
Today we have our review of the Supermicro SYS-5038K-I-ES1 developer workstation for the Intel Xeon Phi x200 series. This review took us longer than most product reviews in terms of the number of hours it took to complete. As standard on STH we will go into the hardware. We will also take a look at why the developer workstation is awesome as we have had the chance to work with several companies who purchased them. We also have experience managing larger systems, namely the popular 4 nodes in 2U systems that are the defacto standard cluster compute blocks of today. As such we are going to specifically review this machine in the context of being a developer workstation either next to one’s desk or in a data center as a prelude to a larger cluster.
Supermicro SYS-5038K-I-ES1 – “Ninja” Developer Workstation Hardware
For some context on the Supermicro SYS-5038K-I-ES1 it is a system meant to come in (configured) at just below $5000 which is a departmental procurement threshold in many organizations. They are very much an entry point into Knights Landing without having to spend tens of thousands on a standard 2U 4 node machine. Intel and Supermicro built these systems to be office friendly and exhibit panache when open. The chassis itself is based on the Supermicro CSE-GS50-000R gaming chassis. Since this is the official Intel developer workstation, the red accents have been replaced with blue.

Overall, the outside is subtle enough to look like a fancy office tower workstation but there is little signage to tell an office visitor that underneath the steel is a water-cooled 64 core behemoth.
Cooling is provided by a CoolIT Solutions closed loop system with a combo pump and water block. LGA3647 is a big change for cooling as we highlighted in our LGA3647 socket post. The radiator has two fans and vents atop the chassis. That configuration works well for desktop use but it is a bit awkward to mount on a shelf in the data center. Again, we have seen these systems, in the same data center we have our DemoEval lab in, and that system has now been replaced by a Xeon Phi- Omni-Path cluster. These development systems lead to clusters.

There are two other fans to provide internal airflow with all four being PWM controlled fans which keep noise down. To add to this, Supermicro adds sound deadening material to the chassis panel we removed which keeps the water pump hum to a minimum.
Zooming in, the water cooler looks, well, “cool” flanked by six 16GB DDR4 RDIMM modules. If you had this in your office, it is likely to invoke Phi Envy when you open it up to show co-workers.

Around the CPU socket, there are six DDR4 RDIMM slots to fill the Xeon Phi x200’s memory channels. The standard system comes with 16GB DDR4 RDIMMs but you can add 32GB RDIMMs to the system to hit 192GB RAM. The fact that your many-core compute chip has direct access to six DDR4 channels and 96 or 192GB of RAM is an advantage that Intel touts with its Xeon Phi x200 series processors.

The chassis has a ton of drive bays. There are 6x 3.5″ internal bays, 4x 2.5″ internal bays and 2x 5.25″ external bays which perfectly match the system’s 10x SATA III connectors. We do wish that in a future iteration we get hot-swap external drive bays even if that lowers the total count. They are significantly more convenient if you need to sneakernet large datasets from the data center to a remote office. Our advice is to use an external NAS device for 3.5″ storage to keep power consumption and noise down on the KNL tower.

With a total of three PCIe slots on the internal Supermicro K1SPE motherboard there is a decent amount of expansion opportunities onboard. The PCIe 3.0 x4 slot is perfect for a NVMe PCIe SSDs. The two PCIe 3.0 x16 slots do support dual width cards. One is likely to be used for networking. Be forewarned if you are thinking about adding a GPU to the system, you will need to adjust the factory default BIOS settings. Options such as Above 4G encoding need to be changed to support modern GPUs. If you try this, and get a hang at DXE PCIe enumeration you know what went wrong.

Power is provided by a Seasonic 600w 80Plus Gold PSU with modular cables. The system does come with the cables that are not already pre-wired in the event you want to add drives or PCIe devices that require additional power. At STH we prefer Seasonic PSUs and use them in virtually every workstation we build.

The rear of the system has a standard server-I/O pattern including dual 1GbE, USB 3.0, VGA out and an IPMI management port.

We suspect most users will utilize IPMI management to perform console actions as it is much easier than finding a VGA video monitor. The KNL system firmware had features such as the HTML5 iKVM so you do not need to use a Java applet to access the remote console. You can even reboot the system and access the console via mobile IPMIview as we did on a recent international trip over VPN.
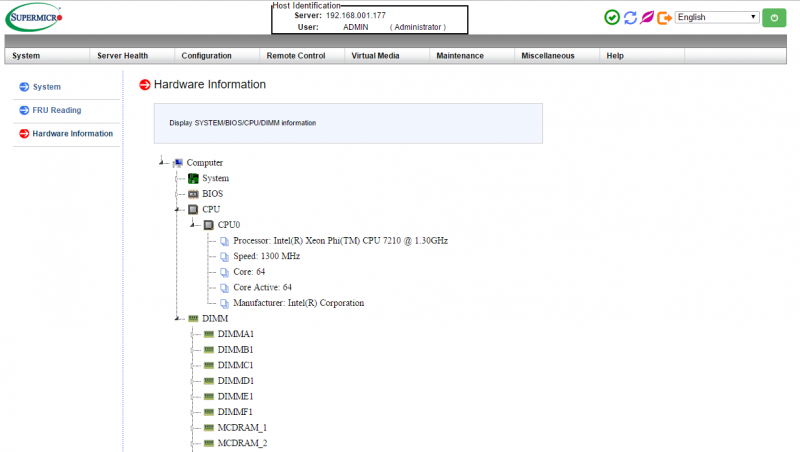
Overall, the Supermicro SYS-5038K-I-ES1 strikes a good balance providing a subtlely insane Xeon Phi server clothed in an office acceptable desktop tower.
What Would We Recommend Adding?
One of the first things we noticed with the Supermicro SYS-5038K-I-ES1 is that the system is shipped with dual 1GbE networking. This actually makes sense on the developer workstation since the included Intel i350 NICs work on just about every OS out of the box. Realistically, just about everyone will want to add some sort of higher-speed networking. With the Intel Xeon Phi x200 series there are only a few options:
- 10GbE – only if that is your only network option
- 25/40/50GbE and FDR Infiniband – better options to feed data and if you are going to use MPI
- 100GbE/ EDR Infiniband – better yet
- Omni-Path – While you can get external Omni-Path cards, it may be worth seeing if you can get an on-package solution
We saw even doing lower-end data algorithms (e.g. training on Wikipedia data sets) that 1GbE was getting saturated and choked by the Xeon Phi 7210. We have the advantage of using a lab in the same data center as one of the major hyper- scaler’s AI lab. Before their full Omni-Path enabled 4-node-in-2U cluster went live, they had a high-speed network card in their Supermicro SYS-5038K-I-ES1 so they could access a faster fabric before their Omni-Path switches arrived.

Internal storage wise, the hard drive that comes with the unit we wish was swapped out for an SSD. CentOS load times were not quick with the spinning media and we noticed significant boot speed improvement by using a lower-cost SSD. This is important because developers are likely to want to change the core communication and MCDRAM settings on the box which requires a reboot each iteration. Colfax does include a P3520 SSD which is super.
What OSes Can the Xeon Phi x200 Series Run?
We did quite a bit of testing regarding which operating systems will work with the Intel Xeon Phi x200. In terms of Linux, CentOS 7 came pre-installed on the system’s hard drive. We first ran Ubuntu 16.04.1 and that had no issue. These two OSes also supported Docker so we were able to run Alpine Linux containers on the Xeon Phi 7210 without issue. You can see that were able to add the system easily to our Rancher based Docker Swarm and push containerized workloads directly to the machine.
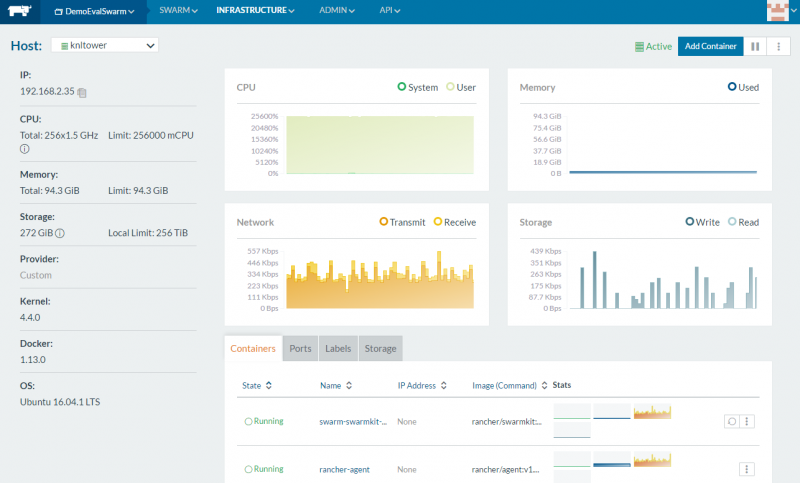
If you are using Linux, this is awesome as it means you can run services and push workloads (potentially with different compiler flags) directly to the machine. We highly recommend using Docker as the Xeon Phi x200 is compiler sensitive and it makes life much easier on a developer workstation like the Supermicro SYS-5038K-I-ES1. If you are not comfortable with the Docker CLI, you can use a GUI management tool. We recently looked at Rancher, Shipyard and Portainer Docker management tools so you can get a feel for each.
Outside of Linux, we were able to get the Intel- Supermicro SYS-5038K-I-ES1 to boot an existing Windows Server 2012 R2 installation and run programs. This was an awesome feat of compatibility.
Along with the Windows Server 2012 R2 we were also able to get Windows Server 2016 data center working on the KNL system.
With DPDK, a super fast 16GB addressable MCDRAM memory pool, a large number of cores, and other features, we have seen many FreeBSD shops start working on KNL systems. We tried four popular FreeBSD versions out, FreeBSD 11, FreeBSD 10.3, pfSense 2.3 and FreeNAS 9.10.
Our key takeaway with the Intel Xeon Phi x200 and FreeBSD is that you will want to start development using FreeBSD 11 and later. The FreeBSD 10.x OSes failed to boot. That is fine as FreeBSD 11 will replace older versions as time passes.
Overall, we were extremely impressed with the breadth of what worked on the KNL developer workstation. It speaks a lot to out-of-the-box code compatibility. The biggest catch is that one needs proper development tools (e.g. icc) for an environment and there is still a large gap between gcc and icc performance.
Performance
The Supermicro SYS-5038K-I-ES1’s Intel Xeon Phi 7210 with its 64 cores and 256 threads is an interesting machine. To get the most out of it, it does require utilizing the onboard 16GB of high speed MCDRAM as well as its AVX512 vector units.
KNL is still a platform that is rapidly getting better. AVX512 instructions are going “mainstream”. GCC supports automatic AVX512 vectorization and can even provide vectorization reports via the “-fopt-info-vec-all” option. If you are interested in getting started with AVX512 development, we highly recommend Colfax’s guide. They have a great table that breaks down Xeon Phi versus future Xeon (e.g. Skylake-EP) AVX512 instructions and compiler flags. Here is the summary table you need to know to start KNL optimization:
| Intel Compilers | GCC Flags | |
|---|---|---|
| Cross-platform | -xCOMMON-AVX512 | -mavx512f -mavx512cd |
| Xeon Phi processors | -xMIC-AVX512 | -mavx512f -mavx512cd -mavx512er -mavx512pf |
| Xeon processors | -xCORE-AVX512 | -mavx512f -mavx512cd -mavx512bw -mavx512dq -mavx512vl -mavx512ifma -mavx512vbmi |
You can see the four gcc flags in lscpu output for the Intel Xeon Phi 7210 cpu:
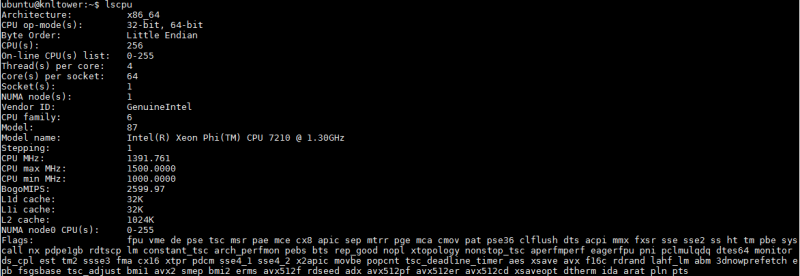
Single core performance of the Knights Landing CPU is far from excellent. The Intel Xeon Phi 7210 has a base clock speed of 1.3GHz (Turbo 1.5GHz), low by modern standards. In fact, if you have a <44 thread workload that cannot use AVX512, we suggest simply using standard Xeon E5 CPUs. Our first attempts at porting code from our Intel Xeon E5 benchmark suite to Xeon Phi was bad (okay, really bad.) Here are our tips for getting better:
- Use icc over gcc if possible. We saw performance increase in some tests by 30% or more. That is huge. Intel Parallel Studio XE Cluster Edition
- Intel provides tools like Intel Python and Intel Caffe that provide a speedup. Use them!
- Intel is releasing MKLs. If you are using a deep learning framework (e.g. Tensorflow) you will see a fairly large out of the box boost when using the appropriate MKLs.
- If you have existing code, run automatic vectorization reports. If you have code that is not going to work well on AVX512 (and do not want to port it) use Intel Xeon E5 chips instead.
- Adjust the MCDRAM and cluster modes.
You may be wondering what is meant by the MCDRAM and cluster modes. MCDRAM is 16GB high-speed on package memory that offers relatively high performance such that it occupies a performance tier between on-die cache and the hex channel DDR4 DRAM. There are four different options to set the system to, Flat, Cache, Hybrid and Auto. We are going to cover the first two. Flat means that the 16GB MCDRAM becomes byte addressable such that you can run your application using 16GB of extremely fast RAM. If you have 96GB of DDR4 installed in the system and then set it to Flat you will see 112GB addressable memory. Cache gives something akin to a huge L3 cache that is slower than on-die but is still significantly faster than DDR4 system memory.
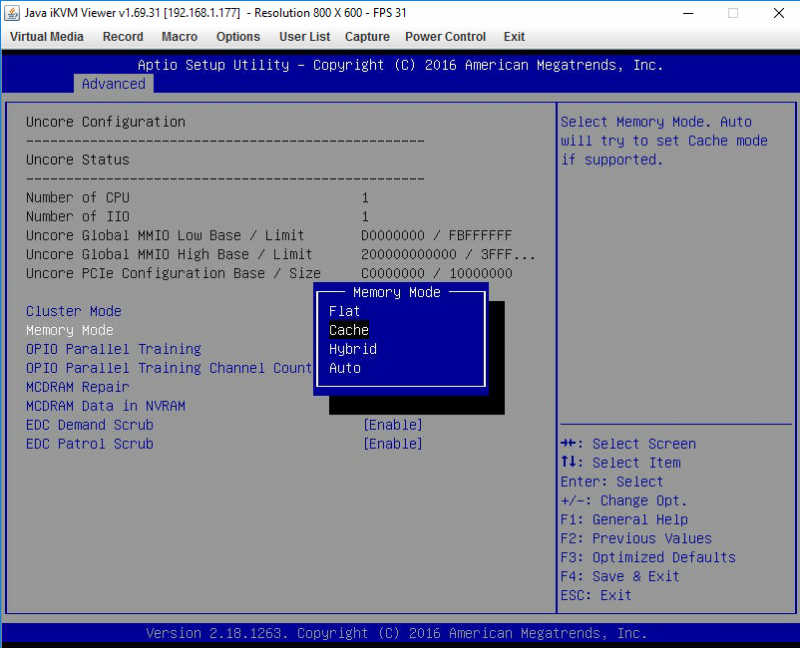
Beyond this, there are six different options for the on-die core cluster configuration. These options essentially describe how the on-die core resources get distributed.
Since we ran different workloads and different sets of code, we ended up running them through three different memory mode configurations times five different cluster mode configurations for a total of fifteen iterations per. Although the system is easy to power cycle and access BIOS remotely, changing these values does require a system reboot. We do hope that Supermicro adds a reboot to BIOS feature in the future as the initialization time of KNL platforms is quite long. If you are thinking that as a developer you will be rebooting the server often to test core cluster modes and MCDRAM modes, that is likely during the learning process. We had a simple AVX2 workload that we ran out of the box on the system before we even touched AVX512 optimizations.
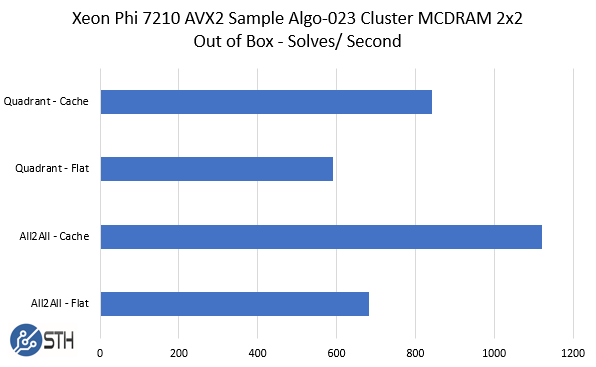
In the end, we got the fastest performance from All2All – Flat once we made the slight change to use the MCDRAM in Flat mode but Cache had a big impact on the out-of-box run performance. Each iteration (and the 11 more not shown here) took a few minutes during the BIOS change and reboot. The process of testing different cluster and MCDRAM configurations is very common.
There are a ton more tips in terms of performance and there are also experts in the field who are far better than we are. As a result, we are going to publish a few figures just based on what we were able to achieve relative to dual Intel Xeon CPUs using a few of the tricks discussed here. We are still profiling our AI/ Machine learning benchmarks so these are a bit of a work-in-progress. It is a huge effort where we profile many different types of systems. Here is an example when our Docker Swarm cluster was only 1024 cores and 17 machines (and that does not include the 18 GPUs in the cluster.) The Xeon Phi machines are requiring additional effort for benchmarking but we have about 13,000 runs completed. That is also why we have become big fans of using Docker as a framework for machine learning development.
Suffice to say, we are still in progress but these runs can take upwards of 24 hours each so iterations can be slow.
We are going to use Intel Xeon E5-2698 V4’s. Each Intel Xeon E5-2698 V4 has a TDP of 135W versus a 215w TDP for the Xeon Phi 7210. Likewise, each Xeon E5-2698 V4 lists for around $3200 compared with approximately $2400 for the Xeon Phi 7210.
Development Task: Linux Kernel Compile Benchmark
Our standard gcc Linux Kernel Compile Benchmark is an interesting use case here. The Supermicro SYS-5038K-I-ES1 is meant to be a developer workstation. Despite the platform having a HPC chip, users are likely to spend quite a large amount of time compiling different software builds on the machine.
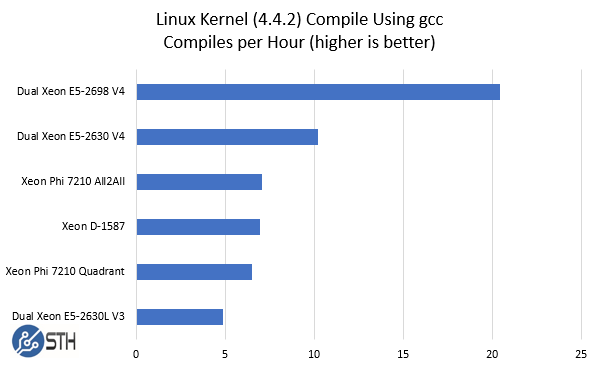
As you can see, we added a few comparison points to the benchmark so you can get a feel regarding where the system falls. The Intel Xeon D-1587 is only a 65w TDP chip, however, the suggested selling price is around 2/3 of the Xeon Phi 7210 making them reasonably close competitors in terms of price. Looking at the dual Xeon E5 results the dual Xeon E5-2698 V4 platform is a racecar in comparison. It also uses about twice the power during benchmark runs. The Intel Xeon E5-2630 V4 is closer in terms of power per run when housed in a 1U system and is slightly faster. For compile jobs that take a matter of minutes, KNL compile performance is very reasonable. We also wanted to highlight that switching from Quadrant to All2All shaved an appreciable 8% off of the compile time.
Stream MCDRAM Testing
We did want to provide a quick look at the stream performance of the MCDRAM in flat mode to compare it to the hex channel DDR4. Our Intel Xeon Phi 7210 is limited to 2133MHz DDR4 RDIMM operation which is a small handicap Intel put on its lowest end part. We used gcc with -DSTREAM_ARRAY_SIZE=6400000. The results were somewhat shocking.
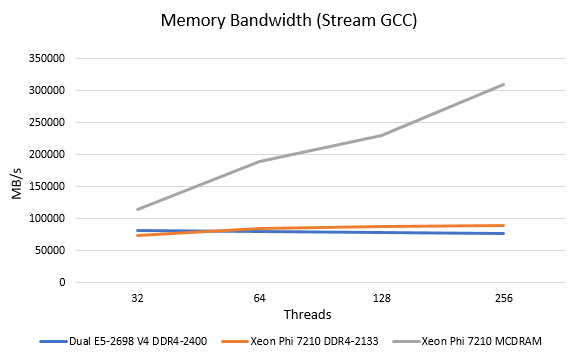
We knew the MCDRAM was going to be fast, but this is was shocking. As we raised the thread count we were able to get over 300GB/s. Using icc provides significant performance boosts, especially at lower thread counts with Stream and Intel publishes >450GB/s figures. Still, the bandwidth potential of the KNL chip onboard is awesome. In a follow-up piece focused on the Xeon Phi 7210 we will have more optimized icc results but we just wanted to show what is possible.
Torch – Intel MKL – Component Failure Prediction
We were able to allow a local Silicon Valley startup on the Supermicro SYS-5038K-I-ES1 to try out their model. They are doing component failure prediction using images taken of assemblies. Hopefully, we can talk more about their application in the coming quarters, but we wanted to share their results on the machine.
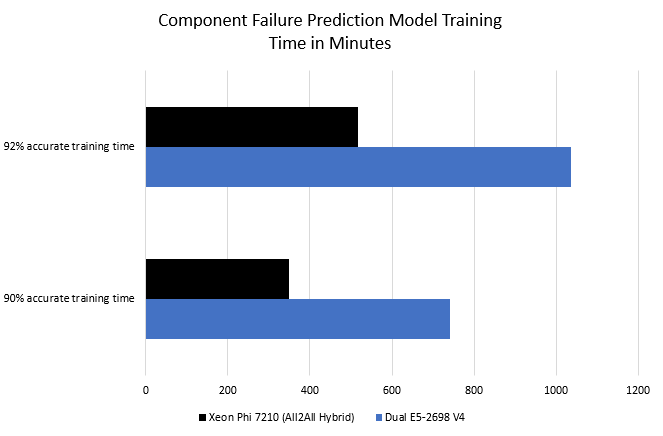
The result was somewhat predictable. In terms of speed, once icc and the AVX512 vectorization happened in their code the Xeon Phi speedup was apparent. We also should note that it is not just raw performance that was impressive. The water-cooled tower was using about half the power of the slower dual Intel Xeon E5-2698 V4 setup in the process.
After giving our test machine a try in the STH lab, the startup bought two of these for their cramped office.
Environmental – Power Consumption and Sound
While we do not publish sound levels for data center gear, we do for products that are intended for habitable space. We have seen plenty of these machines on rack shelves in data centers but they are clearly targeted at office space.
- Idle: 109w
- Average Workload: 248w
- Max Observed: 331w
In terms of sound levels, the system hovered in the 33-37dba range during testing. There were no high pitched noises or jet engine sounds as you would hear with a 2U 4-node system sitting in your office.
Final Words
Overall, we were extremely impressed by the Intel Xeon Phi “Ninja” developer platform based on the Supermicro SYS-5038K-I-ES1. If you do not have budget (yet) for a 2U 4-node solution, this is a great solution. It is more than many single CPU Xeon solutions, but it is just about the lowest cost option to get into Knights Landing that there is. We also like the fact that this comes pre-assembled as LGA3647 is harder to work with than older generation sockets. The fact that upon opening the chassis you have something that you can show off to lustful colleagues due to the clean water cooling solution makes adds to the cachet of the workstation. At the same time, the system looks sleek but is far from some of the outlandish gaming towers we have seen. The fact that it is black and blue, and not overly loud also can make the system inconspicuous if that is desired. We would have liked to see external hot swap bays for sneakernet multi-TB data loads. We would have also liked to see the radiator placement moved to the front or the rear of the chassis so it would be easier to rackmount. We have seen several in data centers now and it is not uncommon to see a quarter rack taken up by the configuration. Still, this is the best sub $5,000 system out there for developers to start working with KNL and its associated MCDRAM memory and AVX512 capabilities.



{kind=link}
Excellent review! I would like to see more benchmarks and tests of software packages that are really designed to work with AVX-512 instructions and multithreaded cores when you get the chance. This was a solid first-look at the product though, and clearly this category of products is trickier to test than standard consumer hardware.
FYI – All2All and Cache are basically the modes that you want to use when the target software isn’t cluster aware or Phi aware, respectively. If you’re willing to make your software cluster aware, then non-All2All settings should yield better performance. The same is true of the flat versus cache mode. If you’re willing to have the OS export the MCDRAM to your application and then manually manage that memory, then sure, you should be able to exceed the performance of the “dumb but automatic” cache mode. Finally, if your software gets better performance under “flat” mode but is actually not MCDRAM aware, then that strongly implies “dumb luck” with where the OS allocated your memory (MCDRAM versus regular RAM).
Comments are closed.