
Today we are going to launch Part 1 of our performance series on the dual AMD EPYC 7601 series processors. This is going to be the first of a multi-part series. For those wondering why we discussed a bit in our AMD EPYC Infinity Fabric Latency DDR4 2400 v 2666: A Snapshot piece but we have been waiting for our test platforms to mature to the point that we feel confident that our numbers will resemble what our readers will see if they buy systems.
With that said, our expanded benchmark suite runs are automated but take 10+ days to run, especially with the higher-end applications. We also wanted to get enough data we could use to compare systems that will compete in the marketplace. Comparing a $10,000 Intel Xeon Platinum and a $4,200 AMD EPYC CPU is not something that is overly useful since they are focused on different market segments. Every day that goes by we are collecting a significant amount of data on AMD and Intel platforms, but this process does take time. Just to give our readers a sense, at any given time we are now using about 10kW in the data center testing this new generation of gear.
The AMD EPYC 7601 is a great chip and an absolute monster in terms of raw specs. It has 32 cores, 64 threads. L3 cache measures 64MB. There is a total of eight DDR4-2666 memory channels capable of two DIMM per channel configurations or up to 2TB per CPU. PCIe lanes abound with 128x (1P) 64x (2P) I/O lanes per CPU that can be used for PCIe or SATA III. Let us be clear, on a platform level, the AMD EPYC 7000 series is simply awesome.
Test Configuration
For our tests we have been using a Supermicro Ultra platform configured as follows:
- System: Supermicro 2U Ultra EPYC Server (AS-2023US)
- CPUs: 2x AMD EPYC 7601 32-core/ 64-thread CPUs
- RAM: 256GB (16x16GB DDR4-2400 or 16x16GB DDR4-2666)
- OS SSD: Intel DC S3710 400GB
- OS: Ubuntu 17.04 “Zesty” Server 64-bit
- NIC: Mellanox ConnectX-3 Pro 40GbE
We did run tests both with DDR4-2400 and DDR4-2666 and stand by our recommendation that anyone purchasing an AMD EPYC 7000 series system use only DDR4-2666.

We also wanted to make a few notes that we thought warranted discussion. First, we do have some professional application benchmarks that run on CentOS/ RHEL. We use CentOS 7.3 but with EPYC, we are going to suggest upgrading the kernel. Likewise, Ubuntu 16.04 is the current LTS release but we suggest using Ubuntu 17.04 “Zesty” or upgrading the kernel to 4.10 or later if you must use 14.04 LTS or 16.04 LTS. Our general policy is to use standard Ubuntu LTS and CentOS releases but AMD EPYC is getting more performance from newer software ecosystems. This is normal and we expect EPYC to get performance gains as software optimizes for the new CPU architecture.
Just to give one an idea in terms of power consumption, here is what we saw with the platform:
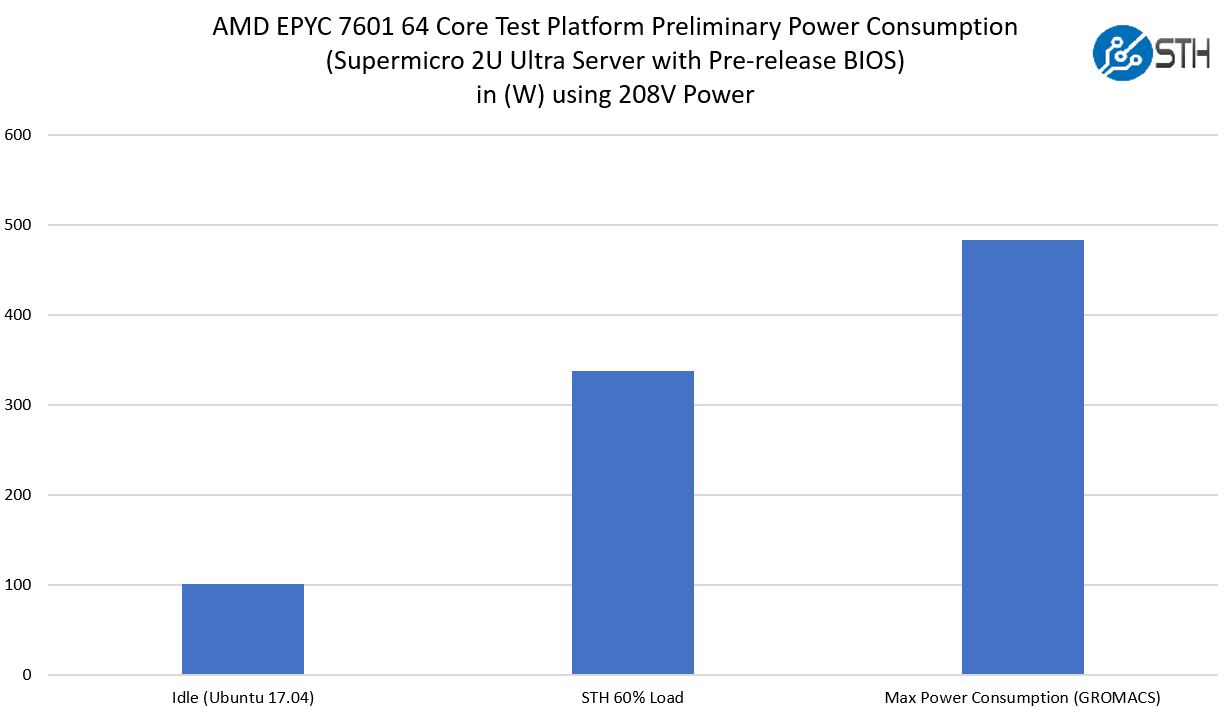
Overall, strong results. We are going to delve more into power consumption as we do the system review since chassis cooling, power supplies and platform configurations make such a big difference in today’s overall server power consumption. These numbers are directionally correct which should provide a sense of power consumption of the platform.
We also expect the Supermicro EPYC platforms to be among the first that are commercially available so it is a reasonable starting point.



{kind=link}
“If you live in environments with VMware, Microsoft, Oracle or other applications where licensing is on a per-core basis then your TCO calculations will look considerably different.”
THANK YOU STH. This is the first review I’ve see – maybe anand’s too – that has a clue. It’s also the least gaming hype-fest evaluation out there.
“when buying your next generation of servers you should look into getting a few to run your workloads”
When can my company by low volume for a test cluster? I can’t get now.
Thank you especially for the compiler and Gromacs benchmarks!
It looks like Epyc is a competent server for many general purpose workloads where the per-core performance doesn’t need to excessively high and you can away throwing cores at the problem. Then again, the lower-priced Xeon Golds certainly and even Broadwell are in the picture too.
That AVX-512 test really puts into perspective some of the over-hype that was seen when a certain website starting with “A” claimed that Epyc running Gromacs was using less than 500 watts of power. That’s true but on a performance per watt scale Epyc is clearly outclassed in HPC workloads, which probably explains the number of Skylake Xeons that are already on the Top 500 list.
As a followup about GROMACS, given your conclusions that the quad-socket server is kind of wasted on that working set, can you post followup numbers that show a dual-socket Skylake machine in the same workload? Even the lower-end Xeon Gold 6150 would be interesting.
Lots of words but it boils down to Epyc is a good entry offering for AMD.
Very interesting review and CPUs, thanks a lot! The EPYC platform looks to perform excellent.
An “alternative fact” made its way into the review:
“If you live in environments with VMware, Microsoft, Oracle or other applications where licensing is on a per-core basis then your TCO calculations will look considerably different.”
VMware Licensing is per CPU socket, which is actually beneficial to the EPYC platform. The platform in this review requires 2 VMware CPU licenses. On the other hand, this particular platform requires 4 Windows Datacenter licenses.
A virtualization server from 2014 with 2×8 core CPU’s would be covered by a single Windows Datacenter license. With VMware licenses it requires the same 2 CPU licenses as the EPYC platform. The generational increases in core counts are thus a great advantage to the VMware customer, while the Microsoft customer has to buy more and more Datacenter licenses as core density increases.
Putting virtualization servers in the same basket as enterprise SQL servers when talking licensing is not fair or representative. Only very few SKUs are actually used for cost effective enterprise SQL server platforms, like E5-2637, E5-2667 and Xeon 5122 and 6134.
A major advantage with the EPYC platform is the 8 memory channels, which means you get 33 % more memory capacity for the same license cost. This is quite important in many virtualization platforms.
One benchmarking metric I would like to see, is a high thread count of virtualized workloads for mixed VPS hosting scenario. For example, like 40 web CMS stacks, 10 small forums, 30 game servers and 20 small Windows RDS servers with desktop workloads.
To Esben – used to be per core in older VMware agreements. We’ve got an client still covered by that model. But you’re right that 6.x changed VMware licensing.
> That’s true but on a performance per watt scale Epyc is clearly outclassed in HPC workloads
Seeing as we have no power consumption numbers for the Quad 8180, we don’t know which one is more efficient.
@Esben and @Hans good callouts on the VMware. Edited that part with a noted. vSphere 6.5u1 falls under per socket. Good point to remember though, the supported VMware vSphere versions are relatively fewer as well.
@Ed – the 4P Intel 8180 is a bad comparison point. I believe it did get to around 1.2kW IIRC, however, that is with more networking, storage and frankly a server platform that was much less tuned than the Supermicro Ultra. The SM Ultra we are using is based on the same line as their Intel servers. When we get an apples-to-apples 4P platform, perhaps the Dell EMC R940 or similar, we will re-run and get numbers to use for comparison. The SM Ultra does not come in a 4P design from what we gather.
The basic rule is that we are doing power consumption at the platform level. If our team does not believe the platform is representative of a shipping product, especially with early samples, we will not publish numbers. That is also why we waited for our EPYC numbers until we were confident in the firmware and DDR4-2666 for Infinity Fabric.
Just some numbers to put things in perspective
EPYC 7601 Base 2.2 GHz all core max. freq = 2.7 GHz 32c/64t $ 4.200 180 Watt TDP
GOLD 6150 Base 2.7 GHz all core max. freq = 3.4 GHz 18c/36t $ 3.358 165 Watt TDP
GOLD 6154 Base 3.0 GHz all core max. freq = 3.7 GHz 18c/36t $ 3.543 205 Watt TDP
PLAT. 8160 Base 2.1 GHz all core max. freq = 2.8 GHz 24c/48t $ 4.700 150 Watt TDP
A Different View Dual EPYC 7601 And Intel UB Whetstone By Core Thread
A Different View Dual EPYC 7601 And Intel UB Dhrystone 2 By Core Thread
Looks like EPYC is faster per clock-cycle.
A Different View Dual EPYC 7601 And Intel Linux Kernel Compile By Core And Thread
The software department of AMD has some work to do (I guess they get help with that).
The easiest way for AMD to compete in higher per core speed is to release the
EPYC 7901X Base 3.4 GHz all core max. freq = 3.7 GHz 32c/64t $ 8.400 360 Watt TDP
(2 threadrippers 1950x glued together)
Interesting results. Now if you could be so kind as do so some OpenFoam CFD benchmarking… CFD tends to be very memory bandwidth constrained and it sounds like EPYC ought to do well in that regards.
Very interesting review – thanks!
Any plans to compare dual EPYC 7601 and/or 7551 server with something like this 4-CPU Xeon blade – https://www.supermicro.com/products/superblade/module/SBI-8149P-T8N.cfm (24 RAM channels and up to 48 DIMMs and 8 NVMe) when it’s populated with 4 low-end Gold CPUs (priced under 2K$ each – e.g 6126/6130/6132 – to have total hardware cost per blade comparable to server with dual EPYC 7551 or 7601)?
Also dual EPYC 7551 vs quad Xeon 5115 and dual EPYC 7601 vs quad Xeon 5118.
Hi Igor, we have a ton of content in the pipeline. We are going to do a top to bottom EPYC comparison, and have almost the entire Bronze and Silver lines done in 1P already. Publishing queue takes some time to work through, unfortunately.
Let me bring that idea back to our team and see what we can put together. It is certainly an interesting concept. Thank you for the feedback.
Hi Patrick,
If those 4-CPU Xeon blades mentioned above aren’t available there’s also a Supermicro quad Xeon 2U server – https://www.supermicro.com/products/system/2U/2049/SYS-2049U-TR4.cfm with very similar specs (except that it’s storage is 4 NVMe + 20 SAS vs 8 NVMe) and with barebone cost of ~3K$ (which seems perfectly reasonable to me).
Igor – that is awesome! I did not even know that existed. Will see what we can do.
Great initiative with https://demoeval.com/ will try it some day.
Good to see that intel scalable processor does great in AVX-512 and in the Intel Linux Kernel Compile, would love to see those tests done with only AVX2 and only generic linux kernel compile.
Can you measure the power draw of the CPU after the vrm’s (like tomshardware does sometimes) during AVX-512, the TDP of the Plat. 8180 is 205 watt, my estimate is 350+ Watts per cpu, just running prime95 would also be helpfull.
Resume:
Intel shines in specific intel optimized software (AVX-512 and Intel linux compiler).
Intel reaches higher clockspeeds on most of their CPU’s.
Intel can go up to 8 sockets, 224 cores, 448 threads where AMD can go up to 2 sockets, 64 cores, 128 threads.
On non intel optimized software the IPC (https://en.wikipedia.org/wiki/Instructions_per_cycle) of AMD is higher or on par with intel cpu’s.
AMD sockets can handle 2048 GB RAM (EPYC 7601 at $ 4200).
Intel socket can handle 768 GB RAM (Plat. 8160 at $ 4700) or 1536 GB RAM (Plat. 8160M at $ 7700).
Dual socket systems are on par with IO.
Looks like AMD EPYC shine’s in 90% of the server market. Lisa Su told us a couple of weeks ago that this 90% is their target market.
HPC (non gpu) stays intel territory.
Looking forward to the cinebench scores of the dual epyc system, a single EPYC7601 does around 5400 in cinebench R15 MT (Maxon has to think fast about something new).
Thanks STH for the unbiased, or maybe most unbiased review of AMD EPYC.
I love all the people screaming at me in YouTube but that’s entertainment. Your reviews are the ones I show to our IT procurement team and my boss for making purchases.
It’s nice to see AMD is supporting this kind of work, even in cases where they’re not #1. I don’t believe that Intel or AMD will be #1 in every metric.
You could have delved into the OS support more. That’s a big deal for us. We have lots of servers on older ESXi and RHEL that aren’t on the support list.
I’m impressed with your results so far.
PS any plan to try the 1S and low cost CPUs? Average server buying price for many companies is below $5K since there’s a market for cheap servers with 3.5″ disks.
RAM: 256GB (16x16GB DDR4-2400 or 16x16GB DDR4-2666)
Is it Single-Rank?
Please test also DDR4-2400 Dual-Rank.
Dual-Rank is faster for Ryzen.
Dual-Rank is faster for Xeon Platinum.
So Dual-Rank must be faster for Epyc too.
I suspect that if you added a couple of GPU’s to the dual EPYC system, you’d get gromacs performance similar to the quad Platinum 8180, for significantly less money. The problem with AVX-512 is that anything it can do, a GPU is likely to do better, though there are cases where AVX will win because using a GPU adds communication overhead.
From Kenneth Almquist:
I suspect that if you added a couple of GPU’s to the dual EPYC system, you’d get gromacs performance similar to the quad Platinum 8180, for significantly less money. The problem with AVX-512 is that anything it can do, a GPU is likely to do better, though there are cases where AVX will win because using a GPU adds communication overhead.
Or a GROMACS run on DeepLearning11, the hardware is availible. 10 GTX1080Ti is roughly the same price as one 8180. On the other hand it uses a lot more power.
You can however buy a lot of kWh for $ 20.000.
@Misha regarding the add GPUs and similar performance could be, but remains to be seen! I think that was AMDs original idea with the Bulldozer design also. Any CPU vectorisation can be done better by a GPU. Perhaps they were just a few years too early.
Pre-EPYC you can find some Gromacs data about Intel+GPU and AMD+GPU in this paper:
https://arxiv.org/abs/1507.00898
@ Johannes I was referring to this http://www.gromacs.org/GPU_acceleration, STH has the hardware with Deeplearning11, so it should be possible to test this(I hope they have some time left to sleep and see the family, etc…). What I’m looking for is perf/dollar, perf/watt, TCO, etc.. for different kind of workloads.
Educated guess:
i9-9700x does 271 GFlops FP32 and 223 GFlops FP64 (AVX2) whetstone, lets assume that AVX512 is twice as fast as AVX2 and the 8180 is 3 times as fast as the i9-9700, that would make around 1,5 TFlops for both FP32 and FP64.
NVidia GP100 does 5 TFlops FP64 and 10 TFlops FP32, conusming the same amount of power as an 8180, it won’t work for all work loads but it’s getting better fast over time.
Or when looking at GROMACS the Deeplearning11 with it’s 10 GTX1080ti’s should do, which is the benchmark we are talking about now.
Very good numbers by AMD, we’ll see how they do dollar to dollar vs. Intel. These will likely be great for workloads such as web application servers that don’t heavily really on shared data structures.
I would be very interested however to see how AMD does vs. Intel on workloads like large databases or things like Spark / Elasticsearch where I/O and memory access figure in (yes, I’m still beating that NUMA horse which to me was a rather large disappointment in the Zen architecture).
Thank you very much for all the benchmarks, but one point really needs some discussion:
HPC performance is no way related to AVX-512 performance. HPC should be translated as computing at the bottleneck, not performance in Linpack. And the bottleneck is almost never peak performance. No one who really cares about application performance will buy a cluster of quad+ socket nodes at the pricetag of $40000 for a single cpu-only node. All HPC codes are very well parallelized using mostly MPI, so what you really want is to have a balanced node performance and interconnect bandwidth.
And since the latter is not really increasing anymore bigger nodes don’t help that much.
However, I do understand that you cannot bechmark real hpc applications, but let me suggest a possible solution:
Run gromacs on a more realistic benchmark, not a large system which no one is interested in, but small systems, especially how many atoms do you need in the simulation per cpu core before the scaling of the node breaks down. And I really guess, that you simply need more atoms per core to saturate the AVX-512 units.
The other thing which is questionable: If I understood things right, only the Xeon Gold 61xx and Platinum series do have 2 AVX 512 units per core, so below the $1691 Xeon 6128 only half Linpack performance is available? Taking into account the reduced AVX 512 frequency you will notice that actually the peak performance decreased or is on par in comparison to Broadwell CPUs at the pricetag below $1700! And as I said peak performance is almost never the bottleneck in real world hpc applications.
@Tobias
“All HPC codes are very well parallelized using mostly MPI, so what you really want is to have a balanced node performance and interconnect bandwidth.
And since the latter is not really increasing anymore bigger nodes don’t help that much.”
From what I see the latter is increasing a lot http://www.mellanox.com/page/press_release_item?id=1933 and with the release of PCIe 4 and the upcoming mellanox IC’s that directly connect to AMD’s infinity fabric(reaction to Intel’s OmniPath, http://www.mellanox.com/page/press_release_item?id=1931 ) I see a huge increase in interconnect bandwidth. Width ConnectX6 already released doing dual port 200 GB/s.
@Misha Engel,
indeed they have begun to push the maximum bandwidth in the last years, but have a look at the bandwidth/flop we had with the release of QDR Infiniband and compare that to the numbers we have now. The same with latency, the big jump came from the integration of the pci-e directly into the cpu not from going from QDR to FDR. Have also look at the bandwidth profiles (http://mvapich.cse.ohio-state.edu/performance/pt_to_pt/): if your application cannot use large enough data chunks, you simply don’t notice the faster interconnect at all and this is really a problem because taking a given problem-size and scaling it to several nodes usually ends up in smaller and smaller data chunks to send around. I think it might be changing with the new competition from Intel to Mellanox. And if you really want to pay for a dual/multi-rail network two single port cards, one for each cpu, is the way to go, otherwise you mess up your inter socket bandwidth and also the latency for the remote cpu is higher in the dual port option.
Building up a reasonable cluster is really sad these days, last year the most reasonable CPU was $671.00 E5-2630v4 this year you get for $704.00 the silver 4114. So lets compare these two:
v4: 2.4GHz 2*AVX2, silver: 2.5 GHz 1*AVX 512
On the AMD side you get now a 7281 2.7GHz which should be able to give about the same peak performance however with more memory bandwidth. The only real reason to still buy Intel is the highly optimized math libraries and compilers.
I would like see a $4200 AMD CPU compared to a $5000-6000 Intel CPU.
I think given the same performance, buyers are usually willing to pay some more for Intel products because
it is the incumbent, has good track record, already in use.
@Tobbias
It used to be easy, just buy intel (and nvidia) and pay the bill, now we have choice. AMD is back, GPGPU starts getting better and cheaper by the day, node interconnect get faster and cheaper.
“CPU was $671.00 E5-2630v4 this year you get for $704.00 the silver 4114. So lets compare these two:
v4: 2.4GHz 2*AVX2, silver: 2.5 GHz 1*AVX 512”
Silver 4114 has 2.5 GHz non AVX all core turbo, I don’t know the AVX512 turbo.
On the AMD side you get EPYC 7351P 16c/32t 2.9 GHz $ 750 or TR1920x 12c/24t 3.8 GHz $ 799.
(Threadripper supports ECC memory).
The silver 4114 will only deliver similar performance in AVX-512 optimized software, the other systems will perform with whatever your throw at them.
We have a lot of options today.
Last 7 years I have nothing but intel at work, home servers. The current latest generation goes to AMD with Epyc.
It’s just all around for different workloads a better processor.
The P series Epyc is were I think HPC’s for the next year will pop up. Massive level of pcie lanes for a densely packed gp-gpu system, or sas/nas or even mixed workloads.
Also you are leaving out that avx 512 downclocks and draws significantly more power.
Love to see avx 512 1P vs 1P epyc+gpu in power consumption vs performance. Think Intel would win in Idle, and under load but what would be the difference between performance vs wattage.
@Tobias, these Gromacs benchmarks are absolutely realistic benchmark systems. Indeed, this was a production system of a research project just over a year ago! Currently it can be considered towards the smaller end of system sizes, but those systems need a lot of sampling and very long trajectories and are hence very important.
If you go to HPC facilities and apply for computing time, they want to see scaling of your code for 2000-4000 cores. For that you’d use multiple nodes with MPI. This scaling you only achieve with large systems, and thats what these Tier-0 hpc facilities are for! Compare this 57000 atoms system to a Tier-0 system with multiple million atoms to get an idea what a large system means.
The system shown here would be a sub Tier-1 system. The larger mentioned thats still to come is a Tier-1, also used for “official” hpc benchmarks (TestCaseA):
http://www.prace-ri.eu/ueabs/#GROMACS
If we care for single node performance, than the ones shown here are the system sizes of interest. And the scaling of atoms/core already was and still is being evaluated. Just do a quick comparison of the Gold 6132 system with AVX2 and the Platinum 8180 AVX-512 system with frequency and core ratios and see how well even this small system scales up to the quad Platinum system, meaning system is quite likely already *large enough* for an acceptable #atoms/threads ratio, even for AVX-512.
Your criticism seems a bit based on guesses and assumptions.
Maybe I was somehow unclear, I do have a problem with statements like: AVX 512 is the killer argument for HPC so AMD does not have a chance in HPC. I thought I made clear, that AVX 512 is only going to push the Linpack numbers for CPUs> $1700 that are anyway not commonly used in HPC clusters.
Forget about GPUs most are simply bought because of politics to have a nice Linpack performance
@Tobias – I cannot officially comment but it may be worth reading the last section here https://www.servethehome.com/intel-xeon-scalable-processor-family-microarchitecture-overview/
Also, there were three Skylake-SP TOP500 systems in the list before Skylake was released https://www.servethehome.com/new-top-500-supercomputer-list-released-insights/
@Patrick Just look at the difference between peak and measured linpack performance and this ratio is really bad for #65 (BASF) – I hope that this is due to immature bios / software. However, if Linpack cannot even reach 80-90% of peak what else can?
Coming back to gromacs, it would be really nice to see how many atoms/core are needed to get a good scaling, because in the end you want a improved time to solution. So if you ask me, it looks like that you need bigger problems on each core to feed the avx-512 units and then your simulation needs less nodes but the time to solution will not change.
And since you are pointing to top500, they also wrote a nice article about the issue:
https://www.top500.org/news/with-epyc-amd-can-offer-serious-competition-to-intel-in-hpc/
If Intel would have enabled both FMA units on the inexpensive CPUs it would completely change the picture but spending so much for a single CPU… there will be customers for that cpu but look how many supercomputers were build with the former E7 series.
Strange things are happening:
NVidia welcomes threadripper https://twitter.com/NVIDIAGeForce/status/895746289589039104/photo/1
NVidia tesla p100 ($ 6500) 250 W is more than twice as fast as Xeon Phi 7290F ($ 3368) 260 Watt. https://www.xcelerit.com/computing-benchmarks/processors/intel-xeon-phi-vs-nvidia-tesla-gpu/
and at least 1.6 times faster in FP64. Volta is comming….at least 50% faster than Pascal with 250W.
NVidia must love cheap EPYC’s with all the PCI lanes and have still time left to prepare for NAVI (I don’t think they are scared of VEGA). They stop licensing their GPU tech to Intel (maybe larrabee comes back).
Intel hitting 3.2 GHz all core turbo non-AVX vs 2.8 AVX2 vs. 2.3 AVX512 (within the 205 TDP. don’t know what that means in intel land looking at i9-7900 doing 230 Watts in prime95 running at stock speeds, TDP is 140 Watt) https://en.wikichip.org/wiki/intel/xeon_platinum/8180
2018 is going to be a different year for Servers and HPC.
Exciting times.
@Tobias BTW, contrary to many claims, both relatively cheap i7-7800X and i7-7820X have two FMA units enabled and therefore full AVX512 throughput. However, unlike Xeons they have only 4 memory channels, of course. But the balance happens to be the same as for gold Xeons.
@Vlad Yes I also noticed this, but for the Xeon CPUs the number of FMA units is officially declared in Intel ark:
https://ark.intel.com/products/120481/Intel-Xeon-Silver-4116-Processor-16_5M-Cache-2_10-GHz
Is there any news on successor of the Xeon-1600 series? If these cpus would have both FMA and 6 channel ram, that would be an option to think about.
“From a price perspective, AMD and Intel are going to compete in the single and dual socket markets between the Intel Xeon Bronze and Gold lines. The Platinum SKUs are Intel’s low volume highly specialized tools. That is why we pulled results from most of the charts above. While a $3300 and a $4200 CPU may compete in some markets, a $4200 and $10000 CPU are unlikely to compete.”
What if AMD would allow MB-makers to interconnect EPYC socket’s via PCIe (in the MB, not on) and build a hexa core MB. There is no technical reason not to do it (EPYC is SoC).
32PCIesocket032PCIesocket232PCIesocket432PCIe
infinitifabric socket 0,1 infinitifabric socket 2,3 infinitifabric socket 4,5
32PCIesocket132PCIesocket332PCIesocket532PCIe
It looks like a Mesh interconnect!!!
6 socket with 128 pcie PCIe lanes with approx. the same power usage as a quad 8180
(3x480W – 3xMellanox ConnectX-3 Pro 40GbE – 2xIntel DC S3700 400GB) vs. (1x1336W).
MB price would be around the same, same would count for the rest of the system except the CPU price.
Intel 4x$10.000=$40.000 vs. AMD 6x$4.200=$25.200 that makes a price difference of about $15.000
About the same speed when quad8180 can use (AVX512).
(GPU’s will still be a lot faster in vector apps).
AMD hexa7601 will be around 1,5 times faster in most other tasks and is $15.000 cheaper.
AMD still has to work on the Linux compiler.
hello
can i ask for cinebench score of dual 7281 epyc s ? can u emulate it from 7601 ones ?
Hopefully next version of EPYC CPUs (EPYC 2 ?) will support quad-CPU configurations – otherwise their chances of successfully completing with quad-CPU Xeon servers with 4 low-end Gold CPUs (those <2K$ each) aren't great. And without serious competition from AMD we all know that Intel will charge much higher prices.
However, as of now server with 4 x Xeon 5120 appears cheaper and (likely) faster and also more expandable (using pretty cheap server with motherboard having 48 DIMM sockets on 24 memory channels and 6x16x + 5x8x PCIe etc) than dual EPYC 7601. Of course, actual performance tests will need to be done – maybe Patrick will have a chance to do those.
@janosik
I don’t know how valid these result are.
http://www.cpu-monkey.com/en/cpu-amd_epyc_7281-734
janosik – we should be able to provide actual numbers in the next week or two and will be doing top to bottom figures for all SKUs in the EPYC line.
@ Patrick Kennedy
thank you so much , because i am thinking about buying these 7281 cps for my new workstation …..
and now maybe i am litlle more eager : can i ask for some render benchmarks like a vray or corona bench ? it will be for rendering stuff and no blender is not an option nor pov ray /wtf is that ?/ if not , cinebench will be ok ish ….
@janosik
http://benchmark.chaosgroup.com/cpu
@IgorM
“However, as of now server with 4 x Xeon 5120 appears cheaper and (likely) faster and also more expandable (using pretty cheap server with motherboard having 48 DIMM sockets on 24 memory channels and 6x16x + 5x8x PCIe etc) than dual EPYC 7601. Of course, actual performance tests will need to be done – maybe Patrick will have a chance to do those.”
Under which circumstances do you think this quad xeon 5120 be faster than a dual EPYC?
@MishaEngel
Based on the published (and not published – not the same as unpublished) CPU2006 numbers – under many (but certainly not all) circumstances.
I hope that Patrick will be able to get hold of the necessary hardware and confirm (or disprove) it.
@IgorM
5120 is made for 1 or 2 socket servers (2 UPI links), the 6 and 8 series have 3 UPI links and are made for 1,2,4&8 socket servers. 4 and 8 socket servers can shine in applications where you need a lot of compute power with software optimized for X86 and/or AVX512 and when the software can’t be optimized for GPU.
When the software is (can be) optimized for GPU, a board like the Tyan Thunder HX GA88-B5631 (or an AMD equivalent) and/or the STH Deeplearning11 will be a better option with respect to price, space and power.
AMD stated that they are not after the 4&8 socket server market (for whatever reason) which is only 10% or less of the total server market. AMD does have a nice offering in the 1&2 socket server market, specially in the 1 socket server market they will be hard to beat (AMD’s 1 socket is not only competing with intel 1 socket but also with intel’s 2 socket offerings).
@MishaEngel
Xeon Gold 5120 may be less optimized for 4-CPU configs than 6100 series CPUs but it definitely works in 4-CPU servers – see for example http://spec.org/cpu2006/results/res2017q3/cpu2006-20170626-47245.html .
And if for some workloads extra latency due to having only 2 (vs 3) UPI links/CPU is important, it could be upgraded to quad 6126 for under $1000/server – which then should cost almost exactly the same for a barebone with 4 x Xeon 6126 vs barebone with 2 x EPYC 7601 (while still having 50% more RAM channels and slots and also more PCIe lanes).
That’s why I wish that EPYC 2 will support 4-CPU configs because then price/performance and expandability advantage of 4-CPU Xeon servers using low-end CPUs will disappear.
Actually upgrade from quad 5120 (14 cores, $1600/CPU retail) to quad 6130 (16 cores, $1900/CPU retail) is probably optimal – and quad 6130 will very likely beat dual EPYC 7601 (>$4,500/CPU retail) in many/most workloads.
@IgorM
You can almost always find a way to fit something in when you leave a few arguments out.
Like actual power usage (at least 300 Watt more than the dual EPYC 7601), where to put the rest of the components (4 sockets plus ram slots take a lot of space) price of the motherboard and where to find them. (just look how much space is left in the Tyan Thunder HX GA88-B5631 and that one fitted just in the server rack with no margin left).
I don’t think many potential customers will go for this configuration.
@MishaEngel
Actual power usage isn’t relevant if there are many servers (which is typically the case for buyers of such hardware) – however power/performance is certainly relevant but we don’t really know yet how they’ll compare on that metric (and it depends on the workload also).
As to the size – pls take a look at 2 examples of both types of servers (quad Xeon vs dual Epyc)
https://www.supermicro.com/products/system/2U/2049/SYS-2049U-TR4.cfm?parts=SHOW and https://www.supermicro.com/Aplus/system/2U/2023/AS-2023US-TR4.cfm?parts=SHOW
and let me know why do you think the difference between depth of 30.7″ and 28.45″ is relevant
(other dimensions – as well as power supplies ratings and maybe even models – are the same).
@IgorM
Actual power usage is super important if there are many servers.
Higher power line network cost, higher power usage of the server (electricity bill goes up, 300 watt extra 24/7 is $0.20/kWh = $525/year), larger cooling system, higher power usage of the cooling system approx $ 125/year for 300 Watt (with a cooling systeme effeciency of 400%).
Those are the dimensions of the Rack, have a look at the motherboard, there is an extra row of mem-slots and cpu’s.
One can make a dual-socket motherboard and put (DeepLearning11)10 GTX1080ti’s in it, they can’t do that with a 4 socket motherboard within the same dimensions.
Even NVidia is happy with AMD since Threadripper and EPYC because of all the PCIe-lanes, they might even sponsor Mellanox, to make sure that as many single socket EPYC’s are sold as possible, inter connected with InfiniBand. The main reason for NVidia to give away high end GPU’s is to make sure the software runs CUDA, same reason why intel gave away lots of XEON Phi’s for AVX512 and AMD VEGA for OpenCL. Now intel is trying to push Skylake for AVX512.
And yes is would be nice if AMD could also offer a 4 socket system.
@Igor M @Patrick
Hi,
Looking at the Xeon Sp vs Epyc price sheet.
It does look to me like Intel is pricing its lower end Xeons so that a dual socket Xeon is about the same as
a single socket EPYC of the same cores.
So dual Xeon Silver 4108, 4110 (2 x 8 cores)competes against single Epyc 7281, 7301, 7351(16 cores).
dual Xeon 4116, 5118(2 x 12 cores) vs single EPYC 7401, 7451(24 cores)
dual Xeon 6130 (2 x 16 cores) vs Epyc 7501, 7551, 7601(32 cores)
Those CPU combos are in the same price range and same core counts
So it would be nice to see how Dual EPYC 7601 ($8400) fares against Quad Xeon 6130($7600), 64 cores each.
And how much power these systems use.
Does AMD’s Infinity Fabric use a lot of power?
So… Part 2?
Possibly the dumbest question ever;
Is it possible to run unmatched EPYC processors in 2p configuration, or must they both be identical core counts, identical clocks?
Comments are closed.