
One item we noticed while running AMD Ryzen chips is that the cache reported by lscpu is incorrect with Ryzen. AMD Zen has L3 cache that is split into two hemispheres per four cores. That means on the launch AMD Ryzen 7 chips, if you are programming an application that is meant to fit into L3 cache, your scripts will need to change.
We have one of the most popular, if not the most popular, Monero cryptocurrency Docker mining image around with tens of thousands of pulls. On Intel Core i3, Core i5, Core i7, Xeon E3, Xeon E5, Xeon E7 and Xeon D systems, the general rule is to use L3 cache / 2MB as a number of threads as the miner is designed to fit completely in L3 cache. On Atom based Intel architectures (e.g. Xeon Phi and Atom CPUs) you would instead use the number of threads or number of threads minus 1 to get the best results. When we ran AMD Ryzen through our Monero benchmarks, we used both Docker images to quickly gauge which was the best for performance. We ran into an issue, L3 cache is reported incorrectly.
There is 16MB L3 cache onboard but lscpu will report 8MB. Here is a screenshot from Ubuntu on kernel 4.10.1:
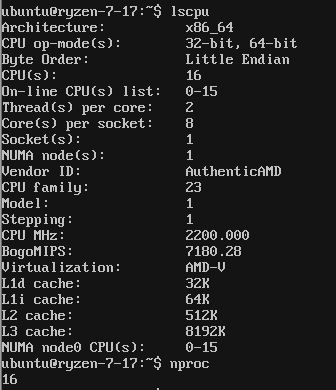
Here is the same from CentOS 7.3 with kernel 4.10.1:
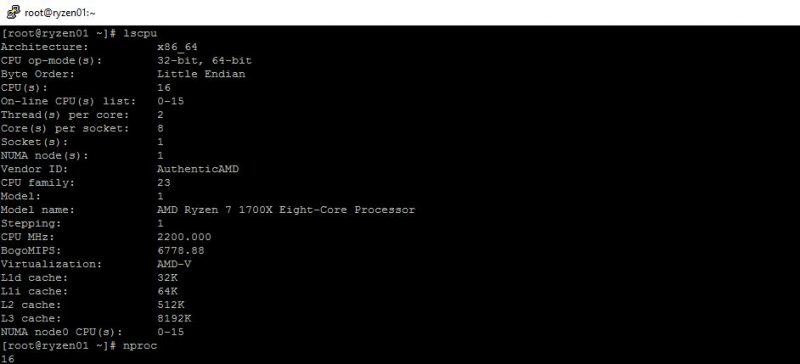
As you can see, only 8MB L3 cache is being reported (this is using the latest stable Linux Kernel 4.10.1.) The net impact is that our popular Docker image that is parsing that figure and dividing by 2MB to get the number of threads was only utilizing 4 threads instead of 8 that it should.
For now, the impact is relatively minor. Tools such as nproc and lscpu are reporting the proper number of cores, but for those with problems that are set to fit in L3 cache, your scripts will need to be updated. We expect that this is something that will be patched in future releases. The impact is fairly large. We created a test Docker image at servethehome/monero_ryzen_xmrpool (you can substitute that in instructions found here), with updated logic and the difference was dramatic. The performance speedup was on the order of 2x just by fixing our logic due to how the L3 cache is reported. For those looking to AMD Zen architectures such as Ryzen and the upcoming AMD Naples platform, this is a minor difference that will have big impacts for some users. We are not sure if this is a “bug” or just a different way of reporting but for now, the Ryzen ratio is 2MB per core or 1MB per thread of L3 cache.



{kind=link}
As the L3 is a victim cache and not inclusive, do you observe better performance if you set to 2.5MB per core?
That may have to do with how the l3 cache is distributed, given that for one ccx (4c/8t) you have 8mb of l3, and connect with the other 8mb from the other ccx via the infinity fabric.
So there are probably a few implications here with regards to memory latency, PCIe lanes etc. as well, given that it’s basically 2 4 Core CPUs in a single chip?
We tried it from 1-16 threads and it was still 2MB per thread in our test for best performance.
It likely is the case. For those running scripts with Zen where they are pulling L3 cache sizes, the misreporting will still impact them.