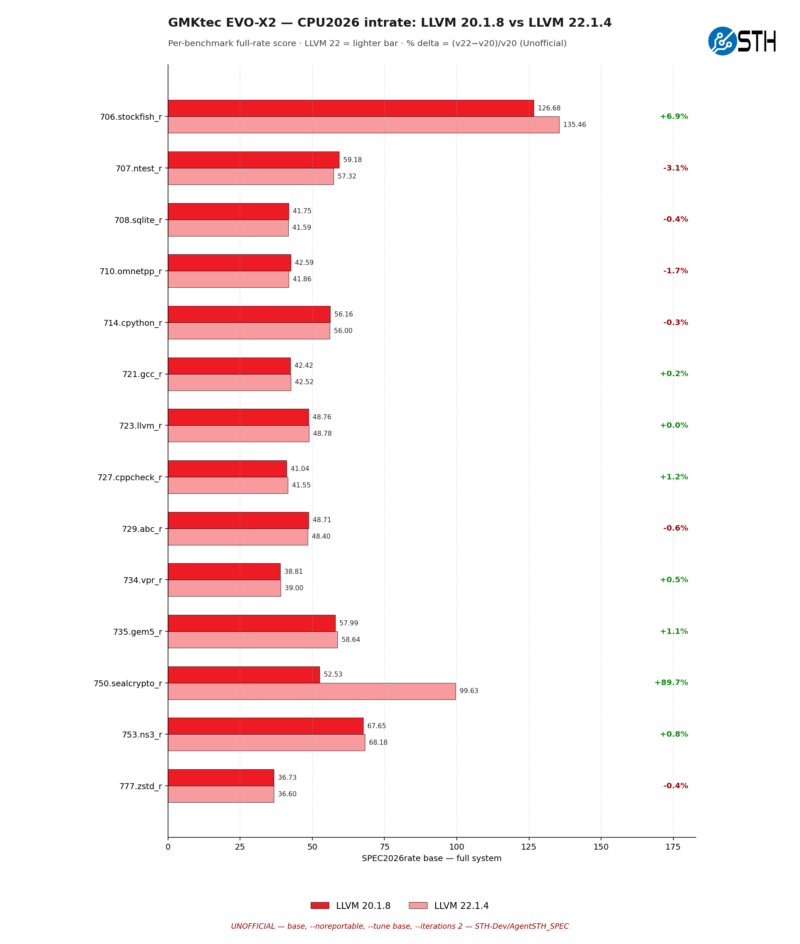
And it is largely the same story on the AMD platform as well. All of the big gains are coming from stockfish and sealcrypto, with the latter seeing an even larger 90% performance improvement. Though the AMD platform is also notable for having one meaningful performance regression, with 707.ntest_r performance dropping by 3.1%.
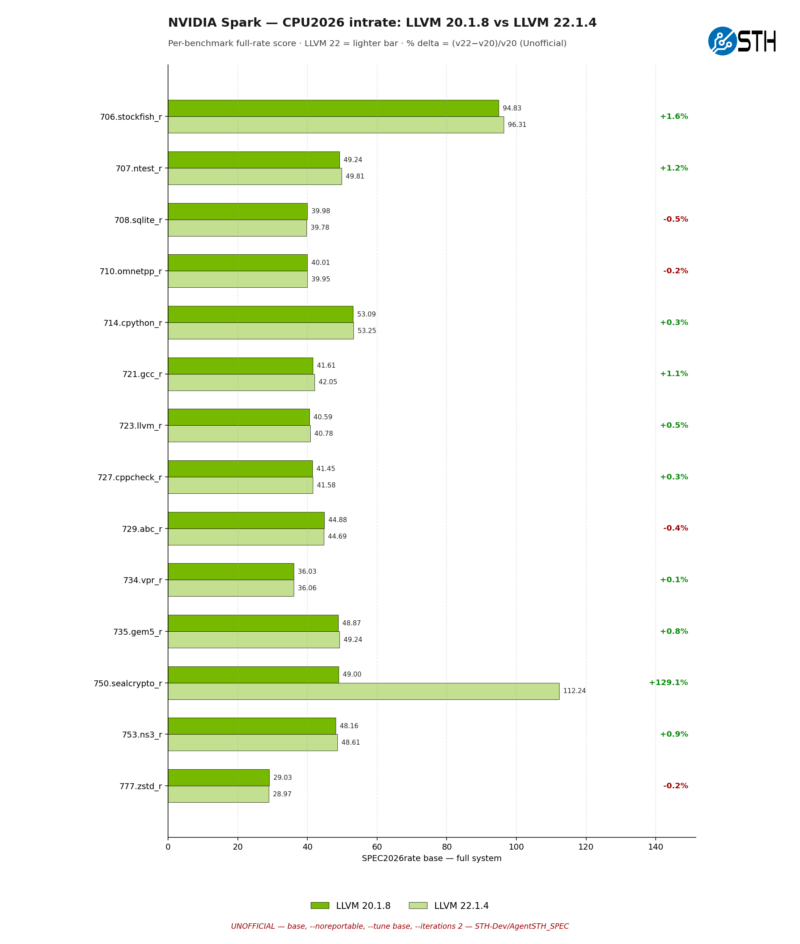
Finally, the NVIDIA platform is a similar picture as well, but with even larger gains in some cases. Stockfish does not pick up as much performance here at just +1.9%, but sealcrypto is 129% faster on LLVM 22 than LLVM 20, more than doubling its performance.
On the whole, every generation of SPEC CPU tends to have one benchmark that gets massively faster due to compiler optimizations. And with SPEC CPU 2026, that appears to be sealcrypto, a security benchmark that is based around running queries on homomorphically encrypted (always encrypted) data. Unfortunately, at this time we do not have a solid answer as to why sealcrypto in particular is so much faster; it is not clear which of the dozens of improvements in LLVM are responsible for the gains. But it is sure neat to look at, eh?



{kind=link}
You need more bass in your editing:
“However under marian we have a major outlier, as while the P-core score improves by 91%, the E-core score is almost trebled, improving by 196%”
I believe that to be tripled?
@Kevin
No, trebled is correct in this instance. To quote Merriam-Webster: treble, transitive verb: to increase threefold.
Though maybe I should have worked a bass pun in there as well.
What is NFS over RDMA and why is important?
“Unfortunately, at this time we do not have a solid answer as to why sealcrypto in particular is so much faster … Overall, the performance gains from switching to LLVM 22 are extremely benchmark-specific right now.”
By their nature, benchmarks are highly workload specific. And similarly, so are compilers. They are now multiplying them together to give you such specific benchmarks they might be irrelevant on their own and you need to do now a cubic power of permutations (all the compilers x all the processors x all the benchmarks = total number of benchmarks required to make it worth it).
This is probably why benchmarks were compiled to begin with wasnt it?