Testing Intel QAT Compression
We are going to ease into this one. We need a few things to get this working. Here we are going to look at five cases compressing the Calgary Corpus. This is a well-known old data set of data to compress. What we are going to do is use Intel’s QATzip which you can find on Github. We are also going to be using Intel’s ISA-L (Intelligent Storage Acceleration Library) also on GitHub. We are doing this specifically to have the ability to use one program and hook in the QAT hardware accelerator. For those that assume that just because we are using Intel projects for QAT, AMD’s performance is going to be poor, hold that thought for the discussion of the results.
What we are showing is a view of running five cases:
- Intel Ice Lake Xeon Gold 6338N with:
- No ISA-L nor QAT (base case)
- ISA-L
- QAT Hardware Acceleration
- AMD EPYC 7513 “Milan” with:
- No ISA-L (base case)
- ISA-L
We are going to express these in two ways, one is looking at performance and the number of threads used:
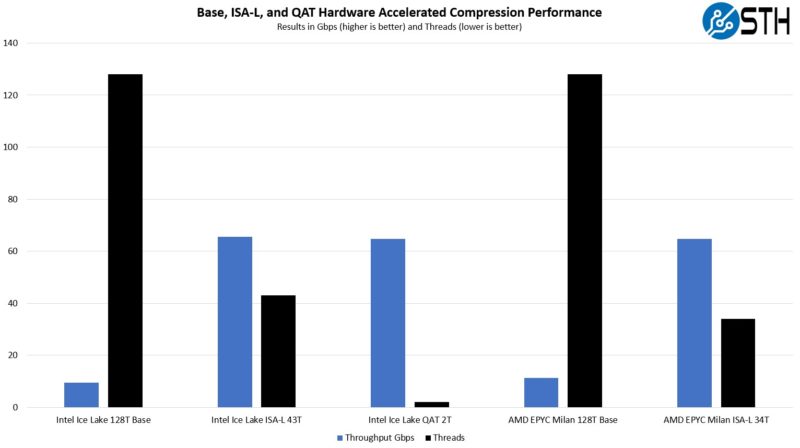
As we can see with the base case, the AMD EPYC 7513 using all 128 threads actually performs noticeably better (19-20%.) Part of that is architecture, the other part is the fact that we are using higher TDP AMD parts than Intel parts to offset adding the QAT accelerator card later.
We can also see that ISA-L compression performance is again better with AMD EPYC. We targeted around 65Gbps and then manually searched for how to best get there using the fewest threads possible on both Intel and AMD platforms. With AMD, we used 34 threads, with Intel it took 43 threads. Again, AMD has a TDP advantage, and we are not using the QAT hardware accelerator.
Using the Intel QAT 8970 hardware accelerator takes only 2 Ice Lake Xeon cores to get to that ~65Gbps mark.

Here is the second is by looking at the throughput per thread:
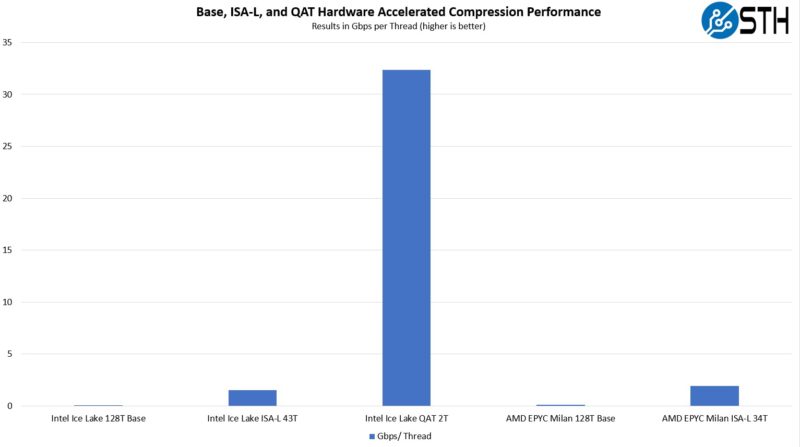
As you can see, the ISA-L is a big improvement in either Intel or AMD, but the QAT hardware acceleration gap is absolutely massive. To put it into perspective, we got about 21x better performance per thread using ISA-L, then another 21x improvement in throughput per thread using QAT.
Realistically, we are calling this a 2 thread result, but the actual usage was closer to 1.25-1.3 threads but we were not running other loads on the system to compete on that second thread so we are assuming a dedicated thread there.
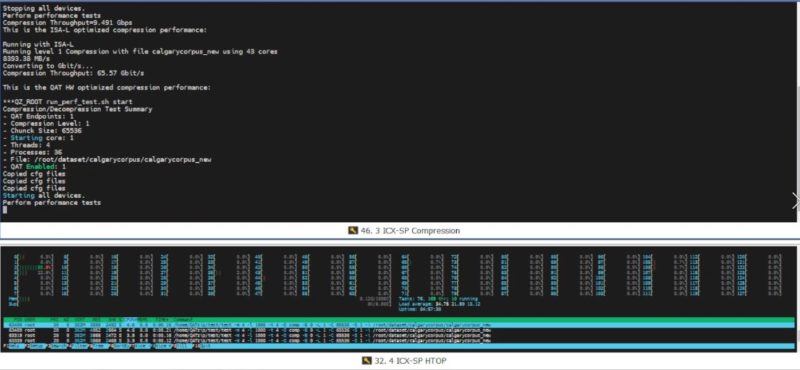
For those wondering how we got to 43 threads on Intel and 34 on AMD, we searched thread placement combinations to get the best possible for each. There may be some optimization left on the table, but this really shows the impact of both software optimizations as well as hardware. It was interesting to see AMD EPYC do well before the QAT accelerator was added because this is exactly the strategy we discussed Intel was going after in More Cores More Better AMD Arm and Intel Server CPUs in 2022-2023.
QAT hardware powers compression for a number of commercial storage vendors. My go-to example is Dell EMC PowerStore. Storage vendors figured out this QAT offload years ago, and the cost is relatively minimal in many cases. Offering storage compression using QAT became very inexpensive because of this type of hardware acceleration.
Next, let us look at the crypto side and look at the IPsec VPN performance.


{kind=link}
I’m going back to read this in more detail later. TY for covering all this. I’ve been wondering if there’s updates to QA. They’re too quiet on the tech
IPsec and TLS are important protocols and it’s nice to see them substantially accelerated. What happens if one uses WireGuard for a VPN? Does the QAT offer any acceleration or is the special purpose hardware just not applicable?
Hi Eric – check out the last page where WireGuard is mentioned briefly.
How about sticking a QAT card into an AMD Epyc box? Would be nice to see how this works and get some numbers.
I came here to post the same thing that Herbert did. Is this more ‘Intel Only’ tech or is it General Purpose?
Also, what OS’s did you test with? It’s obvious that you used some flavour of Linux or BSD from the screenshot, I’d like to know specifics.
It would be also interesting to know if Windows Server also saw the same % of benefit from using these cards. (I’m a Linux/BSD only sysadmin, but it would still be nice to know.)
I don’t think QAT on EPYC or Ampere is supported by anyone, no?
I thought I saw in the video’s screenshots they’re using Ubuntu and 22.04.x?
Some of the libraries are available in standard distributions, however it seems you must build QAT engine from source to use it, there are no binary packages. I think this limits the usability for a lot of organizations. I would be especially wary if it’s not possible to upgrade OpenSSL.
Comments are closed.