
At AWS re:Invent, the company announced their Graviton processors. The announcement that AWS is making their own CPUs should not be news to anyone. AWS purchased Annapurna Labs, the Genesis acquisition for today’s chips, years ago. At the time we had Exclusive: Gigabyte-Annapurna Labs ARM storage server benchmarks. What is special is that AWS made its new a1 Arm instances available today. We took them for a spin to see what users can expect, especially since we had experience with previous Arm servers like Cavium ThunderX and Cavium ThunderX2.
Trying the AWS EC2 a1.4xlarge Instance with Graviton
Firing up an AWS EC2 a1.4xlarge instance was straightforward. The only difference was picking an aarch64 AMI rather than a standard x86 amd64 AMI. Unlike some of the AMD EPYC roll-outs prior to EC2 M5a/ R5a instances, that we covered in AMD Next Horizon Event Live Coverage, there have been many AMD EPYC cloud launches that went by in the form of preview-only releases. The EC2 A1 instances are available to the public on day 1.
Booting the AWS EC2 a1.4xlarge instance one can see a lscpu setup that looks a bit strange at first. The cores show up as 4 sockets and 4 cores per socket.
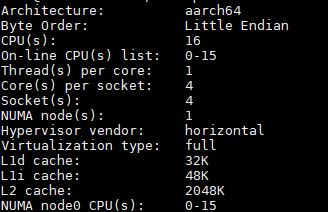
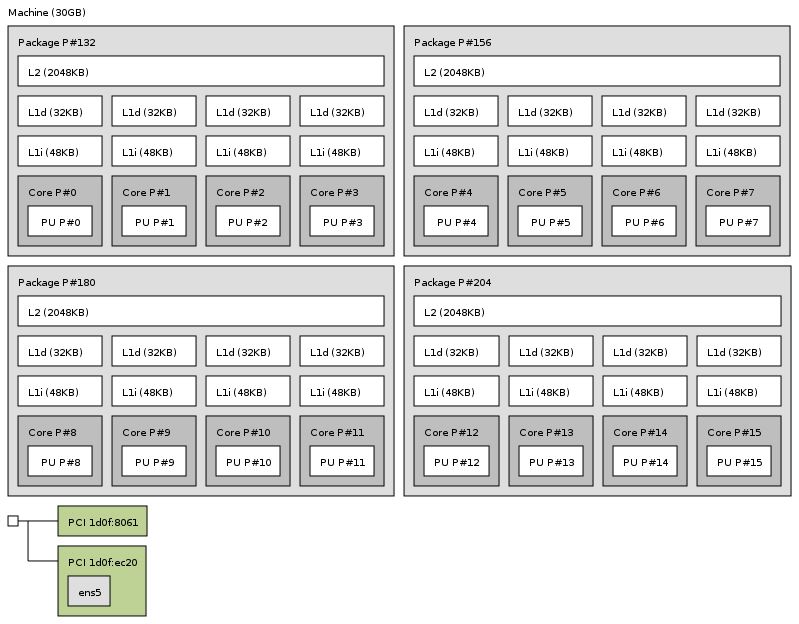
This is a bigger deal than one may expect. If you have a script pulling socket topology, you may be making unnecessary thread pinning decisions. We can also see 2MB L2 cache and at least 80KB of L1 cache. We are not going to put too much emphasis on this because the a1.4xlarge is a virtualized instance so the hypervisor can skew output.
On the cat /proc/cpuinfo side, we can see slightly more information including that this is an Arm Cortex A72 based product.
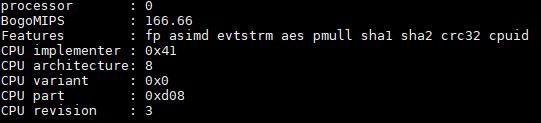
This aligns with the Arm Neoverse announcement since today’s Cosmos platform is supposed to be comprised of A72 and A75 products.

Starting in 2019 the Arm server roadmap is going to get a lot more interesting. Arm is claiming 30% year/ year gains. That is important because AMD is now pushing Intel into an all-out arms race (pun somewhat intended) where 5-8% gen/ gen will no longer be enough.
AWS Graviton a1.4xlarge Performance
We have heard a lot of professional and armchair analysts say that Graviton will change CIO’s Arm strategies. We think that Graviton has solid performance, but performance is not what will lead people to these instances. The ease of going Arm and cost will be deciding factors. Indeed, we are going to show where these instances place in the stack.
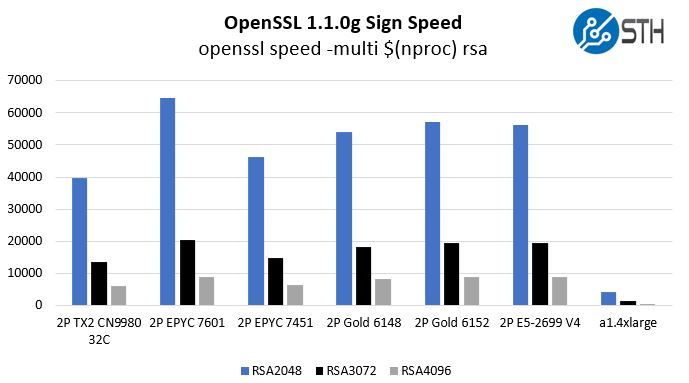
OpenSSL Performance
Since these are meant to be web front-end nodes, OpenSSL performance is going to be an important metric. We ran the same test that you can see on page 6 of our ThunderX2 benchmark and review piece, and here are the sign results:
Here are the verify results:
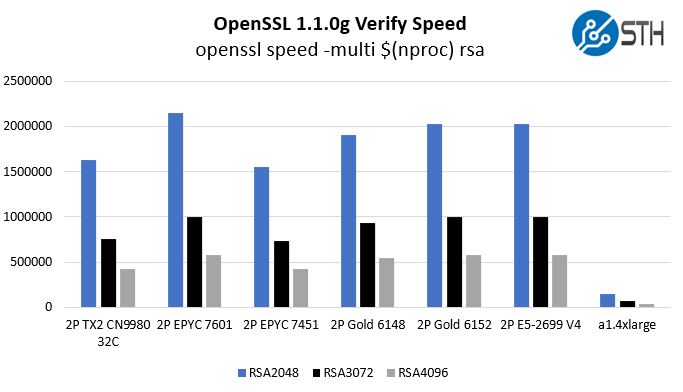
There are admittedly some differences. We are using an Amazon Arm Ubuntu AMI below the same Docker container we used in our original piece. The a1.4xlarge is virtualized while the others are bare metal. At the same time, these charts show one thing: if a CIO wanted to develop an Arm strategy, the AWS Graviton is not something necessarily new. ThunderX2 has been able to offer this level of performance virtualized for some time, and the chips are relatively inexpensive. Also, remember that we expect that the x86 side for AMD EPYC “Rome” will double in the next generation which will make the a1.4xlarge bars into single digit pixel affairs on that chart.
C-ray 1.1 Performance
We have been using c-ray for a long time. We are using our 4K results here because we did not have the Annapurna Labs AL5140 figures for our newer 8K results. The asterisk next to the Annapurna Labs AL5140 result was because this was done in 2015 prior to Ubuntu 16.04 LTS. The Arm server ecosystem was significantly more difficult to use before April 2016 and performance gains using newer compilers could easily hit 30% as we showed in our Cavium ThunderX Part II piece later in 2016.
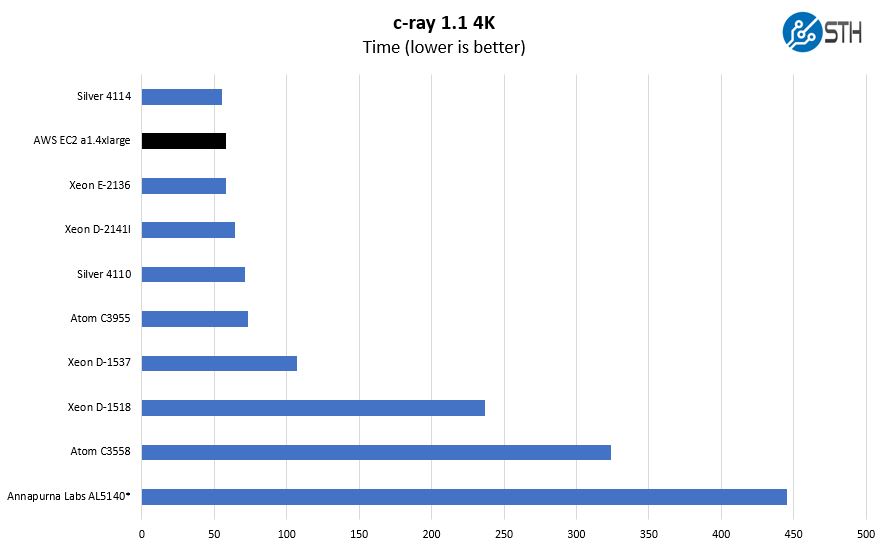
For the record, c-ray is a fairly terrible benchmark when you compare architecture to architecture. On the other hand, it has near linear scaling within an architecture to the point where you can extrapolate results by knowing the core count and all thread turbo speeds within an architecture generation. It is very dependent on caches and very simple calculations. Here we are using Intel CPUs as a comparison point and the AWS EC2 a1.4xlarge does well. You can look at our AMD EPYC results and see that AMD performs extremely well with c-ray and that is why it is the first benchmark AMD has shown with Rome.
7zip Compression
If you are thinking of using AWS Graviton powered a1.4xlarge instances to compress files for transmission, here is a 7zip example:
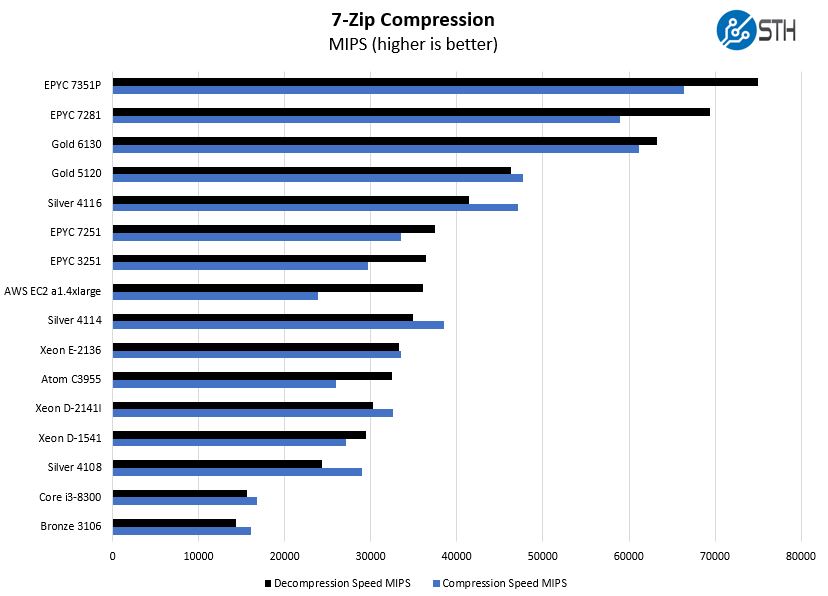
Here the AWS EC2 a1.4xlarge comes in somewhere around Intel’s low power chips, below the AMD EPYC 3251 embedded chip, and realistically below an Intel Xeon E-2136 machine. As standard, we sort this on decompression speed. If we sorted instead by compression, the AWS EC2 a1.4xlarge would instead fall to the third lowest result on the chart just above the $150 Intel Core i3-8300.
If anyone is wondering why we do not have the Marvell / Cavium ThunderX2 benchmark in the above chart, here is what happens to the scale when you add in that solution:
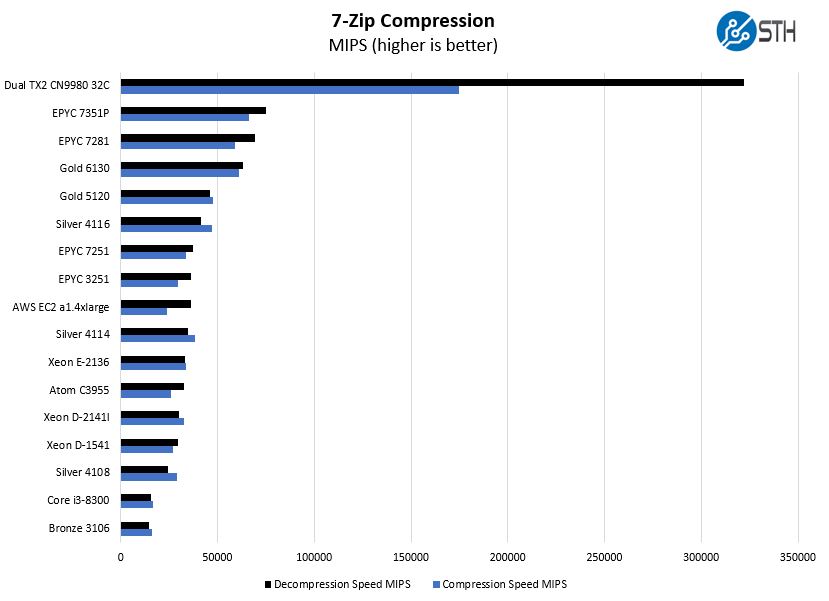
Again, if anyone is telling you the performance of the AWS a1.4xlarge is such a game-changer that Arm adoption will happen for performance reasons, Cavium was out more than a year ago and has plenty of performance, I/O, and memory capacity to virtualize multiple AWS a1.4xlarge class instances.
UnixBench Results
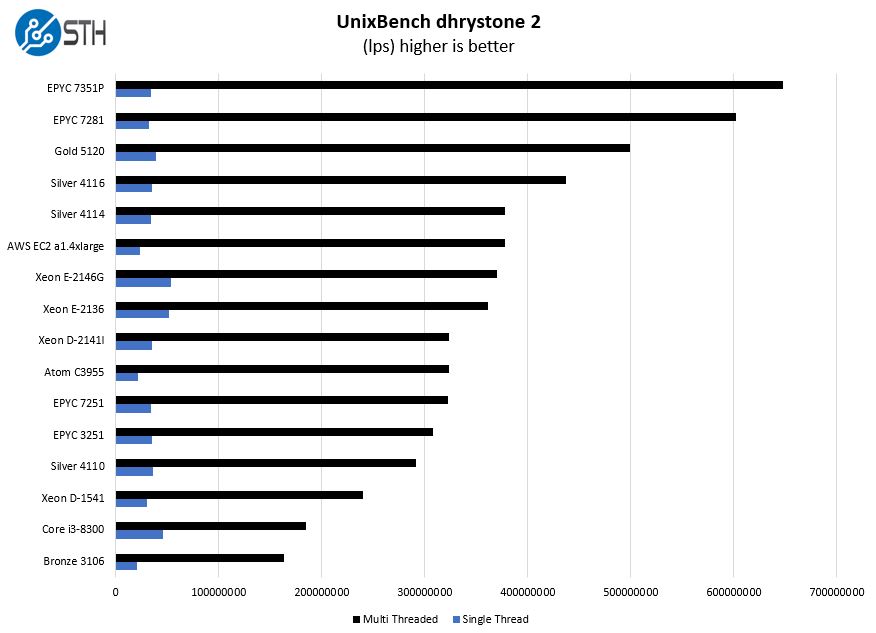
We know a lot of web hosting folks like UnixBench as a measure of system performance, so we get asked for it. UnixBench is an old benchmark, thus it does not take advantage of newer instructions. Here are the dhrystone 2 figures. Again, we need to omit ThunderX2 because it is so much faster.
Here are the whetstone results:
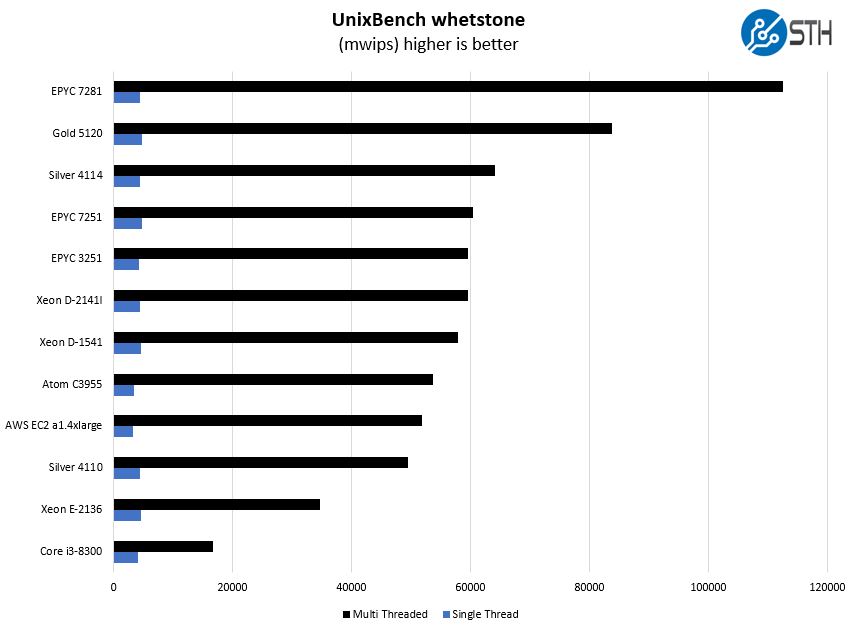
The point we wanted to note here is that the AWS EC2 a1.4xlarge instances have solid multi-threaded performance, the single threaded performance is decidedly not great.
We were working on getting something near apples-to-apples on the nginx/ mysql performance, but there were too many variables given the high-speed 100GbE networking we have in the lab and what we have here. The point that is important we can draw from these results is the single-threaded performance.
Web responsiveness correlates to clock speed. Many people do not care. For example, for STH web hosting, we now have a mix of AMD EPYC and Intel Xeon SKUs, and not necessarily all of the nodes turbo above 3.0GHz. We could get better performance by moving to higher frequency SKUs we have on the shelf, but there are frankly other items to focus on first. The AWS a1.4xlarge solution does not have great single threaded performance which, even though multi-core is everywhere in server architectures for over a decade, is still an inhibitor to performance.
A Word of Caution on A1 Instances
While the cheers from analysts will push one to believe that this is the downfall of Intel, we want to make a quick point here. AWS selling its own Arm CPUs is not what you want as a customer. It may be cheaper. For nginx containers, you may not care. Look at the cpu feature flags from lscpu and cpuinfo. They look a lot different than lists of Intel flags.
Today one can get standard feature sets on-prem, through dedicated/shared/VPS hosting providers, and through other cloud providers. Part of the appeal of Arm Neoverse is that it will allow vendors to customize their chips with specific offload engines. The drawback is that such a strategy invites fragmentation and can cause issues migrating from one platform to another. One of Intel’s positive traits is that it has been keeping instruction sets more standardized as one can see with Broadwell-EP (Xeon E5-2600 V4) and Broadwell-DE (Xeon D-1500) and now with Skylake-SP (Xeon Scalable Gen1) and Skylake-D (Xeon D-2100.) That is a big deal since it allows you to easily move software from one cloud to another without needing to take into account instruction set/ accelerator differences.
If your workflow involves compile-it-yourself or Arm-ready binaries, then Arm is very easy to move to these days. If you have vendor supported software, remember that running on a custom AWS chip is another way AWS will use to exert vendor lock-in over time. For the basic hosting duties that comprise running HAproxy, nginx, and others, Arm is certainly fast enough these days. For more complex tasks, this is still the reason that x86 is king.
Remember, Cavium ThunderX and ThunderX2 were in the market well before AMD EPYC. AMD EPYC will exit this year with more market share than Cavium’s second generation Arm server chips. ThunderX2 with attractive pricing is an architecture that can trade blows with Intel Xeon Skylake and AMD EPYC. One can buy ThunderX2 and virtualize many a1.4xlarge instances on a single box. Still, x86 remains king because there is less work involved to use it. While ThunderX2 can be purchased by your company and by any cloud or hosting provider, AWS chips are AWS-only at this point.
Why This is Happening… the $450 Intel Atom
There is only one reason that we are seeing Arm CPUs, made by Amazon, in the AWS Cloud. It is not because everyone wanted to port their code to lower performance cores. Indeed, AWS does not claim better performance. AWS even caveats the use cases:
These include general purpose workloads such as web servers, containerized microservices, caching fleets, and distributed data stores that that can be spread across multiple cores and can fit within the available A1 instance memory footprint.” (Error in original accessed here on 2018/11/27 at 6PM Pacific)
AWS is saying its single threaded performance is not what others can offer. It is saying its Graviton processors are limited in memory capacity. These may change with the next iteration, but it is instead focusing on multi-core performance at a low cost.
Intel has 16 core Atom parts that frankly could compete with the AWS Graviton. Intel prices chips like the C3955 and C3958 at around $450. To be sure, the Intel Atom Denverton SKUs are competitive with the a1.4xlarge instances and can handle more memory. That memory footprint is extremely important for performance in web hosting. Pricing these chips so high is leaving the door open to Arm server competition.
Likewise, chips like the Intel Xeon D-2183IT being sold for around $1750 for 16 cores is simply too much. If Intel is not careful, the higher-margin business it has with its lower-end parts will migrate to Arm, which will lead to a virtuous cycle pushing its chips out of the hyper-scale cloud markets.
Being fair, if you want performance today, something like the AMD EPYC 7551P virtualized is an absolute beast performance wise and has significantly more storage and network bandwidth available.
Final Words
We are certainly in a different era. The game-changing part of this is that Arm server development on a Raspberry Pi becomes less exciting very quickly. Annapurna Labs had 10GbE built-in in 2015 and has been a serviceable storage platform for years. Putting Arm instances, in volume into the AWS cloud is going to help speed development tremendously. If you want performance Arm, companies like Packet have 96 core ThunderX(1) servers with 128GB of RAM that will run circles around the AWS A1 instances with Graviton.
Another major implication of this whole announcement is that as hyper-scalers decide to do their own chips, companies like Qualcomm have found it difficult to break in. A large hyper-scaler can get an Arm server design team for tens of millions of dollars with a product given Arm’s lower barrier to entry. If hyper-scalers all build their own chips, they squeeze the middlemen and can lower costs. That is not the best for portability, but it puts enormous pricing pressure on Intel’s data center business in the next few years.



{kind=link}
Great article. Good to see TX2 blows these away.
I like that this is at least a balanced viewpoint with data as backup
Great to see that INTEL haters will never die. Keep the good work until another tombstone arises at the Intel cemetary.
What I’m reading between the lines is that this is a negotiation point that AWS will have with Intel for lower pricing.
While the single core performance isn’t quite there yet with A1, at the least these don’t cost Arm and leg
Hoooooly shit how is TX2 this fast on 7zip. Does 7zip work super well with SMT (which is 4-way on the TX2)?
These EC2 instances uh… did anyone at AWS ever look at the pricing for Scaleway’s ThunderX instances???
How does this compare with Scaleways offered ARM servers? I remember them being one of first players in this market.
Comments are closed.