Gigabyte R292-4S1 Performance
Unfortunately, we do not have licenses (nor 24x 512GB Optane PMem 200’s) to do top-end performance on SAP HANA or applications like that. Instead, we wanted to focus on performance deltas from the second generation Intel Xeon Scalable 4-socket parts across a few key areas.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
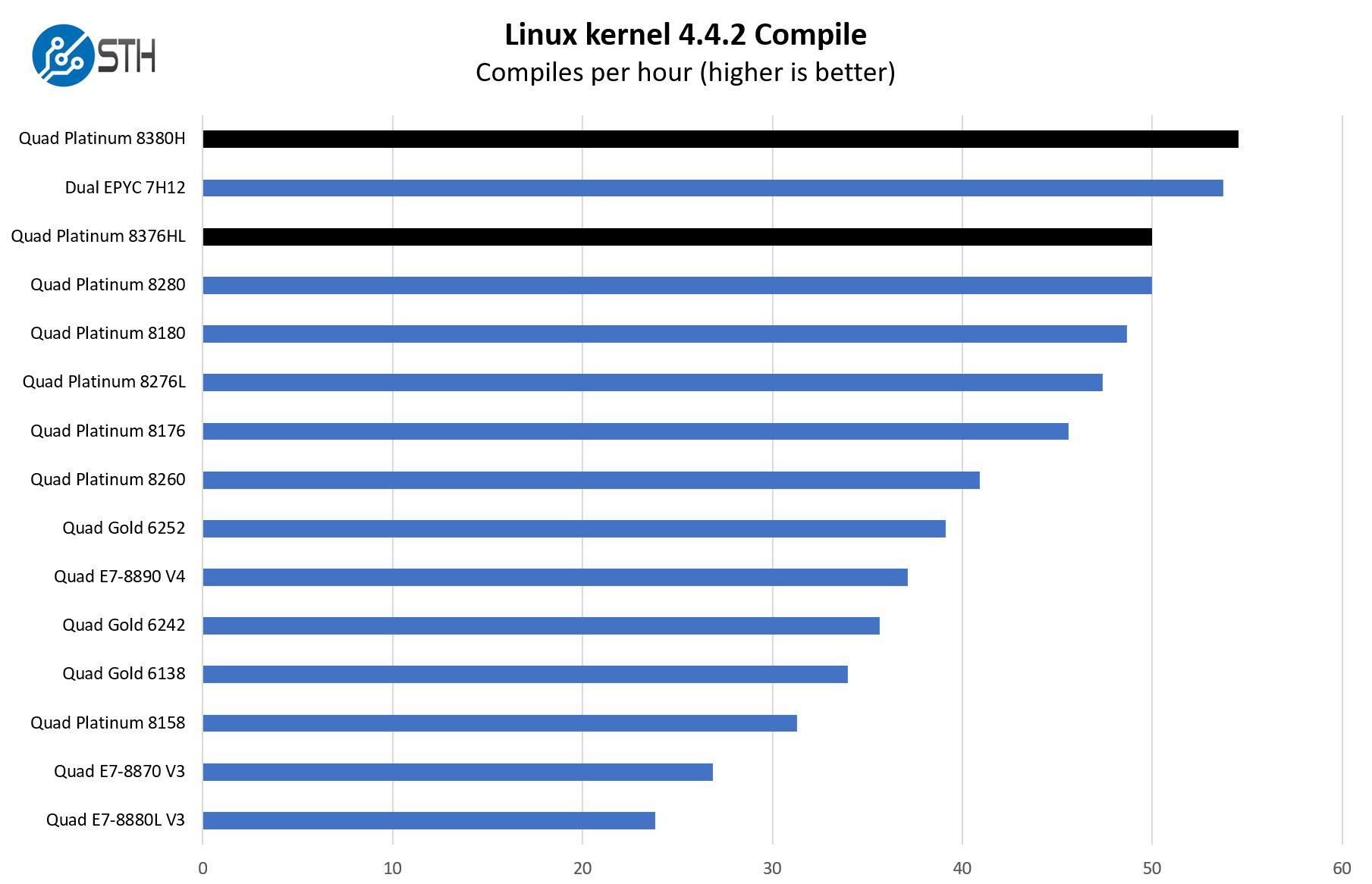
Here we can see the new top-end chips going head-to-head with AMD’s HPC-focused EPYC 7H12 offerings. Still, this is a workload that runs into some short single-threaded performance-bound sections, so we are not getting the full benefit of scaling across cores here. That also leads to compression at the top-end of the chart.
c-ray 8K Performance
Although not the intended job for these, we also just wanted to get something that is very simple and scales extremely well to more cores.
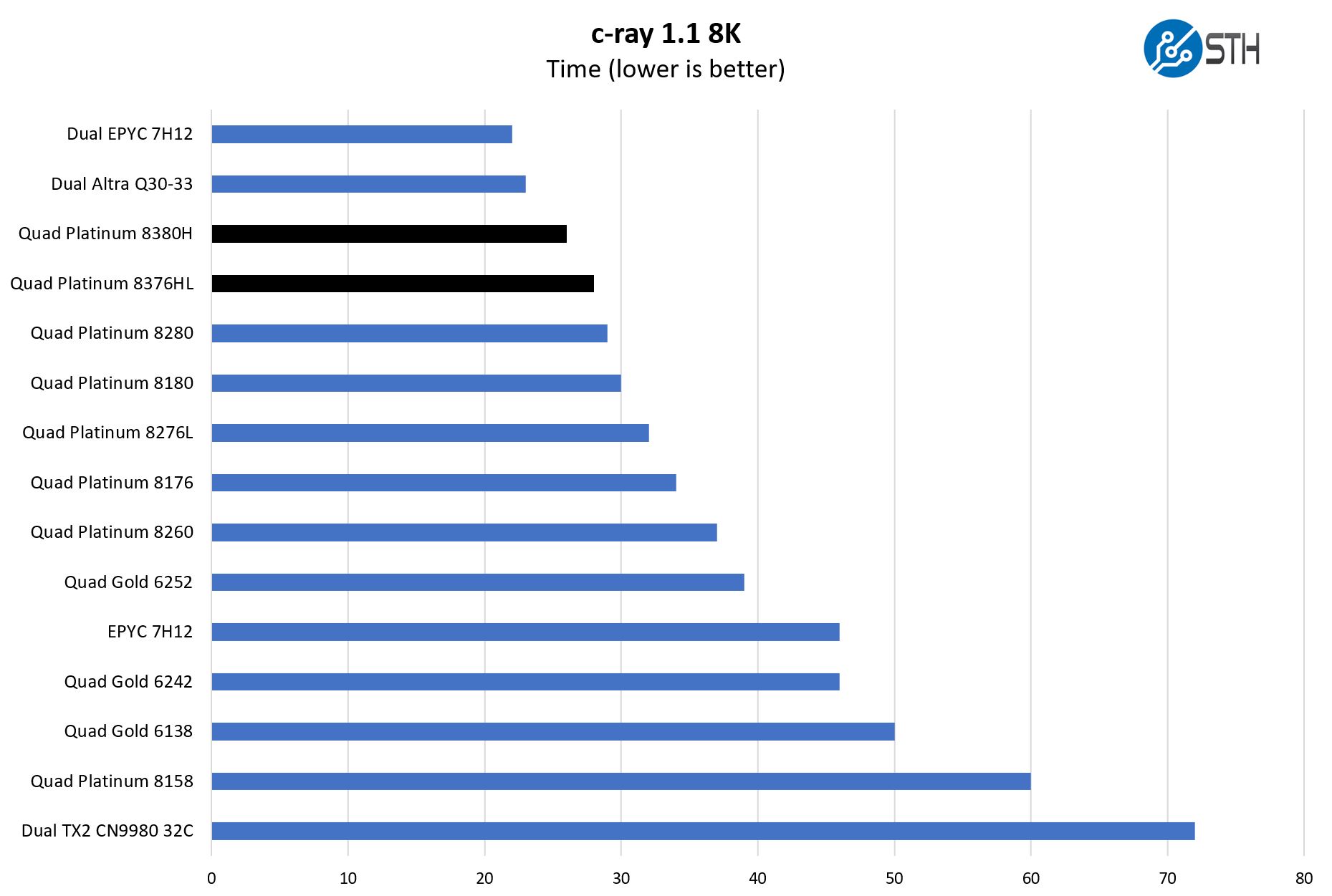
Here we can see the Cooper lake parts out-pace some of the older designs by a significant margin. We also have the dual ThunderX2 32-core and Ampere Altra 2x 80 core results in this chart as well. We will quickly note that this type of test favors more cores, as well as AMD’s architecture, which does well on this type of task.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
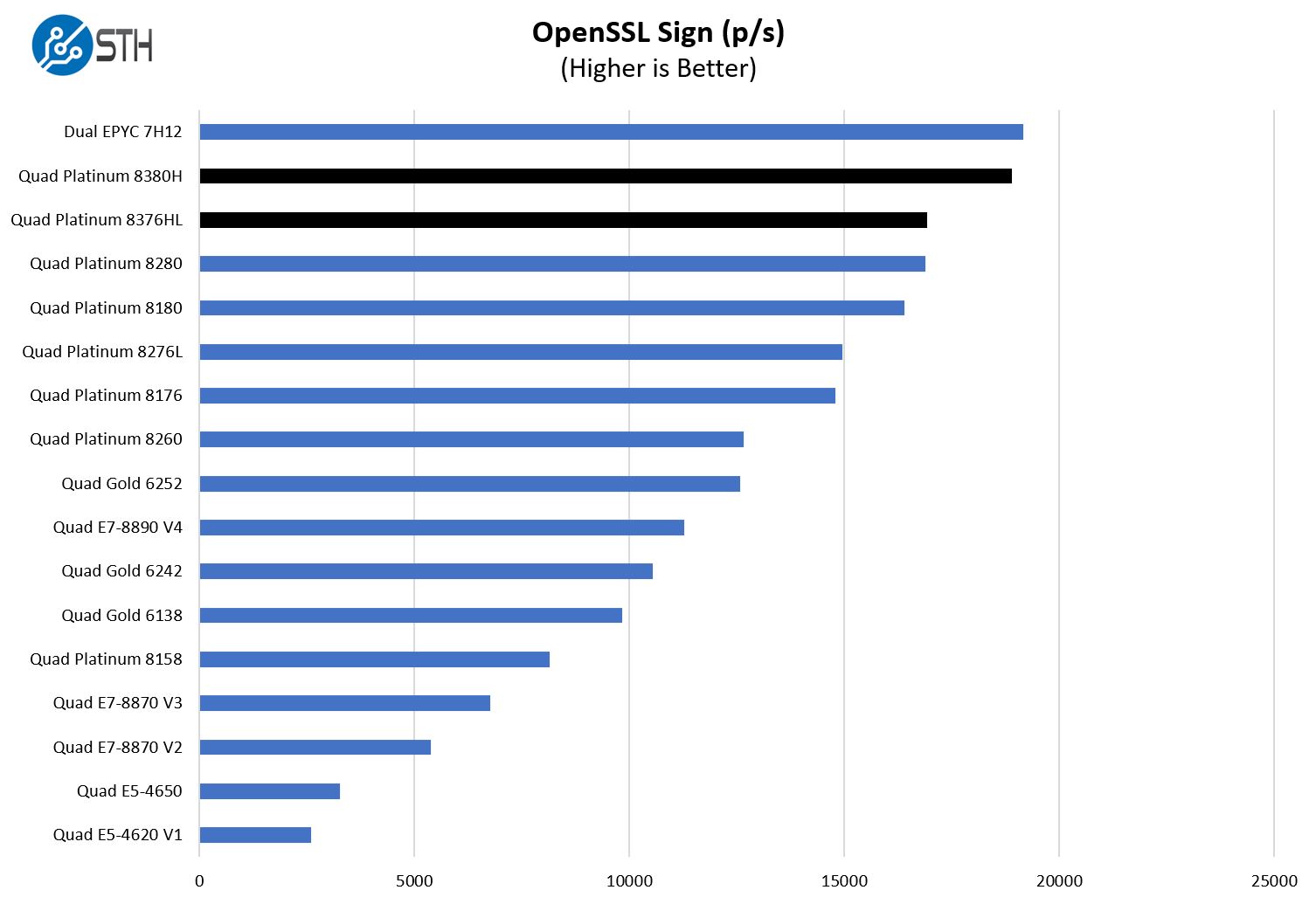
Here are the verify results:
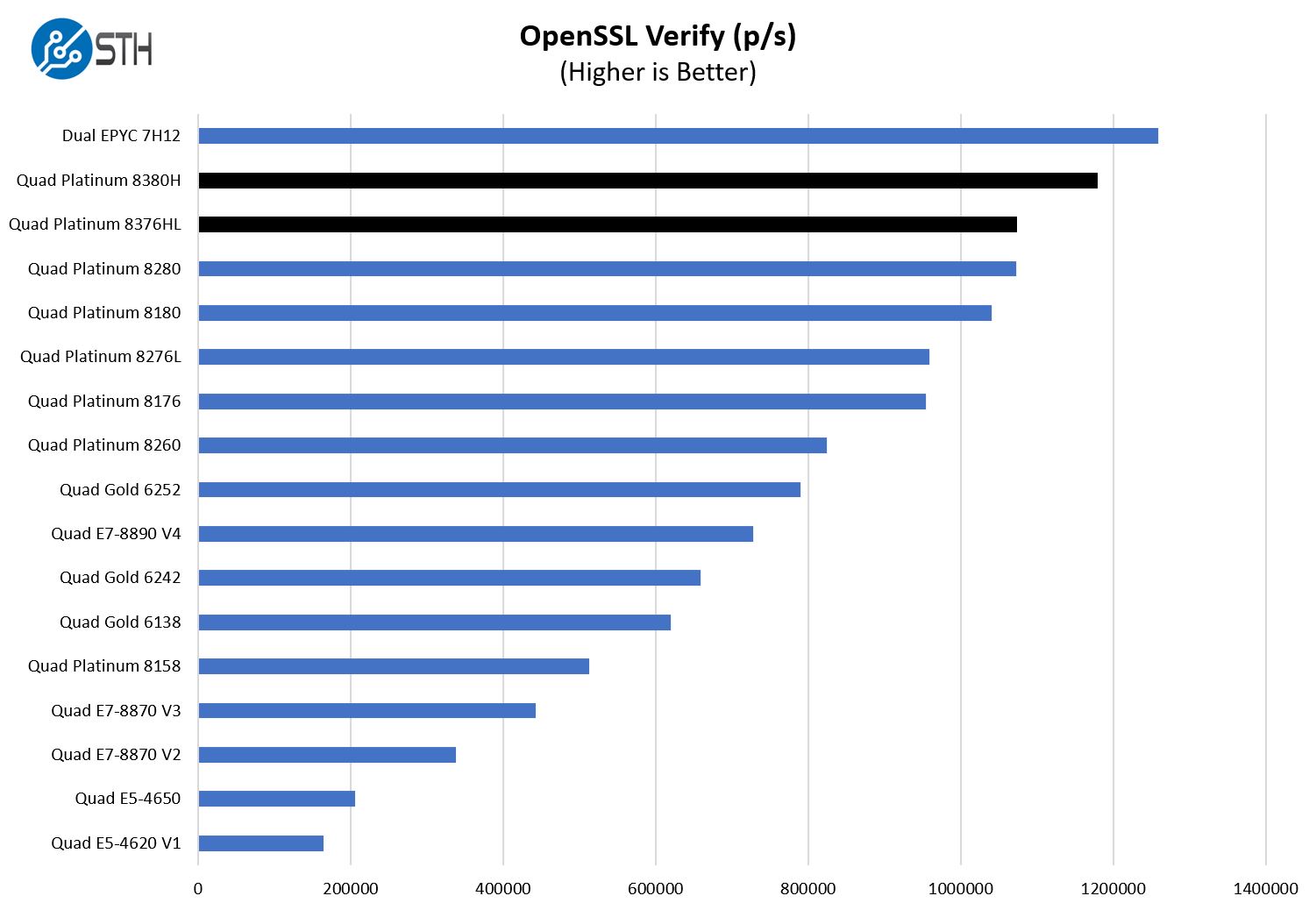
Overall, we can see a nice migration up the stack. The higher TDPs are helping here.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and now use the results in our mainstream reviews:
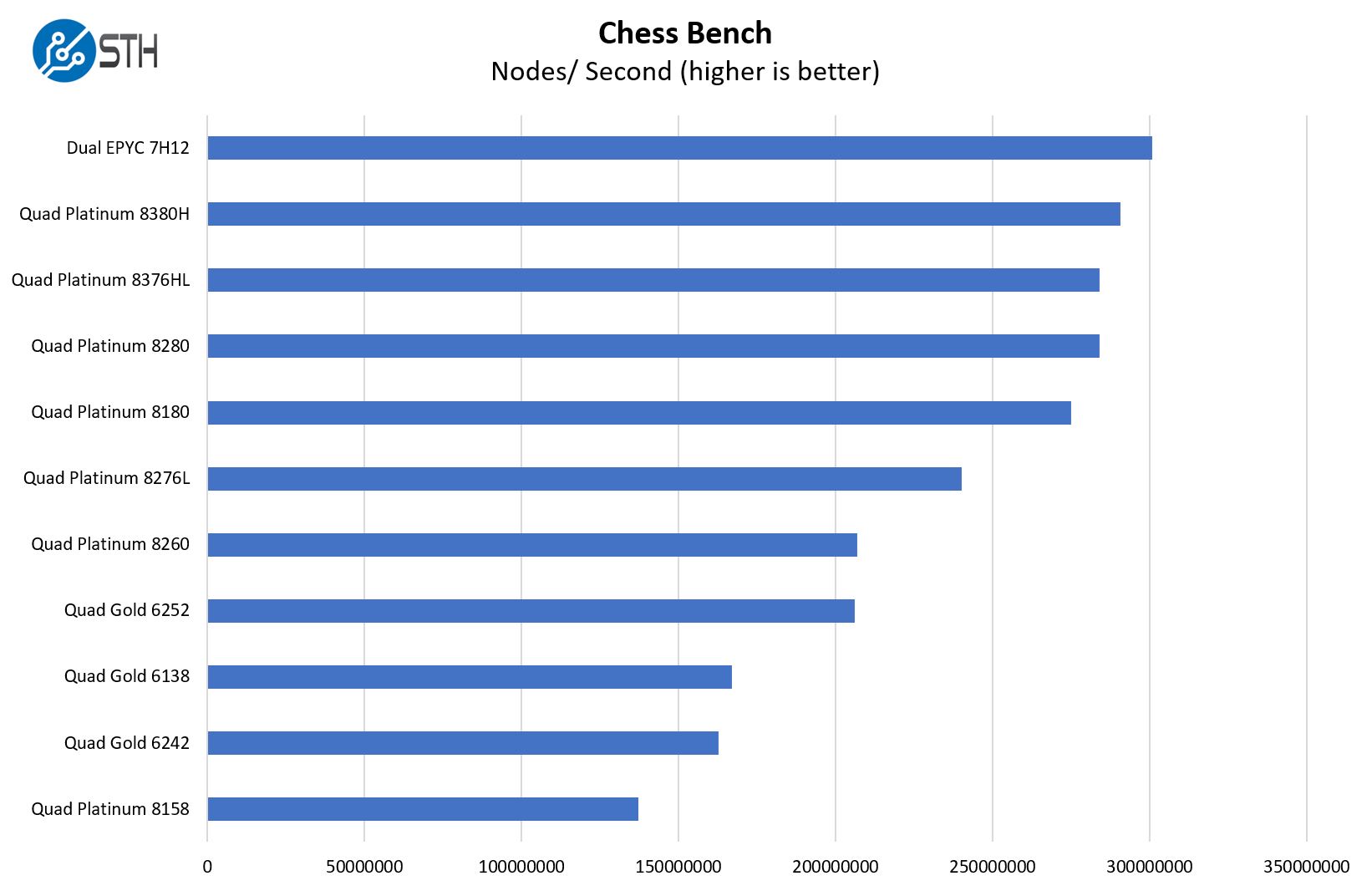
The chess benchmark showed a similar pattern. Here we are seeing clock speed and TDP increases, but not getting as much benefit from the better UPI topology. For that, we need to get to virtualization benchmarks.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker.
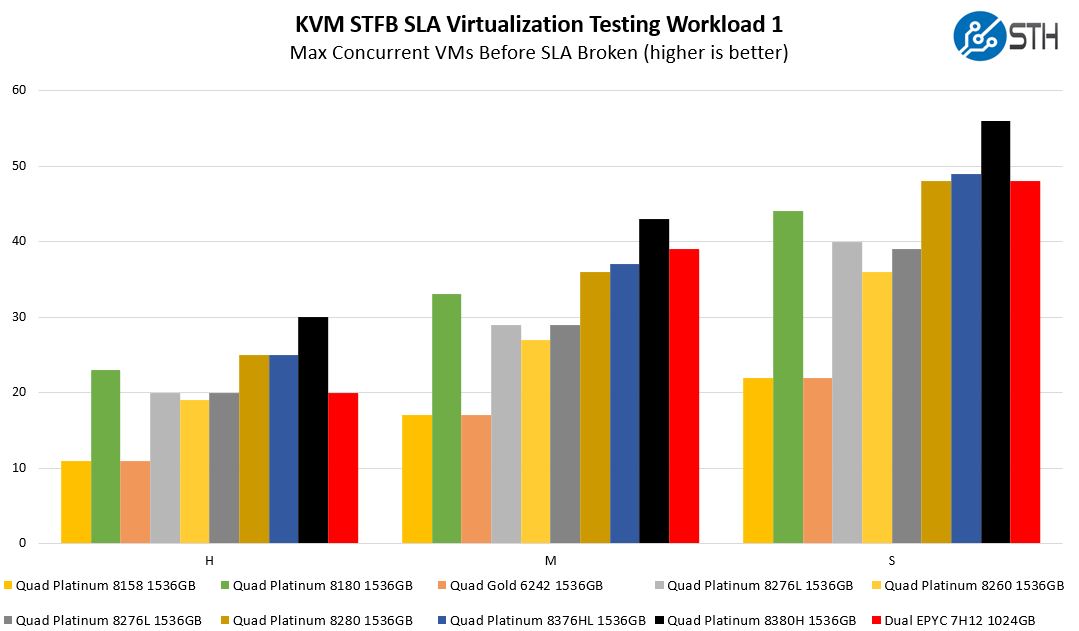
Here what we see is something that is expected, and extremely important. The new Cooper Lake parts are excelling when we get to mixed VM workloads. These are quite a bit different than the micro-benchmarks because they are creating more I/O and churn than we typically see on lower-level tests. Realistically, this is more of what buyers in this segment are looking for. Here we get appreciable gains over the Platinum 8180/ 8280 and 8276L’s with the newer chips. This is clock speed, memory speed, and increased UPI links coming together. One may notice that the AMD EPYC 7H12 trails off a bit here. That is largely due to two factors: the fact that we have more memory bandwidth on the Intel Xeon platform simply with 24x DDR4-3200 v. 16x DDR4-3200 and some of the Rome microarchitectural nuances. We will get to these in the Milan review.
On a more memory capacity bound version (at the ~112 core/ 224 thread level), we get a small but useful insight:
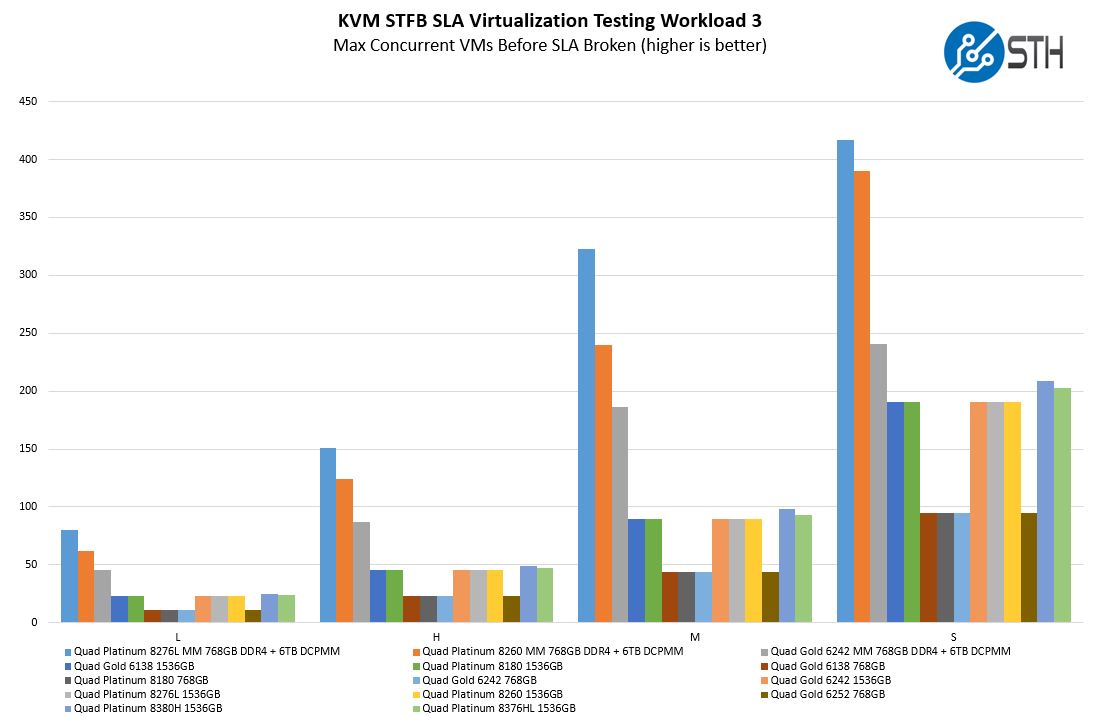
Here we are getting very slight but noticeable improvements with the new version despite being at a memory capacity disadvantage to the Optane configurations. For customers in this segment, this is one of the big drivers to go Cooper Lake over Cascade Lake. What we did not have is a full memory configuration which would push these charts much higher just because of capacity. Again, this is not something that shows up on micro-benchmarks.
SPECrate2017_int_base
The last benchmark we wanted to look at is SPECrate2017_int_base performance. Specifically, we wanted to show the difference between what we get with Intel Xeon icc and AMD EPYC AOCC results and across a few generations.
Server vendors get better results than we do, but this gives you an idea of where we are at in terms of what we have seen:
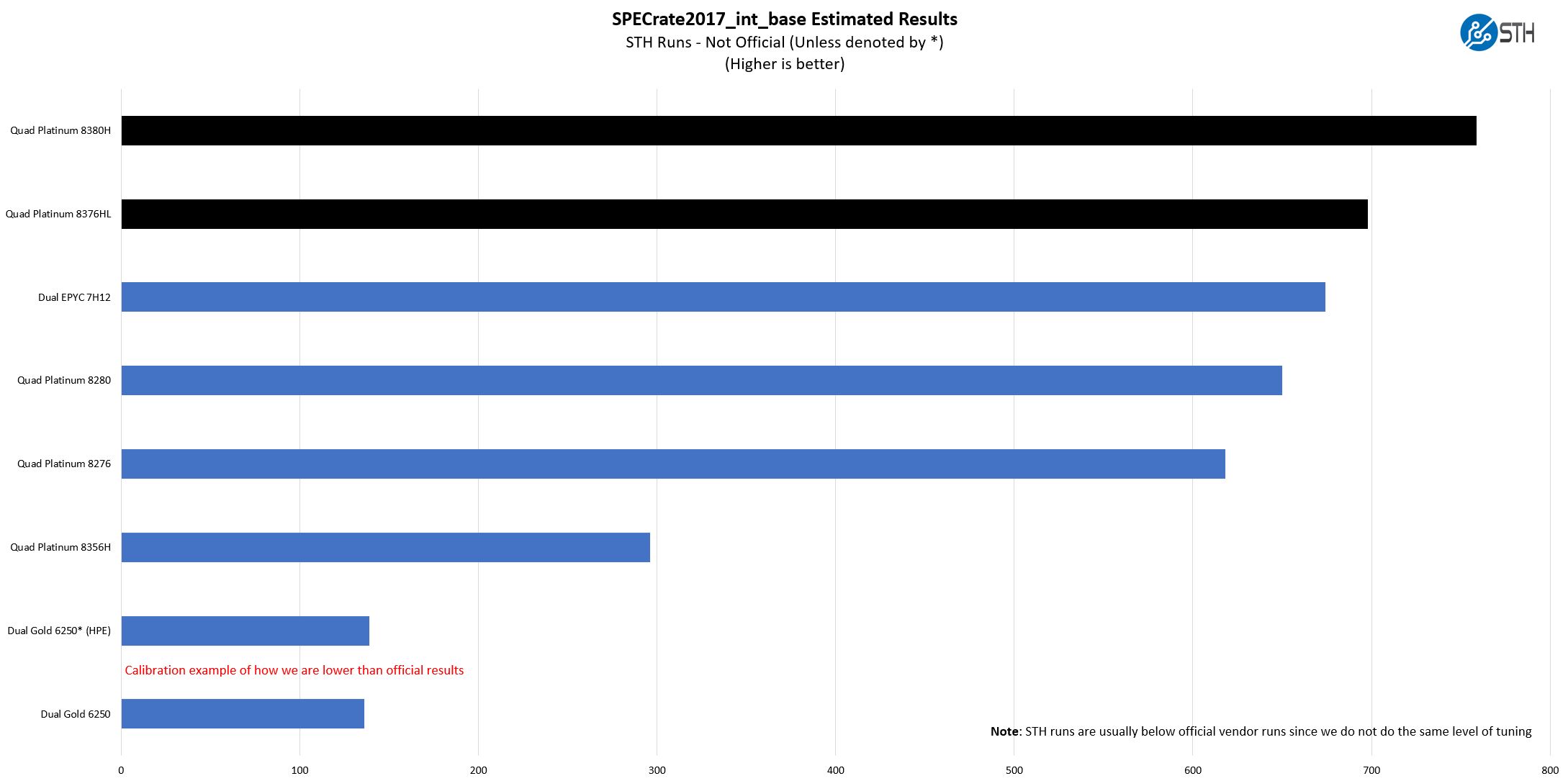
A few quick and important notes here:
- These are not vendor official results. For official results, see the official results browser.
- We are often behind vendor results. So please look up official results, for RFP purposes. Vendors do more to get to extremely tight tunings for their official runs, so ours are comparable only to STH results, not the official data set.
We are going to do a more in-depth Cooper Lake review series, but this should give some sense of performance.
Next, we are going to get into the “so what” and discuss market positioning for the new products before giving our final words.



{kind=link}
This is exactly why we read STH. Ya’ll on a roll with these. It’s like “hey there’s this thing, here’s everything you need to know about it” BOOM.
I wish you reviewed every server out there so the server buying experience was more transparent. I know that’s impractical, but this is so much better than the Dell marketing material on its servers and the junk they pass off as collateral. Oh and I don’t think Dell even has these just the R940/R840 so this is technically higher-end than Dell’s highest-end 4-way
Best review, also only review. Nice STH on not squandering and doing good write up.
I’m learning so much here
I didn’t even know what cooper was until I saw the heatsink video with this system
Comments are closed.