Intel Xeon E-2234 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
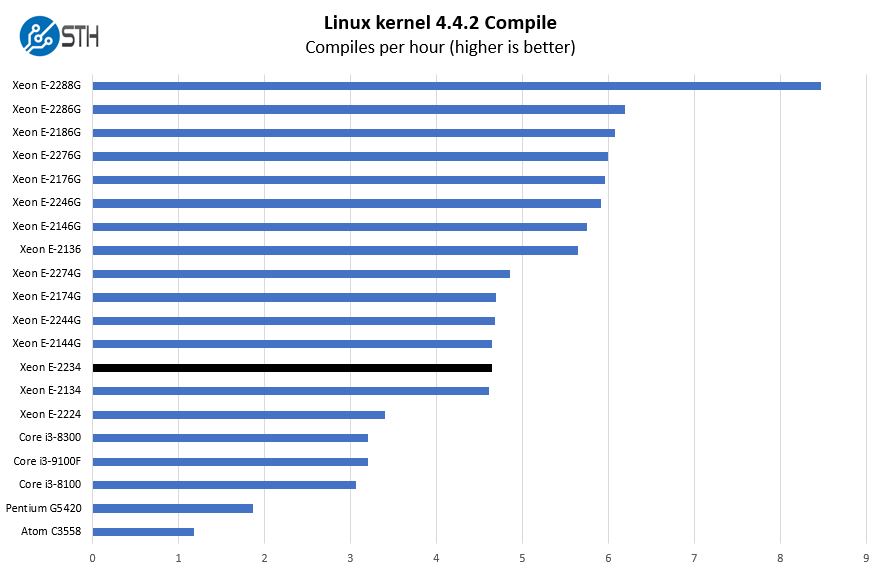
Compared to the previous generation Intel Xeon E-2134 we see a nice uptick in performance. While we certainly welcome this type of performance increase, it is also not something that we would upgrade our existing servers immediately to access. As you will see, this is a very incremental update.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
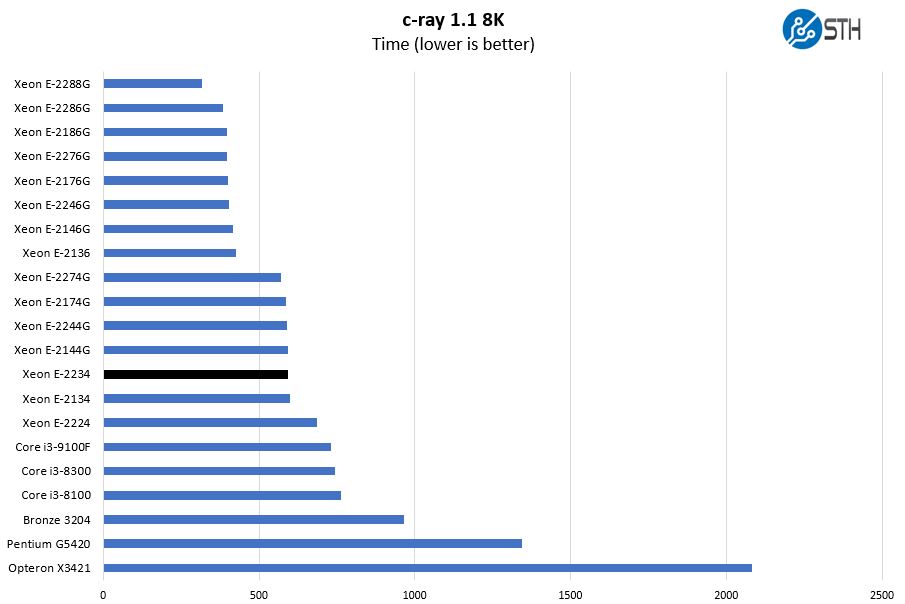
With 4-cores and 8-threads this competes in a virtual dead-heat with the Intel Xeon E-2144G of the previous generation. For customers, this means one can save a few dollars to get the same level of CPU performance. Intel has done this sort of upgrade for years where each new generation in this segment effectively moves the price/ performance down a step with the new generation.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
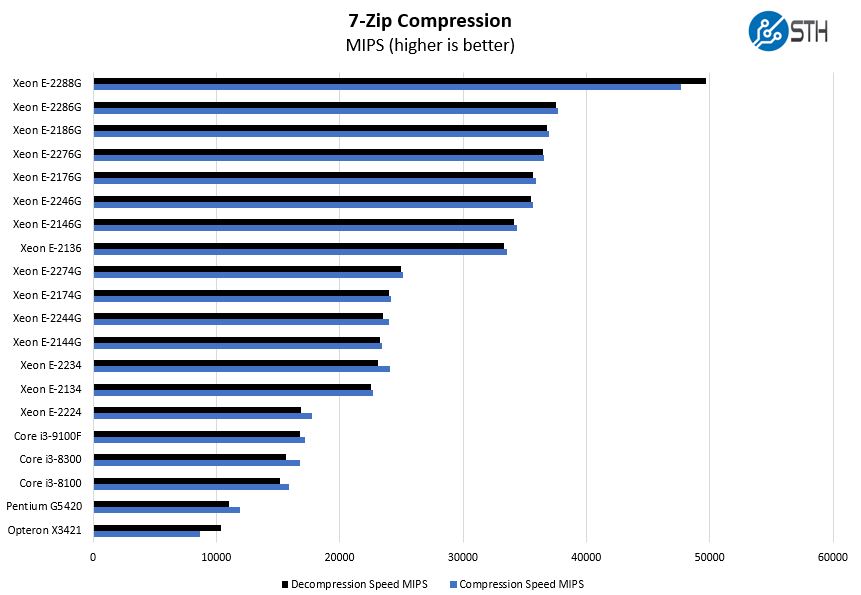
We wanted to focus here on the gap that exists between the Xeon E-2234 and the Xeon E-2224. As you will see, adding Hyper-Threading thereby doubling cores has a noticeable impact on many workloads.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench in the near future. With GROMACS we have been working hard to support Intel’s Skylake AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
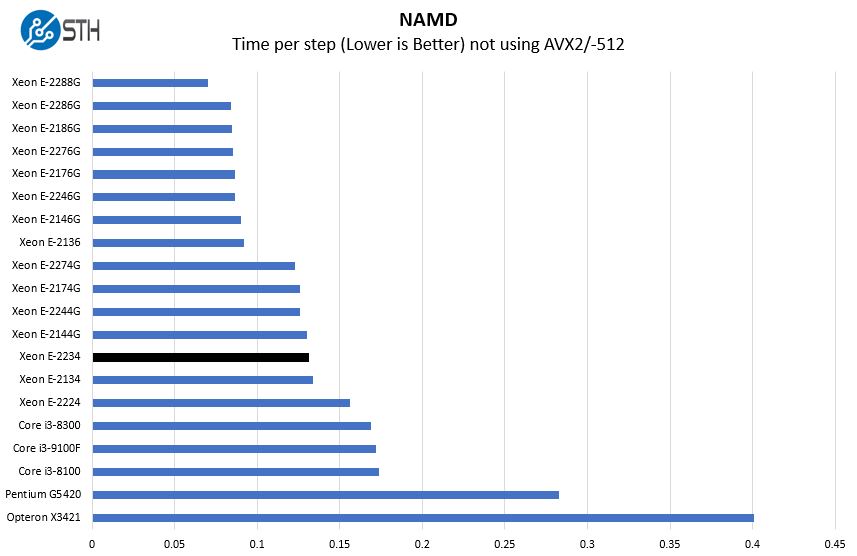
Here we wanted to point out the Intel Xeon E-2136. We have not tested the Xeon E-2236 of this generation but these are 6 core parts that run less than 10% more than the Xeon E-2224. At some point, having more cores and cache is better and one has to remember that that is available for a sub $25 and 9W TDP upgrade.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
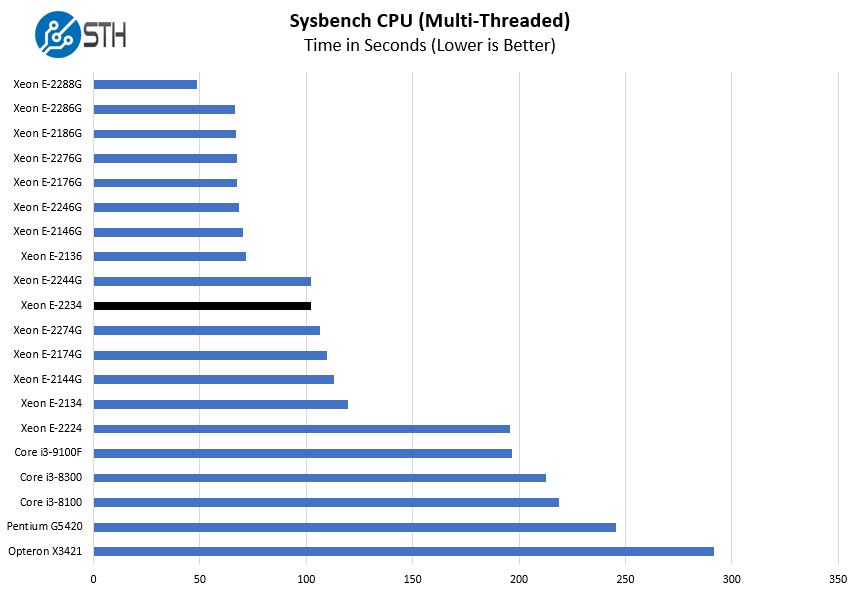
This was an interesting result as the Xeon E-2234 followed the Intel Xeon E-2244G and performed better than the Xeon E-2274G.
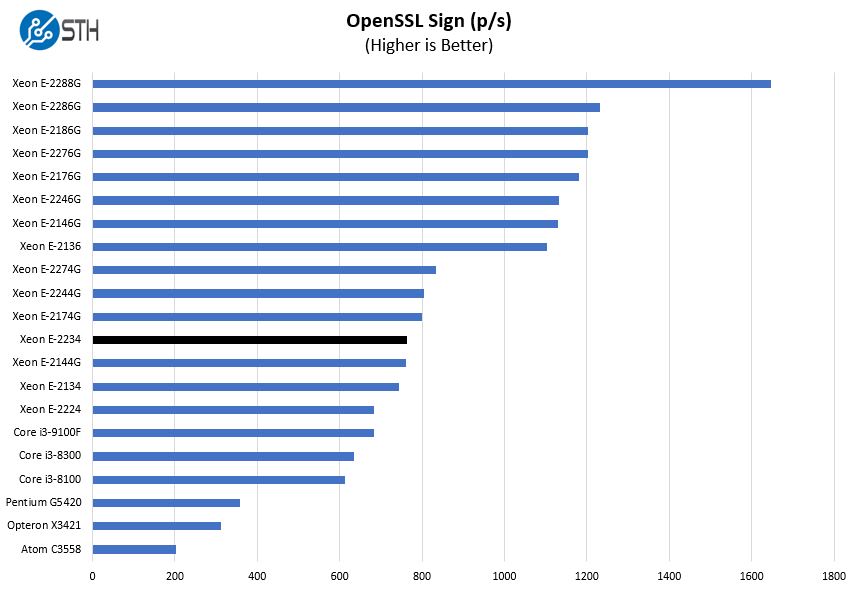
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
Here are the verify results:
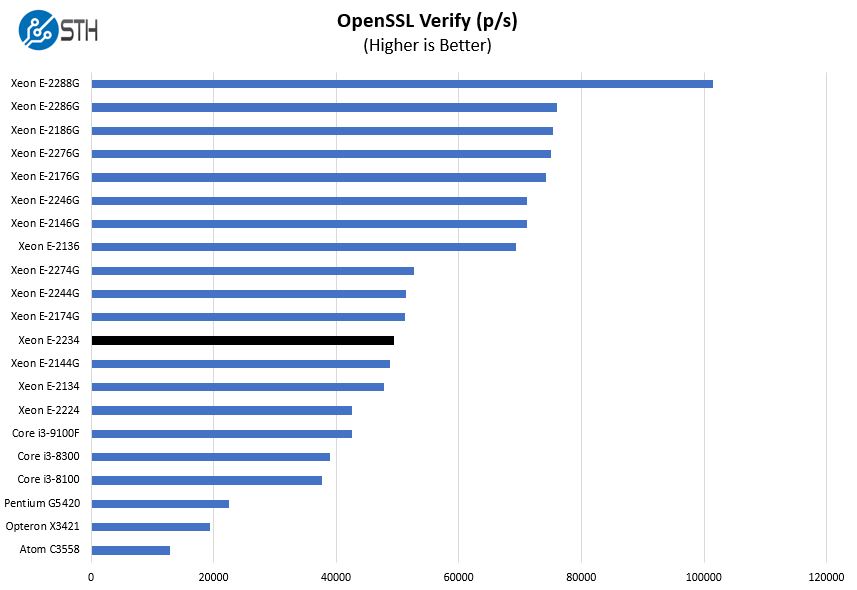
Our top-pick of this generation is the Intel Xeon E-2246G. That part offers 50% more cores, threads, and cache as well as the iGPU for only $61 more at list prices. In many segments, that is a deal-breaker. In others that is one of the best performance per dollar upgrades you can get in the current Xeon range.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
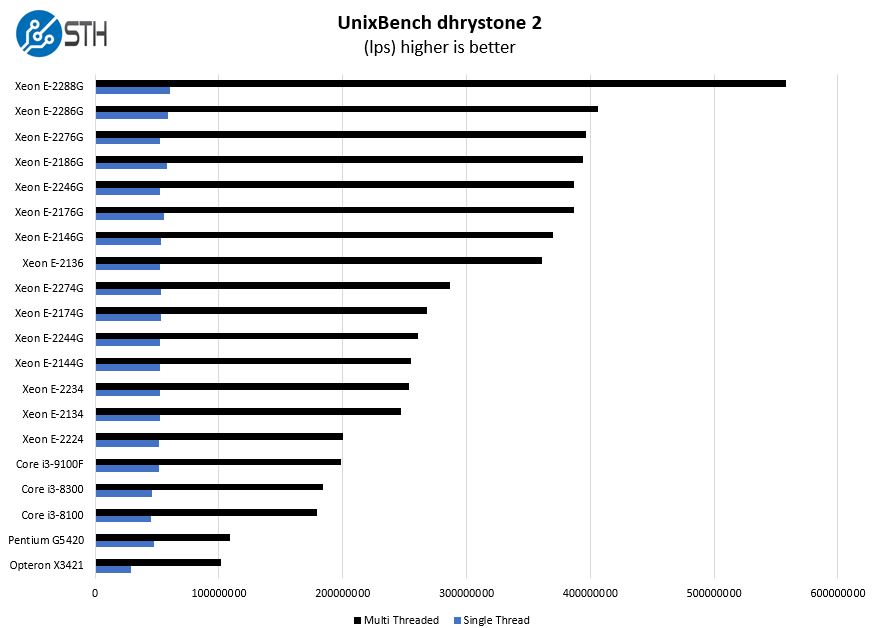
Here are the whetstone results:
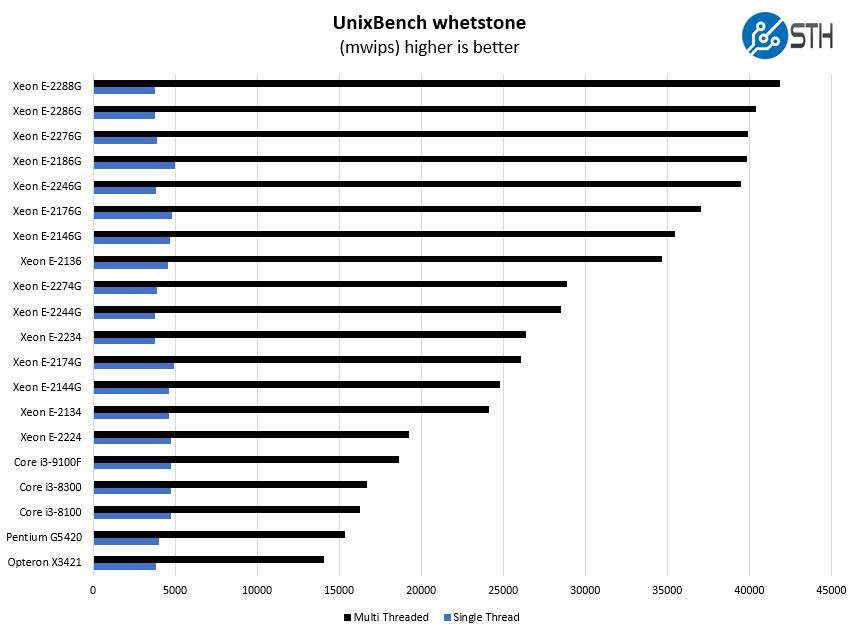
When we look at these parts in the context of higher-end 8-core 16-thread Intel Xeon E-2288G parts we can see just how much this family can scale in the same socket.
GROMACS STH Small AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using a “small” test for single and dual-socket capable machines. Our medium test is more appropriate for higher-end dual and quad-socket machines. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
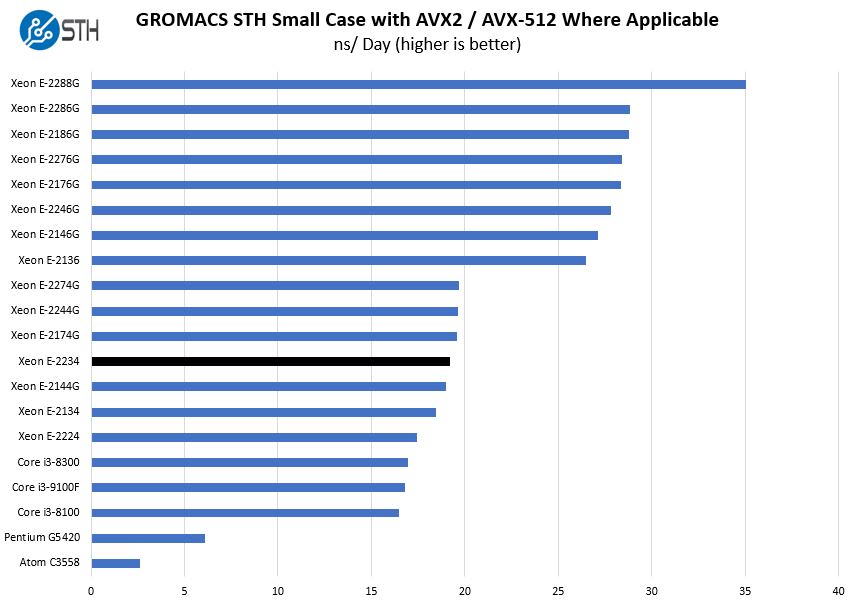
Here we wanted to point out that the Intel Core i3-9100(F) can save around $150 or 60% off the Xeon E-2234G but provides a better performance per dollar proposition. If you truly do not want more performance, Intel has plenty of SKUs that one can use to optimize on cost. There is even the lower-cost Intel Pentium Gold G5420 that can be used in the same socket.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
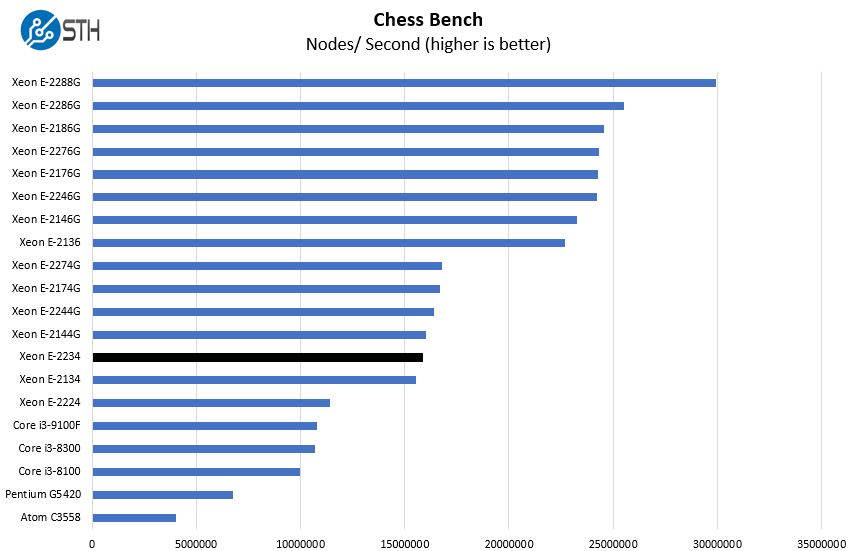
On the chess side, we see similar results. We also wanted to point out that we have a few results from the Intel Atom C3958 in this chart and the others. Moving to the larger cores versus some of the embedded architectures can have a massive impact on performance. Still, embedded parts like the Atom C3000 series can have embedded accelerators such as QuickAsssist as well as embedded networking that can make them attractive in many applications, all while using less power.
Next, we are going to have power consumption, market positioning, and our final words.


{kind=link}
“There are going to be folks who want to point to AMD alternatives. As of this writing, there are really no alternatives in this space because while AMD may have competitive CPU parts, vendors have a vibrant Intel Xeon E-2100/ E-2200/ Core i3 ecosystem.”
ASRock Rack:
X570D4I-2T
Supports AMD Ryzen™ 3rd Generation Series Processors(Max 105W))
Supports 4x DDR4 ECC and non-ECC SO DIMM, max. 64 GB
Supports up 8 x SATA3 by OCulink and 1x M.2 ports
Integrated IPMI 2.0 with KVM and Dedicated LAN (RTL8211E)
Supports 1x PCIe Gen4x16 link (Matisse)
Supports 2x 10GLAN Intel X550-AT2
X470D4U2-2T
Supports AMD AM4 Socket Ryzen™ Series CPUs
Supports 4x DDR4 ECC and non-ECC UDIMM, max. 128 GB
Supports up to 6 x SATA3 6.0Gb/s (inculded 1 SATA DOM), 2 x M.2
Integrated IPMI 2.0 with KVM and Dedicated LAN (RTL8211E)
Supports2 x RJ45 10G base-T by Intel X550-AT2
Supports 2 x PCIe 3.0 x16, 1 x PCIE 2.0 x1
X470D4U
Supports AMD AM4 Socket Ryzen™ PRO/ Ryzen™ 2nd and 3rd generation series processors
Supports 4x DDR4 ECC and non-ECC UDIMM, max. 128 GB
Supports up to 8x SATA3 6.0Gb/s(6x SATA3 6.0Gb/s from X470, 2x SATA3 6.0Gb/s from Asmedia)
Integrated IPMI 2.0 with KVM and Dedicated LAN (RTL8211E)
Supports 2x GLAN by Intel I210AT
Good enough for me.
>X570D4I-2T
Want that so bad. Will be great for my workstation after I move everything to 10Gbps and SAS SSDs.
Afraid price will be crazy too
Misha – John and I are well aware of the ASRR board and Tyan efforts. It is a big difference between there being a motherboard available from a smaller vendor and having all major vendors having multiple systems spanning multiple form factors.
This is a joke of review. No AMD cpu for comparison. Well it must be only way to show that intel is still doing something good, when there is no AMD cpu’s in comparison.
It is a sad day in Mudville when we see STH shilling for a slowly declining Intel.
Patrick – major vendors started as small vendors.
Linaas/ Sleepy, once Dell, HPE, Lenovo, Cisco, or Supermicro have a competitive platform for Ryzen, Ryzen Pro, or a derivative, we will happily add their CPUs to this list. I have been asking the AMD server team to put resources into making a solution in this space.
Misha – while that is true, it will not change before this generation is over.
Having a E3-2324G (4 core + iGPU)
My system is pretty efficient, running 23W in idle. At full 100% CPU usage I see about 100W consumption, pretty bad for a 60W TDP CPU :-(
(no GPU load, all CPU)
Comments are closed.