Step 3: Building the Business Case
So now for the fun part. If you have noticed, STH has transitioned from having more news to almost all reviews since December 2025. The mix is actually very different and something we will get into more in the Q1 2026 Letter from the Editor. As a result, more products are coming in and going out than in the past. That should make sense as if you are doing six hardware reviews a week versus three, the sheer volume of hardware doubles. We had been looking to hire someone to help with shipping and receiving for roughly 8 hours per week. Another 4 hours budgeted was for taking over the reporting function, at least initially. It might take me 2 hours, but we budgeted 4 with some hope that the person would get faster over time. The remaning 28 hours a week would be spent, at least for now, writing articles and doing some miscellaneous tasks. We budgeted $40/ hour for that role which in Arizona is quite good for this type of work.
I do not expect everyone to work at my cadence, so we generally use 50 weeks per year as our baseline. It also makes math easy for this. 40 hours per week, and 50 weeks per year is roughly 2000 hours. I mentioned that we were thinking this new hire would spend four hours a week initially doing reporting, but over time, we were hoping this would be a roughly two hour per week function.
Two hours per week at $40/ hour is $80 per week. With 50 weeks in a year, that is $4000/ year.
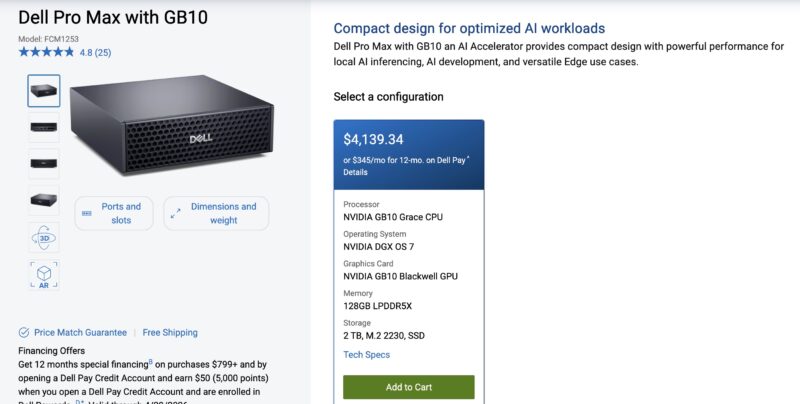
Call that roughly the list price of one of these little boxes. Or in other words, spending a few hours up-front building this workflow, that is underpinned by gpt-oss-120b running on a Dell Pro Max with GB10, is effectively replacing the need for that part time role.

Of course, if it ends up taking someone 4 hours per week instead of 2, then the payback period would be more like six months. We also do not need to schedule vacations, sick time, or a Christmas to New Year’s break for the box, and we get requests that week since it is the end of the year. This box is really working 52 weeks a year not 50. There are many who will rightly proclaim that we could run this on a cloud service much faster, which is true, but again, we do not have to give others access to our data sources by running it locally. For many reporting functions, the data is sensitive, so keeping access local is great. That is also a reason that even with checks on both ends, we do not give remote users access to this. I do not want Dell seeing its page views compared to HP or HPE.

Even as a small business owner with not a huge amount of revenue, buying equipment that has a 6-12 month payback period is really easy to justify.
Step 4: This is Just the Start
Even running a relatively large and slow gpt-oss-120b model, we will not hit 1% utilization on the box. Most days, it has gpt-oss-120b loaded and is just waiting for something to do. Note that we switched to vllm, but the box often looks like this:
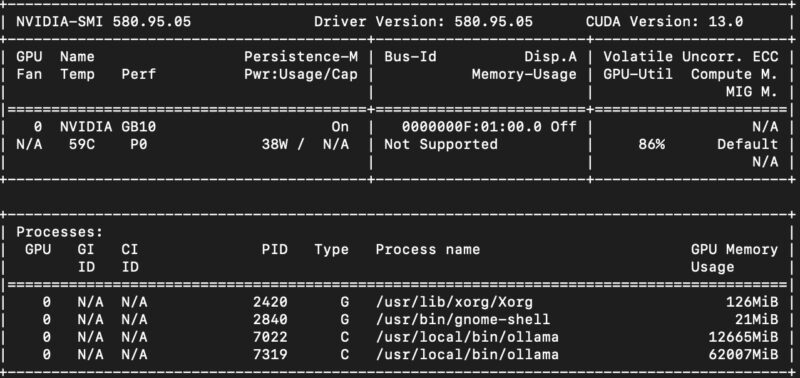
The fact is that we have a gpt-oss-120b model sitting there, loaded, ready to use by other applications. When we discussed trading roughly a role of 2 hours/ week for $40/ hr in our simple model to give us a 12 month payback period, we also have a machine capable of running other applications.
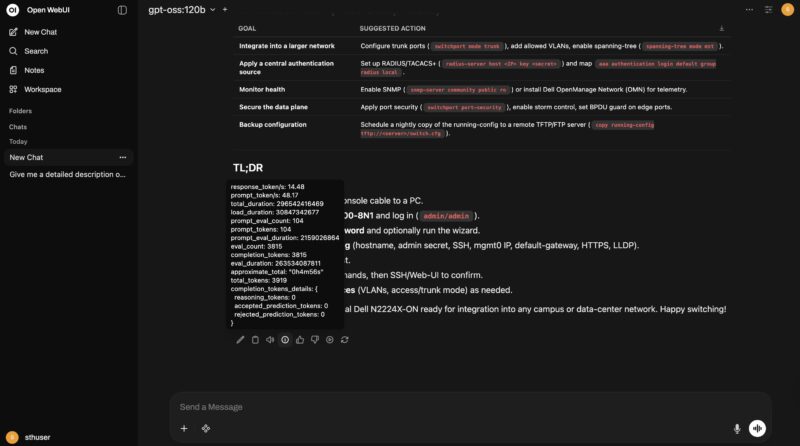
For example, we can even use it to do simple tasks like research and help the setup of our Dell N2224X-ON switch. Just having a local gpt-oss-120b endpoint is great. After testing and seeing how much better this was in a real-world workflow, it gives me more confidence to use it elsewhere.
Next, let us talk a bit about scaling the Dell Pro Max with GB10.



{kind=link}
I’ve got 4 FTEs doing reporting full-time. For those who don’t get it, they’re using the LLM to convert a very unstructured request into a structured request format. There’s a lot of words around that, but that’s what employs people.
Eye-opening to say the least. We’re going to order a few this quarter just to try this.
What I like is since email is asynchronous that interactive performance doesn’t matter and one can run a capable large language model with everything to gain on cheaper hardware.
You haven’t included energy cost in your business case- how does that play out?
H Lowe – Yes
Eric O – Realistically, when these come in, if we get them out that week, that is usually OK. Sometimes folks need them that day or the next. You are right, the SLA is not tight, which makes this easier.
Martin – Power in Arizona is relatively cheap, which is why there are so many data centers and fabs here. These are sub $5/ month to run. On the other hand, what would 0.05-0.10 of a person’s energy cost be to offset that?
@Martin it should be noted in the analysis that energy costs do need to be added but figures are going to be variable. Different regions can have vastly different power rates.
Analysis of this compared larger rack based systems ran locally at the same cost of energy would be interesting. Rack solutions are supposed to more efficient in terms of performance/watt but have a much much higher power consumption as well. In other words, those larger systems need to be loaded for those performance/watt improves to translate into a return on investment. For projects like this who load is cyclical and job completion is not time sensitive, ROI should arrive much sooner due to lower initial investment. The nice thing about the math in small cluster vs. larger rack solution in this analysis is that per unit power cost get factored out of both sides of the equation as the result is a load factor difference.
The comparison to cloud offerings or hosted data centers is that power often is included in their figures. It may not be an explicit line item but does explain some of the different region-to-region pricing cloud providers can have for the same compute. In addition, the rate for which hyperscalers pay is often less than commercial rates or residential rates of power in an area. Electric companies like consistent load and consistent predictable income from large data centers. The cloud solutions can be competitive on a cost basis as they can run multiple customer job across the same hardware to generate the loads necessary to hit ROI in a similar time frame, even including the differences in power cost though that is more abstracted. That performance/watt difference of the larger rack systems is where the profit is generated for cloud providers as they can operate at the scale and loads that are not feasible in-house.
You really don’t need AI to do this.
Easier to setup some basic workflow automation around your content analytics/metrics and have automated reporting setup to key stakeholders/clients that blasts out reports every week/month/quarter.
Make it part of the package of what they get when they sponsor content/run ads, etc.
MR – That would be great, except that is not for the standard reporting flows we have. This is to address the ad hoc requests that come in and need to be serviced.
Your proposal is to use a different process than what folks are asking for/ need. You are right, the challenge AI is solving is the non-standardized reporting.
It is nice to see a real world use case for AI at this level. The growing concern with AI is that there is a lot of spend on the build out and a lot of folks playing with “slop”. There are little practical use cases especially outside of the large enterprises.
As simple as the use case in this article may seem, it is one of the few times that I have seen N8N being used in a way that benefits small businesses.
It also highlights the nuance of how AI hw can be used in this type of business. It is not training at 100% utilization. You are able to create the app with relatively little effort, test and then set and forget.
Now I need to move beyond creating an animated image of Jensen Huang with ComfyUI!
It’s a thousand dollars more than the HP and the exact same configuration.
@Sridhar: Wasn’t the Dell released earlier?
You were not presenting a fictional “GB20” next step on purpose?
If a future GB20 ever shows up, it should come with 128–512?GB of RAM and around 800?GB/s of memory bandwidth, not just a nicer spec sheet.
GB10 looks great, but on some key specs it was already obsolete on paper the day it launched. Prioritizing 2×200?Gb/s networking over seriously juiced?up memory bandwidth is a great way to build a “workstation” that looks amazing in a rack but makes a lot less sense on a desk at home, where extra RAM and bandwidth would be far more useful. And given that Apple has been shipping roughly 800?GB/s on a Mac Studio with an M2 Ultra since 2022, it’s hard to pretend that 273–300?GB/s is still “high?end” in 2026.
GB300 DGX Station is the next step, but that will be $100K+ now.
Remember, you can also scale these out easily. We have an 8x unit cluster already.