Cavium ThunderX2 v. Intel Xeon and AMD EPYC Topology Impact
We wanted to show why the Cavium ThunderX2 looks a bit more like an Intel Xeon Scalable system in dual socket mode than AMD EPYC 7000 series, and why that is important.

You can see that the Cavium ThunderX2 chip occupies a large footprint more akin to AMD EPYC and Intel Xeon Scalable than previous generation Intel Xeon E5-2600 CPUs. That extra area allows for a larger die but also the ability to connect 8 channel DDR4 as well as multiple PCIe options.
Intel Xeon Topology
We are going to start with the previous generation Intel Xeon E5-2699 V4 topology to show what organizations are accustomed to. It is no secret that the Intel Xeon E5-2600 V3/ V4 architectures held well over 90% market share. That means that companies upgrading to current-generation are accustomed to this topology. More importantly, software is written and systems are designed using this as the base assumption for dual socket server topology.

Intel Xeon Scalable example as that is very similar. Here is what an Intel Xeon Gold series topology looks like. For our readers, you will notice we are using a “F” series part just to show what the platform looks like with full Omni-Path enabled SKUs:
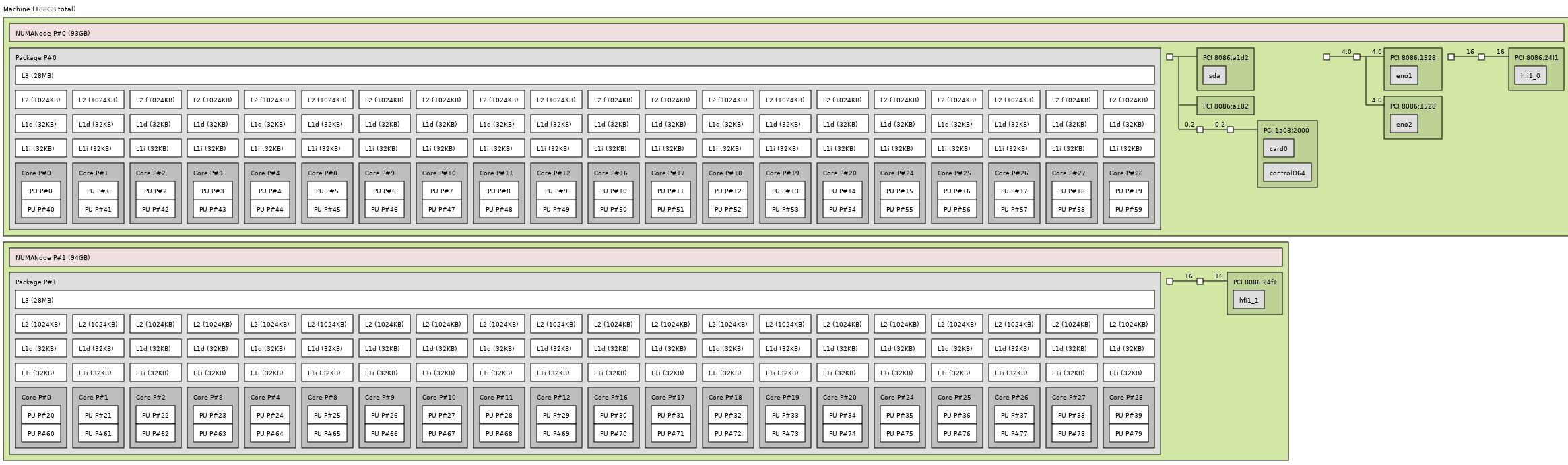
Between the Intel Xeon E5-2600 V4 (or the E5-2600 V1-4) and the Intel Xeon Scalable platforms, one can see that they are largely identical. There are two NUMA nodes and all of the memory is attached to one of the two NUMA nodes.
AMD EPYC Topology
When the AMD EPYC 7000 series launched, we noted that it was more complex. A dual socket AMD EPYC 7000 series platform has 8 NUMA nodes instead of 2 commonly found on Intel platforms.

There are several implications of this. We will get to some of the performance aspects soon, but there are two impacts that need to be mentioned. First, PCIe devices can be attached to all eight NUMA nodes. Second, memory can be attached to all eight NUMA nodes. Essentially this means that you have to do an off-die fabric hop to access PCIe devices or memory. If you running an application that is not NUMA aware, that also means that only 12.5% of the PCIe devices or RAM in a fully populated system are connected to the local NUMA node. With Intel, that figure is 50%.
Here is AMD’s official slide on the topic:
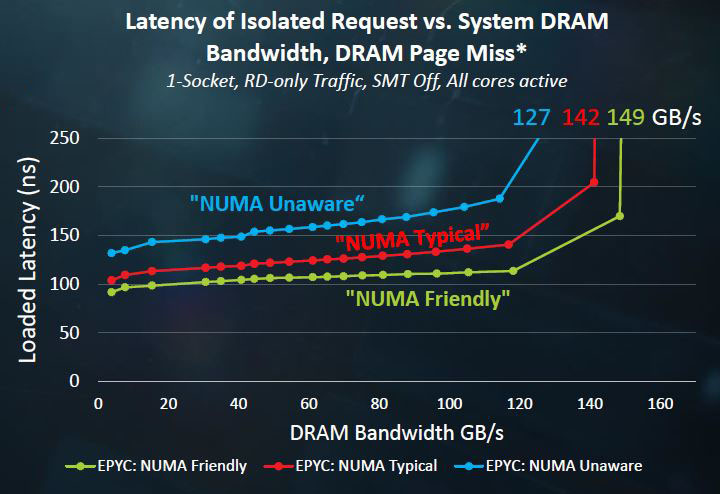
This is in a single socket configuration with SMT turned off (so one thread per core.) In a dual socket configuration, “Numa Unaware” results can be significantly worse. We looked into this in our piece AMD EPYC Infinity Fabric Latency DDR4 2400 v 2666: A Snapshot.
Cavium ThunderX2 Topology
Moving to the Cavium ThunderX2, the topology shows two NUMA nodes with PCIe and RAM distributed more like Intel Xeon CPUs.
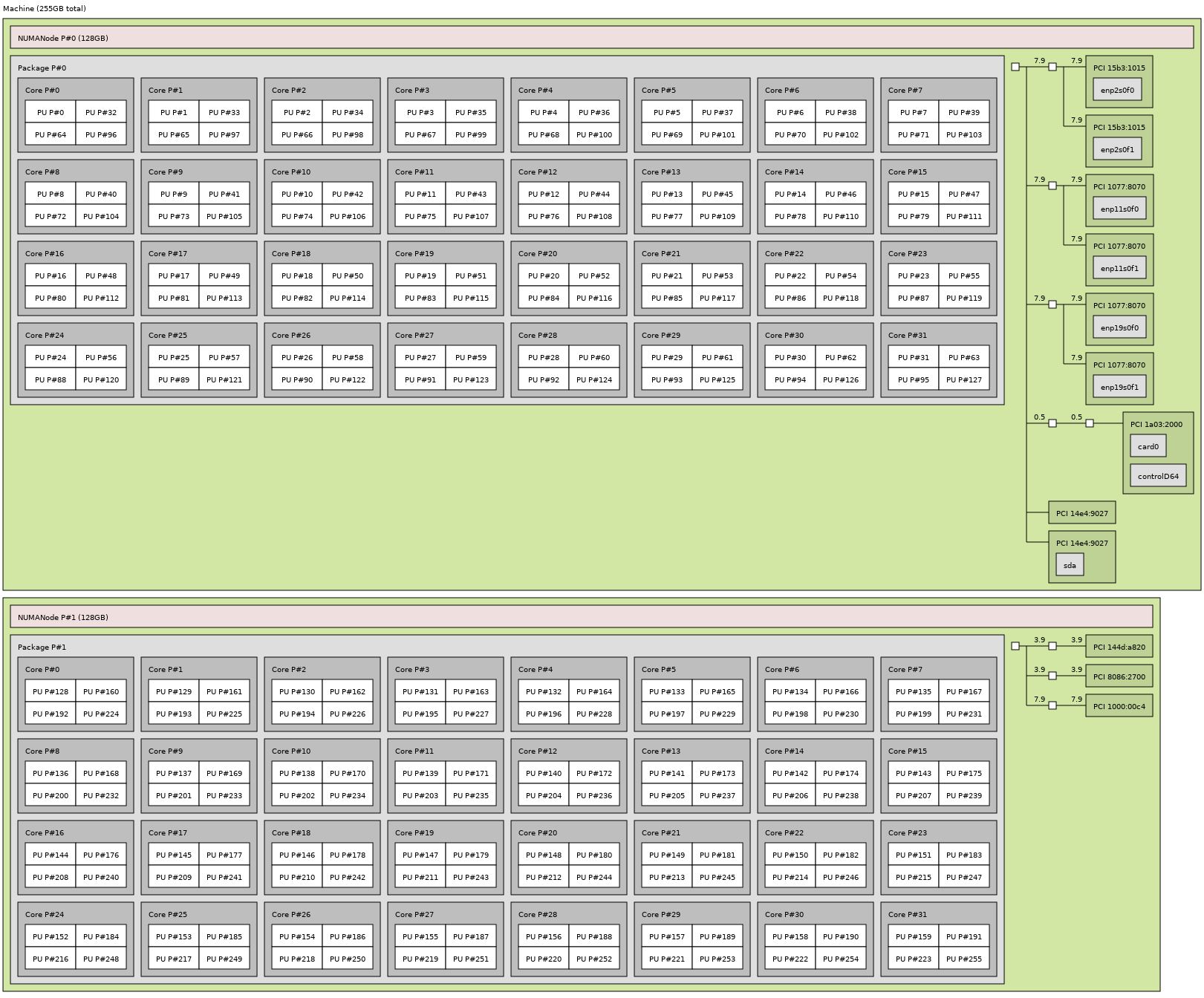
This is a major difference since it means that unlike AMD EPYC you have a hardware topology that looks more like Intel Xeon. For ISVs that are looking to support an Intel alternative, this is an attractive option if the alternative is many NUMA hops.
Just to bring up to points of Arm competition here, the Ampere eMAG and Qualcomm Centriq 2400 are single CPU solutions designed for lower performance and smaller systems. The market favors dual socket systems, despite AMD EPYC single socket being extraordinarily attractive. ThunderX2 competes in two sockets and has 2 NUMA nodes like the incumbent where Ampere and Qualcomm cannot match.



{kind=link}
I’m through page 3. I’m loving the review so far but I need to run to a meeting.
Looks like a winner. Are you guys doing more with TX2?
It’s crazy Cavium is doing what Qualcomm can’t. All that money only to #failhardcentriq
Cool chart with the 24 28 30 and 32 core models
Cavium needs to fix their dev station pricing. $10k+ for two $1800 cpus in a system is too much. Their price performance is undermined by their system pricing
Read the whole thing, very impressed with the TX2 performance and pricing, think i’m going to try one out. But was a bit bummed out when i found out on page 8, the most important thing, power usage, wasn’t properly covered and compared to the Intel and AMD systems :(
Welcome competition, always good to see that there is pressure on the market leader.
Microsoft is also working on an ARM version for windows, so this can go the right way…
I’m very confused by some of what you wrote and the exact testing setups of these platforms is extremely unclear. To cite just one example of Linpack test where you state:
“Our standard is to run with SMT on since that is what most of the non-HPC environments look like. This is a case where having 256 threads simply is too much. We also ran the test with 32 threads per CPU, or SMT off which yielded a solid improvement. ”
On a 4-way SMT system you get 256 threads by operating 64 cores. You claim that the CPU only has at most 32 cores and in the same statement you re-tested at 32 threads. So…. what exactly did you test? A 32 core CPU that *cannot* have 256 threads? A two-socket 64-core system that can have 256 SMT threads but that was then dropped to a single-socket configuration with only a single 32 core processor?
Please put in a clear and unambiguous table that provides the *real* hardware configurations of all the test systems.
That means:
1. How many sockets were in-use. Were *ALL* the systems dual socket? All single socket? A mixture? I can’t tell based on the article!
2. Full memory configuration. Yes I know about the channel differences, but what are the details.
3. That’s just a start. The article jumps from vague slides about general architecture to out-of-context benchmark results too quickly.
Competition in the server industry great!
Don – 32 threads per cpu means 64 threads total right? 2x 32 isn’t that hard.
I don’t think this convinced me to buy them. But I’ll at least be watching arm servers now. We run a big VMware cluster so I’d have a hard time convincing my team to buy these since we can’t redeploy in a pinch to our other apps.
We’ll be discussing TX 2 at our next staff meeting. Where can we get system pricing to compare to Intel and AMD?
Can you do more about using this as Ceph or ZFS or something more useful? Can you HCI with this?
Love the write-up. You guys have grown so much and it shows in how much you’re covering on this which is still a niche architecture in the market.
Nice write-up, with plenty of details, on the newly launched. Congrats to Cavium.
Cavium Arm server processor launch, suddenly Microsoft shows up and reiterates it still wants >50% of data center capacity to be Arm powered. And it’s loving Cavium’s Thunder X2 Arm64 system. Together designed two-socket Arm servers…
Looks like cavium is taking on Intel with armv8 workstation. Same processor as used by cray. Interesting. Comparing to Xeon ThunderX2 is good in all aspects like performance, band width, No.of cores, sockets, power usage etc.
Competition in silicon is good for the market.
CaviumInc steps up with amazing 2.2GHz 48-core ThunderX2 part, along with @Cray and @HPE Apollo design wins, and @Microsoft and @Oracle SW support. Early days for #ARM server, but compelling story being told.
ThundwrX2 Arm-based chips are gaining more firepower for the cloud.
The Qualcomm Centriq 2400 motherboard had 12 DDR4 DIMM slots and a single >> 48 core CPU.
The company also showed off a dual socket Cavium ThunderX 2. That system had over >> 100 cores and can handle gobs of memory
“With list prices for volume SKUs (32 core 2.2GHz and below) ranging from $1795 to $800, the ThunderX2 family offers 2-4X better performance per dollar compared to Qualcomm Centriq 2400 and Xeon…”
Cavium continues to make inroads with the ThunderX2 @Arm-compatible platform..
Nice Coverage. 40 different versions of the chip that are optimized for a variety of workloads, including compute, storage and networking. They range from 16-core, 1.6GHz SoCs to 32-core, 2.5GHz chips ranging in price from $800 to $1,795. Cavium officials said the chips compete favorably with Intel’s “Skylake” Xeon processors and offer up to three times the single-threaded performance of Cavium’s earlier ThunderX offerings.
The ThunderX2 SoCs provide eight DDR4 memory controllers and 16 DIMMS per socket and up to 4TB of memory in a dual-socket configuration. There also are 56 lanes of integrated PCIe Gen3 interfaces, 14 integrated PCIe controllers and integrated SATAv3, GPIOs and USB interfaces.
Kudos to Cavium…
Those power numbers look horrendous. A comparable intel system would be less than half that draw. In fact, 800W is the realm 2P IBM POWER operates in. I get that it’s unbinned silicon and not latest firmware but I can’t see all that accounting for ~50-75W tops. My guess is Broadcom didn’t finish the job before it was sold to Cavium, and if Cavium had to launch it now lest they come up against the next x86 server designs (likely starting to sample late 2018).
I guess when Patrick gets binned silicon with production firmware, he’ll also have to redo the performance numbers because it’s quite possible that the perf numbers will likely take some hit. 800W! At least it puts paid to the nonsense about ARM ISA being inherently power efficient. Power efficiency is all about implementation.
The performance looks quite good, but yeah the 800W are a show stopper…
The xeons and epyc processors consume way less than that.
I doubt they can get to the power consumption of the xeons and epyc without lowering quite a lot the max frequency and voltages accordingly. If they can do it, then that’s great. But I have some doubts.
For the STREAMS benchmark (“Cavium ThunderX2 Stream Triad Gcc7”) I assume the Intel compiler is leveraging the FMA instructions, giving them the boost in performance.
Where is performance for dolar graph? Without it is this just lost of useless results..
RuThaN – how would you propose performance per dollar? All SKUs used in the performance parts have list prices that are easy to get. Discounts, of course, are a reality in enterprise gear. The ThunderX2 is sub $1800 which is by fart the least expensive.
Beyond the chips, what system/ configuration are you using them in? How do you factor in the additional memory capacity of ThunderX2 versus Skylake-SP, will that mean fewer systems deployed?
What cost for power/ rack/ networking should we use for the TCO analysis?
I do not think that performance/ dollar at the CPU level is a metric those outside of the consumer space look at too heavily versus at least at the system cost. For example, this is a fairly basic TCO model we do: https://www.servethehome.com/deeplearning11-10x-nvidia-gtx-1080-ti-single-root-deep-learning-server-part-1/
Failure to publish measured power during *every* benchmark run is evasive. This is critical data, for the spread of workloads, and allows calculating energy efficiency.
Please be honest and report the data. Caveats are fine but failure to report is not fine.
Richard Altmaier – thank you for sharing your opinion. There are two components for sure, performance and power consumption. Both are certainly important, but for this review, performance seemed ready, power did not due to a variety of noted factors.
As mentioned, the test system we have is fairly far from what we would consider comparable to the AMD/ Intel platforms that have been in our labs for more than a year. We do enough of these that it is fairly to see that power is higher than it should be. We do not want to publish numbers we are not confident in, lest they get used by competitors.
We also mentioned that there will be a follow-up piece to this. The other option was to publish zero power numbers. Despite your opinion, performance alone is a compelling story. Unlike the x86 side, the ARM side has never had a platform that can hit this level of performance which makes the raw performance numbers quite important themselves.
BTW – There was a well-known Intel executive also named Richard Altmaier.
Would love to see the commands used to generate these results, especially on STREAM on the 8180. I’ve not seen more than ~92GB/s with 768GB installed across all 6 channels with OpenMP parallelization across all 56 threads…
Comments are closed.