AMD EPYC Genoa Zen 4 Performance
There is something that we noticed in this generation that we had to address. When we design benchmark suites, and many workloads you see online ideally try to run one workload over an entire CPU. If all goes well, this would be the result, a 100% x 384 thread system:
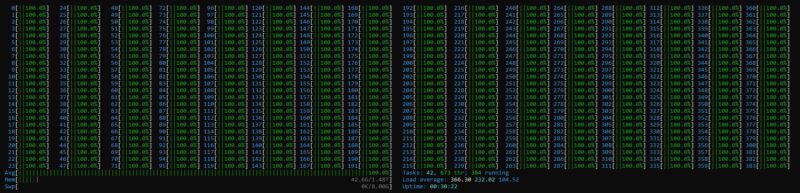
In real-world workloads, if you run a single workload on a large chip like this, sometimes there are single-threaded parts of a workload. That leads to some really poor performance on big chips because those workloads look something like this with 1 of 384 threads running at 100%.
The above is a bigger issue today than it was in the past. On a dual 4-core / 8-thread server, a single thread is over 6% of the total thread count. On a dual 96-core/192-thread server, a single thread is just over 0.26%.
Depending on the workload, these periods where a workload is held up by a single thread became a substantial issue. As a result, we had to do a lot more profiling than we normally do.
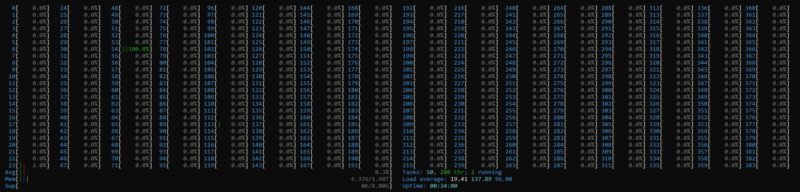
The other fun case we ran into was the below view:
We found a number of workloads that have scaled for years but were limited to 256 threads. That means 1/3rd of the threads are not being used.
That brings up the philosophical question: “Are these CPUs, especially 96-core CPUs designed to run single workloads?” John and I spoke about this for some time. The world of benchmarking has almost always been running a single workload across the entire CPU. That is rendering workloads, HPC workloads, and so forth that will use entire chips. Still, most of the chips are really being used for containerized or virtualized workloads. The cloud segment is a prime example of this. The key point is that going forward, we are going to be increasingly using bare metal containers and then virtualized workloads to scale. This is similar to what VMware VMmark does, but KVM is the bigger hypervisor with its cloud adoption and VMware puts restrictions on VMmark. Still, looking at both will be important in the future since there is an argument that hitting a single-threaded part of a workload on a 384-thread system is terrible for overall performance.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
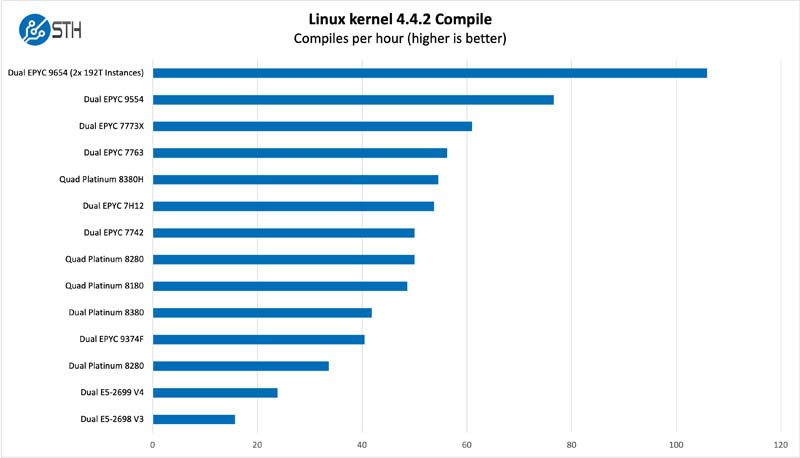
This is one of the workloads where we had to look at the scaling performance. In the future, we are going to express more benchmarks in terms of runs/ time because that metric will eventually allow for comparisons where the system is running parallel runs as well.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. Here are the 8K results:
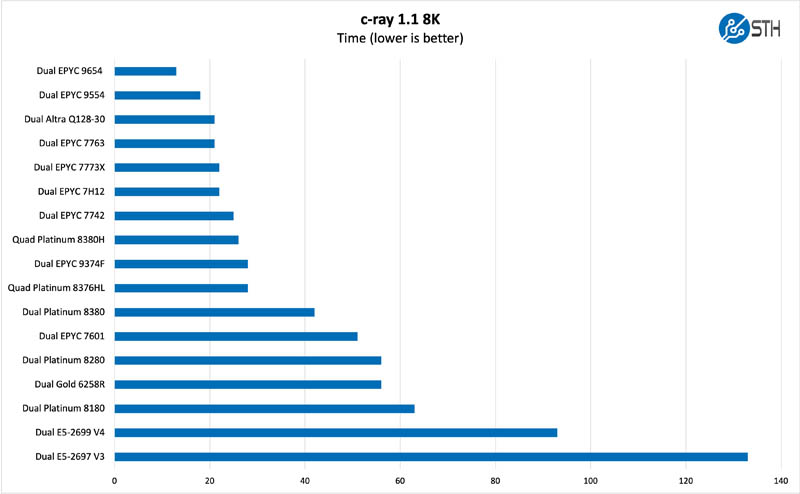
This looks perhaps much closer than it is. AMD is far ahead because this is not being expressed in runs per hour. A fun note, we started collecting data on this rendering-style benchmark back when 8K renders would stress four-socket servers for many minutes. Now, the new generation completes the run in 13 seconds.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench. We are using our legacy runs here to show scaling even without hitting accelerators.
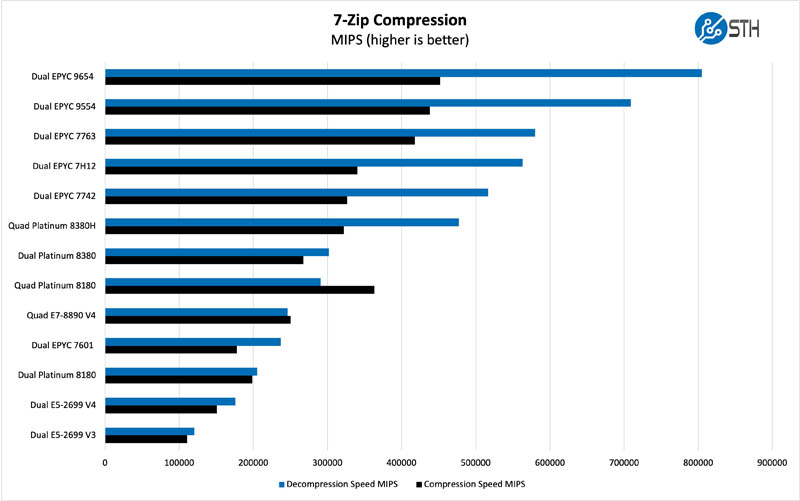
Again, this is a stellar performance, albeit we see scaling challenges at higher core counts on the compression side. Compression, however, is a function that will be ubiquitous in the future but will also warrant offloading to accelerators.
Chess Benchmarking
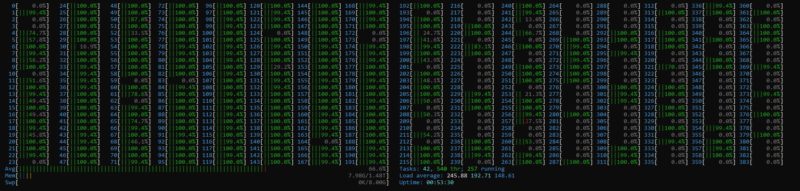
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
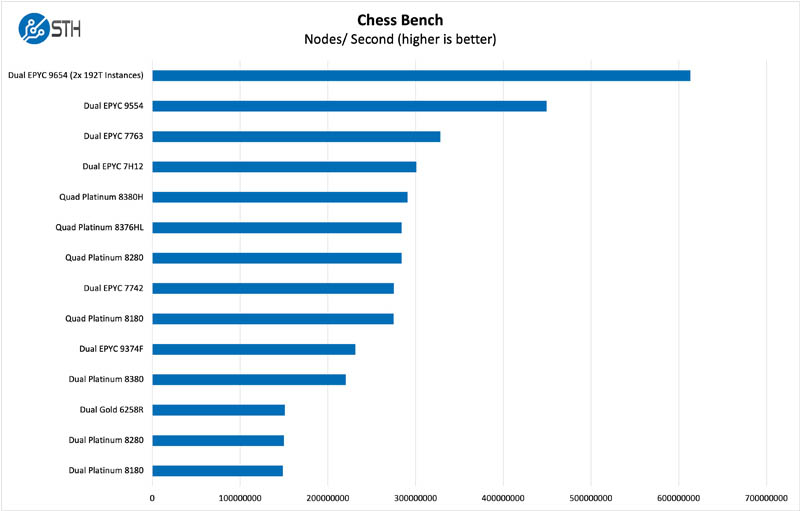
A major challenge here was that our benchmark stopped scaling at 256 threads. We had to split the benchmark up to run in two 192-thread instances via containers to get the result above. Otherwise, a third of the chip was not being used.
SPEC CPU2017 Results
First, we are going to show the most commonly used enterprise and cloud benchmark, SPEC CPU2017’s integer rate performance:
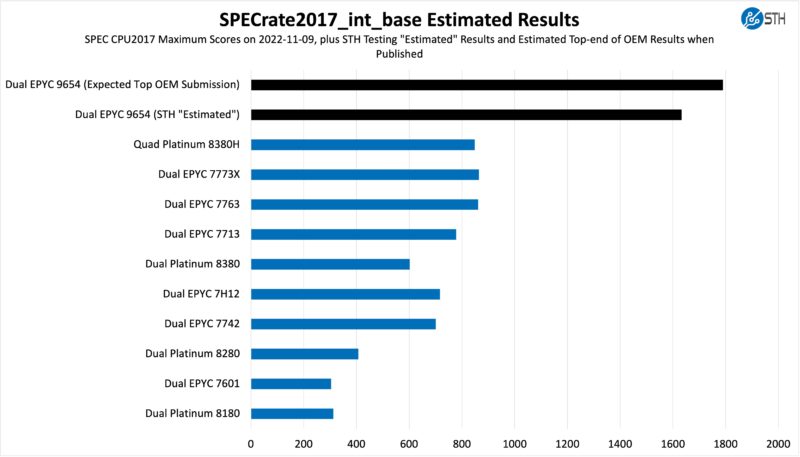
Here, adding more cores, and more clock speeds and memory bandwidth yielded crushing results. We managed to get better than some of the initial estimates that were in the 1590 range. From what we have heard, OEMs doing their full platform tuning will be just shy of 1800 at 1790. That is higher than we got, but it is a crushing figure. AMD will have effectively 3x the top dual-socket Intel Xeon 8380 result in the same socket count. It also means AMD is achieving better performance per core, even when packing cores into 96-core parts.
On the floating point side, we see something similar:
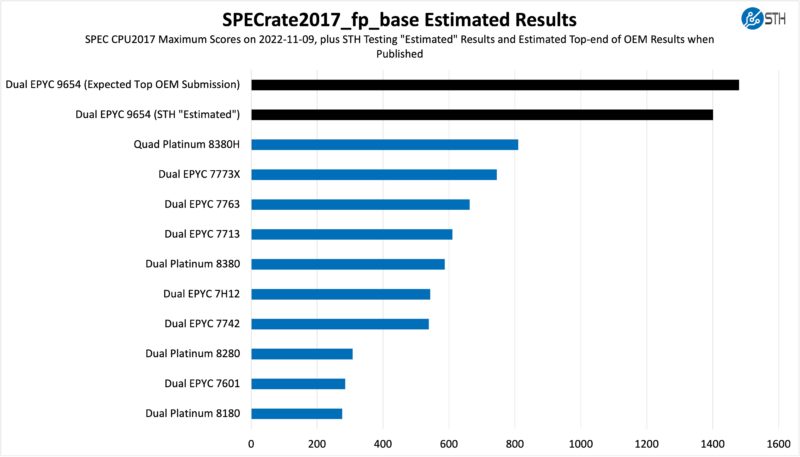
Here, AMD is expected to get a massive performance jump because of AVX-512. The dual Intel Xeon Platinum 8380’s were much more competitive 40 cores v. 64 cores per socket, because of AVX-512. Now that core counts jumped AMD pops to a more than 2x jump over Intel’s top-end. Remember, Intel is only adding around 50% more cores at its maximum and getting some IPC benefits from the new generation, but it needs to get more than 2x the performance to reach AMD. We also saw some preview publication results from OEMs that were higher, so we added those results as well.
Next, we are going to get to some more complex workloads so see how Genoa performs.



{kind=link}
Any chance of letting us know what the idle power consumption is?
$131 for the cheapest DDR5 DIMM (16GB) from Supermicro’s online store
That’s $3,144 just for memory in a basic two-socket server with all DIMMs populated.
Combined with the huge jump in pricing, I get the feeling that this generation is going to eat us alive if we’re not getting those sweet hyperscaler discounts.
I like that the inter CPU PCIe5 links can be user configured, retargeted at peripherals instead. Takes flexibility to a new level.
Hmm… Looks like Intel’s about to get forked again by the AMD monster. AMD’s been killing it ever since Zen 1. So cool to see the fierce competitive dynamic between these two companies. So Intel, YOU have a choice to make. Better choose wisely. I’m betting they already have their decisions made. :-)
2 hrs later I’ve finished. These look amazing. Great work explaining STH
Do we know whether Sienna will effectively eliminate the niche for threadripper parts; or are they sufficiently distinct in some ways as to remain as separate lines?
In a similar vein, has there been any talk(whether from AMD or system vendors) about doing ryzen designs with ECC that’s actually a feature rather than just not-explicitly-disabled to answer some of the smaller xeons and server-flavored atom derivatives?
This generation of epyc looks properly mean; but not exactly ready to chase xeon-d or the atom-derivatives down to their respective size and price.
I look at the 360W TDP and think “TDPs are up so much.” Then I realize that divided over 96 cores that’s only 3.75W per core. And then my mind is blown when I think that servers of the mid 2000s had single core processors that used 130-150W for that single core.
Why is the “Sienna” product stack even designed for 2P configurations?
It seems like the lower-end market would be better served by “Sienna” being 1P only, and anything that would have been served by a 2P “Sienna” system instead use a 1P “Genoa” system.
Dunno, AMD has the tech, why not support single and dual sockets? With single and dual socket Sienna you should be able to be price *AND* price/perf compared to the Intel 8 channel memory boards for uses that aren’t memory bandwidth intensive. For those looking for max performance and bandwidth/core AMD will beat Intel with the 12 channel (actually 24 channel x 32 bit) Epyc. So basically Intel will be sandwiched by the cheaper 6 channel from below and the more expensive 12 channel from above.
With PCIe 5 support apparently being so expensive on the board level, wouldn’t it be possible to only support PCIe 4 (or even 3) on some boards to save costs?
All other benchmarks is amazing but I see molecular dynamics test in other website and Huston we have a problem! Why?
Olaf Nov 11 I think that’s why they’ll just keep selling Milan
@Chris S
Siena is a 1p only platform.
Looks great for anyone that can use all that capacity, but for those of us with more modest infrastructure needs there seems to be a bit of a gap developing where you are paying a large proportion of the cost of a server platform to support all those PCIE 5 lanes and DDR5 chips that you simply don’t need.
Flip side to this is that Ryzen platforms don’t give enough PCIE capacity (and questions about the ECC support), and Intel W680 platforms seem almost impossible to actually get hold of.
Hopefully Milan systems will be around for a good while yet.
You are jumping around WAY too much.
How about stating how many levels there are in CPUS. But keep it at 5 or less “levels” of CPU and then compare them side by side without jumping around all over the place. It’s like you’ve had five cups of coffee too many.
You obviously know what you are talking about. But I want to focus on specific types of chips because I’m not interesting in all of them. So if you broke it down in levels and I could skip to the level I’m interested in with how AMD is vs Intel then things would be a lot more interesting.
You could have sections where you say that they are the same no matter what or how they are different. But be consistent from section to section where you start off with the lowest level of CPUs and go up from there to the top.
There may have been a hint on pages 3-4 but I’m missing what those 2000 extra pins do, 50% more memory channels, CXL, PCIe lanes (already 160 on previous generation), and …
Does anyone know of any benchmarking for the 9174F?
On your EPYC 9004 series SKU comparison the 24 cores 9224 is listed with 64MB of L3.
As a chiplet has a maximum of 8 cores one need a minimum of 3 chiplets to get 24 cores.
So unless AMD disable part of the L3 cache of those chiplets a minimum of 96 MB of L3 should be shown.
I will venture the 9224 is a 4 chiplets sku with 6 cores per chiplet which should give a total of 128MB of L3.
EricT – I just looked up the spec, it says 64MB https://www.amd.com/en/products/cpu/amd-epyc-9224
Patrick, I know, but it must be a clerical error, or they have decided to reduce the 4 chiplets L3 to 16MB which I very much doubt.
3 chiplets are not an option either as 64 is not divisible by 3 ;-)
Maybe you can ask AMD what the real spec is, because 64MB seems weird?
@EricT I got to use one of these machines (9224) and it is indeed 4 chiplets, with 64MB L3 cache total. Evidently a result of parts binning and with a small bonus of some power saving.
Comments are closed.