
Inspur is the fastest growing large server maker, currently sitting at #3 in IDC tracking just behind Dell EMC and HPE. The company’s main focus at this time is on the cloud service provider market where it has enormous market share within the large Chinese hyper-scale companies, speficially in the domain of AI and GPU compute servers. In the last week, Inspur presented several new solutions at the OCP Summit 2019 and NVIDIA GTC 2019 both in the San Jose Convention Center. We wanted to pick a few highlights from their booths and presentations to show the level of innovation the company is achieving with its large CSP customers.
Inspur 32x GPU Node and JBOG Contribution to OCP
When it comes to scaling up GPU servers, Inspur had an absolutely fascinating solution. Although the SR-AI rack has sixteen PCIe GPUs, and expansion for up to 64 GPUs in the complex it is still a PCIe architecture. For those that want to scale up without having to go over InfiniBand, Inspur has a solution for attaching 16, or more, GPUs to a single server node and utilizing NVLink. Inspur’s solution: instead of attaching each 8x GPU baseboard in a NVIDIA HGX-2 based chassis to a CPU, instead connect each PCIe switch in the HGX-2 design to a CPU. Inspur does this by connecting each of the CPUs to a PCIe switch in a quad socket server.

Inspur claims that utilizing the high-speed NVSwitch architecture from the HGX-2 plus the scale-up features of the quad socket design means that it can get 20-60% more performance. The design also allows the use of more memory and more CPU cores for the sixteen GPU system than a standard HGX-2 / DGX-2 design.
Scaling-up does not stop there. In the standard HGX-2 dual socket design a CPU is connected to two PCIe switches on a HGX-2 baseboard and therefore eight GPUs. Inspur can utilize the NF5888M5 quad socket server and attach a HGX-2 baseboard with eight GPUs per CPU as well. That yields a 32 GPU server spanning three chassis.
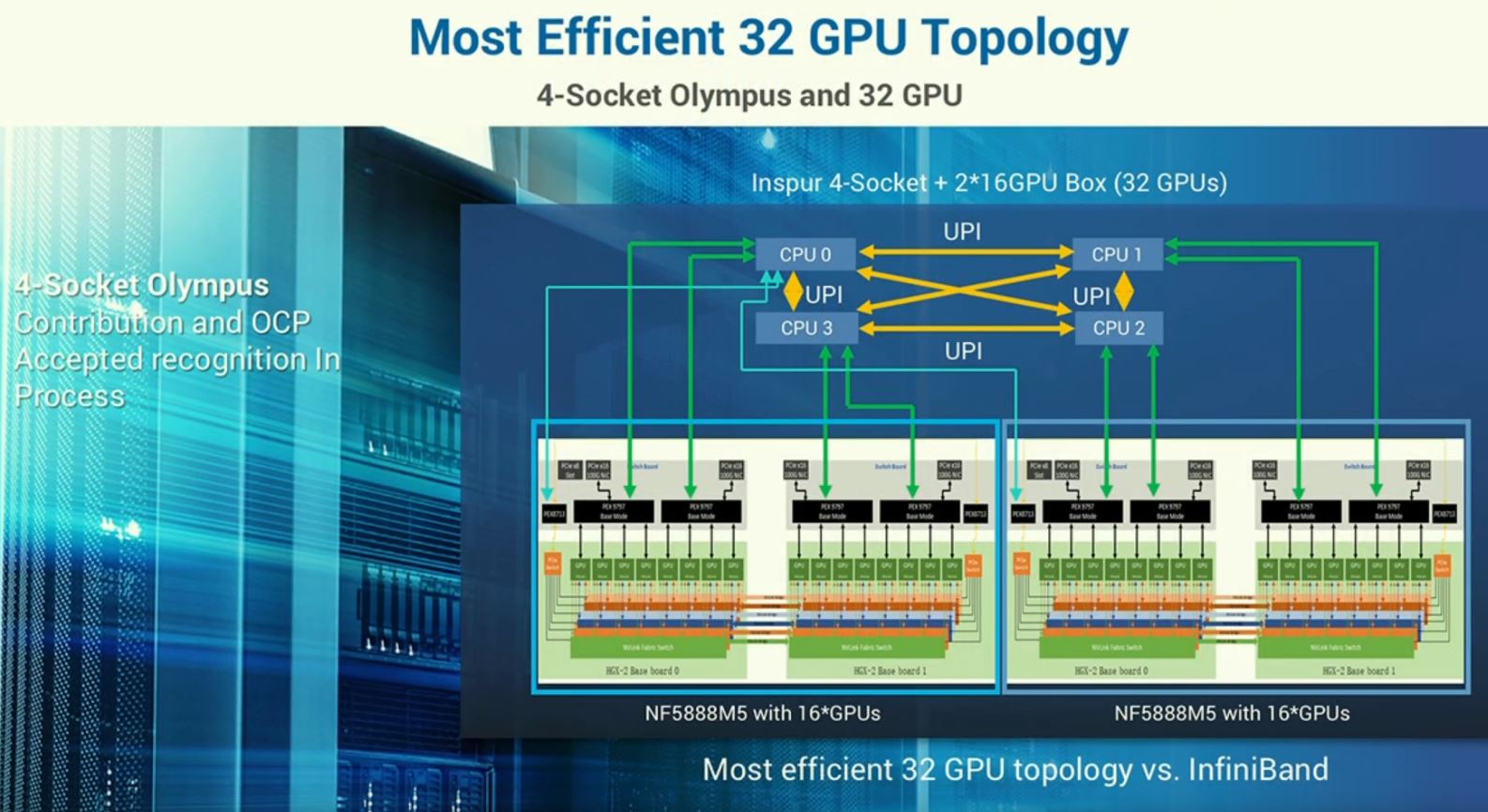
The implication here is that one can essentially connect 32 GPUs to a single node that has access to the shared main system memory, NICs and storage. One can scale up model training across 32 GPUs in a single system before having to go over InfiniBand to other nodes. This is truly innovative design and far beyond the re-badging of a HGX-2 server that some other vendors are doing.
The Baidu Inspired Inspur SR-AI Rack
GPU pooling system using two layers of switch to link 16 GPUs in a single 4U box. Through the PCIe cables, those GPUs can be used by one to four servers.

The SN3410M5 SR-AI Rack utilizes a multi-level PCIe switch topology and 16x GPU PCIe GPU boxes to increase deployment flexibility between server nodes and GPUs. An administrator can partition the 16x GPU shelves to be dedicated to a single node or partitioned off to up to four nodes. In that way, the same physical infrastructure can be used to support four compute nodes each with four GPUs or even three CPU compute only nodes and a 16x GPU node.
This setup is one that Baidu uses to increase its infrastructure agility and speed of deployment.
The Inspur NF5488M5 “Half HGX-2”
One of the key differences between the NVIDIA DGX-1 and DGX-2, and their partner base model HGX-1 and HGX-2 derivatives is that the latter utilizes twice as many GPUs along with a high-speed NVLink switched fabric. The DGX-1/ HGX-1, by contrast, utilizes a lower performance point-to-point NVLink. The Inspur NF5488M5 combines the deployment friendly (sub-5kW) eight GPU per node form factor with high-performance NVSwitch fabric.

We asked about the overall power consumption for the NVSwitch fabric in the NF5488M5 and were told that it was only a few hundred watts. This is yet another case where the company is going beyond the status quo and why Inspur has become the leading AI server vendor in China.
On the next page, we are going to look at some of the CPU compute and inferencing designs that were shown off at OCP Summit 2019 and GTC 2019.



{kind=link}
Those are some amazing GPU servers. 32 V100 = 1TB of video RAM plus you can stuff DIMMs into it. I want to know if it can handle apache pass and how much they cost
Comments are closed.