Supermicro X12SDV-16C-SPT8F Topology
At the time of writing this review, we did not have access to the block diagram as we normally do. Instead, here is the topology output:
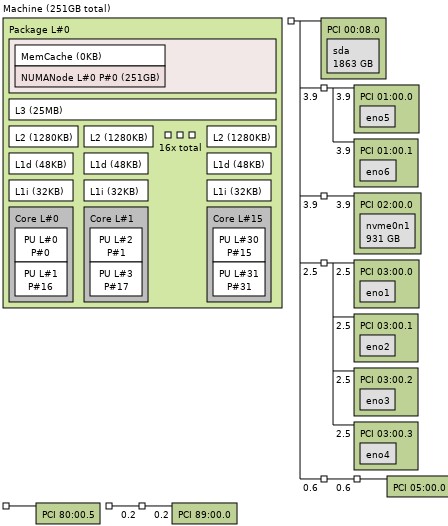
A key here is that this is a single NUMA node. The AMD EPYC 3451 is still a two NUMA node design with half of the DIMM channels and half of the PCIe lanes, networking, and so forth on each NUMA node. Effectively the Ice Lake D-2775TE looks like a single socket server while the EPYC 3451 looks like a dual-socket option. In the X12SDV-16C-SPT8F, that means that all resources are attached directly to the same CPU making communication faster.
Supermicro X12SDV-16C-SPT8F BIOS and Management
The Supermicro X12SDV-16C-SPT8F utilizes Supermicro’s newer web management interface. It also supports Redfish APIs. The newer web management portal has features like HTML5 iKVM but also a more responsive layout that is easier to access via mobile devices.
One item we will note is that this platform utilizes a random IPMI password and not ADMIN/ ADMIN like older generation systems. You can read more about this in Why Your Favorite Default Passwords Are Changing.
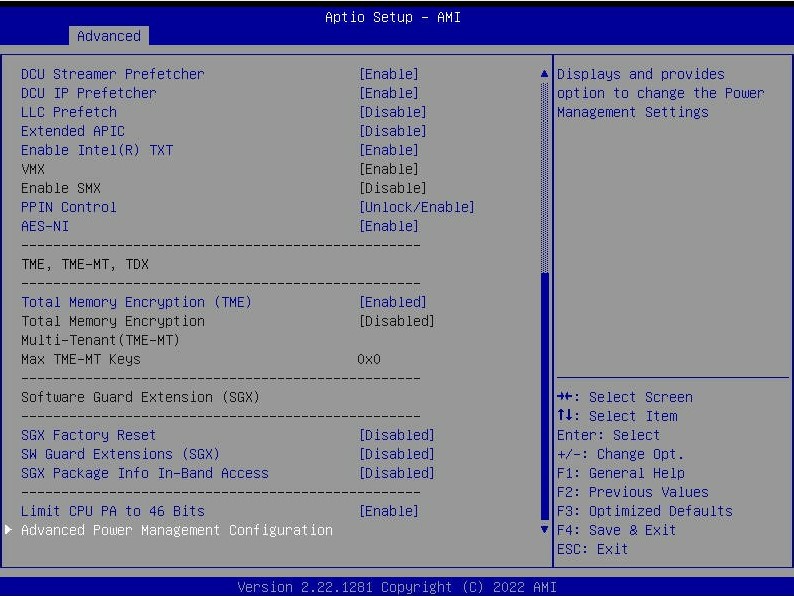
The BIOS are still the same AMI Aptio base that we have seen for generations.
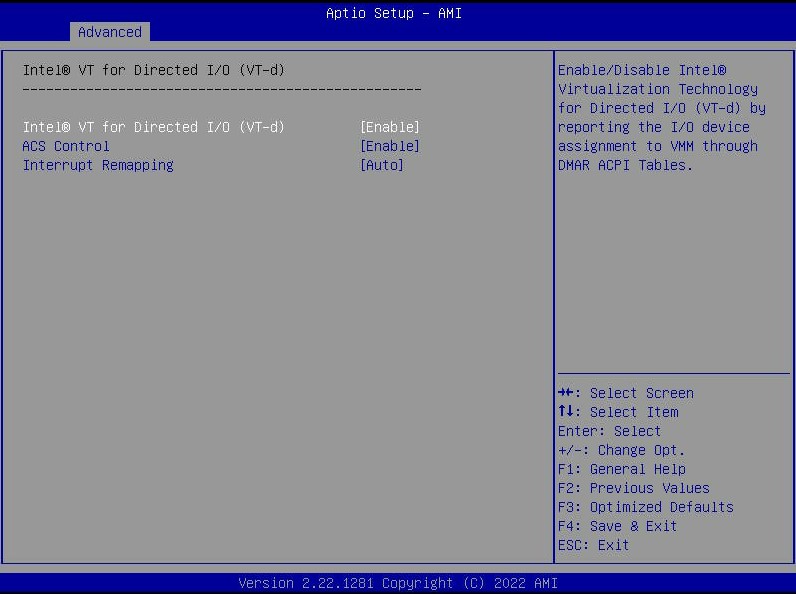
The new chips support features like VT-d and Intel has certainly made an effort to do a much better job supporting a common virtualization set between its embedded and mainstream Xeon lines.
That also means that we get features like TME and SGX in BIOS which are more advanced features with this generation.
Even though this is an embedded motherboard, it feels much more like a mainstream Supermicro server platform.
Supermicro X12SDV-16C-SPT8F Intel Xeon D-2775TE Performance
Taking a quick look at the generational performance we wanted to show a few benchmarks that we ran directly on the three generations of Supermicro platforms, X10SDV, X11SDV, and now X12SDV. We are not going to focus on things like AVX-512 and VNNI performance as we looked at those for the Ice Lake series more broadly. Part of the Ice Lake Xeon D’s appeal is the ability to use these extensions for things like AI inferencing. Intel’s theory is that by providing “enough” AI inference performance onboard, companies will not have to add additional PCIe accelerators thereby shrinking footprint and power consumption.
Instead, let us take a quick look at a few generational benchmarks, starting with our Linux Kernel Compile benchmark:
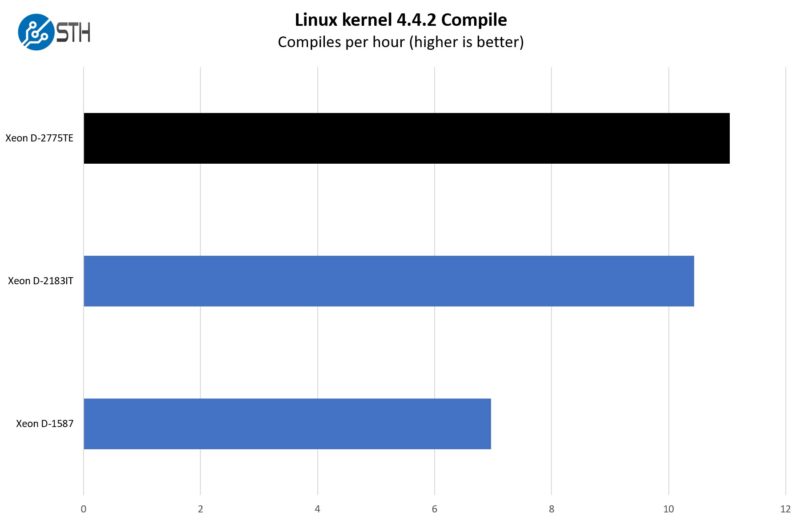
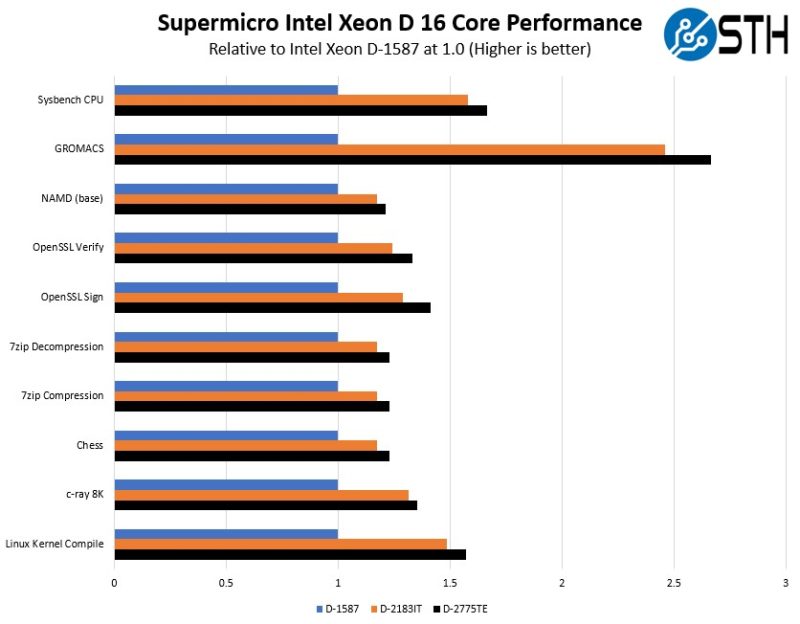
Here, we got a nice performance gain but this was not a 30-100% gain over the X11SDV generation’s D-2183IT. There is a much larger gain shown between the X10SDV generation’s Xeon D-1587. The D-1587 was lower power and had a “unique” architecture to fit that many cores into such a small space. The D-1500 series was also a dual-channel memory architecture. This is a big difference in performance.
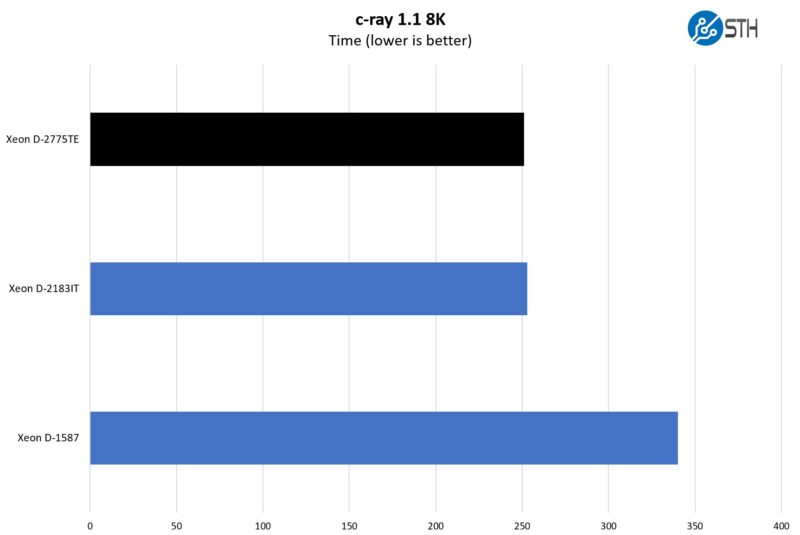
In our classic c-ray 8K test, we see another small gain. This is more akin to a Cinebench run on the consumer side, so we still see a big jump between Xeon D-1500 and D-2100 but a smaller jump to the D-2700.
On the Chess Bench side, we get another solid gain.
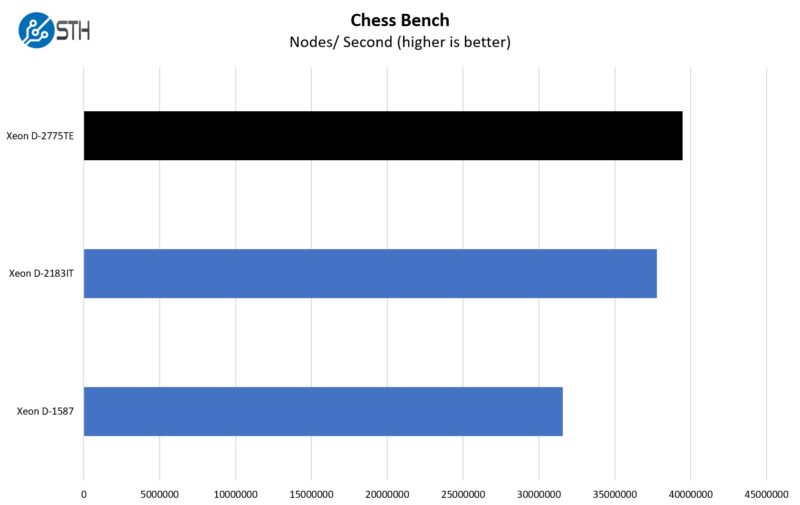
Just taking a quick look at the performance deltas since Broadwell-DE.
There are certainly some IPC increases, but keeping cores constant, it seems like the biggest factor was adding memory channels and TDP since the Broadwell-DE generation.
A quick note on the networking performance, we used iperf3 and could push line rate from both SFP28 ports. We also tested the X550-at2 10Gbase-T ports and the i350-am4 1GbE ports and saw line rate from those as well. This is an area that has improved since we saw our first pre-production samples, but it appears as though networking performs as one would expect at this point.
Next, let us move to power consumption before our final words.



{kind=link}
Ah, we will have exciting homelab performance 5-6 years down the road :)
Are those boards even available? Since the launch this April Xeon-D 1/27xx was pretty much nonexistent.
What’s the purpose of such boards? Building a router / firewall which consumes >100W?!
Edge compute. Websites doing processing before it gets to the database. Though I run a whole site on an older D-1521, you could do it on one of these with the right storage mix.
OVH has a bunch of this kind of server, though they build them into stacks rather than chassis. Pile them high, lease them cheapish.
Its very nice. I’m impressed by all of the onboard network adapters.
I wonder why the occulink and M.2 are PCIe Gen3 instead of Gen4. Is it because those go through the PCH?
The new IPMI user interface is pretty cool too
I hope there will be a compatible active cooler especially too for the Xeon D-1700 series. If the X11SDV-8C+ heatsink/cpu-cooler will fit? We will find it out sooner or later…
“dreams about a small NAS with a mirror of 7,68tb-15,3tb pcie gen4 nvme drives and 25gbe”
Comments are closed.