
The IBM POWER10 is coming. Generally, IBM announces its new processors about a year before availability. With the Hot Chips 32 (2020) announcement, we expect that these new chips will debut in systems in Q4 2021. Since IBM is so far ahead announcing products, and because unlike much of the rest of the industry IBM is not following Intel Xeon, POWER10 gives us a glimpse into the future of computing. IBM is offering new features in POWER10 that we will not see until late 2021/ 2022 from many other vendors.
As a quick note, we are using the IBM pre-brief materials for this, so we will update this article as the actual Hot Chips presentation proceeds.
IBM POWER10 Video Version
For those that want to hear a bit about the new processor, we have a video version.
In the video, we focus more on what the IBM Power10 tells us about the future of computing rather than getting more into the microarchitecture. There is a lot here that tells us about what customers are asking for in late 2021 and beyond.
IBM POWER10 Overview
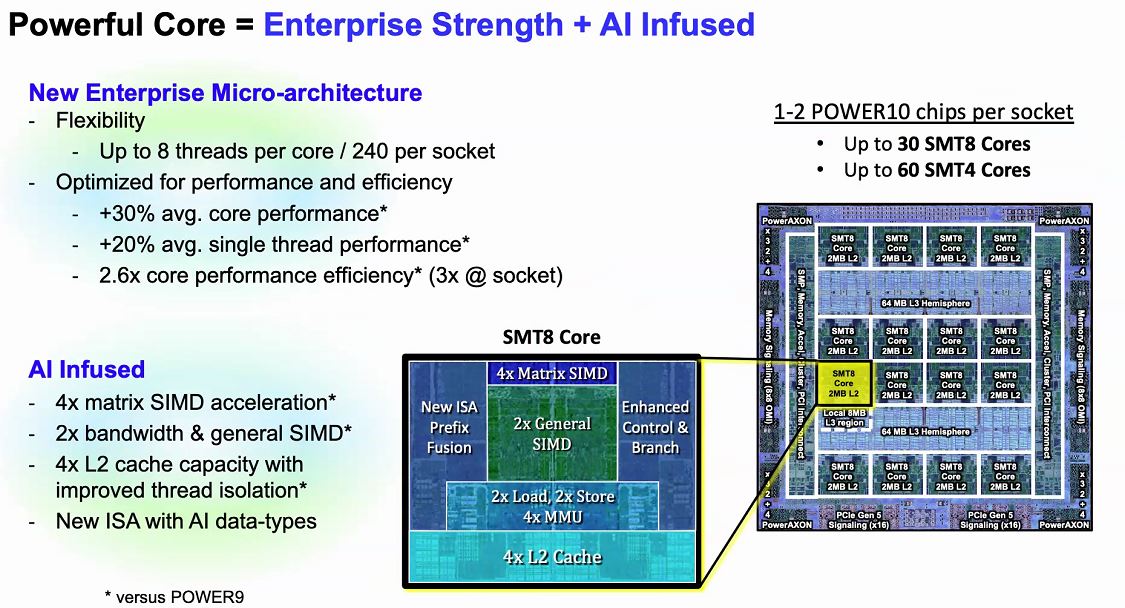
The IBM POWER10 is a big chip. IBM is moving to the Samsung 7nm process and will offer not just one, but up to two die packages. Moving to a 7nm process allows IBM to provide more compute in a lower power envelope than with IBM Power9.

We get up to 120 threads per chip but that is only a small part of what is happening here. We also get new AI boots, new faster OMI instead of DDR signaling for future memory connectivity, faster PowerAXON for a flexible interconnect, and PCIe Gen5 for general-purpose connectivity. Overall, this is a lot new, so we wanted to unpack what this means at a core, then at a system level.
Something you may notice is that there are 16x SMT8 cores as well as 128MB of L3 cache yet IBM quotes a maximum of 15 core die with 120MB of L3 cache. For yield purposes, IBM is effectively expecting to use 15 of the 16 cores and 8MB L3 chunks.
IBM POWER10 Core
Taking a look at the ore, we get SMT=8 operation. We can also get two POWER10 chips per socket which mean we can get 30 SMT=8 or 60 SMT=4 cores per socket. The POWER10 core can run with eight threads, or effectively partition itself to two cores that can each run four threads. IBM is claiming massive performance gains.
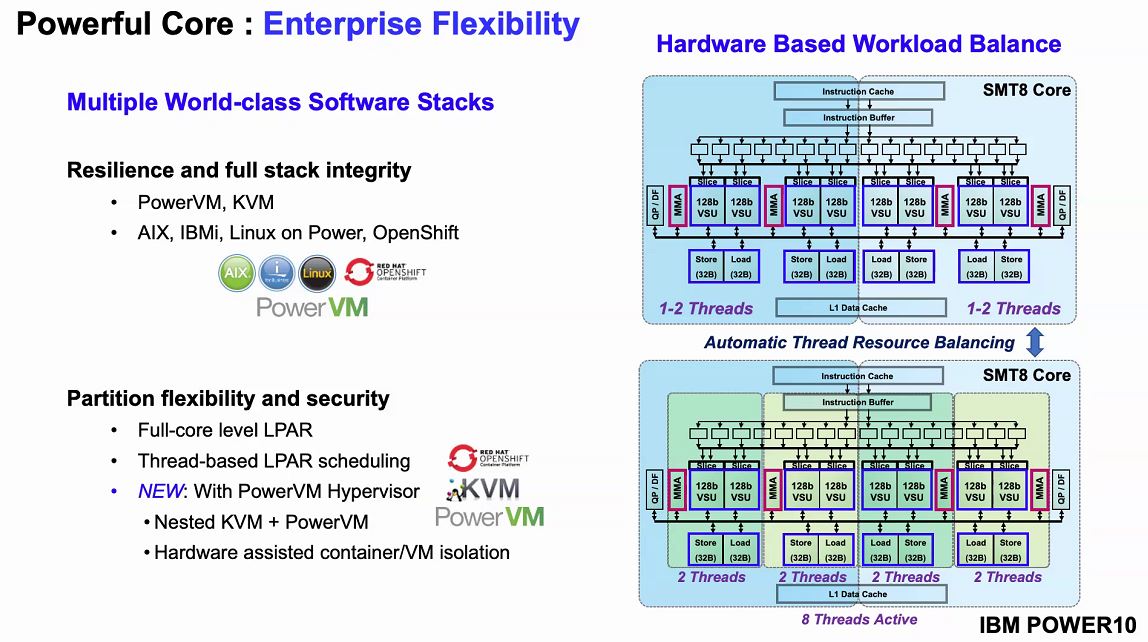
One of there interesting features of the new chip is it is supporting KVM nested in PowerVM. If you want the security of PowerVM yet still want to run KVM virtual machines or isolated containers, IBM now has a solution enabled by POWER10.
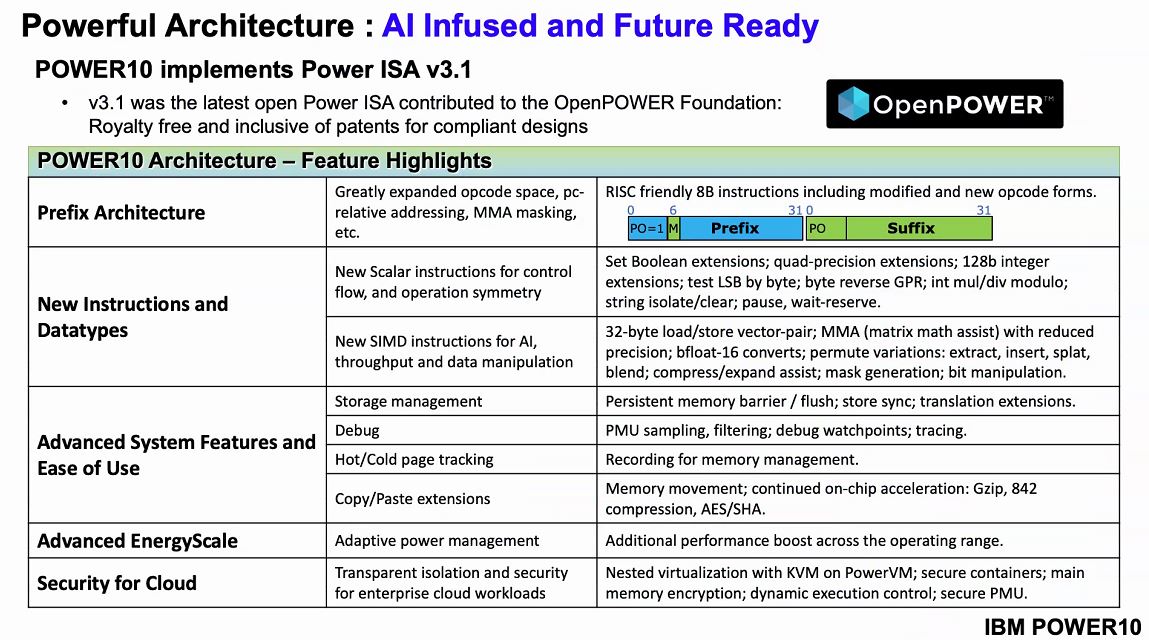
Another major leap forward is the Power ISA v3.1. This has been contributed to the OpenPOWER foundation. We will let you read some of the individual features below, but IBM has advanced the ISA and therefore performance.
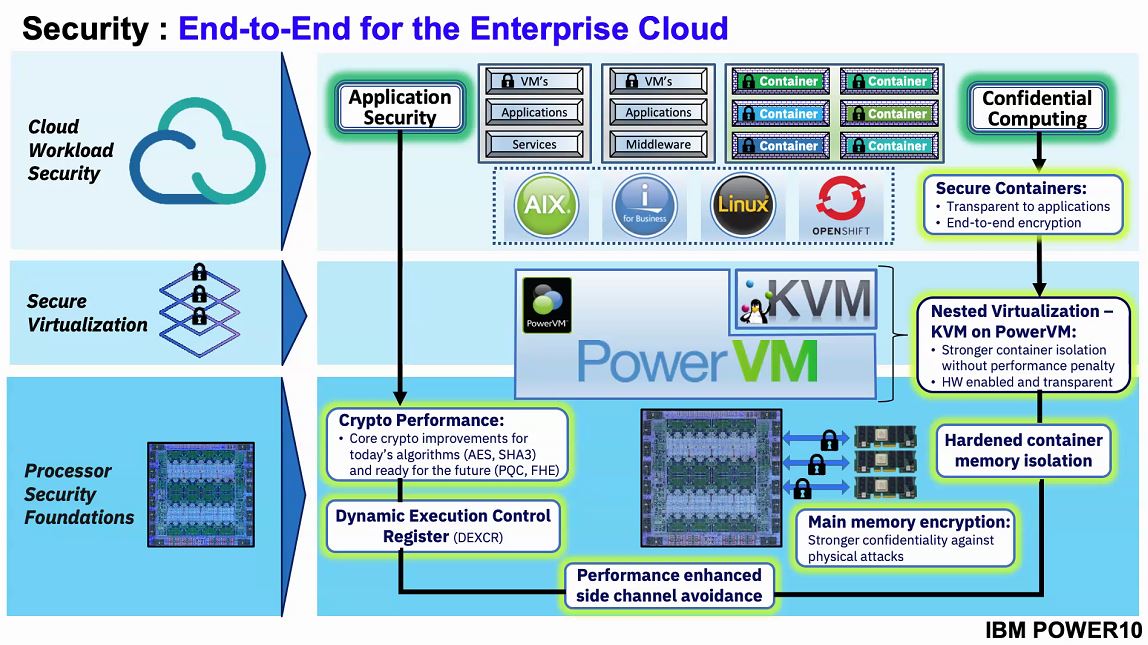
Since this is IBM, security is a big driver of their platform. We can see that IBM has a confidential computing push in this generation including features such as hardware memory encryption. For some reference, AMD EPYC “Rome” shipping today does memory encryption and enabled Google Cloud Confidential Computing. For Intel, we are going to have to wait until Ice Lake Xeons for SGX to go mainstream along with memory encryption on the server-side. We covered this recently in Intel Shows Ice Lake Xeons and Talks Sapphire Rapids and Xeon D during Intel Architecture Day 2020.
One of the interesting parts about the IBM Power10 is that the cores are big enough that even IBM splits the cores in half to a SMT=4 core in order to show off the architecture. We are not going to deep dive here, but the IBM team did significant work improving the efficiency of the microarchitecture to deliver performance per watt savings.
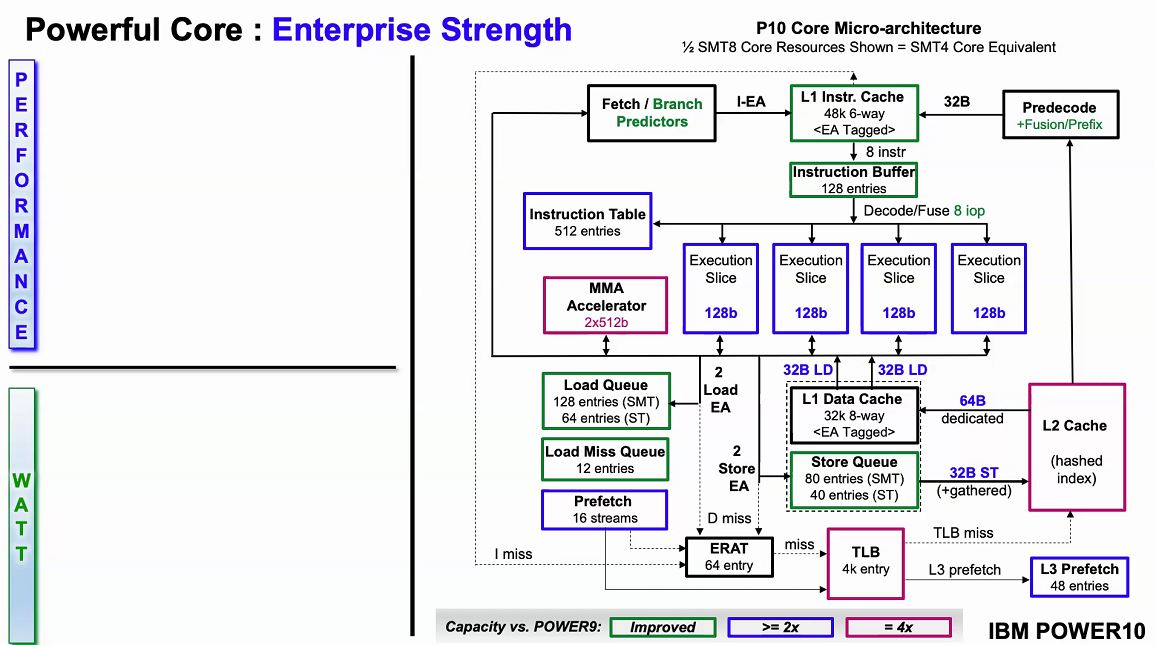
Naturally, IBM has an AI story. The company focused improvements to add twice the bandwidth and flops per cycle for many common types of compute. By moving to OMI plus enhancements in the company’s caching structures, POWER10 is designed to move twice as much data through the processor.
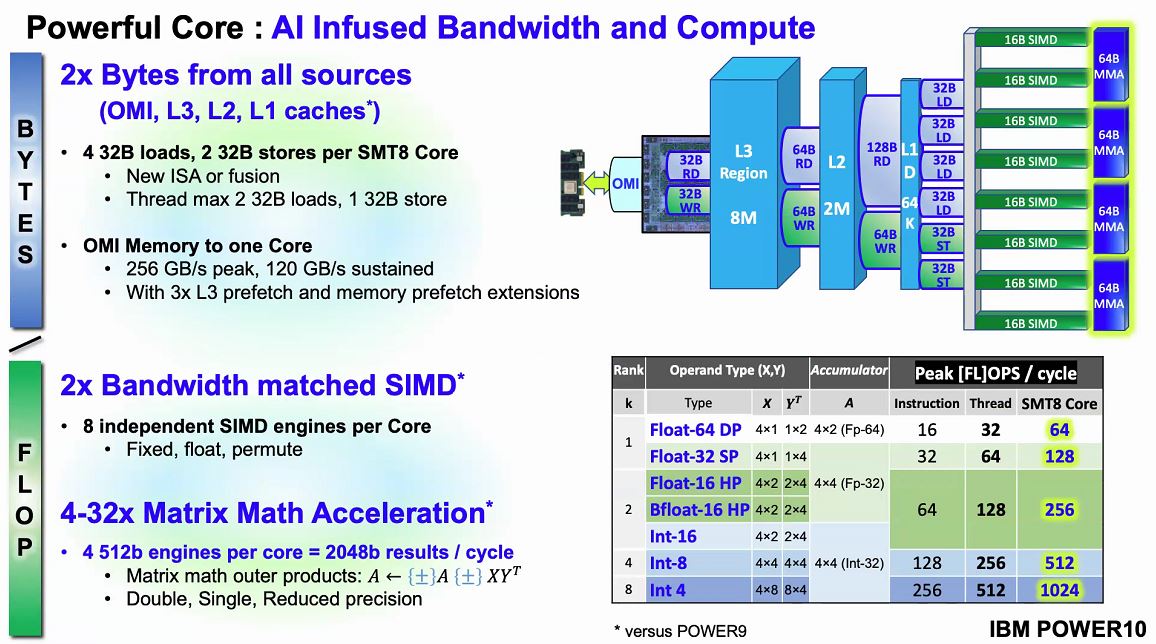
The company also includes support for bfloat16 for training as well as INT8 and INT4 common for AI inferencing. IBM is subscribing to a view similar to Intel where the CPU cores can in many cases replace accelerators removing the need to go off-chip. For some workloads, the memory requirements are so extreme that 40GB of NVIDIA A100 HBM2 memory is simply not enough.
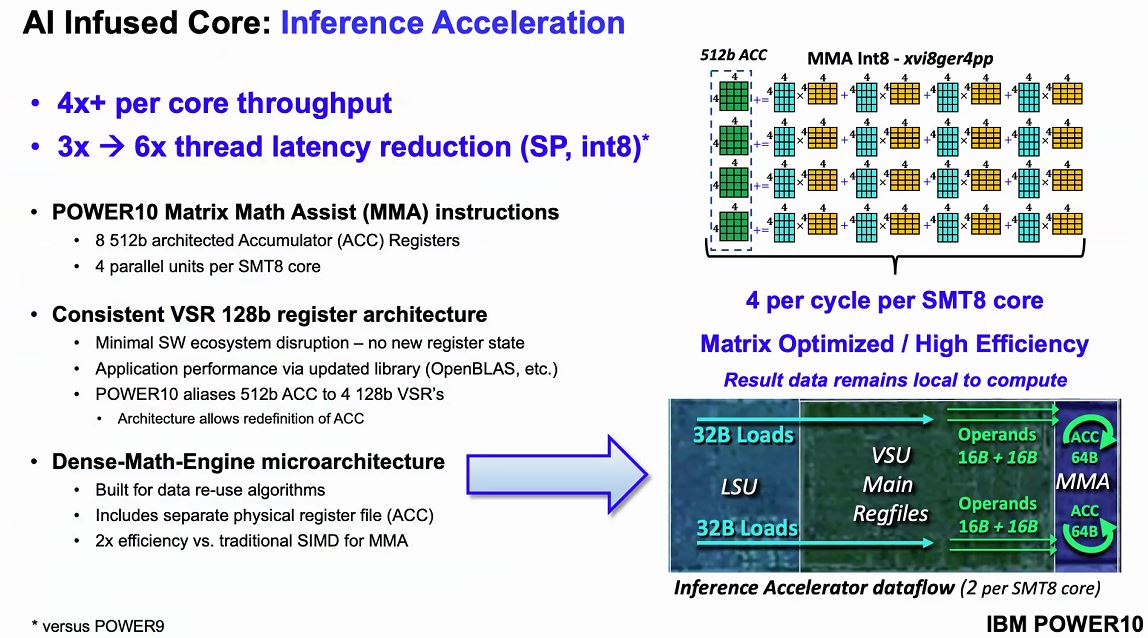
IBM says that these AI acceleration advancements yield a large performance gain.
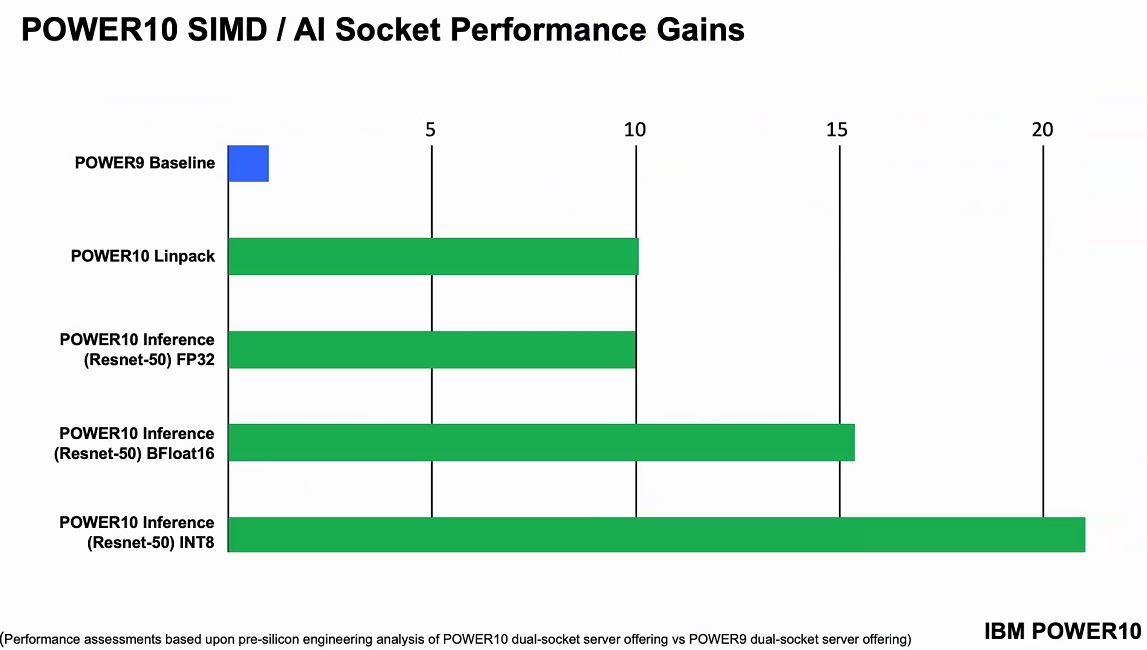
The core is interesting, however, once we get out of the core, we can see the big changes that we see the industry aligning to in the future (albeit perhaps different in implementation.)
IBM POWER10 Quest for the Holy Grail of Compute
The core advancements are cool, but where IBM POWER10 gets exciting is its external connectivity and scalability. Using its PowerAXON technology, systems can scale to 4x dual-chip module sockets or 16x single-chip sockets.
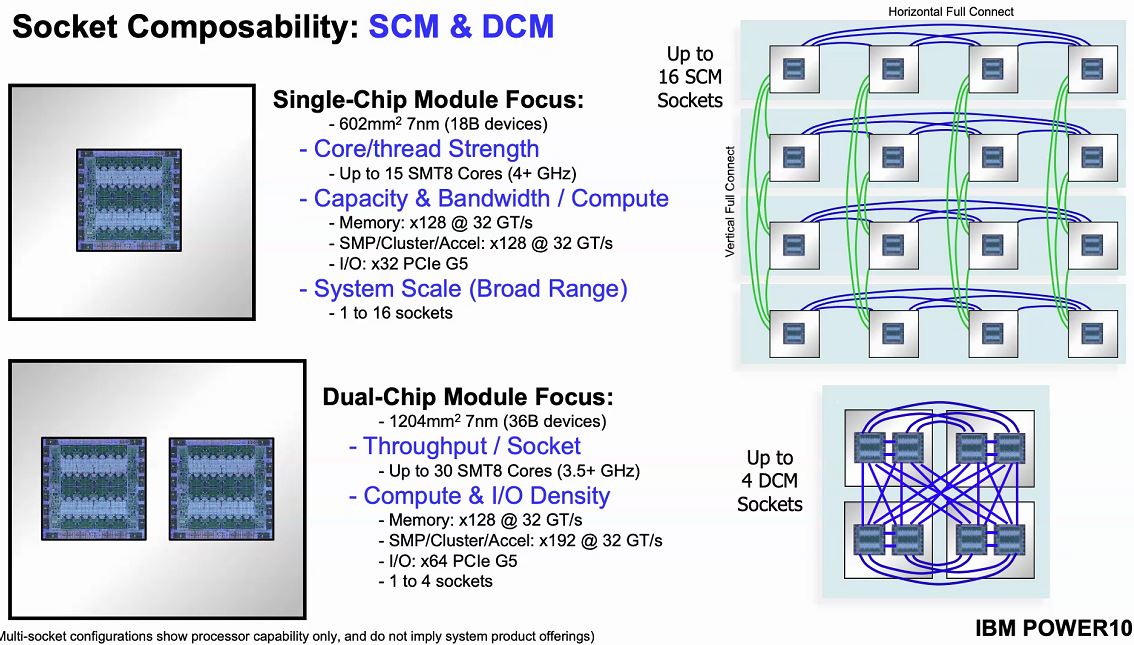
IBM has used PowerAXON for some time. This is a flexible interconnect that can be harnessed for socket-to-socket communication. It can also be re-purposed and used as it is in some large supercomputers and connect to accelerators.
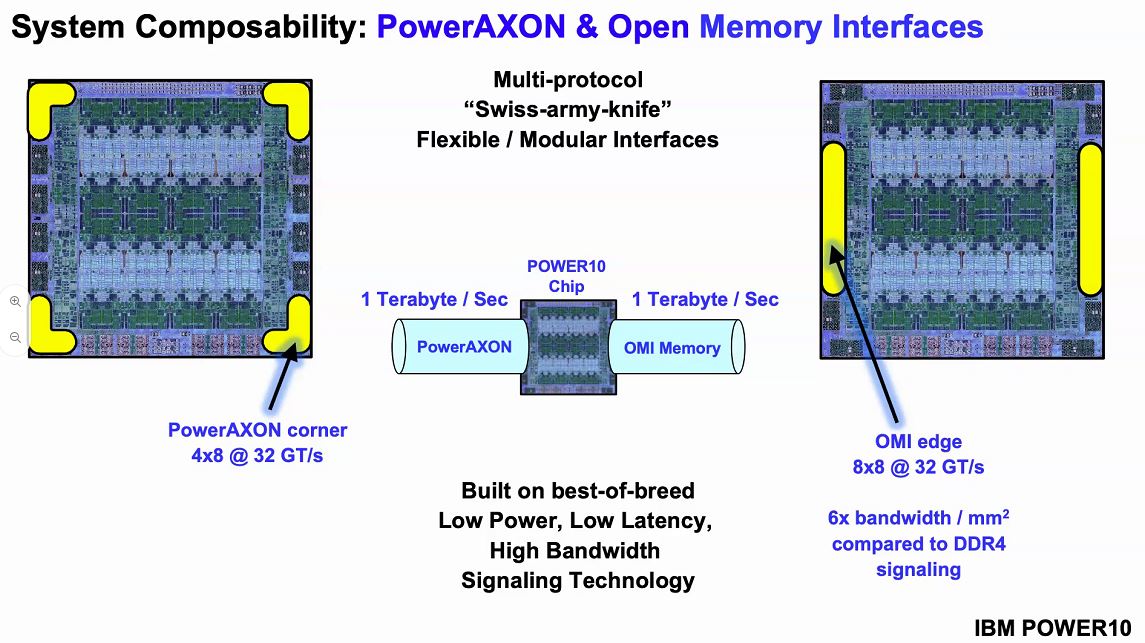
Perhaps what is more interesting, to us, is OMI memory. Last year, we covered the Microchip SMC 1000 For The Serial Attached Memory Future which will give some background here. Traditional DDR uses a lot of power, controllers occupy a large die area and it is not overly flexible. When all there was on the market was DDR memory, these tradeoffs made a lot of sense. With innovations such as storage-class memory and a DDR4/ DDR5 transition, IBM instead is using a high-speed serial interface and OMI.
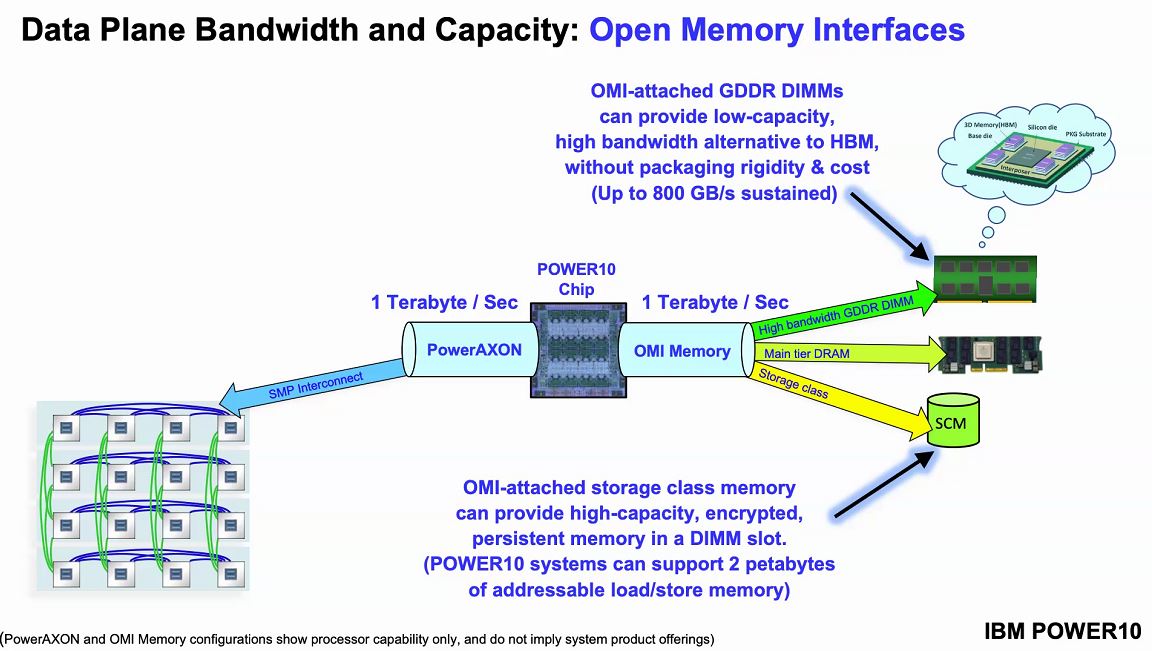
Setting up what Power10 is looking to accomplish, they will have 4TB per second with 410GB/s peak bandwidth with around 10ns of additional latency. Since the interface is via OMI, not DDR4, it means that one can, in theory, build OMI modules with DDR5, persistent memory, or even GDDR6 so long as the serial controller on the other side of the link supports it. From a chip perspective, the serial OMI memory allows IBM to effectively put a 16 channel memory controller on the chips without using enormous amounts of die space as would be needed for DDR controllers.
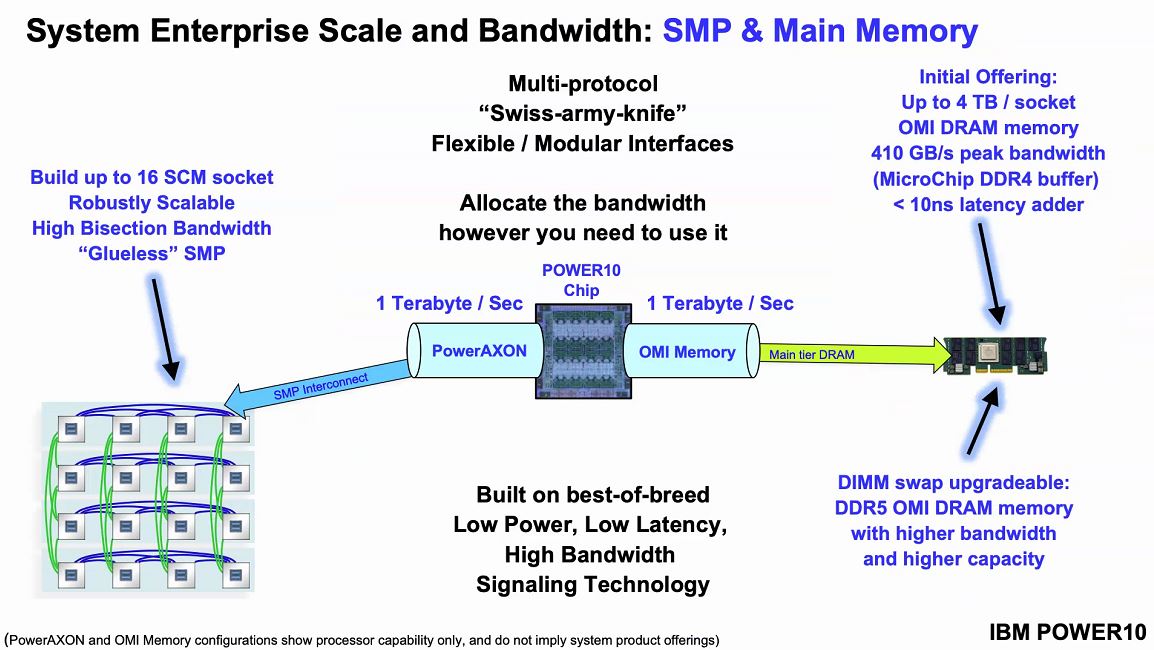
The other side of the equation is that the PowerAXON provides the SMP interconnect to up to 16x sockets. That means that, in theory, Power10 will be able to have 1TB/s of memory bandwidth and 1TB of SMP bandwidth.
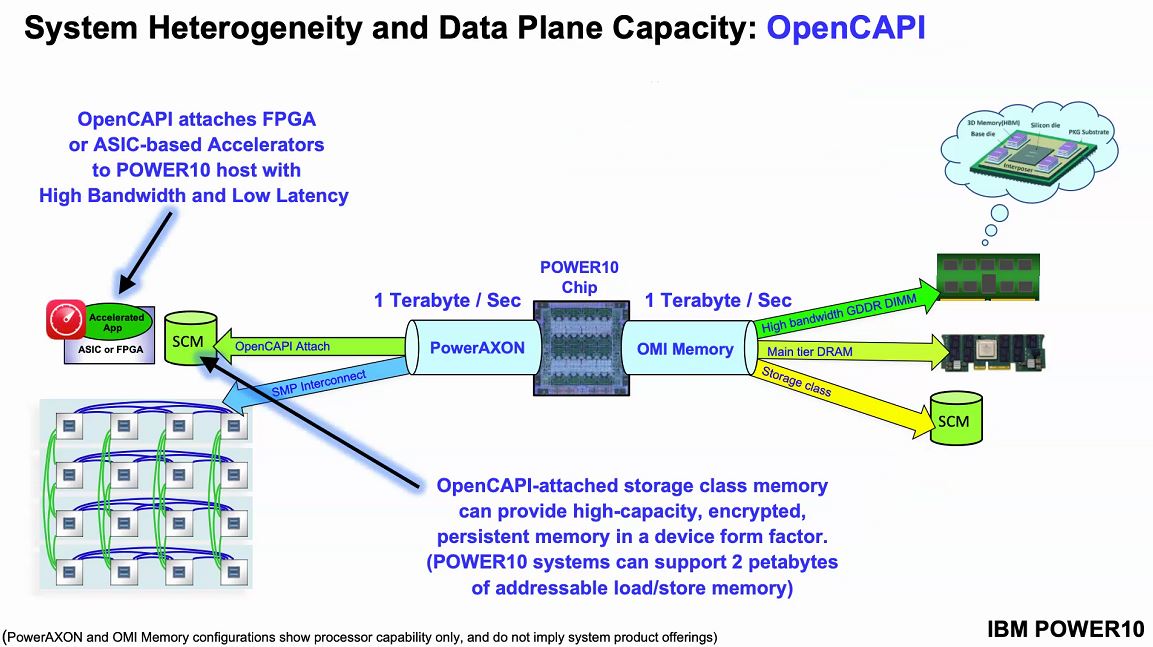
That PowerAXON technology also speaks OpenCAPI. OpenCAPI embodies the concept of moving to a load/ store model between the CPU and other accelerators in the system. Most of the industry is focused on CXL support starting with the PCIe Gen5 chips due out in 2021-2022. This is one area that IBM is supporting its legacy move in the space, but it will need CXL support to reach a larger ecosystem.
The PowerAXON memory clustering function allows for a system to map another system’s memory to be mapped into its own memory structure. The load/store requests can then be passed to the memory of a remote node. This is getting close to the “holy grail” of computing that Intel, HPE, and others have been working towards.
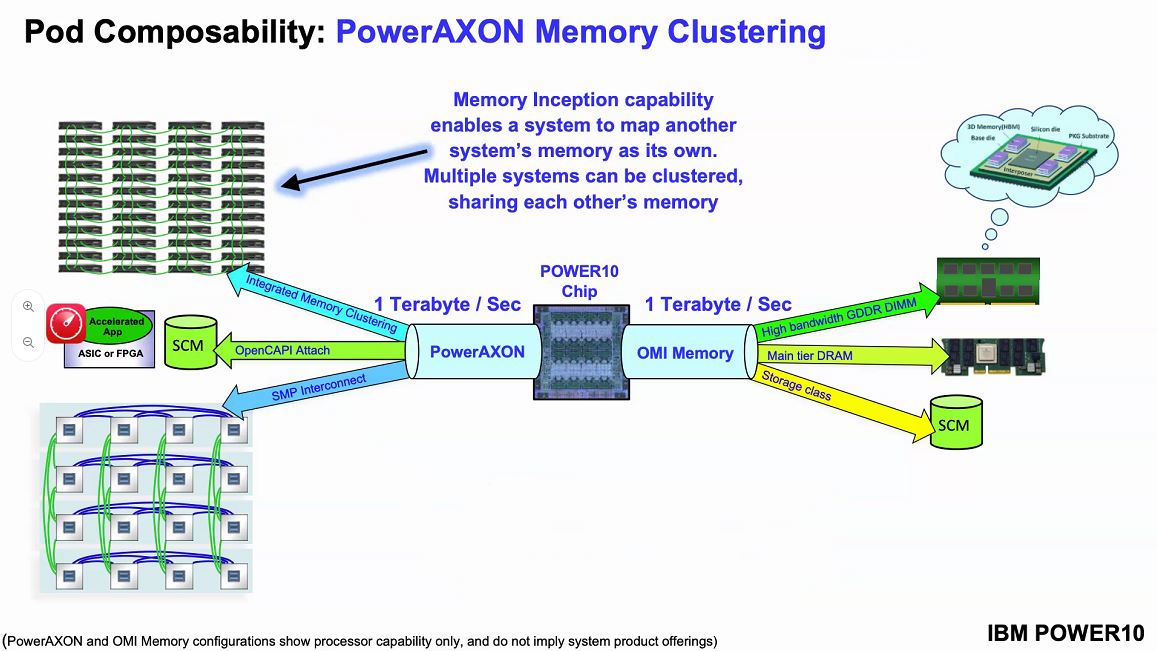
IBM has an example of memory clustering. Each system can be configured with a standard number of OMI modules. Then a workload running on a node can utilize additional memory in other nodes. There is a latency hit, but IBM says it is 50-100ns of additional latency using short reach cabling which makes it better than Infiniband and RDMA.
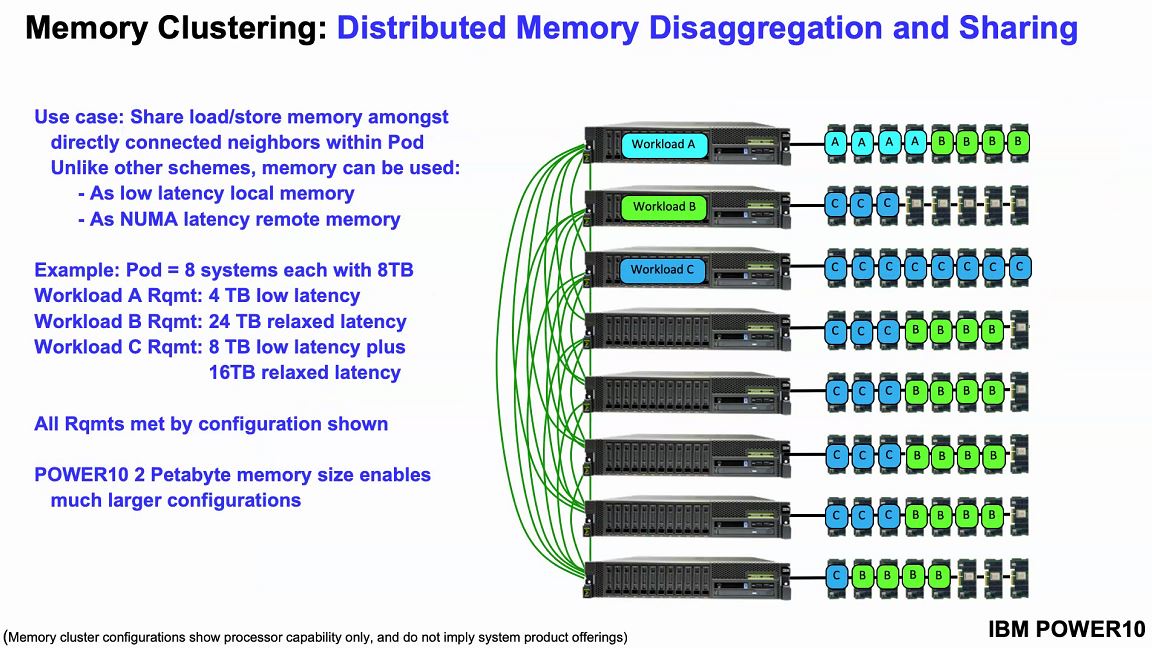
With OMI supporting more than just traditional DRAM (think storage-class memory in the future), one can build systems with up to 2PB of memory.
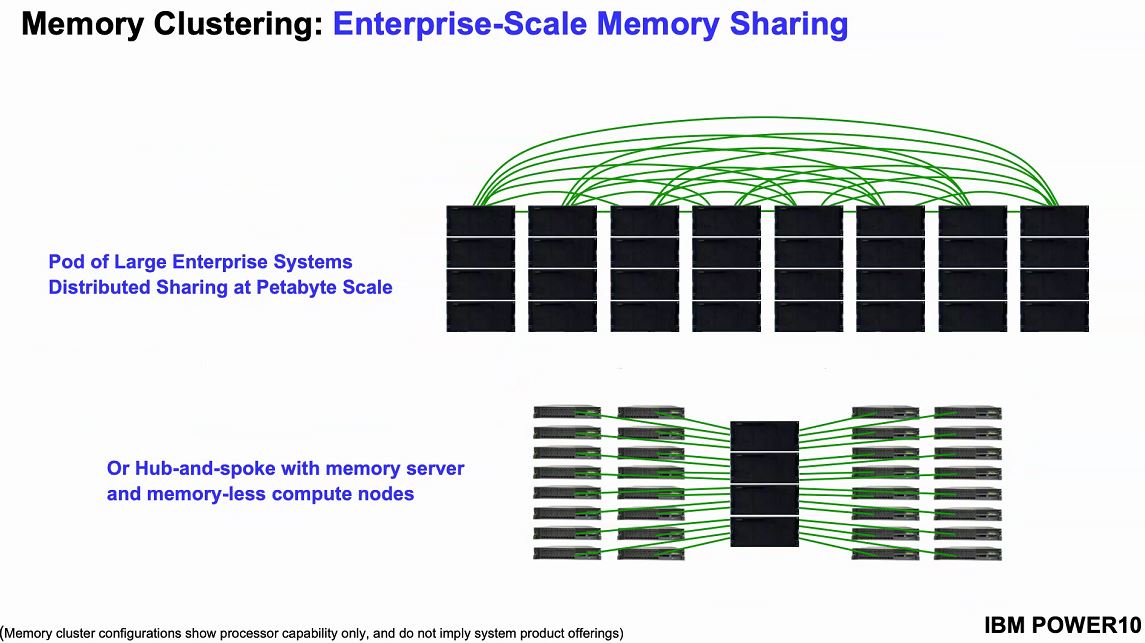
One of the biggest challenges in the data center is DRAM sprawl. DRAM is spread across multiple tiers of a system, and as a result, it is often idle. Since DRAM is relatively expensive, using less DRAM or DRAM more efficiently can save enormous sums in data center build-outs.
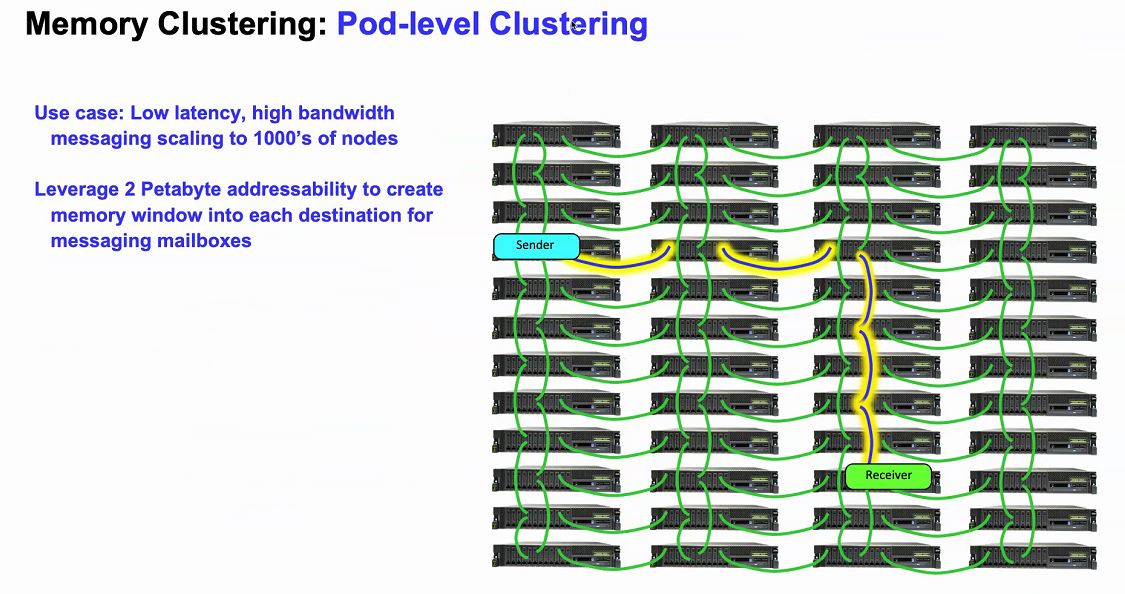
IBM sees the ability of POWER10 to cluster and share memory as attractive to both scale up to new applications where getting 1-2PB of memory in an SMP system was impossible or where it was (even more) cost-prohibitive.
Beyond these IBM-centric features, Power10 will also support PCIe Gen5. That allows the new chips to be on the same generation of PCIe as other chips that we expect to see in the 2021-2022 timeframe including Intel’s Sapphire Rapids Xeons and AMD’s Genoa generation of EPYC processors.
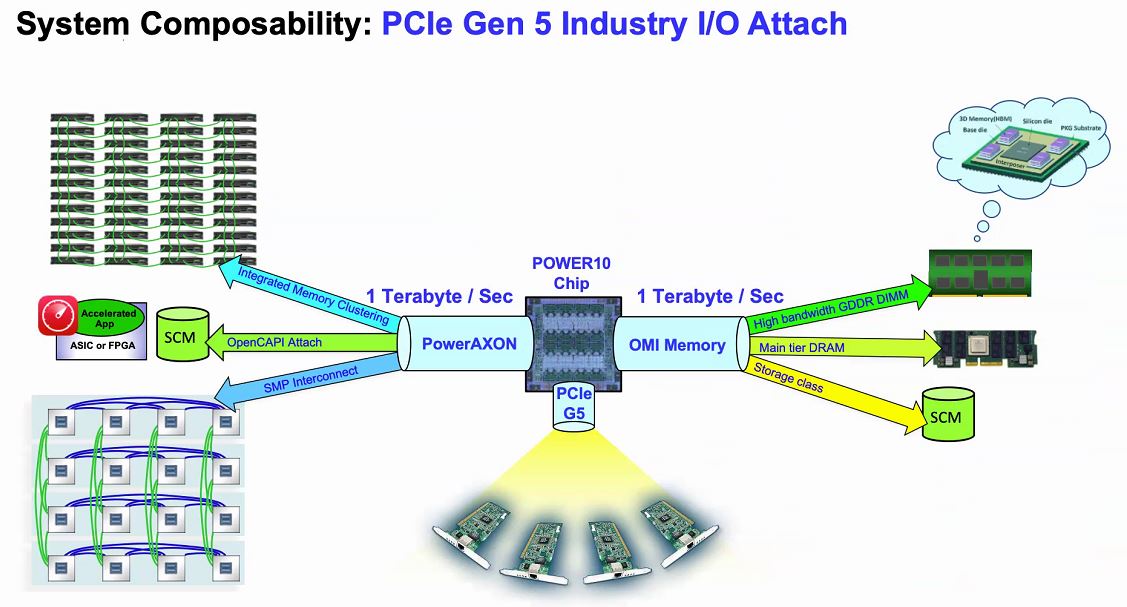
PCIe Gen5 is where we expect other chip vendors to support CXL, so we are awaiting that story. A fun fact is that in the Linux kernel, the OpenCAPI user library is “libocxl” so we will leave that there.
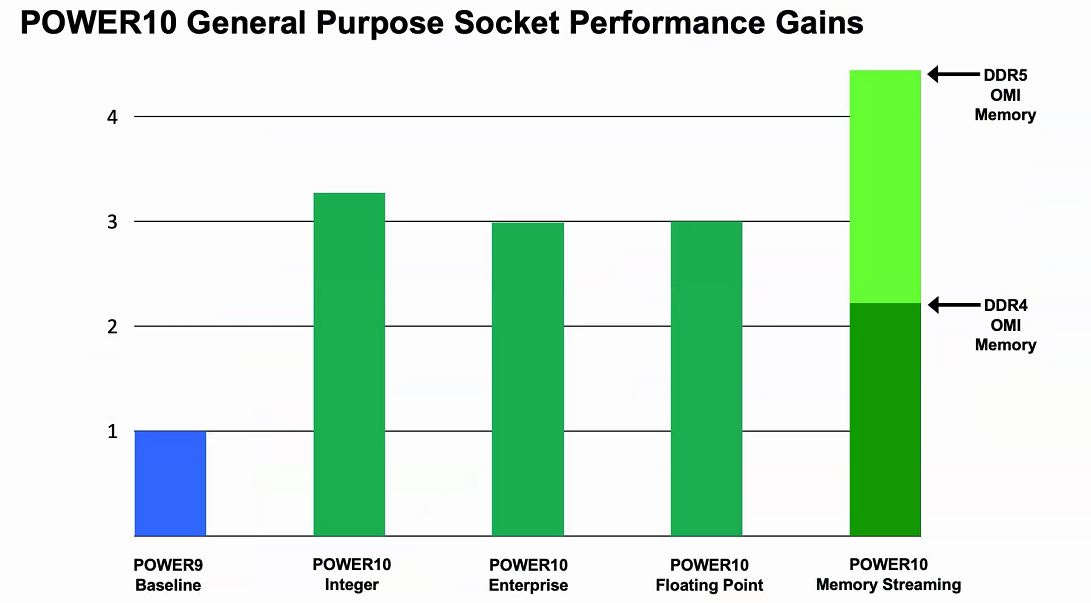
Overall, IBM sees Power10 as offering around a 3x speedup over Power9 which is an enormous generational leap, albeit POWER tends to see slower cycles and thus larger generational leaps.
Final Words
A surprisingly large number of STH readers run IBM Power-based servers at work. Those same readers are the target audience for Power10. For those who have no plans to transition to IBM’s newest architecture, these chips are equally as interesting. They give a glimpse into the future of computing by showing a processor’s features that is designed to launch closer to AMD EPYC Genoa and Intel Sapphire Rapids Xeons. IBM, given its semi-captive market, can be more aggressive pushing for new models such as OMI, but something similar will likely happen on the x86 side of the house.



{kind=link}
This is the best part about STH. Patrick’s taking slides on some niche processor and talks about the entire industry.
Your video was good too.
Thanks for the IBM coverage, this and the z15.
> For those who have no plans to transition to IBM’s newest architecture, these chips are equally as interesting.
I fall in that category and indeed find POWER and IBM z fascinating. STH’s coverage of these topics is a real treat. I hope that just because a processor or architecture is exotic, that doesn’t impact whether it will be covered or not. Even if you’re never going to review the silicon, great coverage like this is still appreciated (same for other exotics like Cerebras, NUVIA(?), Xe-HPC, fancy HPE stuff, etc).
We still run a couple of applications on Power boxes but only under protest. We used to be a purely IBM shop until the late 90’s when Window’s value proposition was just too good for our software vendors to ignore and we started deploying it to get access to those apps. Power was still where we ran “the important stuff”. Then we got one of IBM’s signature hostile audits about a decade ago where we were told essentially “it doesn’t matter if your reseller thought you were properly licensed, you aren’t and you have 30 days to cough up about a million bucks or we’ll see you in court.” Which brings us to today where we have just those two apps left and one will hopefully be replaced by the end of the year.
Still their CPUs are pretty cool. I’m simultaneously eager to hear about what Big Blue is developing and hopeful I’ll never have to touch it.
Comments are closed.