
A few weeks ago we were allowed to discuss the new Intel mesh interconnect architecture at a high-level. You can read Things are getting Meshy: Next-Generation Intel Skylake-SP CPUs Mesh Architecture for that initial overview. Today we can share full details on the Intel Xeon Scalable Processor Family (Skylake-SP) mesh architecture, and what it means for the Intel platform.
Much of the information here was scattered in our Intel Xeon Scalable Processor Family (Skylake-SP) platform overview piece, and others on microarchitecture. The mesh architecture is a cornerstone, so important that it can have dramatic impacts on performance.
Understanding Intel Moving From Ring to Mesh and AMD Infinity Fabric
The first concept we wanted to cover is the Intel Mesh Interconnect Architecture and why it is moving away from rings. As we covered in our previous piece, the ring architecture was the product of a much smaller topology. As larger core counts became normal, and two sets of rings were added, Intel needed on-die bridges to connect the two hemispheres. Moving to a mesh interconnect aligns resources in rows and columns yielding higher overall bandwidth and lower latencies than Intel could have achieved with its older rings scaled up yet again.
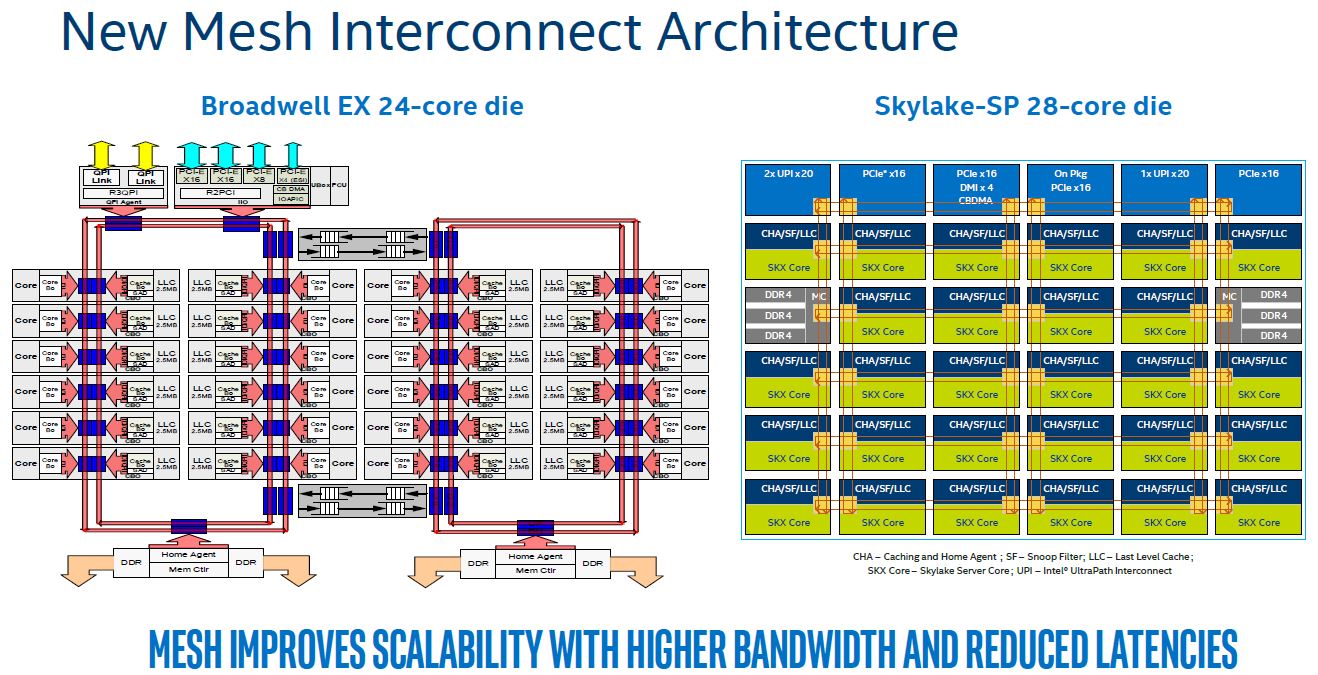
Astute eyes will notice that the Intel diagram labeled “Broadwell EX 24-core die” is actually the XCC Broadwell-EP die. The Broadwell-EX 24 core die actually has a second QPI stop on the second ring set for its third QPI link. That is important for our discussion of mesh as it is comparable to the third UPI link in the Xeon Platinum and the top end of the Gold range.
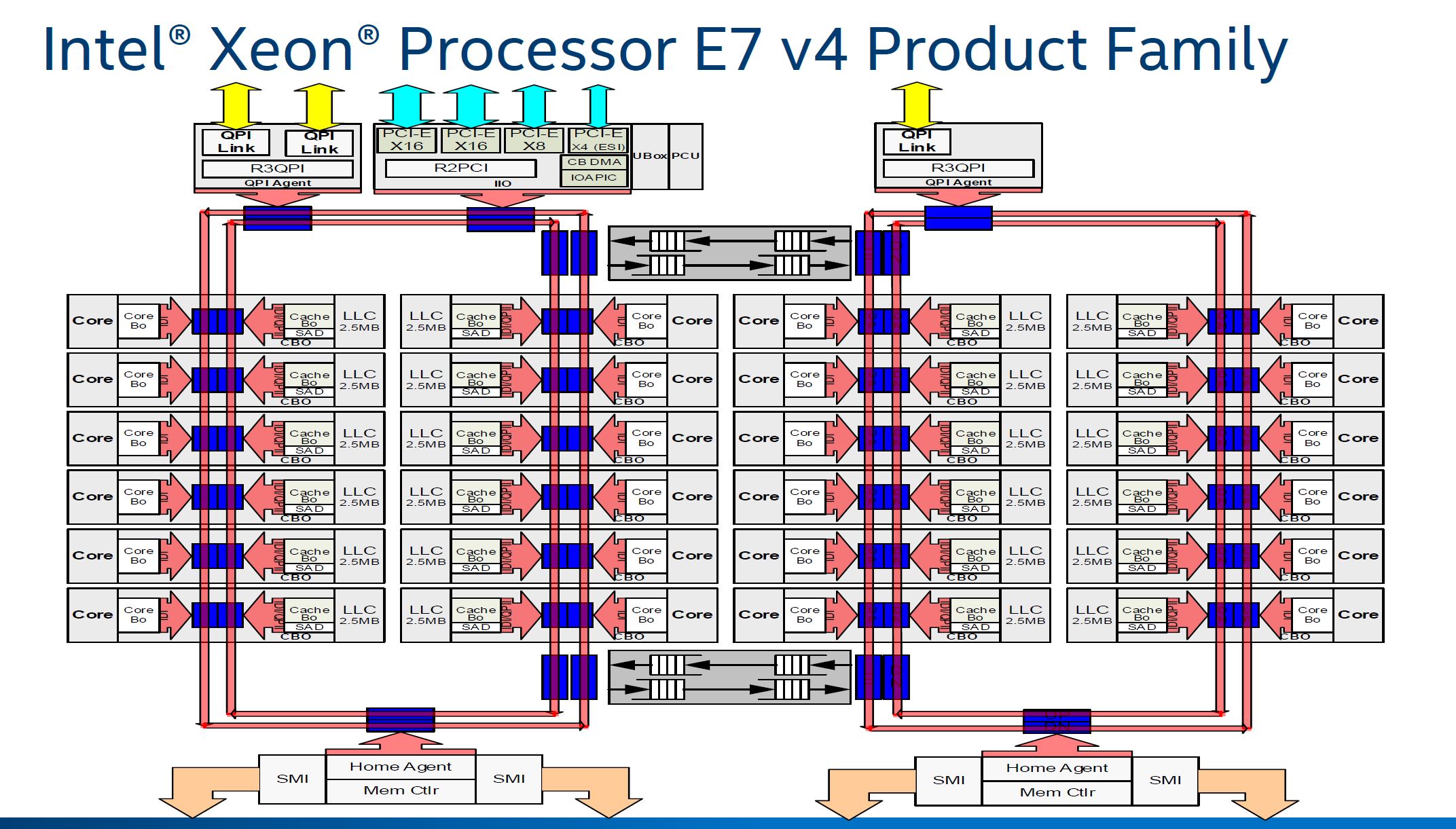
Here is a larger view of the comparable new mesh:
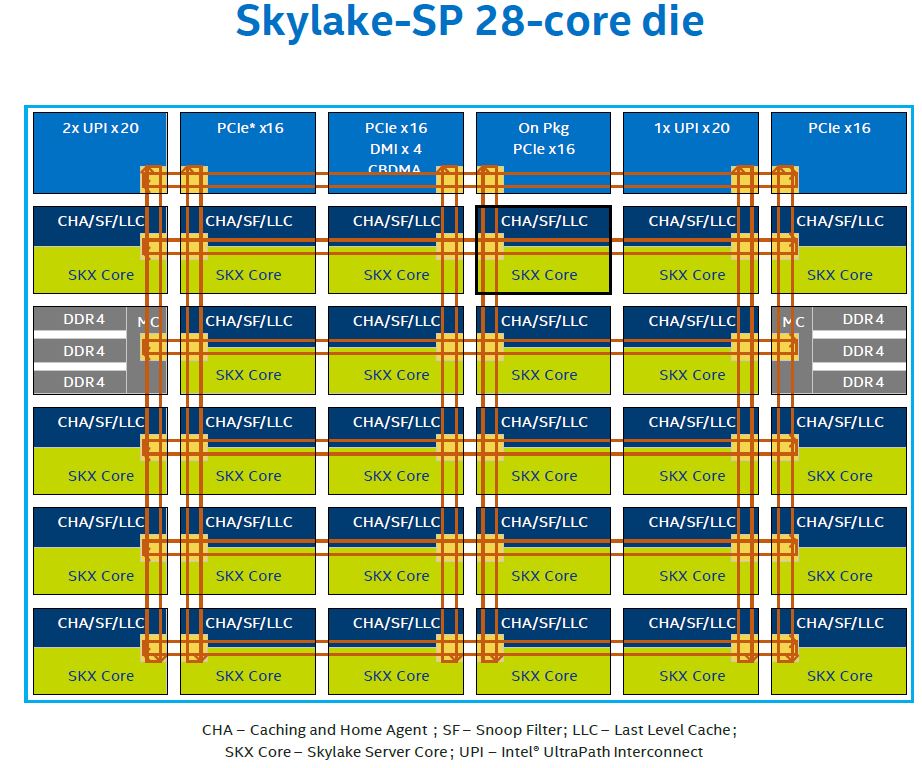
We covered the UPI links in our Skylake-SP Platform Overview piece. In the meantime, here is the video we recently published on AMD EPYC Infinity Fabric and Intel Broadwell-EP rings that will help you understand how the install base (Intel Xeon E5 V1 to V4) and the new competitor (AMD EPYC) work:
In the 6×6 mesh topology of the 28 core die, there are up to a total of 36 stops on the fabric. 28 are for the cores. 2 for memory controllers (each handling 3x DDR4-2666 channels), two for UPI, three for PCIe and PCH connectivity, and one for integrated package devices such as Omni-Path fabric.
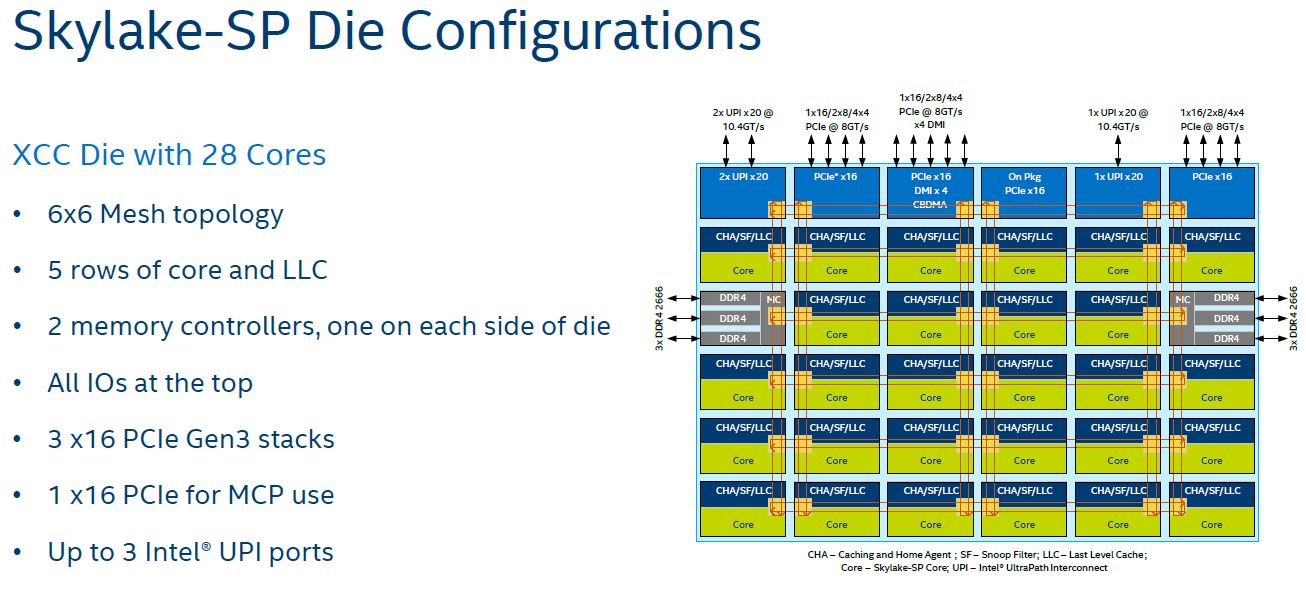
Also, before we get too far ahead of ourselves, we will often use the 28 core die in our examples. The vast majority of Skylake-SP CPUs sold are going to be smaller 18 core and lower die configurations. These have less complex structures.
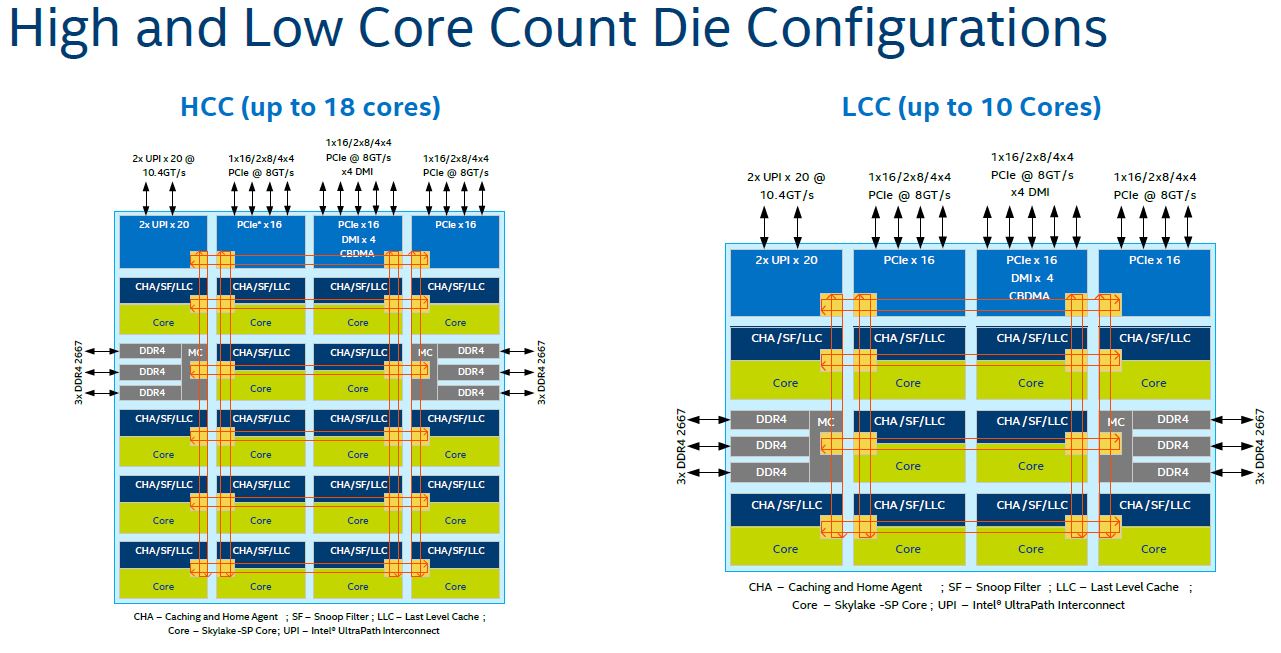
Two items are missing from the smaller die mesh diagrams. First, there is no on-package PCIe x16 interconnect and second, the third UPI link is absent. This dovetails well with the Intel Xeon Processor Family Platinum Gold Silver and Bronze segmentation.



{kind=link}
Thanks for this Series of Articles on the two camp’s newest Server Processors.
Did you see Kevin Houston’s Article: http://bladesmadesimple.com/2017/07/what-you-need-to-know-about-intel-xeon-sp-cpus/ ?
He mentions the lack of Apache Pass (Optane) and the observation that the SKUs with only 2 UPI Links are essentially a Ring Topology; you need to go top shelf for a Mesh.
Those Cables on the Skylake-F look innovative. If you accept a bit of Latency you can wire up a Rack of 8-ways for a SuperSever – 42U x 8 x 28 = 9,408 Cores per Rack (or only half that many if you need 2U per 8-way).
Wish AMD had made a separate SKU for 4-way but I guess they’re counting on the Core doubling that next year’s switch to 7nm will bring.
Thanks again Patrick, for all these Articles.
Comments are closed.