Intel Xeon Gold 5217 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. Starting with our 2nd Generation Intel Xeon Scalable benchmarks, we are adding a number of our workload testing features to the mix as the next evolution of our platform.
At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
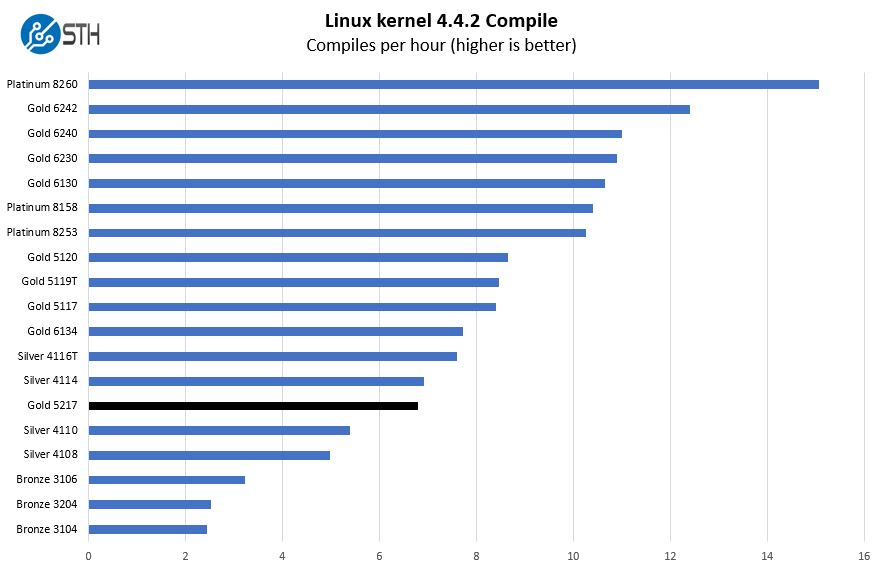
Results here are solid with performance closer to 10 core Xeon Silver parts. Frankly, this is one test that we expected slightly better performance from the Intel Xeon Gold 5217, but it fell slightly behind our expectations across test runs.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
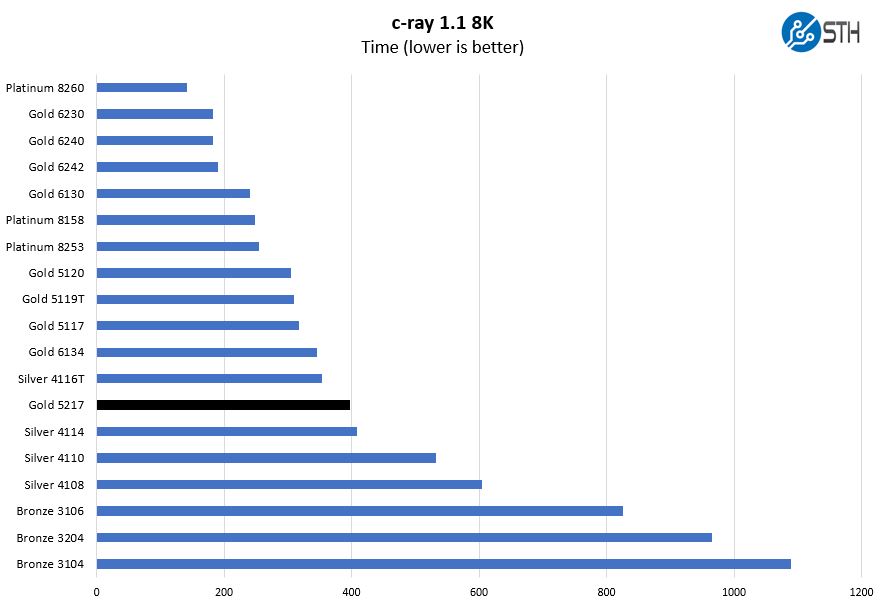
Here we see the part in the range that we would expect. Originally we were expecting that the Intel Xeon Gold 5217 and the Intel Xeon Gold 6134 would be a bit closer together in terms of performance. Here we can see both placing around the level of 12 core lower-clocked parts which makes sense.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
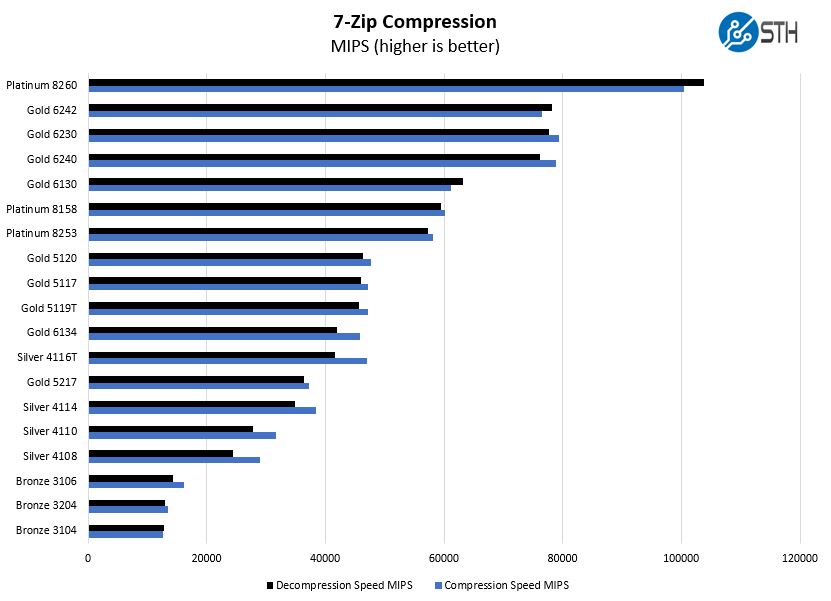
Our compression testing shows something important. Here, one can see the Intel Xeon Gold 5217 is a major digression in performance for the 5×17 parts versus the Intel Xeon Gold 5117. The Intel Xeon Gold 5117 was a 14 core part and so in tests where multi-threaded performance matters most, the additional execution units help tremendously.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench in the near future. With GROMACS we have been working hard to support Intel’s Skylake AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
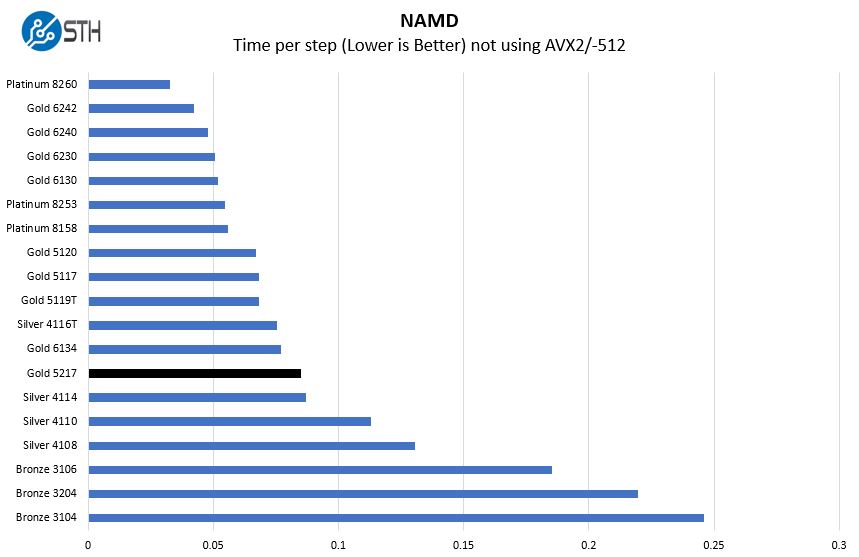
Again, here we see performance close to the Intel Xeon Gold 6134 and well below the Intel Xeon Gold 5117 due to the factors mentioned above.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
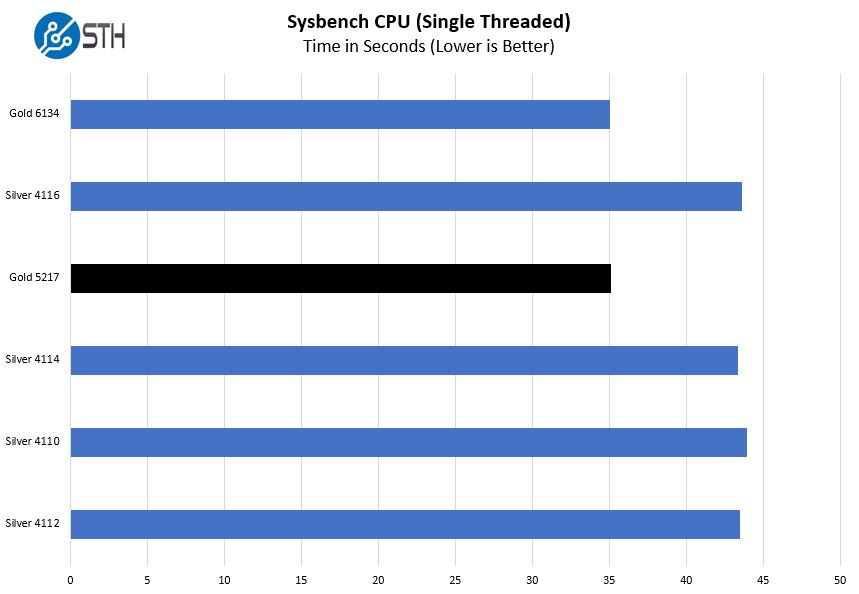
We wanted to quickly highlight single-threaded performance using our sysbench CPU test. Here, one can see performance of the 3.7GHz turbo clock part in-line with the Intel Xeon Gold 6134 and significantly faster than the 3.0GHz maximum Intel Xeon Silver 4100 series.
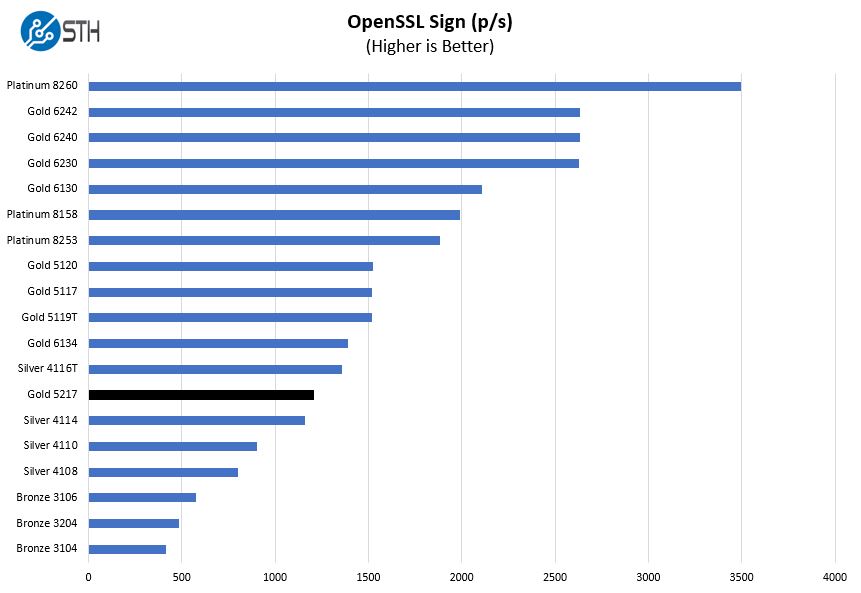
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
Here are the verify results:
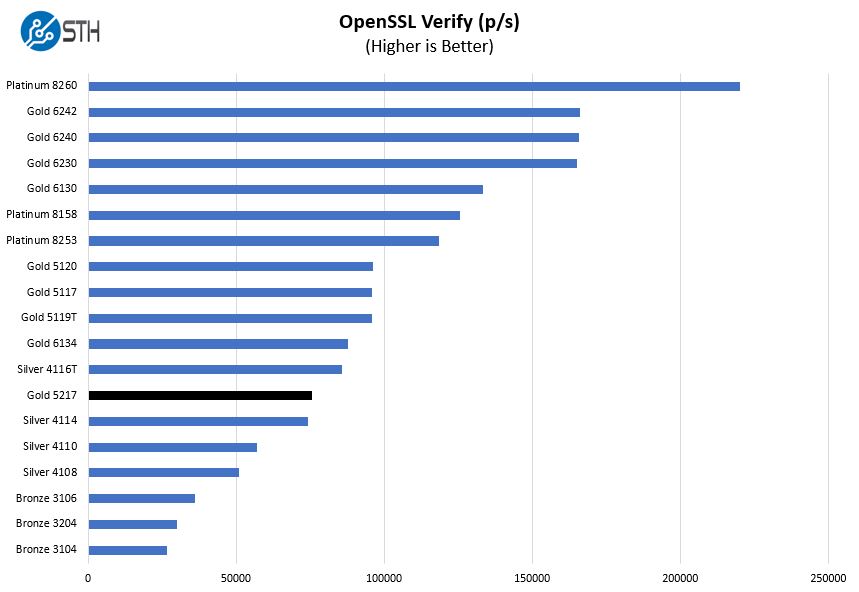
OpenSSL shows more of the same with more performance than 10 core previous-generation CPUs but well behind the 14-core Intel Xeon Gold 5117.
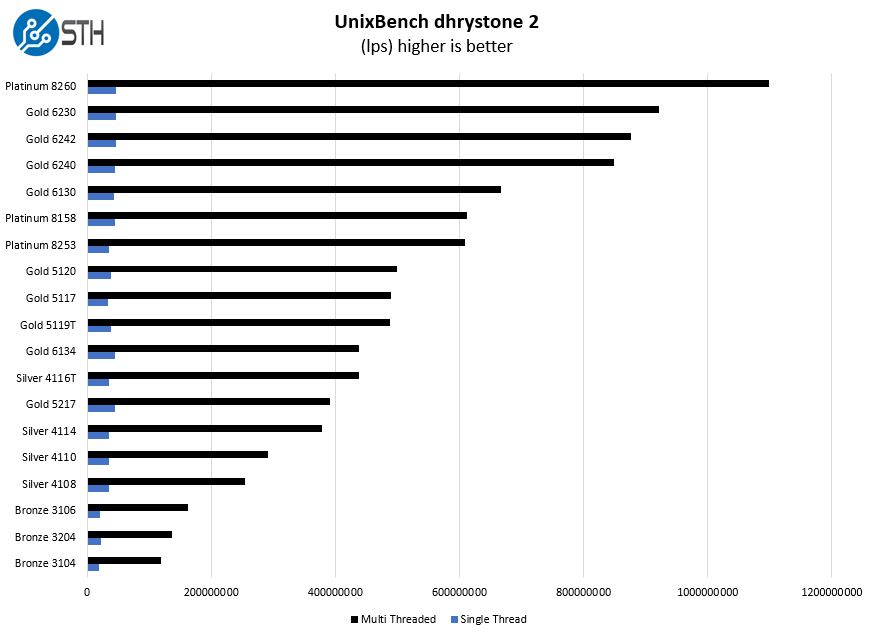
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
Here are the whetstone results:
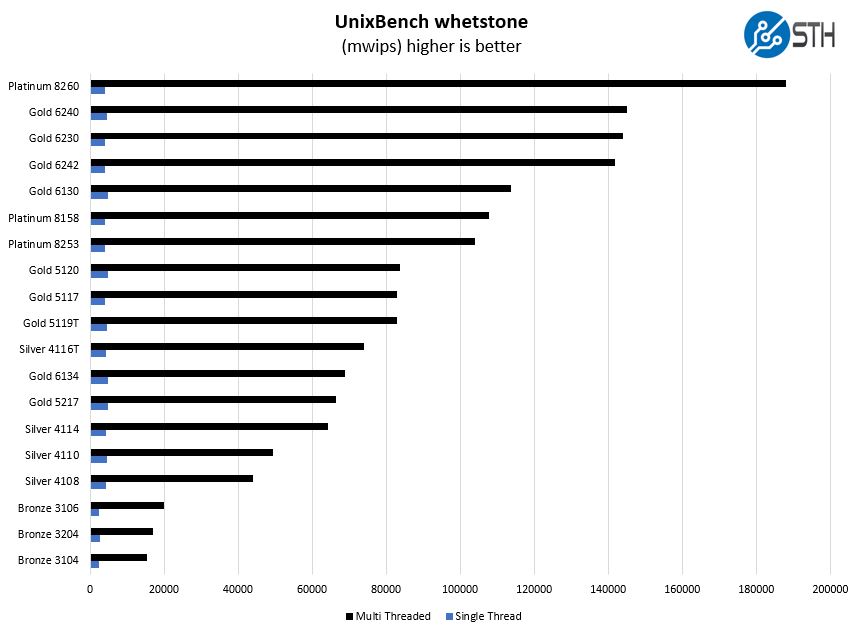
If we direct our attention to the single-threaded dhrystone 2 tests, we can see great single threaded performance in-line with the Gold 6134.
GROMACS STH Medium AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using our “small” case which is appropriate for single-socket servers. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
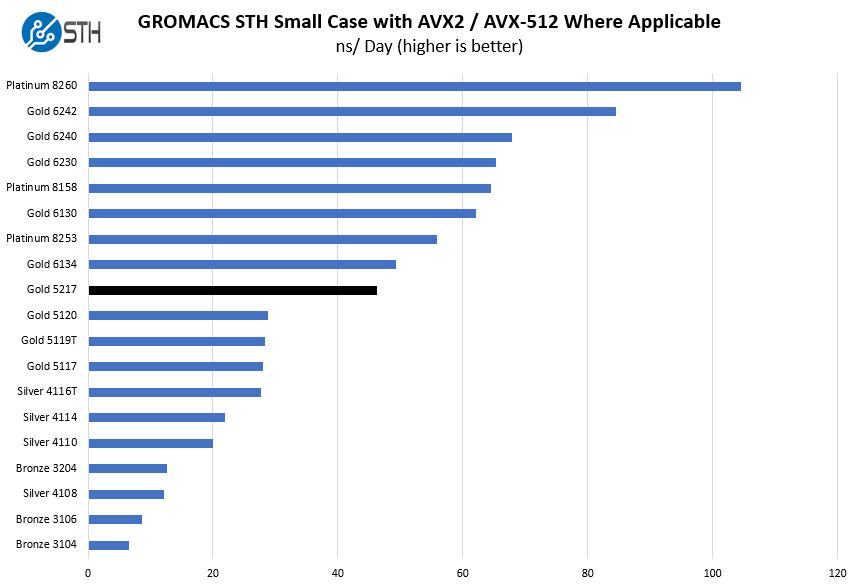
As a quick note here, this is a good example of a trend we are seeing and we discussed in our recent Intel Xeon Bronze 3204 Benchmarks and Review as well as our initial 2nd Gen Intel Xeon Scalable Launch Details and Analysis piece. The Intel Xeon Gold 5200, Silver 4200, and Bronze 3200 series CPUs have much better performance on our AVX-512 workload than their previous generation counterparts. Indeed, when we did our Intel Xeon Gold 6134 Benchmarks and Review we showed how the dual port FMA AVX-512 implementation on the Xeon Gold 6134 allowed it to be significantly faster than higher core count Gold 5100 series parts.
With the Intel Xeon Gold 5217, we see performance in-line with what an Intel Xeon Gold 6134 would look like if it had slightly lower clocks/ TDP. For the record, Intel confirmed to STH on April 2, 2019 that the Gold 5200 series has a similar AVX-512 implementation as the Gold 5100 series despite what we are seeing here.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and now use the results in our mainstream reviews:
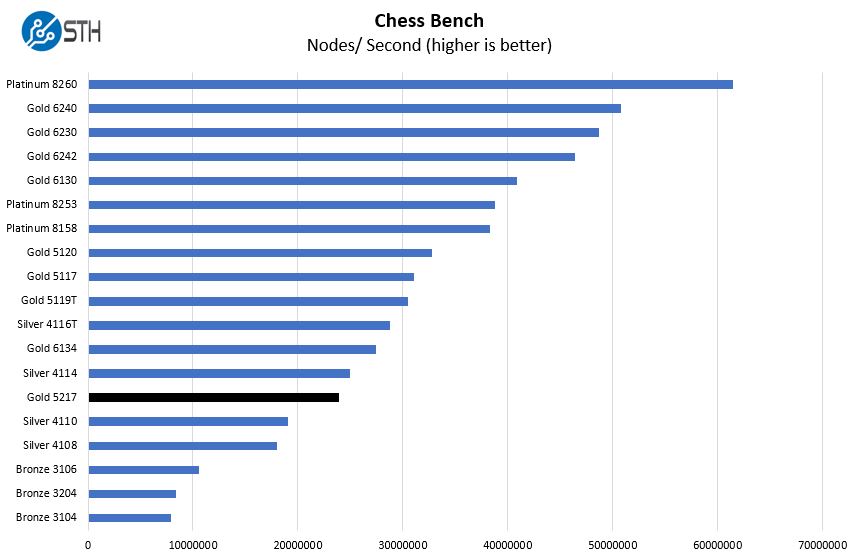
On our chess benchmark, the Intel Xeon Gold 5217 is naturally limited by only eight cores, even if they are higher-speed.
Next, we are going to discuss market positioning before our final words.


{kind=link}
As if the lineup wasn’t confusing enough already with the first generation Xeon SP