Performance
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article. Specifically, since we just did a Intel Xeon D-2123IT benchmarks and review piece, using a similar Supermicro platform that performed effectively identically, you can skip this section as it is effectively the same from a performance perspective.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
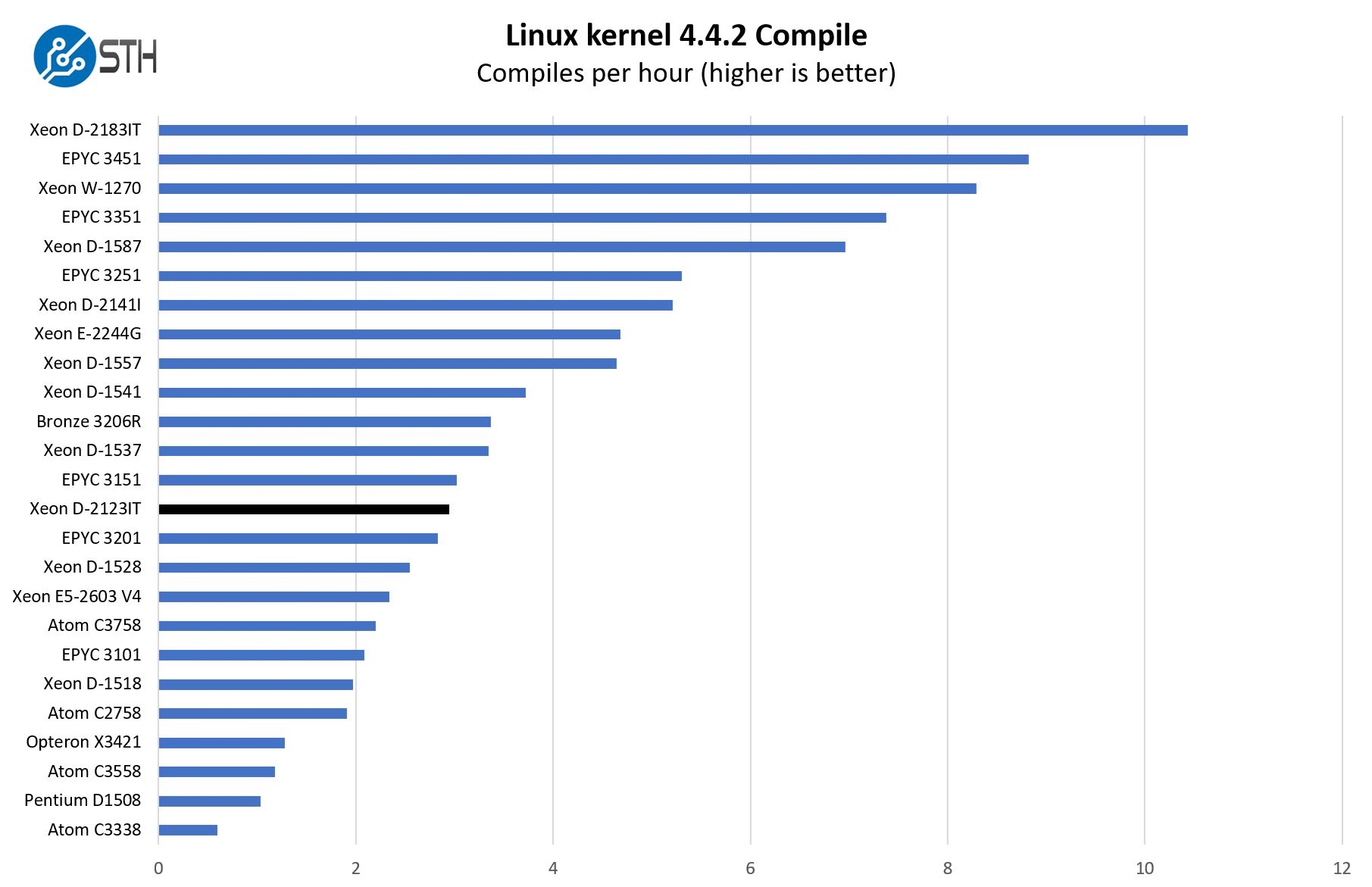
These charts are a bit busy given how many comparisons we wanted to show. Here, we actually wanted to focus on just how big of a gap there is between this CPU and the Intel Xeon D-2183IT in terms of performance. Many systems and motherboard manufacturers design a PCB, then place a number of different Xeon D SKUs to create different performance levels. There are segments of the embedded market that want just single SKUs, but there are others that want to have this flexibility to minimize design cycles while being able to scale performance.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
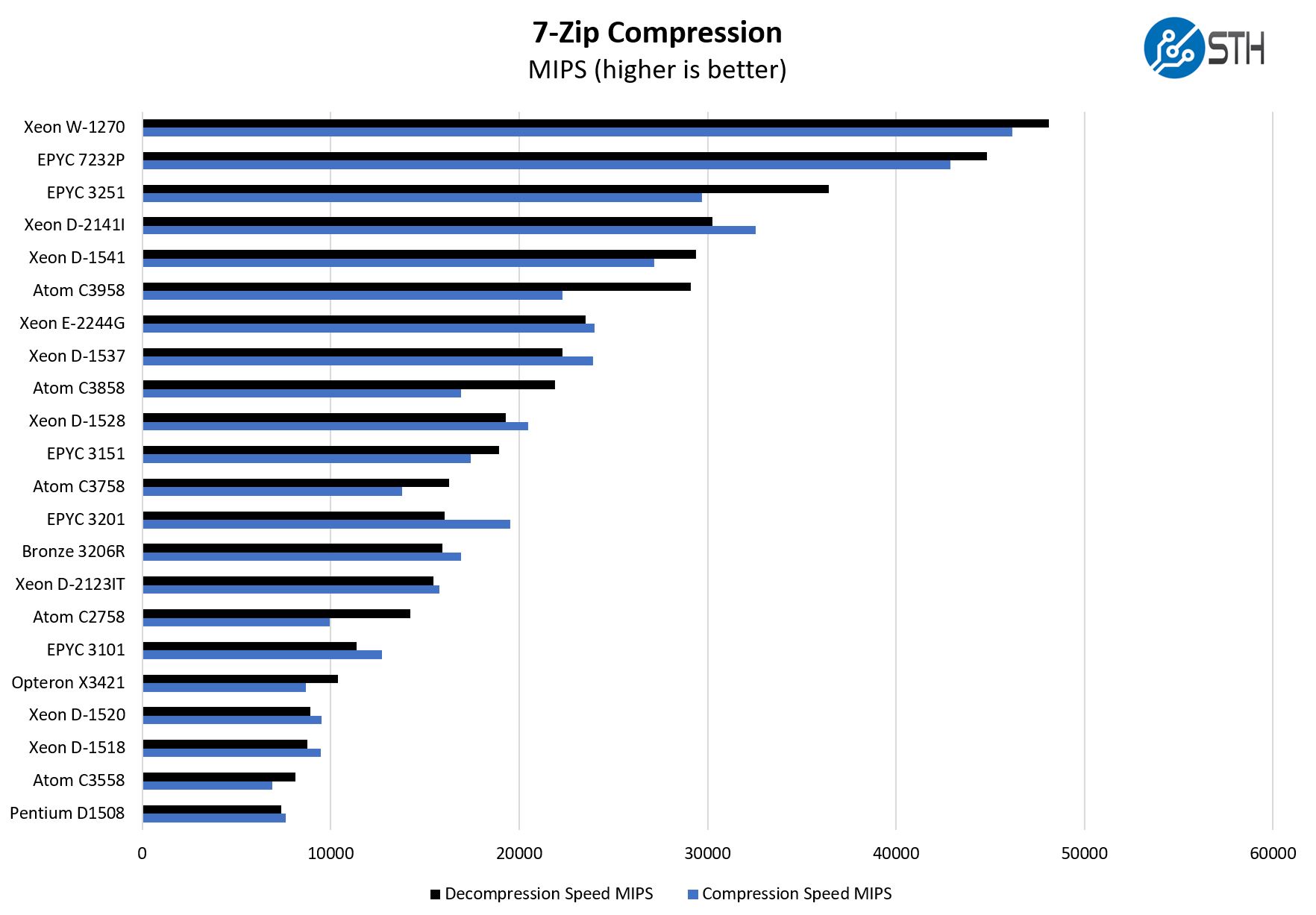
Here we wanted to highlight performance that was close to and often better than the Intel Atom C3758. The 4 core/ 8 thread configuration with the larger cores means we get more performance than eight smaller cores.
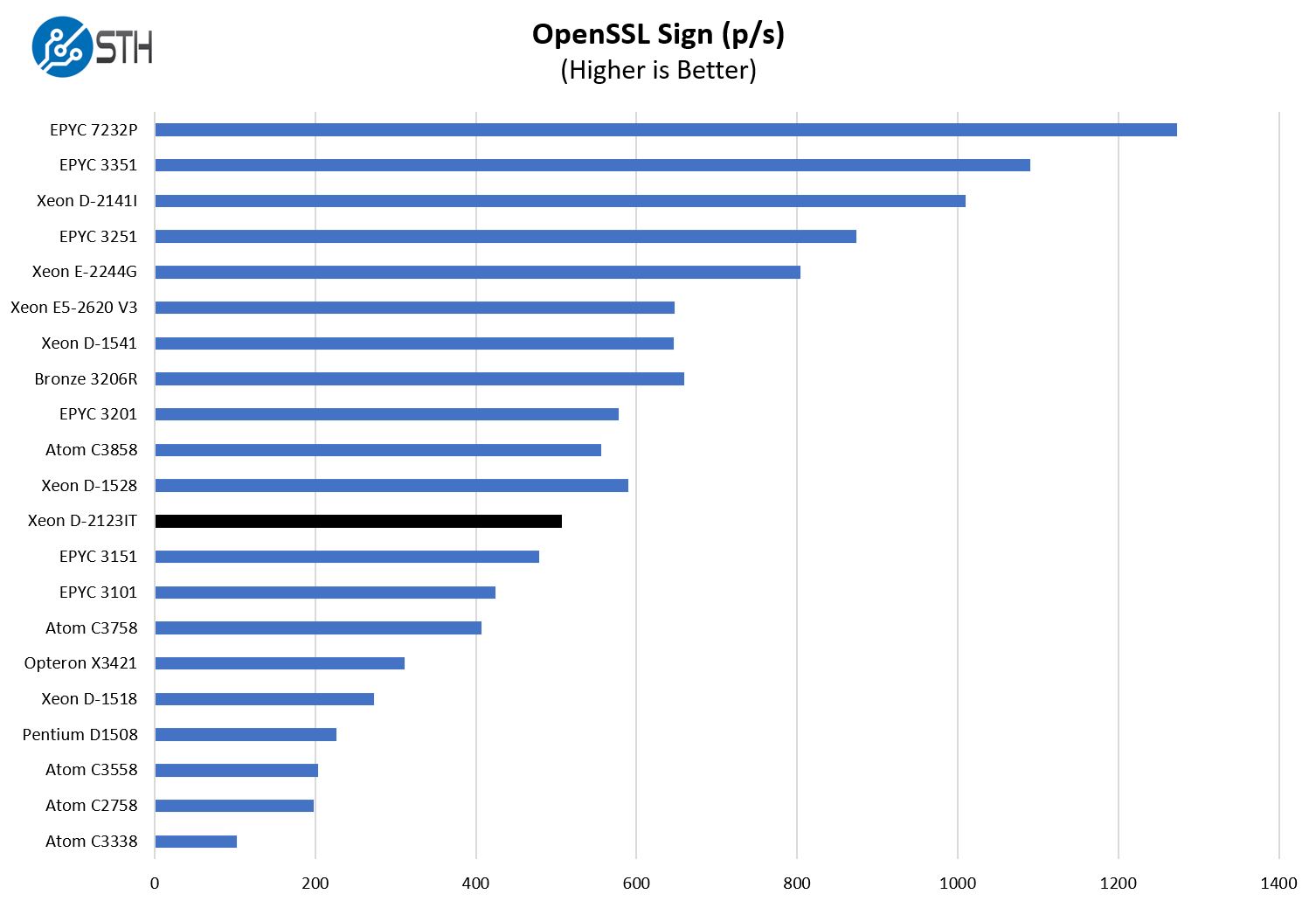
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
Here are the verify results:
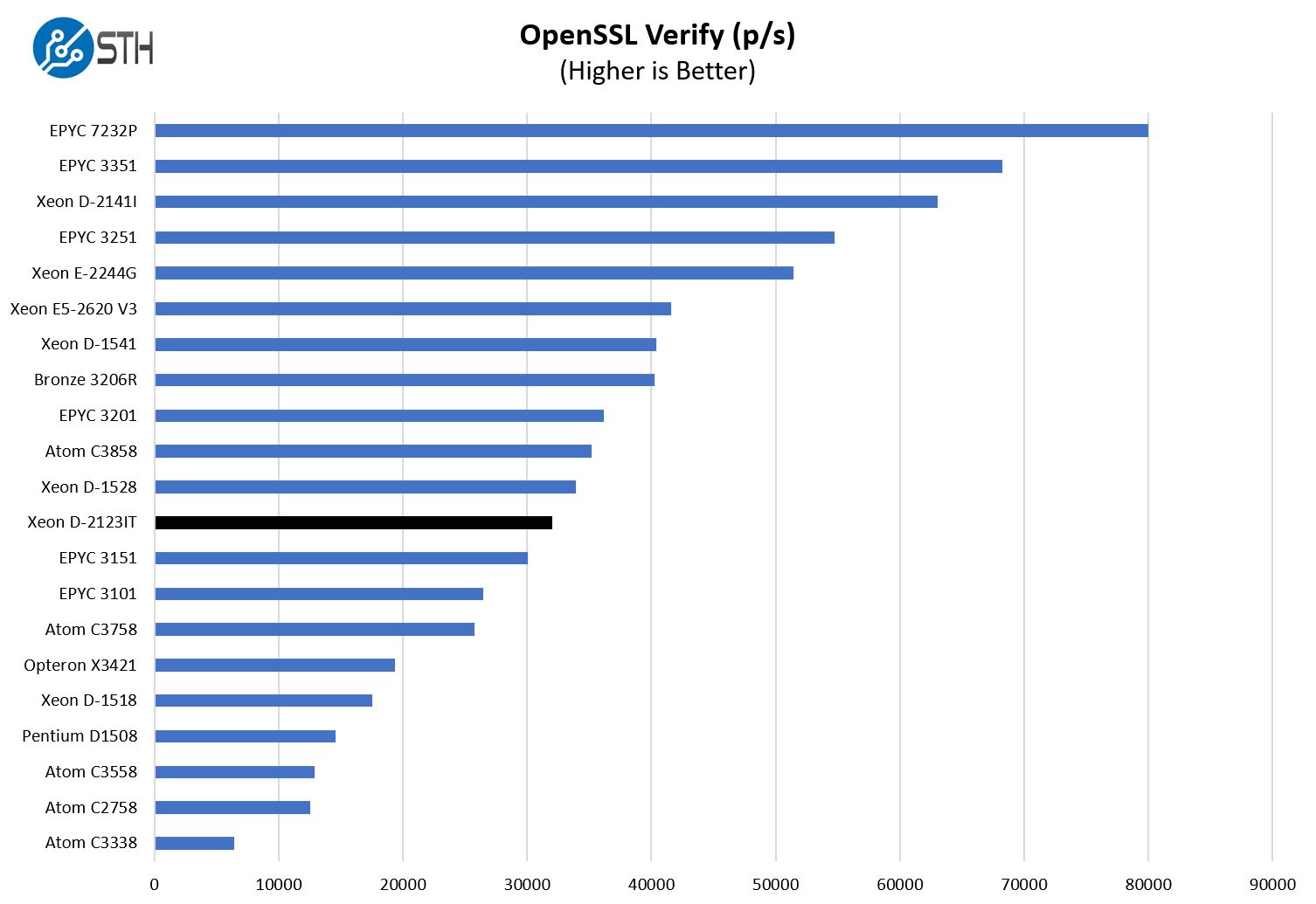
We traditionally sort by the verify results which is why the sign chart looks a bit different. Still, we can see that we are a bit ahead of the 4C/ 8T AMD EPYC 3151 here and well ahead of the 4C/ 8T Intel Xeon D-1518.
GROMACS STH Small AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using a “small” test for single and dual-socket capable machines. Our medium test is more appropriate for higher-end dual and quad-socket machines. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
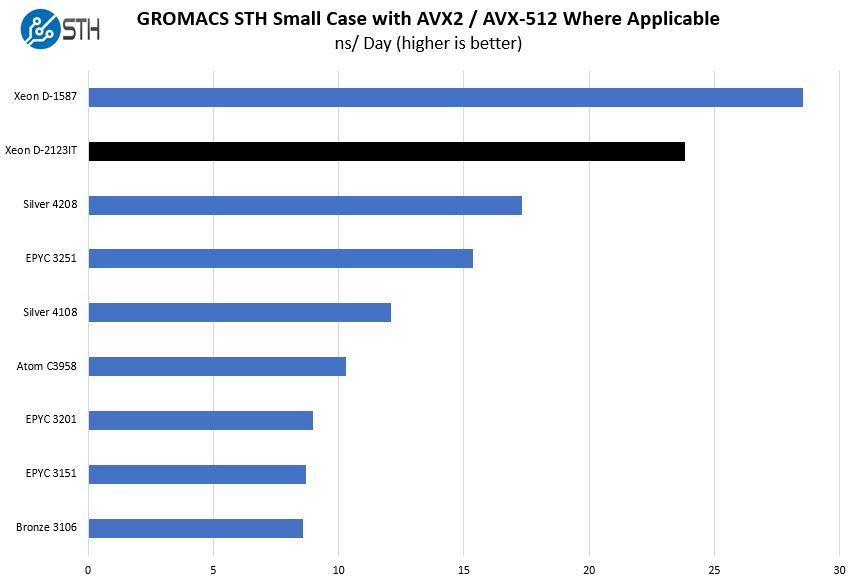
This is always one of the more interesting results. Intel maintains that the Xeon D-2100 series has a single FMA AVX-512 implementation just like the Intel Xeon Silver 4100/ 4200 series. Consistently we see in applications that are AVX-512 enabled that it performs extremely well, significantly better than even the 8 core/ 16 thread Intel Xeon Silver parts. We confirmed this again around the time of the Cascade Lake launch with Intel. This is a great example of where a specific acceleration feature can make a chip leapfrog options that do not have the same feature.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
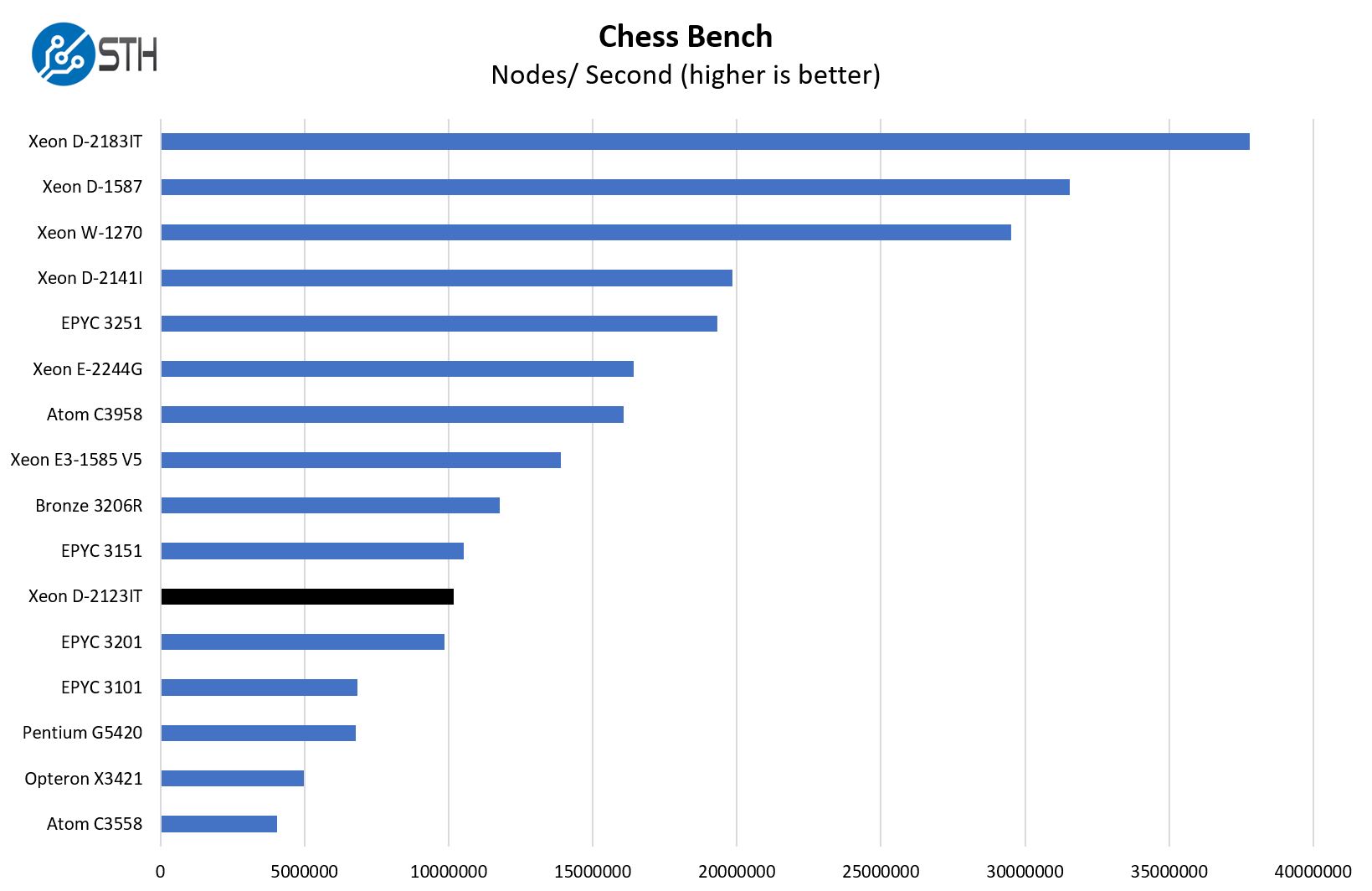
The chess benchmarking shows a lot of the same. Some may notice that we use the Intel Xeon Bronze 3206R in many of these charts. In our view, this is the lowest-end 2nd Gen Intel Xeon Scalable Refresh part so it may be one some segments are tempted to run as the low-end mainstream Xeon server solution which is why we wanted to include it here.
Next, we are going to have power consumption, market positioning, and our final words.



 offers){kind=link}
Thank You for your solid review of my dream motherboard! Yes, I am one of those Supermicro X11SDV-4C-TP8F fanboys;). Best Regards, ABQ :)
I know as the readers of STH we do not like that STH is now doing video, but the video for this one is like a doctoral dissertation on this system and the current state of the Xeon D-2100 series.
I’d say you should make the Xeon D insight around pricing from the video its own article. That’s a stinger in the video.
Anyone that has one and can comment on how picky this system is regarding SFP+ optics/DAC? I have the previous generation and with most Intel drivers these started requiring Intel coded DACs halfway through their lifecycle, causing major issues when this happened after scheduled updates on devices in the field.
Intel forgot to put a QAT in this processor :)
Not great for IPSEC, openssl and crypto workloads.
VPNs are quite popular in 2021.
But they offer nice xeon-d models with hardware crypto acceleration.
The Supermicro SuperServer E300-9D-8CN8TP has some distinct advantages. The E300-9D-8CN8TP sports an Intel® Xeon® D-2146NT, which has Intel Quick Assist Technology. The reviewed Supermicro SuperServer E300-9D-4CN8TP sports the more limited Intel® Xeon® D-2123IT, which lacks Intel QAT. The E300-9D-8CN8TP adds 4C and a sizeable $500 on Amazon. An alternative might be to add an Intel QAT accelerator, but there would need to be available power and you’d lose the PCIe slot. Used Intel QAT accelerators are available on eBay for cheap.
it’s seems a great option for home server but for 8-900 $ it’s to high
The Supermicro X11SDV-4C-TP8F motherboards are $449 NIB & free shipping, if you already have a case.
@Fred Tang: I am a long-time reader too and enjoy the videos.. So it is not all of us.
I was sceptic at first, but it provides additional value and is not just the article script in video form.
I urge other video sceptics to give it a try!
And to the die-hard anti-video crowd: Any tech journalist knows, that without YouTube, traditional online journalism is dead as disco. It is a matter of survival, plain and simple.
@ABQ Supermicro X11SDV-4C-TP8F in italy is over 700€ on ebay 500$ plus 2-300$ of duties
usa’s price is very differente for europeans people for costums duties and VAT (in italy is 22%)
BMC/IPMI licenses are BS, which is why I’m happy purchasing Gigabyte/ASrock Rack.
I’m running 2 of these for 2 Years 7/24 now without any Problems. Perfect for a VMWARE Home-Lab, but not only. I’ve replaced the (loud) Stock Fan’s with Noctua Fan’s – they are not so loud and cools good (Noctua NF-A4x20 PWM). Also added the RSC-RR1U-E8 expansion for the low Profile Riser Card (AOC-SLG3-2M2-O), so you can run 2 additional M.2 NVMe SSDs. Perfect for running/testing VSAN (Robo). As i was so satisfied with this Supermicro-Solution i run now 2 additional 8-Core Versions of this Barebones (E300-9D-8CN8TP) for running/testing “remote-site replication” scenarios. I can only recommend this Barebones.
Hi Giuse! Did you replace the fans of the E300 chassis with Noctua fans? Are you happy with them? Did it get silent?
Hi Giuse! greeting,
do you run E300-9D-4CN8TP or E300-9D-8CN8TP,
I’m looking for my expansion of 2x for workload home lab (VMware SDDC Stack) on E300-9D-8CN8TP?
do you advice for the same.
SYS-E300-9D-8CN8TP
Release Date: Nov 2018 (EOL: Q1 2025)
CPU: Intel Xeon D-2146NT (8c/16t)
Memory: 512GB
Storage: 1 x M.2 (Additional 1 x M.2 possible with PCIe Add-in-Card or 2 x M.2 possible with AOC-SLG3-2M2)
Max Devices: 3
Network: 2 x 10GbE, 2 x 10GbE (SFP+), 4 x 1GbE, 1 x 1GbE (IPMI)
VMware HCL: Yes (supports up to vSphere 7.0 Update 1)
which one you recommend:
1-https://www.amazon.com/gp/product/B07JN5T2RT/ref=ox_sc_saved_title_6?smid=AEELF2HAVZFED&psc=1
2-https://www.amazon.com/gp/product/B07RCN114X/ref=ox_sc_saved_title_5?smid=ATVPDKIKX0DER&psc=1
Comments are closed.