The Forgotten Parts of the AI Cluster
When you look at this picture, you may be drawn to the Supermicro GPU servers, the network switches, firewalls, cold aisle containment, or overhead cable raceways. If you look a little closer, you might see some of the more forgotten parts of the AI cluster.

In the middle of that rack, there are traditional compute servers as well. Here are three Supermicro 1U servers.

We also found a number of 2U Supermicro servers around the cluster.

We discussed some of the other 1U storage servers, but there is a good reason we see so many traditional CPU compute platforms around. Lambda needs to operate its cluster. Customers need traditional compute resources located with the AI servers to orchestrate activity and also to provide other services. We are not going to provide an exact count, but if you watch the video and look for them, you will notice there are many traditional compute nodes in different form factors alongside the GPU servers.

Here is a quick screen capture from a running cluster where you can see the GPU nodes running, but also the CPU-based nodes.
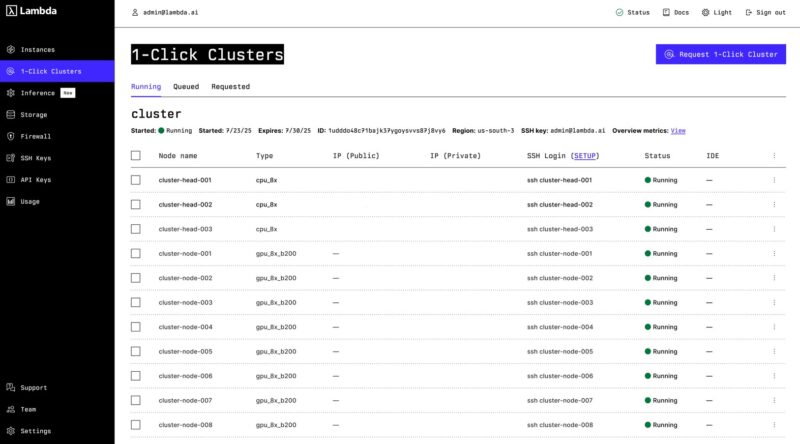
There are also a ton of other components. For example, you might have noticed the red and blue power cables, the PDUs, different types of labeling (the Sharpie version was perhaps the most fun), cable management devices, and so forth. It is always fun to see just how many things must come together to make clusters work.

While investors may focus on the high-dollar items like the Supermicro servers, NVIDIA GPUs, storage vendors, network switches, optical modules, and so forth, that is only a part of the overall BOM of a cluster like this.

Instead, if these other pieces are missing, often the cluster cannot be brought online, and costly GPU servers sit idle not able to service customer workloads.

What is more, even seemingly small details can have impacts on the supply chain like the airflow direction on the switches.

Small things can make a difference. For example, if you have fiber bundles custom-built, but to the incorrect lengths, they then need to be redone and delay go-live. AI clusters have a surprising amount of surrounding infrastructure that needs to be in place for the clusters to operate.
There was one cool item that we missed, and that is a special “tool” for helping run cabling in the overhead raceways. Hopefully, we will get that in a future video.

One of my hopes with this article and video is that folks appreciate just how many things must come together to make AI clusters work. While in mainstream media these parts are often forgotten, this is STH, and I want to show our readers whenever we can.
Lambda needs to manage this not just for this cluster, but for all of its existing and future clusters. Let us get to growth next.



{kind=link}
Manmade horrors beyond comprehension!
Article good. Video better. I’m not sure I’ve seen a dc video as fast paced as your xAI video since that one. It was like I was watching some gripping mission impossible action movie not some boring dc video. I don’t know how you did that, but keep doing more of it
Eagerly awaiting the day when the AI bubble bursts after investors figure out that AI isn’t a magic black box that replaces human employees. Then some of this hardware can hit the secondary market for prices that hobbyists are willing to pay for hobbyist use of AI.
AI isn’t some investor-fueled bubble. Companies are actively spending massive amounts of money on it. If the companies are collectively spending hundreds of billions of dollars per year on AI just to satisfy perceived investor interest then there is a much bigger problem in the marketplace than an AI bubble. If it is a bubble it is in the hopes and expectations of technology companies, not in the speculation of investors.
@Matt it’s become so bad that the likes of Microsoft have started ‘trimming the fat’ despite record revenues, and are desperately tacking AI (‘copilot’) onto any popular product despite customer pushback that it doesn’t really add any value let alone justify a price increase.
Looking at Cologix’s locations it seems that the most northerly location is Montreal Canada.
Checking the Open Canada website for “Permafrost, Atlas of Canada, 5th Edition” we see that there’s so many better locations available for cooling a server farm (at the lowest possible price). Just as you probably don’t want to setup in southern California (because of the temperature and electricity costs) you wouldn’t setup in southern Canada (when you can move to northern Canada, near a dam).
Not my hundreds of millions ….
Within a year or two, we’ll be looking back and wondering how absolutely *everyone* seemed to think this was a great idea.
I’d love to see this equipment put to work doing scientific research but I fear that it’s already too tightly optimized for AI work.
Regardless, fascinating view into how these clusters come together. Thanks, Patrick!