Intel Pentium Gold G5420 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
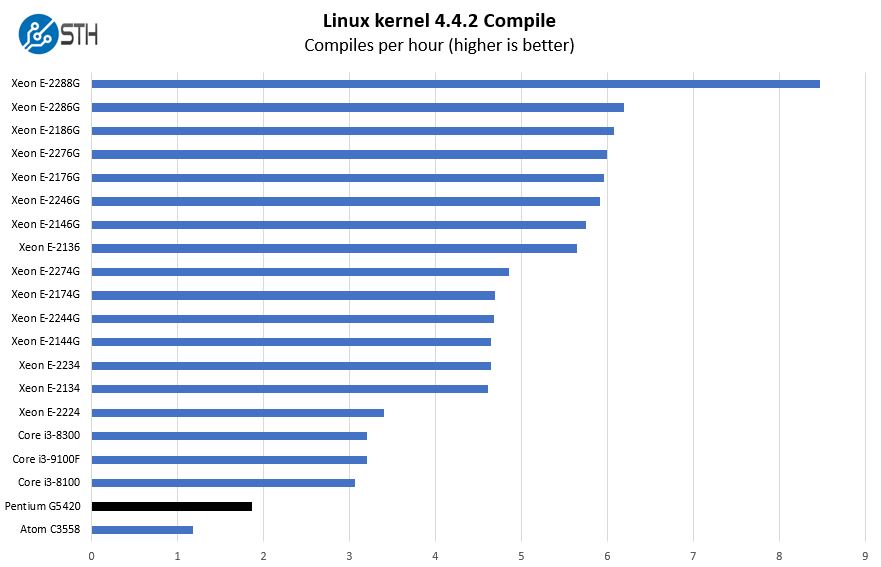
In our recent Intel Xeon E-2200 series coverage, we have focused on in-socket performance. We now have a considerable number of data points to compare with. As you can see, the Intel Xeon E-2224 provides a lot more performance, almost 2x, so we are going to add a few more comparison points here.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
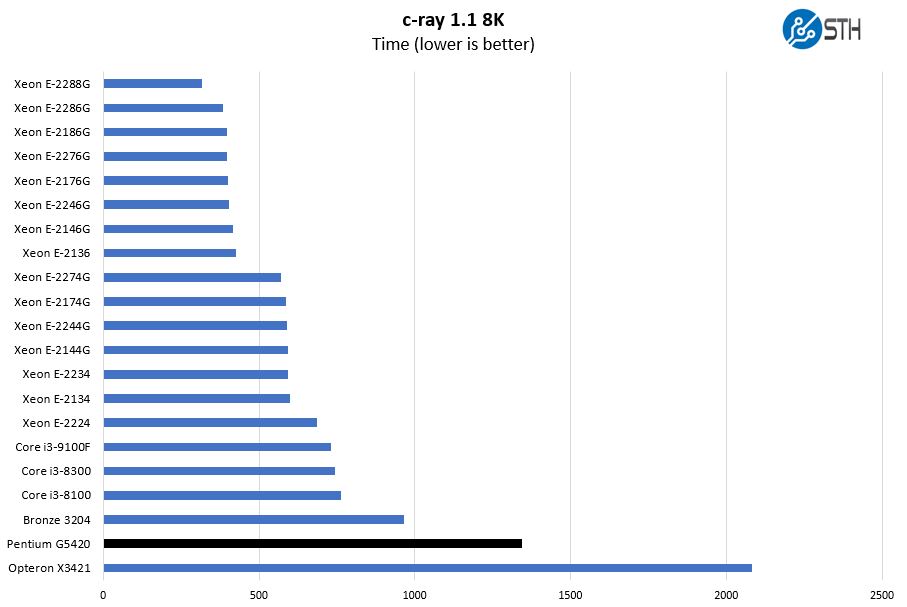
The c-ray 8K render test we added the Intel Xeon Bronze 3204 simply to show something we saw that was interesting. These are both fairly low-performance SKUs from their respective sockets and the Pentium G5420 is slower, but not by an enormous amount. Clock speed has a lot to do with this result.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
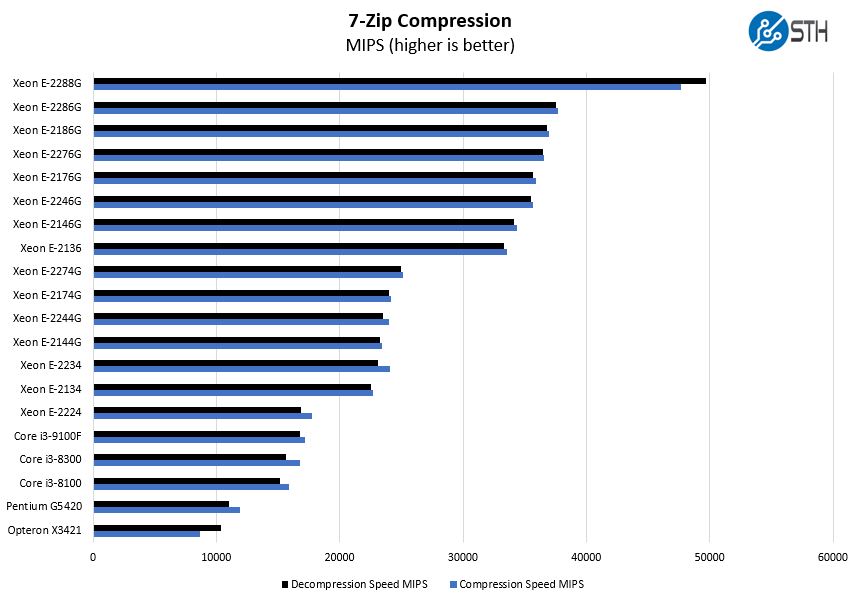
Steps up for servers involve the Intel Core i3 series. Intel positions the Core i3 with models supporting ECC memory as low-end server CPUs below the Xeon E series. As one can see, moving to four full cores instead of two cores and two Hyper-Threads has a large impact here.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench in the near future. With GROMACS we have been working hard to support Intel’s Skylake AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
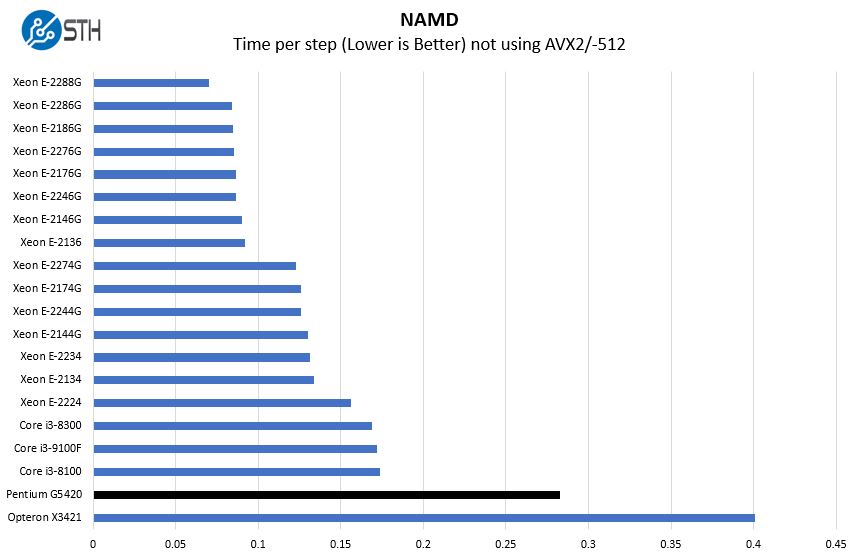
One may also notice the AMD Opteron X3421 in many of these charts. That is an embedded SoC, also with an integrated GPU. It is the top-end CPU in the HPE ProLiant MicroServer Gen10. We are showing it here because it is being replaced by the Pentium G5420 as the low-end option of the Gen10 Plus. You can read more about the differences in our HPE ProLiant MicroServer Gen10 Plus v Gen10 Hardware Overview.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
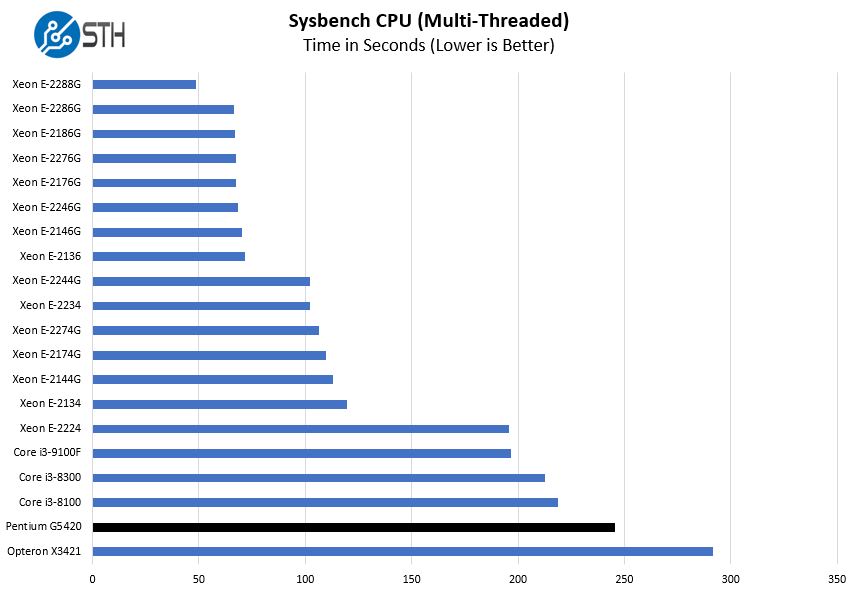
A good point here is that the Intel Core i3-9100(F) is only about $33 more than the Pentium Gold G5420. $33 for some at the low-end of the market is a large amount but to others, this represents a relatively small amount for upgrading performance to this degree. In mainstream Xeon Scalable, one cannot get 20-30% more performance for only $33.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
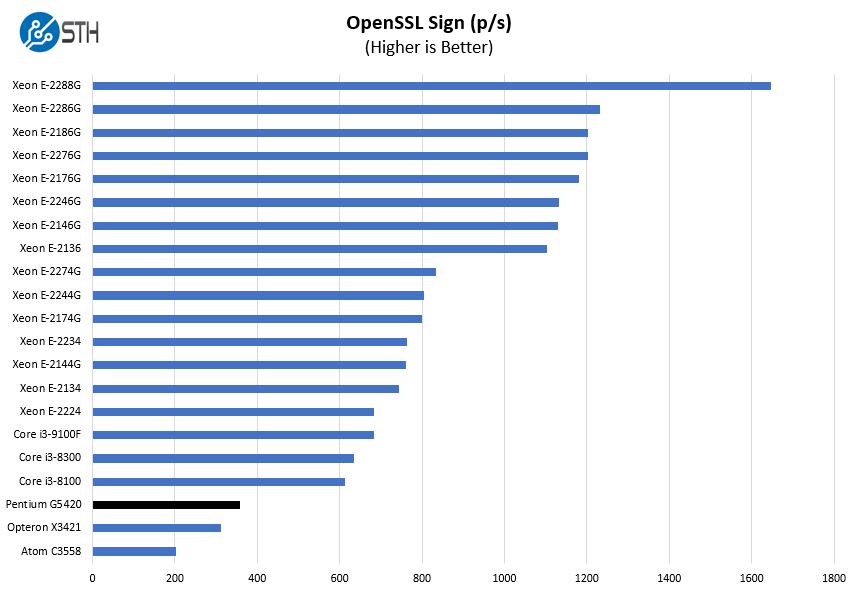
Here are the verify results:
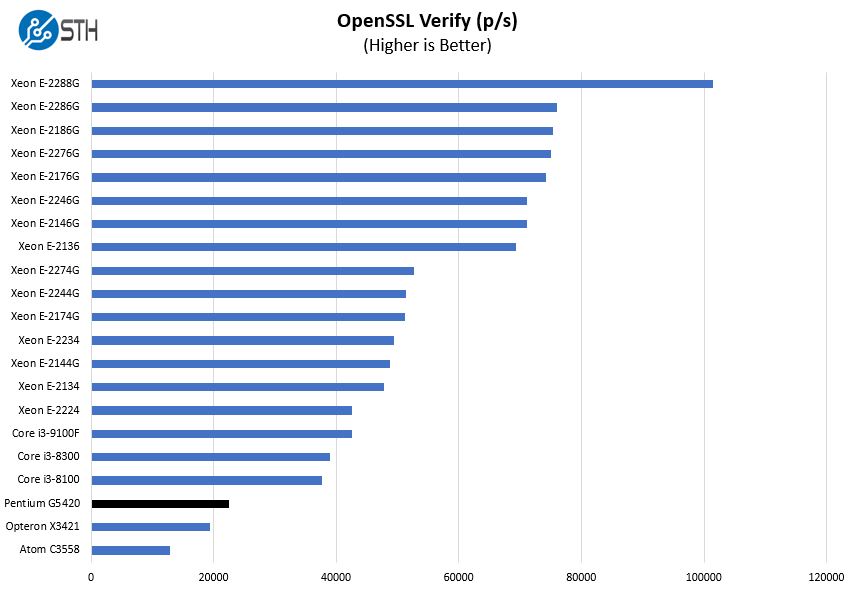
Here we added both the AMD Opteron X3421 and the Intel Atom C3558 SoCs. The Atom C3558 is a lower-clock speed power-optimized SKU with four cores and threads. In many cases, such as this, we are getting 75-90% more performance with the G5420.
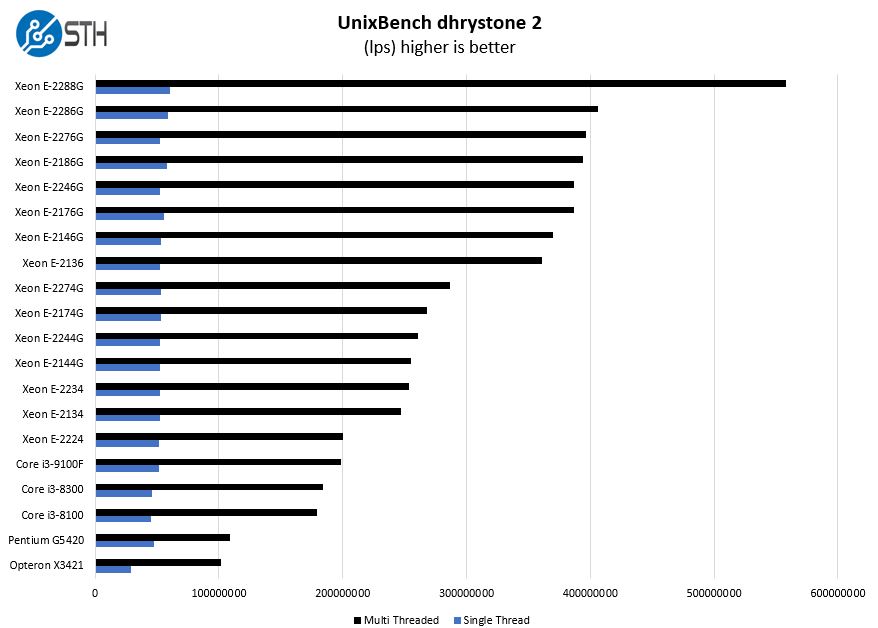
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
Here are the whetstone results:
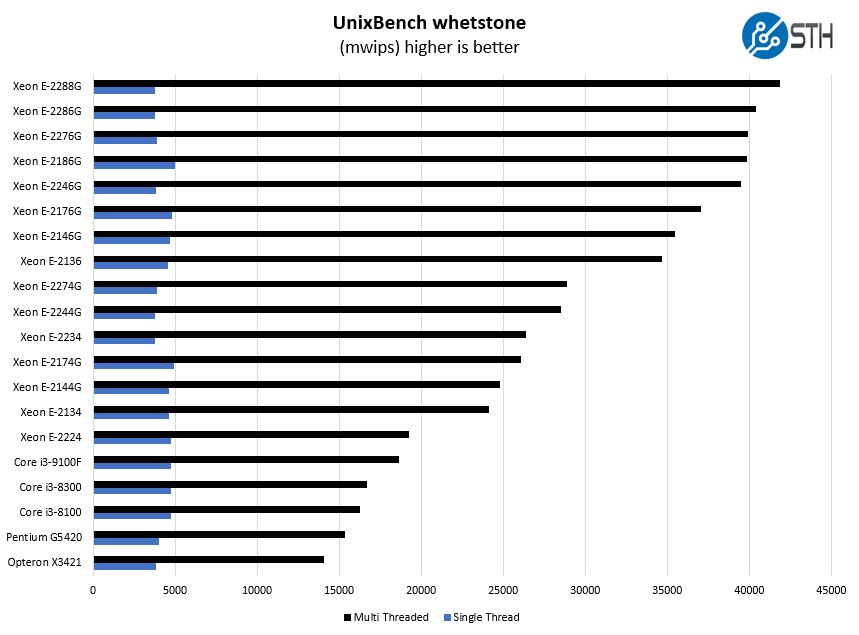
Although the Pentium Gold G5420 normally performs much better than the Opteron X3421, it is not always the case. Here we can see appreciable performance gains but the Pentium Gold G5420 is also a higher-power CPU. We see the Opteron X3421 as being somewhere between the Atom C3558 and the Pentium Gold G5420.
GROMACS STH Small AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using a “small” test for single and dual socket capable machines. Our medium test is more appropriate for higher-end dual and quad-socket machines. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
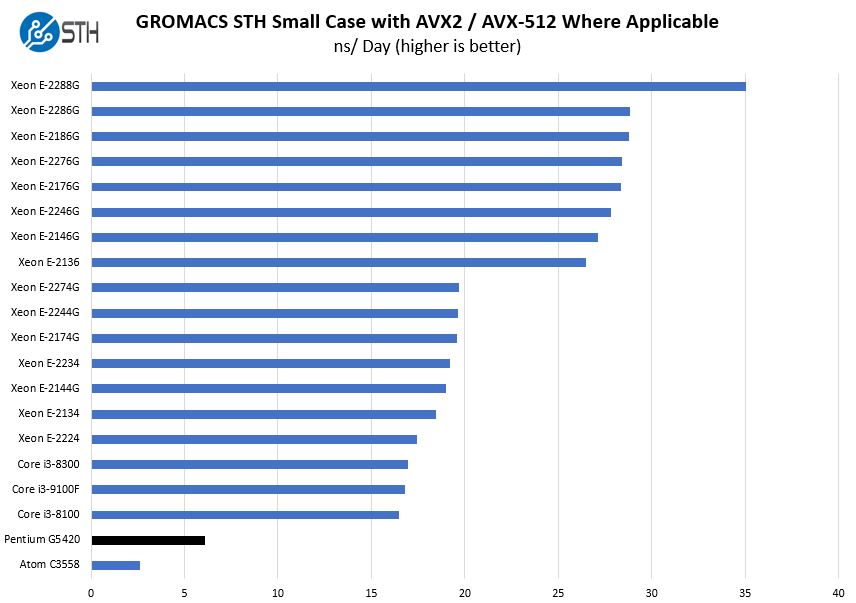
Then we get to a test where we see the impact of a 12-year old SSE4.2-level instruction set. Here, the Pentium G5420 does not have access to features such as AVX2 and AVX-512 which mean performance is about a third of what we see on the Core i3 side. Of course, one is unlikely to purchase a low power and cost chip like this for GROMACS, however, this is a great example of the impact we see with the older instruction set.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
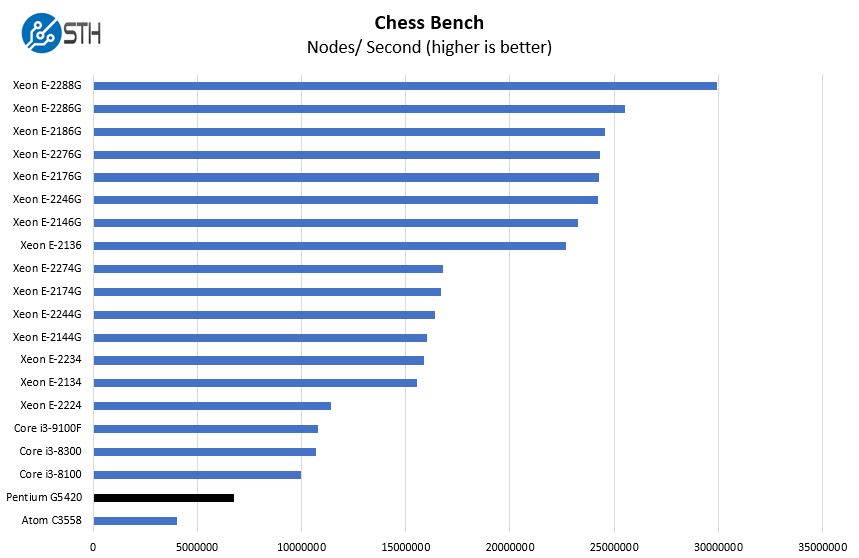
Performance again here falters as this test needs to use the popcnt rather than the bmi2 instructions. This is a smaller impact, but another one that is due to the reduced instruction set in the Gold G5420.
Next, we are going to have power consumption, market positioning, and our final words.


{kind=link}
Didn’t realize Intel had given these Pentiums AES acceleration finally. I might just use this CPU in my next PFSense box.
54w processor for small business or home small server?
That not very appealing
yawn, you two.
IMO, AMD just need to clone some Ryzen 3000s consumer CPUs and put some server features more appealing: ECC support, high DIMMs density, crypto accel. etc. I have no doubt these Pentium “Gold” will looks blant compared to Ryzen 3000s. While Rome is winning at the top end, this is the time they need to fill up the lower end market.
AMD already has the CPUs to compete against this, but there’s a lack of AM4 server boards.
Very likely Intel is aware of the danger ARM hardware poses to the company’s bottom line…
The last sentence in the second to last paragraph is so true. Not enough Epyc/Ryzen servers out there with the big brands. Looking for a 16C Epyc Rome tower and I’m gonna have to use a Supermicro builder or generic workstation builder instead.
Seriously guys…why do you continue to do reviews of intel CPUs which has so many critical security holes, that nobody in right mind would buy and put that in server? Personally(in home), I get rid of everything with intel procesor…from workstations to servers. Only PC with intel procesor left, is old Ivy Bridge Core i7-3700 which I use as gamebox with windows.
Anything can be a server if you define server appropriately.
I have a c50 netbook that functions as an SSH bastion ‘server’ on my home network. It isn’t good for much else.
would it have made sense to compare against some Xeon D processors?
If your goal would be to make a cheap (nas)server or whatever with this cpu you might want to look at another mb since the Supermicro X11SCA- cost in excess of 300$ if you even can get it NEW nowdays, used hw is another matter ofc…
Great point. We are just using a common platform for this testing. The timing of this review was specifically because we had the MicroServer Gen10 Plus review coming a few days later which has a pre-configured model using the G5420.
Thanks for this very informative posting. I just bought a new desktop with then Pentium Gold as my Intel Celeron CPU N3350 1.1ghz laptop was not sufficiently strong for some analytics features. I was looking forward to unboxing my machine but now I kind of feel that I should have gone for a Xeon.
Comments are closed.