
Sometimes you just want to go fast. The Broadcom BCM57508 NetXtreme-E is a 200GbE OCP NIC 3.0 adapter. We were told this was a 100GbE adapter but later found that it was actually a 200GbE version so we thought it would be worth showing our readers.
Broadcom BCM57508 NetXtreme-E 200GbE OCP NIC 3.0 Adapter is FAST
Here is the Broadcom BCM57508 NetXtreme-E NIC. One of the biggest trends in servers is the use of the OCP NIC 3.0 Form Factor in servers. Years ago, we had a different mezzanine form factor for almost every server vendor. Now, we have the OCP NIC 3.0 form factor that is being used by not just hyper-scalers, but traditional server vendors as well.

On the rear of the card, we have two QSFP56 ports. These allow for higher-speed communication than the 100GbE QSFP28 ports we have seen.

The Broadcom BCM57508 is one of the company’s PCIe Gen4 x16 cards. For dual 200GbE connections, one would need PCIe Gen5 x16 to have the host bandwidth to drive two 200Gbps ports.

Here is a quick look at the heatsink. These cards and the PCIe versions see a typical power consumption of under 20W. One of the biggest challenges for DPUs in these form factors is the power consumption and cooling OCP NIC 3.0 cards that are higher TDP.

Here is a side view of the card.

Here is the other side.

With that, let us take a look at what the NIC looks like installed.
Broadcom BCM57508 NetXtreme-E 200GbE OCP NIC 3.0 In Linux
Although we were told when we did the Supermicro SYS-221H-TNR review that this was a 100GbE adapter, this is what we saw when it was installed in Ubuntu:
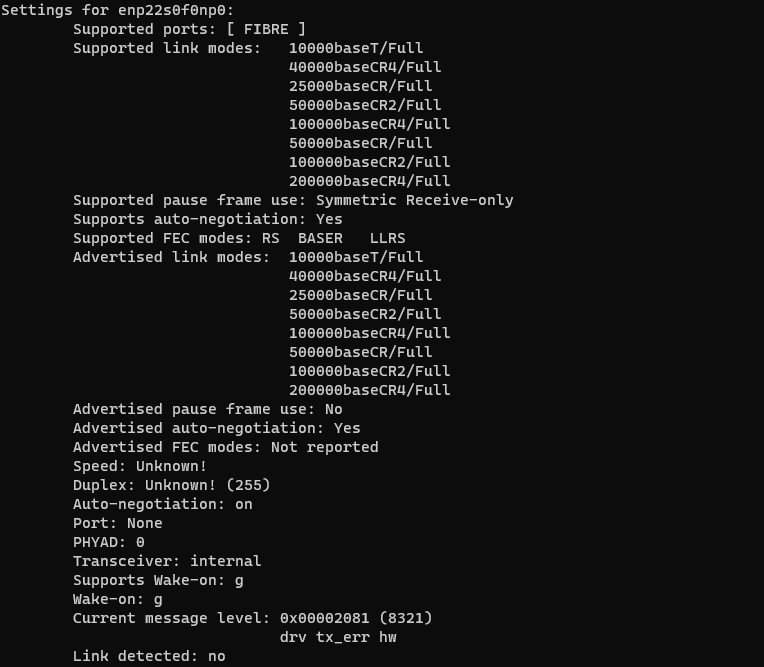
Checking ethtool, we saw 200000baseCR4/Full or 200Gbps full duplex.
We have a 200GbE capable adapter that we could test.
Broadcom BCM57508 NetXtreme-E 200GbE Performance
One of the challenges is that while we have a ton of 100GbE gear, and we will have a lot of 400GbE gear, on the 200GbE side we have less infrastructure. We had the QSFP28-DD switch in the Dell EMC S5248F-ON but that was not QSFP56.
We ended up getting optics on each end and were able to eventually tie the switch to NIC, but we had to use multiple 100GbE test nodes for iperf3 sessions. With the 400GbE coverage over the next few weeks, we are going to have more on how complex some of the cabling and connectors get. We spent something like $1000 on finding “inexpensive” DACs to connect four nodes to a switch with that project
Still, here is what we saw trying to do a 1x 200GbE link:
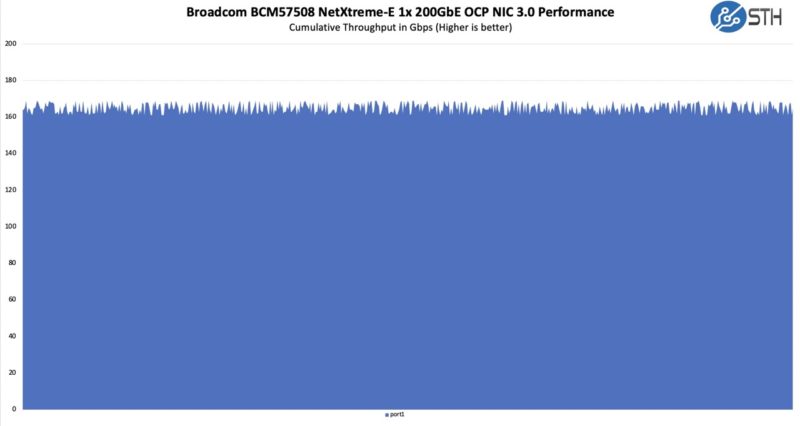
We certainly got well over 100GbE speeds but we were also notably off of 200Gbps. At these speeds, we need to do a lot more NIC tuning to get that level of performance. For our 400GbE results soon, we had to do a lot more than we are doing here so please read this as we verified that it is linked and transferring above 100GbE speeds, but it is not optimized.
Here is what we got trying two 100GbE clients through the switch to the NIC.
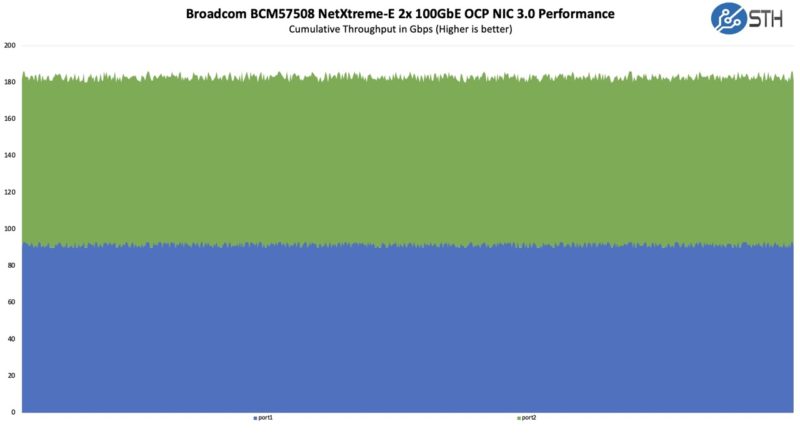
That is probably closer to what we would have expected.
A quick note here is that we need to run something like DPDK or similar which was not set up. CPU utilization at 200Gbps speeds is a challenge.
On power, a PCIe version of this card we would expect to be rated at 16-20W typical with DACs, and more with optics.
Final Words
We tend to use mostly NVIDIA (Mellanox) ConnectX-5/ ConnectX-6 cards (and BlueField-2 DPUs) in the lab, and also the Intel E800 series. Still, Broadcom has a solid NIC market share so we should be covering them more than we do.

This is either more of a dual 100GbE adapter or a single 200GbE adapter. The PCIe Gen4 x16 limits us to not getting dual 200GbE speeds to a host through the NIC.
These adapters support RDMA and other features, but since there are so many features that our readers look for, we are going to suggest that folks look for those if they are interested in the cards.
Hopefully, folks enjoy seeing these kinds of cards as we come across them.



{kind=link}
According to the Wikipedia page for PCI Express, PCIe 4.0 x16 has a throughput of 315 Gbps in each direction. This would seem more than enough for 200 Gbps full duplex, wouldn’t it? I’m no expert so please correct me if I’m wrong.
Were the tests done with jumbo packets? In my own experience these do lower the CPU load, but in my case that’s because it means fewer packets to pass through iptables etc.
It’s interesting this card can do 200 Gbps at only 20 watts. I have a Connect-X 6 PCIe 100 Gbps card that requires 75 watts, which seems rather excessive!
Chelsio dual sfp+ t520 nics used 12-15W. Now 20w for dual 200W. That’s a good jump even if the chelsios did run warm. Though at this point, how is sfp+ still the most expensive speed? Guess that’s what you get when all businesses at the Enterprise Level just blank checked it to anything that was a tech related bill for almost 2 decades.
@Malvineous
The actual power consumption of CX6 VPI is about 20W without the optical transceiver.
driver reports only to check whether the slot can provide 75W power supply to ensure nothing goes wrong.
@Malvineous, PCIe 4 is good for 31.5 GBytes/s. Multiple by 8 to get 252 Gbps. That’s clearly not enough for 2x200Gbps. Furthermore, PCIe has higher packet header overhead than Ethernet. With Max Payload Size (MPS) of 128 bytes which is the mandated minimum supported by every chain of the PCIe topolology, the overhead is ~20%. It’s common to have support for 256 bytes MPS which cuts it down to ~10%. Obviously, you’d be better off with 512 bytes (higher values are much more uncommon) but it’s still ~5%.
@Rohit Kumiar, could you please also provide the output from lspci -vv so we can get more details on what PCIe features this chip supports?
BTW, by default the Linux kernel will configure every PCIe device for 128 byte MPS. You need to use the kernel boot option pci=pcie_bus_perf to let the kernel configure devices for the max supported MPS.
“With the 400GbE coverage over the next few weeks, we are going to have more on how complex some of the cabling and connectors get. We spent something like $1000 on finding
“inexpensive” DACs to connect four nodes to a switch with that project”
Ok this has QSFP56 connectors and your 400 Gb switch probably has QSFP-DD. You should be able to use a QSFP56 to QSFP56 DAC to connect those for 200GbE (only using four lanes, instead of the 8 in -DD switch).
Four of those cables should be under $500 from cheap sources. Did you use both connectors per card (making 8 DACs) or am I missing something?
BTW Good to see fast Broadcom cards. Hard to get them through retail.
Very exciting OCP 3.0 card, thanks for sharing. For way too long, many servers vendors have been stuck at 2-4x 25G ports on NDC, OCP 2.0 and OCP 3.0 cards.
When connecting Mellanox ConnectX6 Dx cards to a Dell Z9432 switch, I used simple and inexpensive 400G QSFP-DD to 4x100G QSFP56 breakout cables from FS.
Hi!
I’ve reached this page because I have this card in a pair of servers with Ubuntu 20.04 but I’m unable to make them work.
Regarrdless what I do I always get the state as DOWN and I’m not sure the reason.
* ifconfig up
* ip link set up
* Upgrade the driver to latest version and check again
* set IP address and check
I’m starting to fair that maybe the connection between the cards is not working.
Did you did something special to make them work?
For Linux, the Broadcom bnx2 driver has historically been a perfromance suck and CPU hit compared to, say, Intel. Any comments on whether that was improved? Currently I am primarily Mellanox, mostly based on that previous experience with Broadcom.
It’s very said we don’t see CPU load for this performance. Currently, we have this card on server with two INTEL(R) XEON(R) SILVER 4516Y+ processors and we tried to forward packets: use this server as a router. We’ve failed to process even 80Gbit of traffic due to high CPU load, so I guess this driver still has CPU problems.
Comments are closed.