ASRock Rack ROMED8-2T Performance
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts.
At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
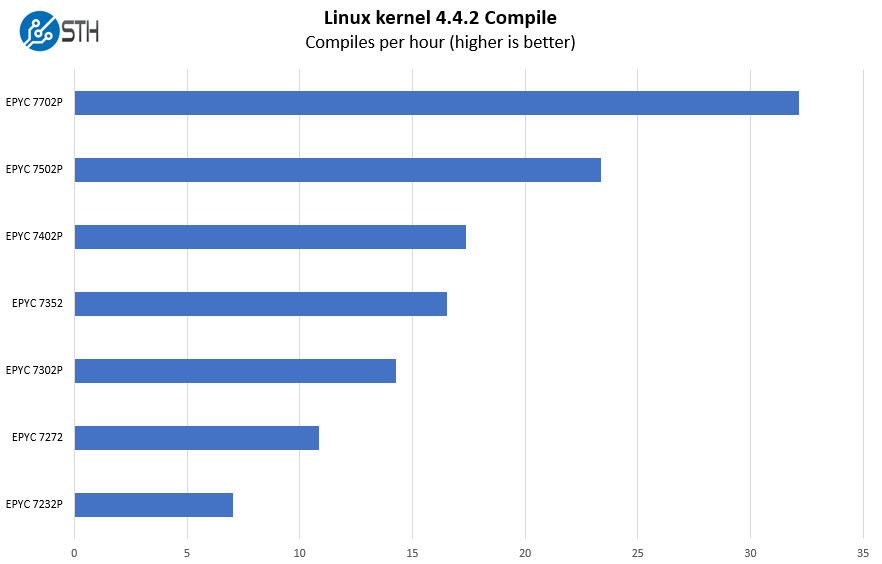
The performance for this platform scales across a wide range of scenarios, even just using the “P” series discounted parts. We have 8 to 64 core options on our list.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
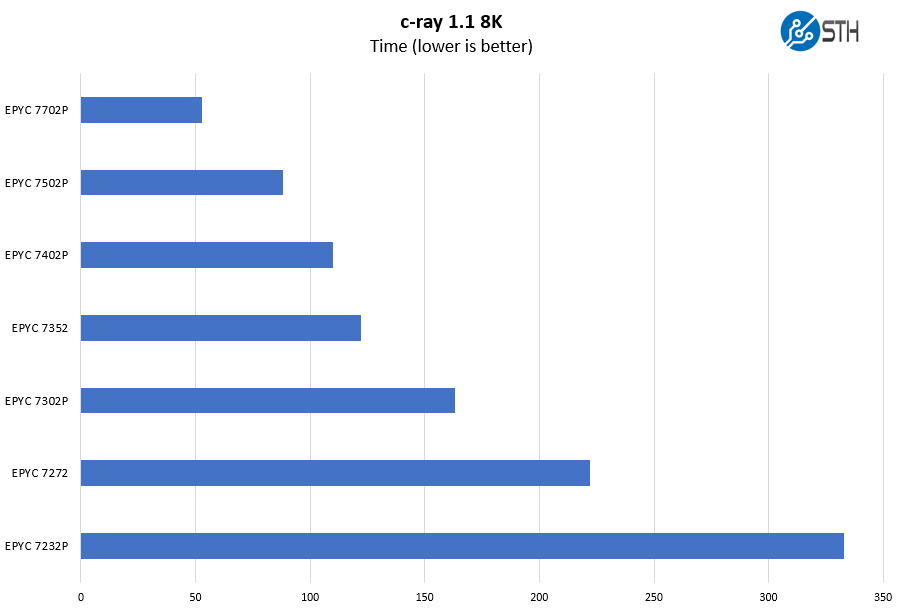
We highlighted this in our recent AMD EPYC 7552 Benchmarks and Review piece, but AMD currently does not have a 48-core “P” series part. With the AMD EPYC 7702P pricing, we think that is likely a better option, but there are 48-core parts we are not showing here as well.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
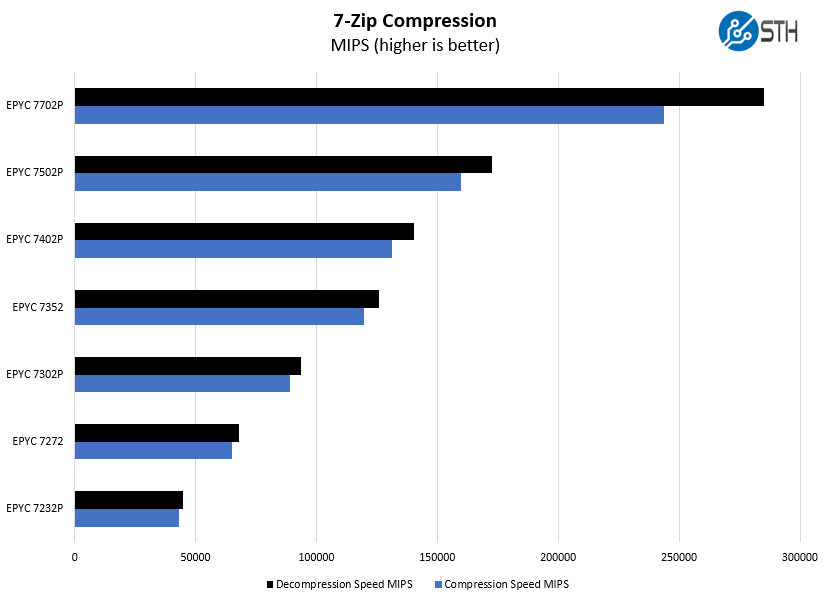
We think the AMD EPYC 7302P, EPYC 7402P, and EPYC 7502P may be the best fits for this platform given their price/ performance. The EPYC 7702P offers the “wow factor” of having a 64-core part but the lower price and core count parts offer a lot of value as well.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
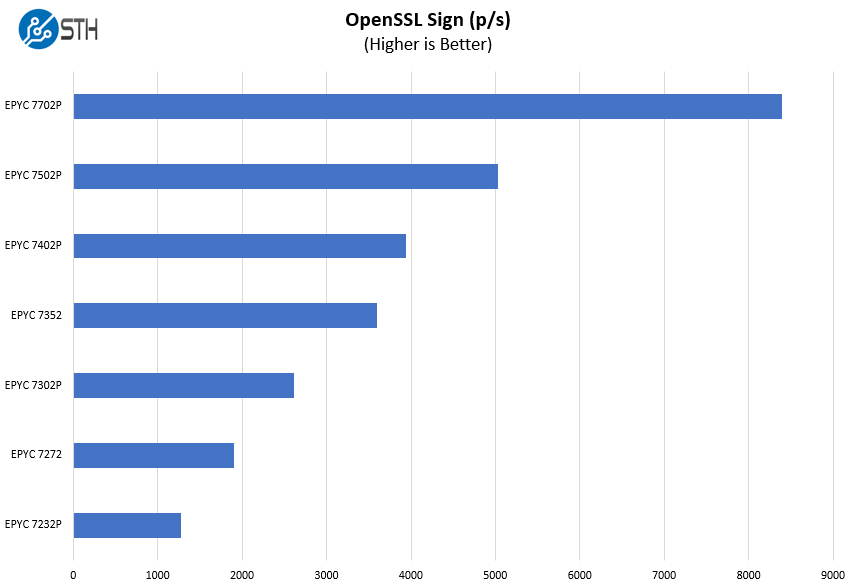
Here are the verify results:
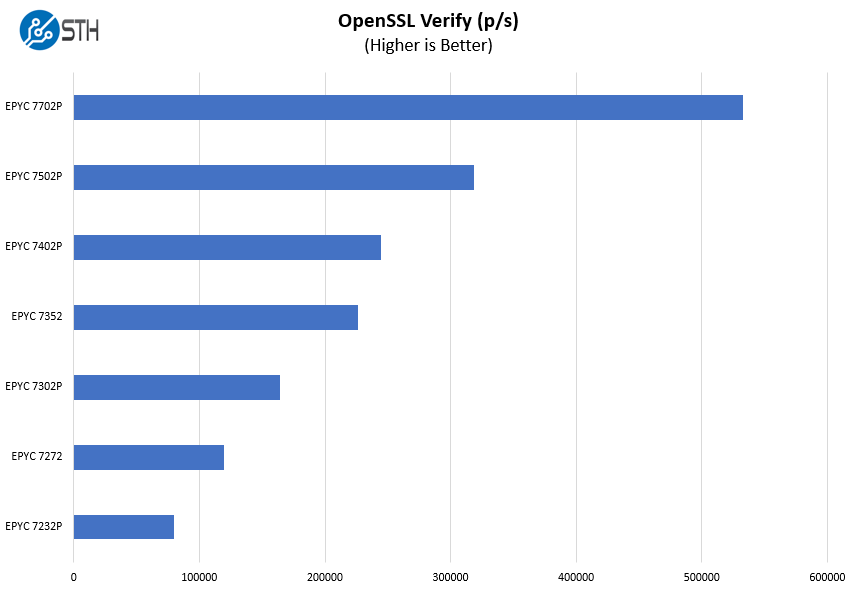
Something that is important, yet often missed, is that AMD also has “4-channel optimized SKUs” such as the AMD EPYC 7232P and EPYC 7272 we are showing above. These are designed for lower-cost installations where one does not intend to use massive CPU core counts and high memory capacity. We covered this in AMD EPYC 7002 Rome CPUs with Half Memory Bandwidth and in our video:
On a system like the ROMED8-2T, this is an option for those who intend to use the PCIe slots for networking and storage but may not need all of the compute. At the same time, given the speed of PCIe Gen4 devices, it is likely that you will want full memory bandwidth in this platform if heavily relying upon the PCIe Gen4 slots.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
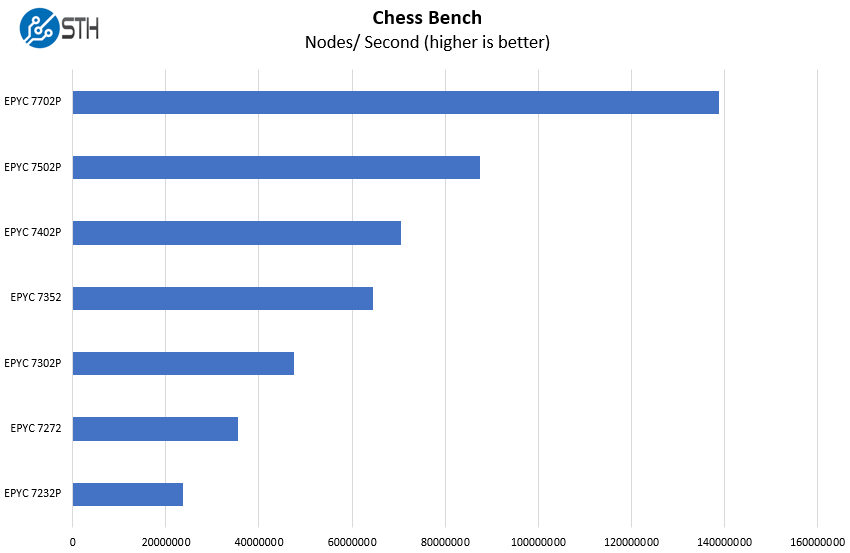
If you are a systems integrator building bespoke solutions for your clients, then the impact of having an ATX size motherboard with 64-cores and an absolutely massive RAM and PCIe I/O loadout cannot be understated. AMD is able to offer top-bin dual Xeon performance in a single socket and ASRock Rack is putting that performance into a compact ATX form factor.
Next, we are going to end taking a look at the block diagram followed by our final words.



{kind=link}
Patrick,
Is the ASRock Rack ROMED6U-2L2T slated for review at some point?
We have a couple on the way here shortly as Micro-ATX is perfect for a small cluster node application.
Thanks for the great articles. It’s great to see objectivity like this as it builds trust. :)
Philip
Just started coming to this site regularly since I put a rack in my basement. Really like the content!
Anyone have power consumption numbers for this board with a low-end EPYC chip? I want something I could load up with RAM, but not something that idles at 100+ watts.
On the AsRockRack website are CPUs with over 225W TDP listed in the supported CPU list. Are they compatible or just with extra airflow over the VRMs? What’s correct?
i would like to know 2 things:
– case used to house the board ? is it server rack case, used with air shrouder ??
– how hot get CPUVRM when cpu is fully loaded at all cores ??
I think there is a one small problem – and it’s with the name of this motherboard.
ASRock Rack has already a motherboard named ROMED8-2T, and it has 4 PCIe 3.0 X16 and 3 PCIe 3.0 X8 and it’s for both ROME and Naples CPU’s (7001 & 7002 series).
This board has the same name, and it’s a pity that they didn’t change it, so if you plan to buy this board, then MAKE SURE you’ll getting this one and not the older one.
Oops, my bad. The previous gen called EPYC8D-2T, and this is ROME8D-2T. Terrible names!
Patrick,
You mention that this MB only support 1 DIMM per channel, but you don’t have any test which compare memory performance against ‘standard’ server MBs.
Perhaps you could post an update with a comparison?
hi there,
thanks for the great review! I bought this board few weeks ago and there is one big trouble currently: neither bios nor ipmi lets me configure fan controls. Talked tomasrock already, they promised new firmware until, well, yesterday. now they told me it is going to be tuesday, we will see. right now all fans run at full speed and dont make use of any thermal management.
did you guys experience something alike?
cheers
How does this compare to Tyan Tomcat HX S8030 (S8030GM4NE-2T)? Thanks!
As the first person in Europe who got this board more than 2 months ago. Have to say I’m not super impressed. The fact they advertise Thunderbolt support and there is a TB header on the notherboard but it does not work at all and I made AsrockRack aware of this months ago and they seem to try and suppress this glaring issue. (I also have TRX40 Creator where they advertised Thunderbolt support but then removed it from website and BIOS (i still have the BIOS that contains a whole optuons page with Thunderbolt options.)
Have to say I have been very disappointed by Asrock lately, and I used to be a hughe fan.
I don’t see thunderbolt on their site for this or in the review. It’s an AMD platform so i wouldn’t expect it to have TB support. Intel has only certified a very small set of AMD for TB right?
So they also removed it from their website now which reinforces my point. I have the printed manual that came with the motherboard that states TB support and also with all respect I have the motherboard in my hand You don’t. Why would Asrock go through all the trouble and implement a physical header on the motherboard and in the BIOS named Thunderbolt and then try to.erase it from the website?! Time for my EU commisary to investigate.
I always get asrock if possible for any build, and they again show they are on top with their Motherboards, propped full of features pushing the limits of all the form factors. Hope to see the 2p ROME2D16-2T next!
Any case suggestions ?
I am planning to plug 7 watercooled gpu on it.
Thanks for the review. When I build my next system it will be with this motherboard. My own AI workstation.
@Mario I am also facing the same problem, that there does not seem to be any fan control in either bios or ipmi…..
For now plugging them to PSU, but thats one loud box now…
Do you have access to linux drivers, firmware or an updated BIOS for this board? BIOS P1.10 sees the one SATA drive, the Boot menu sees the SATA drive, Windows sees the SATA drive, but Debian does not. I use Debian 10 (Buster) stable with kernel 5.6 from backports with linux-firmware (including non-free). Everything, including Debian, sees and installs on the two nvme sticks on the motherboard.
Does anyone know if we solder the TB header will that work? Any setting in the BIOS?
Probably a stupid question but I’ll ask anyway. With Zen three coming out, will this board be compatible or should I be patient and wait? Really want to set it up with Milan!
Also, with 8 dimm channels, would I benefit from filling all slots and dispersing the memory in say, 128gb segments at 1tb vs 4 256gb ram? Cost prohibitive!
I have this motherboard and after 2 months one of the 10gb ethernet ports went out (totally dead – no lights etc even though driver still sees port). Asrock won’t do a cross-ship which means I’m down for weeks on my server. I stuck an Intel X520 card I had in to cover me and am now debating what to do. Sort of disappointed in Asrock for not offering to cross-ship a $600 motherboard and wondering if quality control is not up to snuff. This was my first venture away from Supermicro and I’m regretting it.
Hello Longreen – Do you know what BIOS version has Thunderbolt in it? Is it still on the latest version but not working?
Interesting update on this board that it now support the 7003 processors (with BIOS update)
https://www.asrockrack.com/general/productdetail.asp?Model=ROMED8-2T/BCM#Specifications
Has anyone got Esxi 8 running on the ASRock ROMED8-2T? I`m hoping to run 8.0U1 on this as a homelab machine with a cheap epyc 7302p from Ebay
I live in the UK so if you have any better suggestions I would be interested if there were a better alternative?
Comments are closed.