Gigabyte G893-ZX1-AAX2 Topology and Block Diagram
Installed in the system we had two 192 core AMD EPYC 9965 CPUs. That made for a massive system loaded with GPUs, storage, and NICs. This is one of the bigger topology maps we have ever seen.
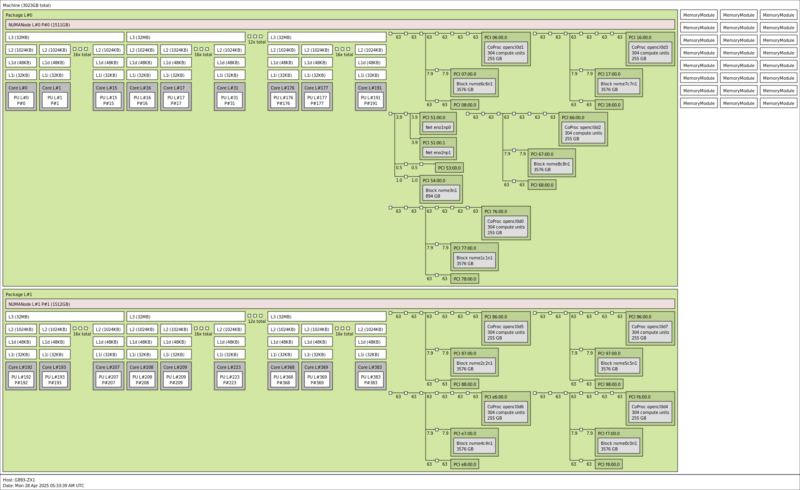
For the system’s block diagram, perhaps most interesting part is how the PCIe lanes are distributed.
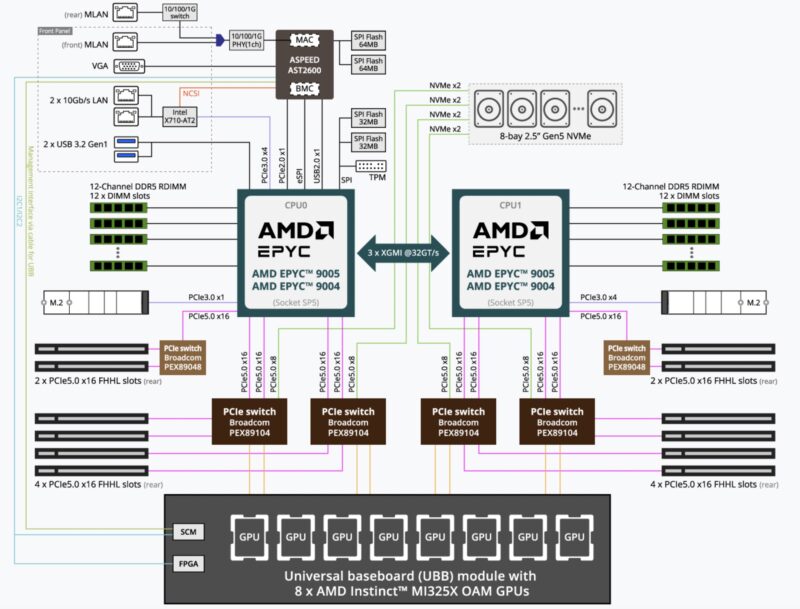
This system has six PCIe switches with the four Broadcom PEX89104 switches handling the CPU-GPU-NIC-NVMe topology. Then there are two Broadcom PEX89048 chips to handle the CPUs to the North-South network links. Those PEX89048’s are not directly connected to the GPUs and storage.
Gigabyte G893-ZX1-AAX2 Management
On the management side, we get an ASPEED AST2600 BMC running MegaRAC SP-X. This is an industry standard management interface.
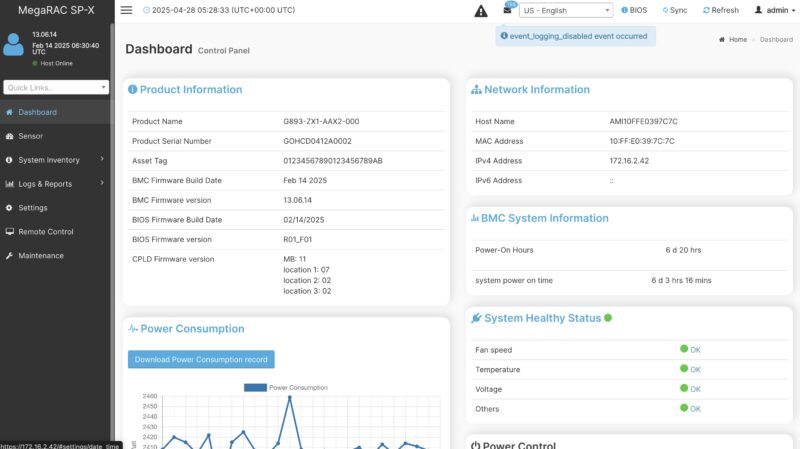
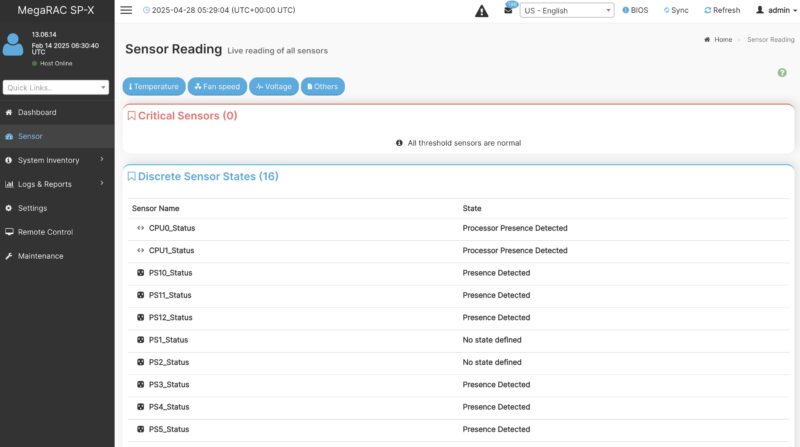
On these systems, the number of components tends to be higher since we have so many fans, and even things like twelve power supplies. That means that the management interface has a lot more to cover in terms of monitoring and logging.
Still, we get standard features like an HTML5 iKVM. Here we can see our eight AMD Instinct MI325X GPUs idling at 122-137W using rocm-smi.
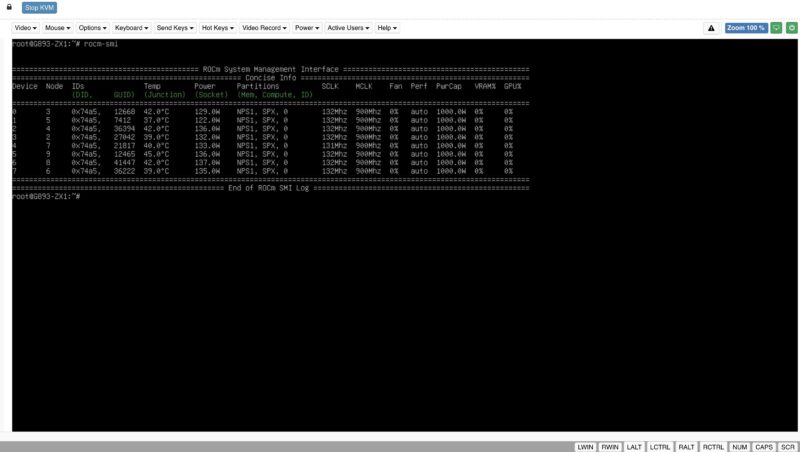
All of this will be familiar to those who have used SP-X on a Gigabyte server or other servers before.
Gigabyte G893-ZX1-AAX2 Performance
In terms of performance, we had dual 192 core AMD EPYC 9965 CPUs for a total of 384 cores and 768 threads. There are often a few schools of thought regarding CPUs for these systems. Some go with the highest core counts, which we have here. Others go for lower core count higher frequency parts.
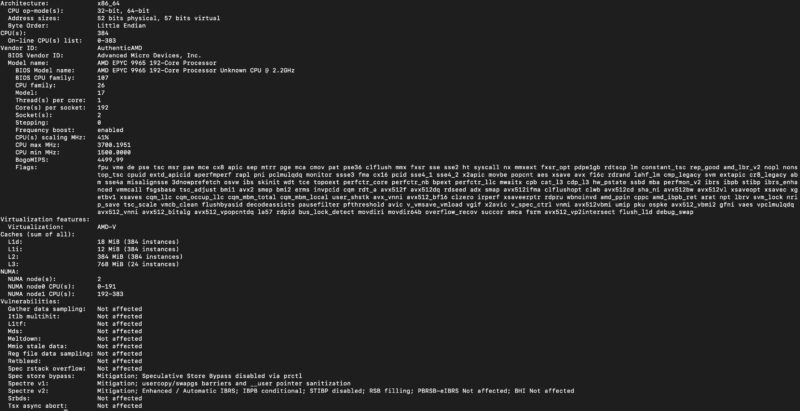
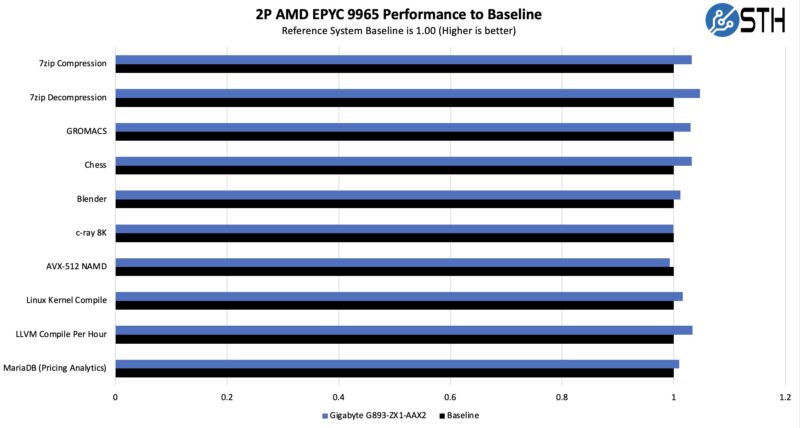
Still, we wanted to validate that we were getting the performance we would expect from the CPUs so we compared the performance to our reference 2U server:
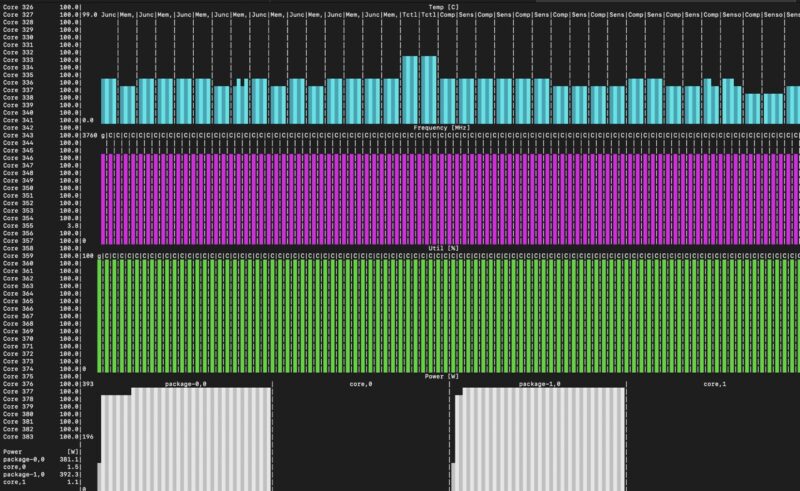
One of the big challenges in these big AI servers is keeping the CPUs cool. Gigabyte is doing a good job in this area.
On the GPU side, we have been testing a number of these systems. We used vllm for Llama 3.1 and sglang for Deepseek-R1. On the LLama 3.1 side we used 128 input tokens and 2048 output tokens since that tends to be a sweet spot we found. We also used a batch size of 8 for our latency comparisons. On the Deepseek-R1 we were using the same 128/2048 and at a concurrency of 64 with the mean inter-token latency as our latency comparsion point. Performance was on par with other systems.
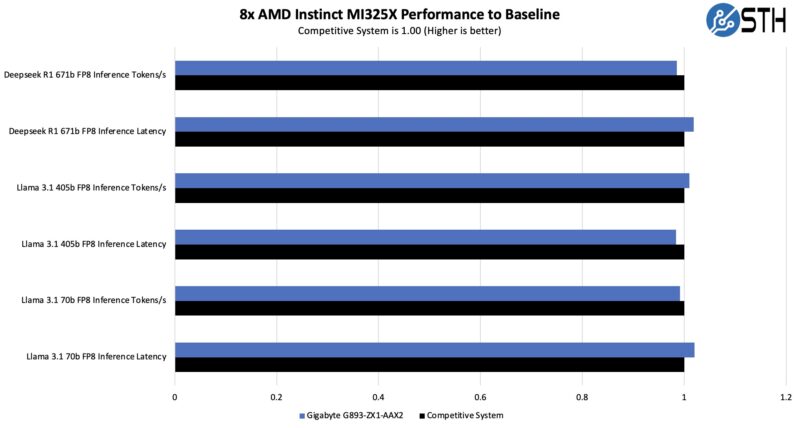
Directionally, these were in-line with other systems with the AMD Instinct MI325X that we have tested. Something to keep in mind is that we tested these systems pre-ROCm 7. AMD is making big strides in its software stack, so performance using a modern stack should be faster than what we are getting.
Next, let us talk about power.



 with dual AMD EPYC CPUs works){kind=link}
Is there any concern with regards to performance when using these pci switches?
ex. Any potential for oversubscribing and causing congestion avoidance protocols to kick in?
How does this topology compare to a typical dgx system regarding the issue above?
Is there the same potential for oversubscription with similar Nvidia based servers?
The motherboard without components actually has dual socket SP6 with 32 DIMM slots.
Kawaii, the unpopulated motherboard has different layout too. Most obvious is the m.2 slot adjacent to the middle bank of DIMMS on the unpopulated board.