Floating Point Performance
Shifting gears, let us see what LLVM 22 does for fprate performance. Starting again with the Intel system.
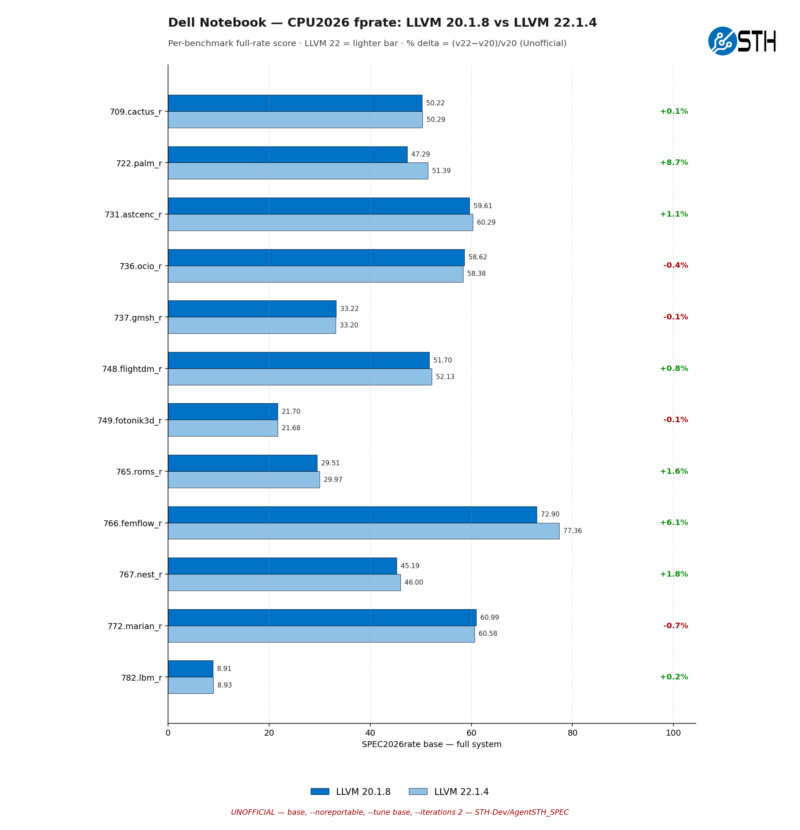
Once again, we see that most of the benchmarks see rather trivial gains and losses going from LLVM 20 to LLVM 22. Which tracks, as the Intel system only improved in performance by a geomean average of 1.6% here. Still, we do have two benchmarks that stand out above the others: 722.palm_r and 766.femflow_r.
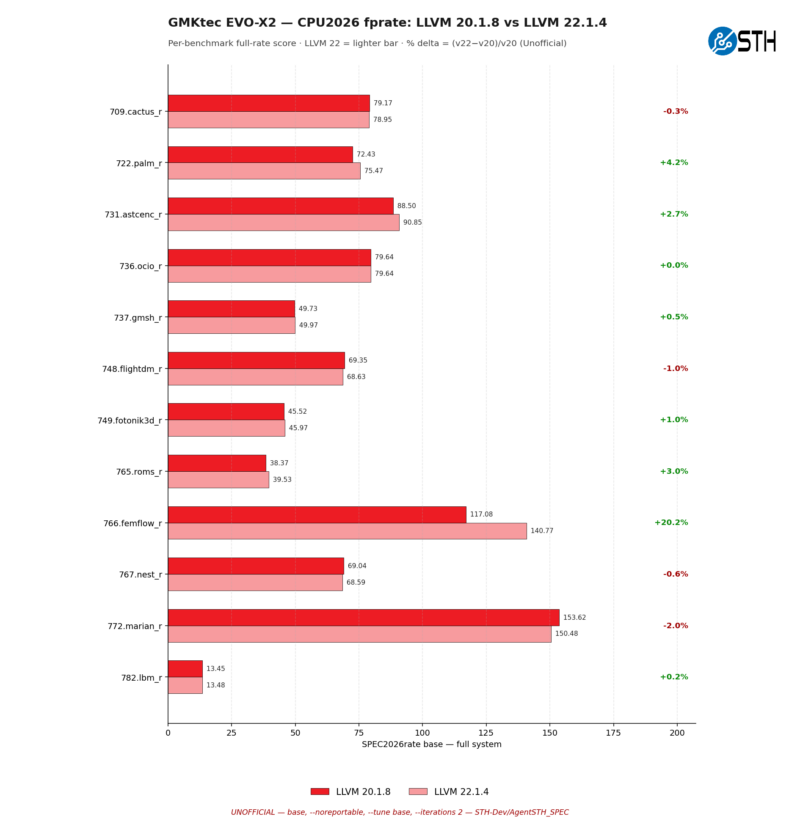
The picture on the AMD system is similar as well, though there are some differences. The performance gains under femflow are far more significant this time, picking up 20% overall, while palm only picks up 4%. Meanwhile there is a bit of a regression with 722.merian_r at -2%.
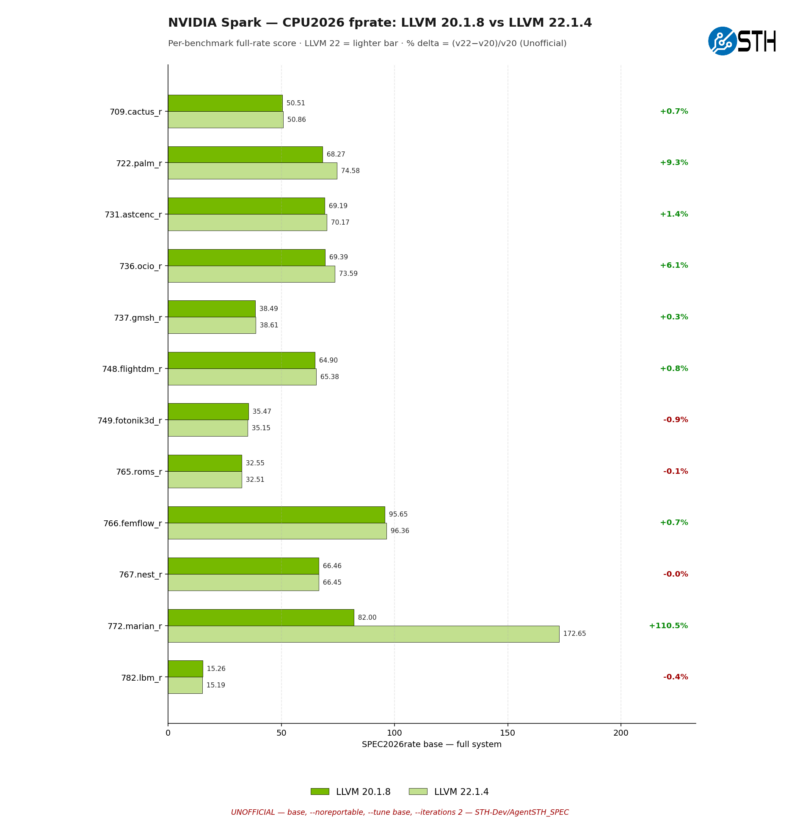
Finally, we see why the NVIDIA system picked up the most performance overall under fprate – and it is for some very different reasons than the x86 systems. While the palm performance gains here are even greater at 9.3% from the newer LLVM, femflow is nearly unchanged, a stark difference from the AMD system. In its place, marian performance is through the roof, more than doubling with a performance increase of 110%.
Interestingly, despite the performance gain, the NVIDIA system only ends up only a bit ahead of the AMD system in terms of the overall marian score: 173 vs 150. So there is a good argument to be had that LLVM 22 has not so much improved the performance of marian overall, so much as it has removed a performance bottleneck that was holding back the GB10 SoC.
As for the marian workload itself, this is a neural machine translation package for translating written languages that, among other things, is used for Microsoft Teams’ live caption translation feature. So perhaps fittingly for NVIDIA’s tiny AI development box, this is one of SPEC CPU 2026’s AI benchmarks – though being a CPU benchmark, it is not leveraging the GPU or tensor cores.
Diving just a bit deeper still, here is one last chart, looking at the single-threaded performance gains on the NVIDIA system – and specifically, showing the gains on both the GB10’s P-cores and E-cores.
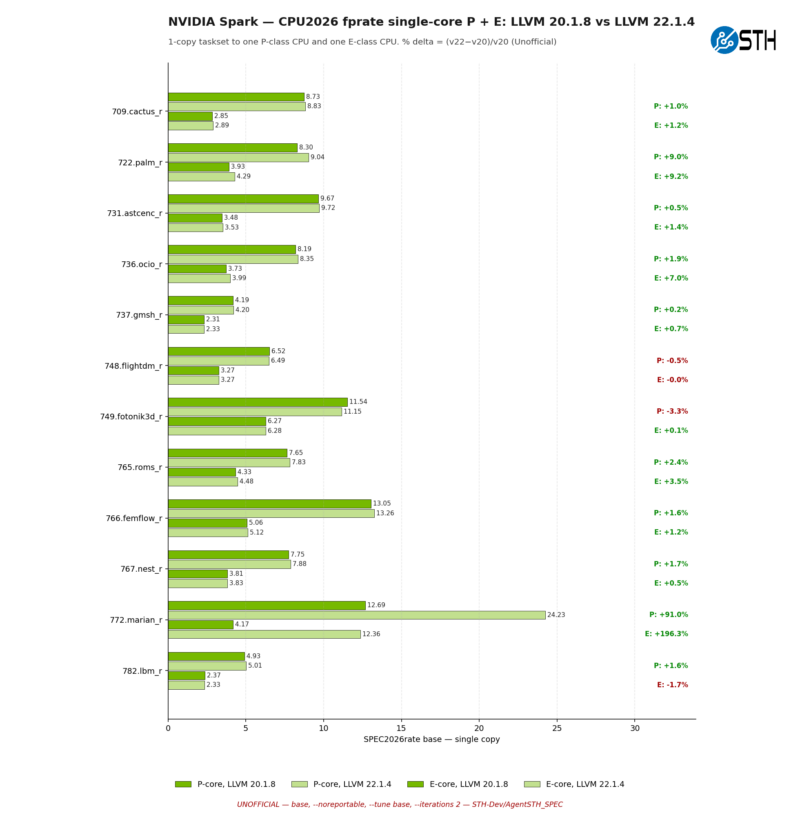
For most of the benchmarks, the performance gains for the E and P cores are similar. However under marian we have a major outlier, as while the P-core score improves by 91%, the E-core score is almost trebled, improving by 196%. With E-cores making up half of GB10’s CPU cores, unlocking the performance of marian on those cores is by far the biggest driver in improving the NVIDIA chip’s score on this benchmark, even for the full rates.
Final Words
Wrapping things up, our brief comparison of SPEC CPU 2026 performance between LLVM 20 and LLVM 22 underscores the importance of compilers in the performance equation. With average performance gains of 5% in single-threaded SPECrate testing and upwards of 7.9% in multi-threaded (full) SPECrate testing, merely upgrading our compiler to the in-development branch of LLVM has given us a meaningful improvement in SPEC CPU 2026 benchmark scores. This also underscores the importance of keeping testing apples-to-apples as much as possible, as otherwise the performance impact of a different compiler can drown out an architecture’s performance advantage.
Overall, the performance gains from switching to LLVM 22 are extremely benchmark-specific right now. The bulk of benchmarks did not see significant performance gains from the newer compiler, but a few did – and with some of these gains more than doubling performance, this was enough to move the needle on the benchmark suite’s performance as a whole. And ultimately, if history is any indicator, this will not be the last time we see some major performance gains in SPEC CPU 2026 over the next several years.



{kind=link}
You need more bass in your editing:
“However under marian we have a major outlier, as while the P-core score improves by 91%, the E-core score is almost trebled, improving by 196%”
I believe that to be tripled?
@Kevin
No, trebled is correct in this instance. To quote Merriam-Webster: treble, transitive verb: to increase threefold.
Though maybe I should have worked a bass pun in there as well.
What is NFS over RDMA and why is important?
“Unfortunately, at this time we do not have a solid answer as to why sealcrypto in particular is so much faster … Overall, the performance gains from switching to LLVM 22 are extremely benchmark-specific right now.”
By their nature, benchmarks are highly workload specific. And similarly, so are compilers. They are now multiplying them together to give you such specific benchmarks they might be irrelevant on their own and you need to do now a cubic power of permutations (all the compilers x all the processors x all the benchmarks = total number of benchmarks required to make it worth it).
This is probably why benchmarks were compiled to begin with wasnt it?