Arm Neoverse V1
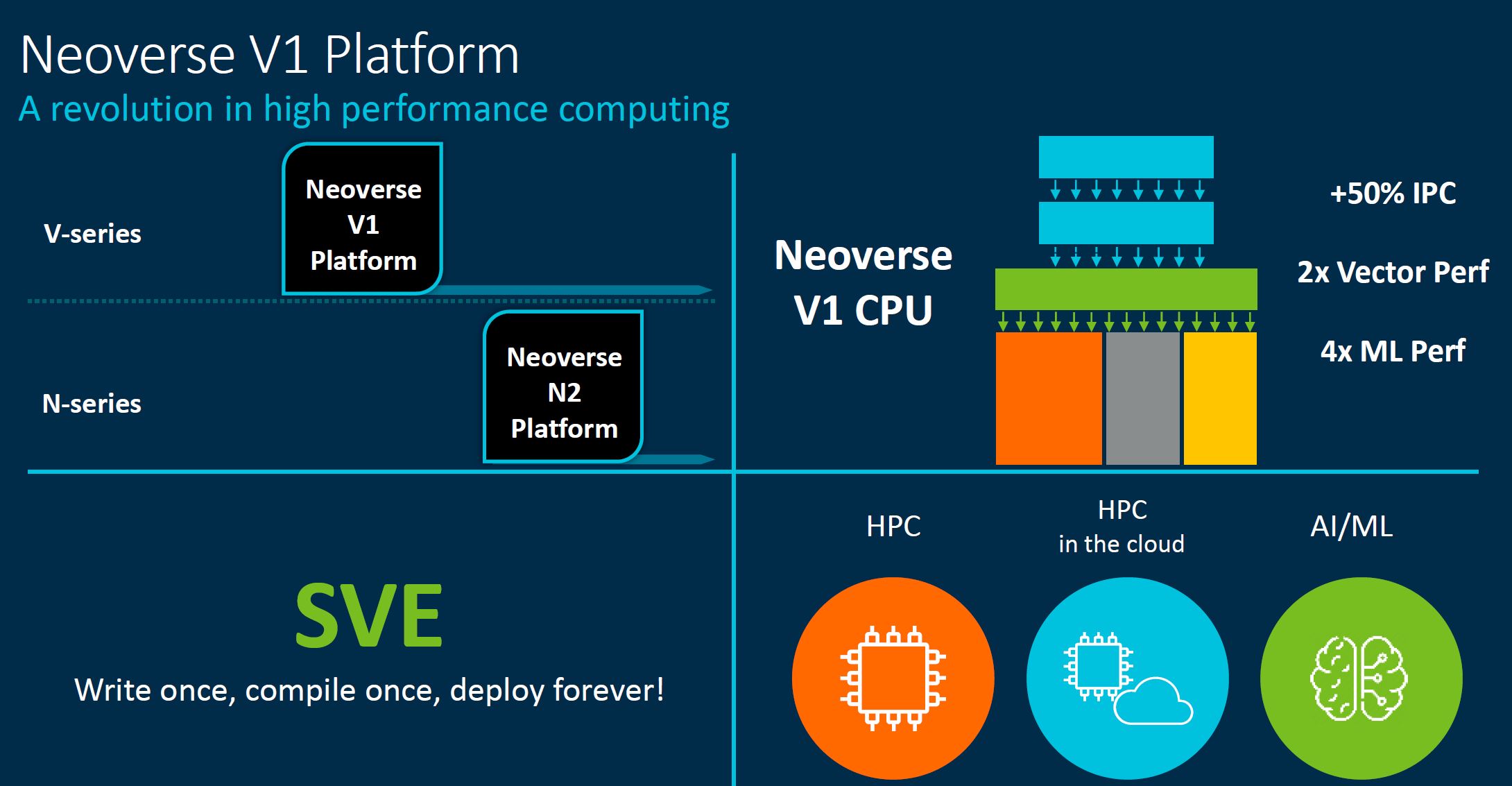
Arm is a company that likes to put its impactful summary slides last. If you just want to know quickly about the Neoverse V1, then the key aspects are that it has a large IPC increase and uses SVE to get vector performance speedups, at the expense of efficiency.
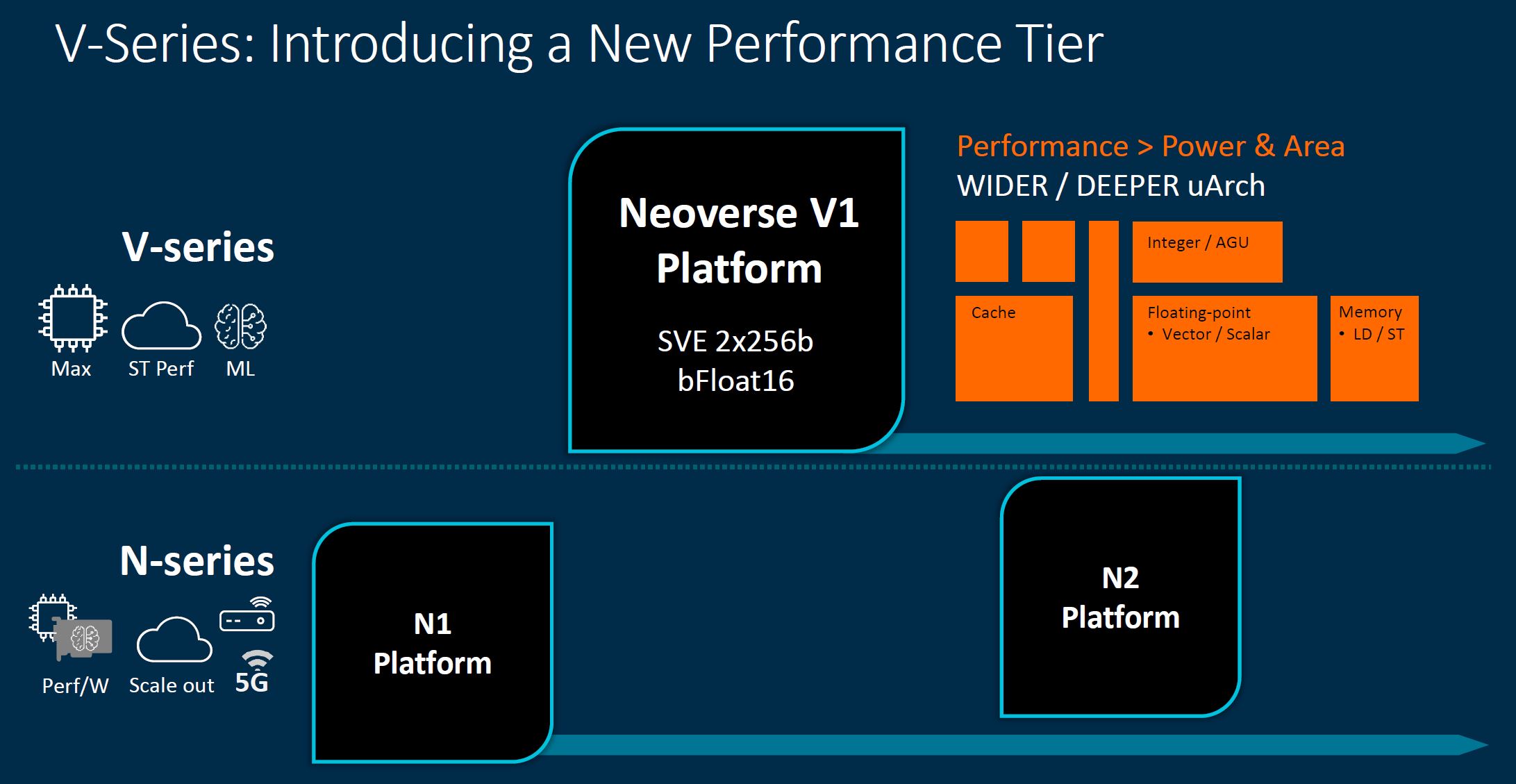
Key here is that the V-series is a wider/ deeper architecture that prioritizes performance over power and area efficiency.
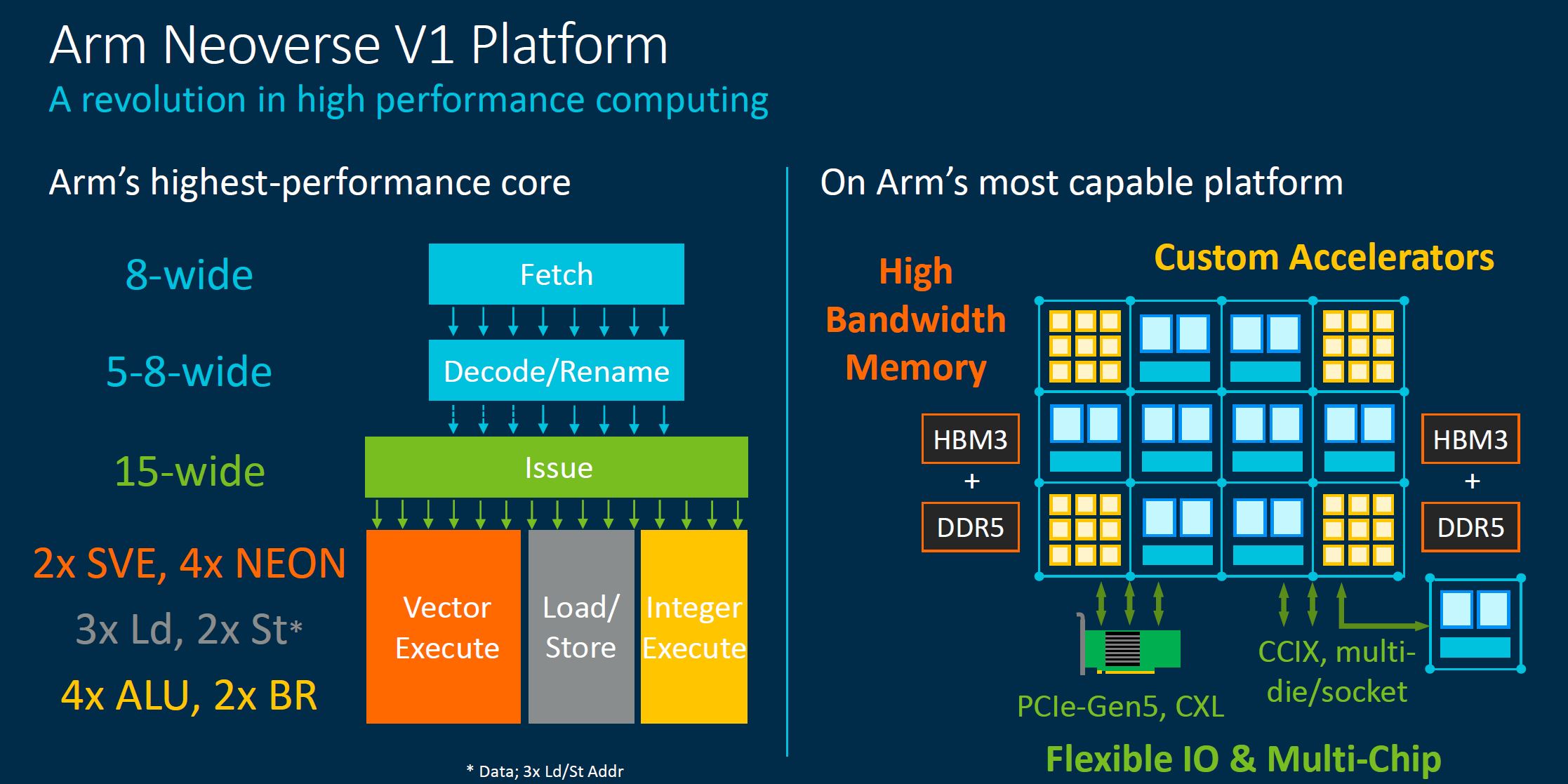
Where the V1 is targeted is not necessarily deployment in cloud web hosting nodes. Instead, it is designed to bring high-performance cores to accelerated systems designed for high-performance workloads.
We will let our readers read the what’s new slide:

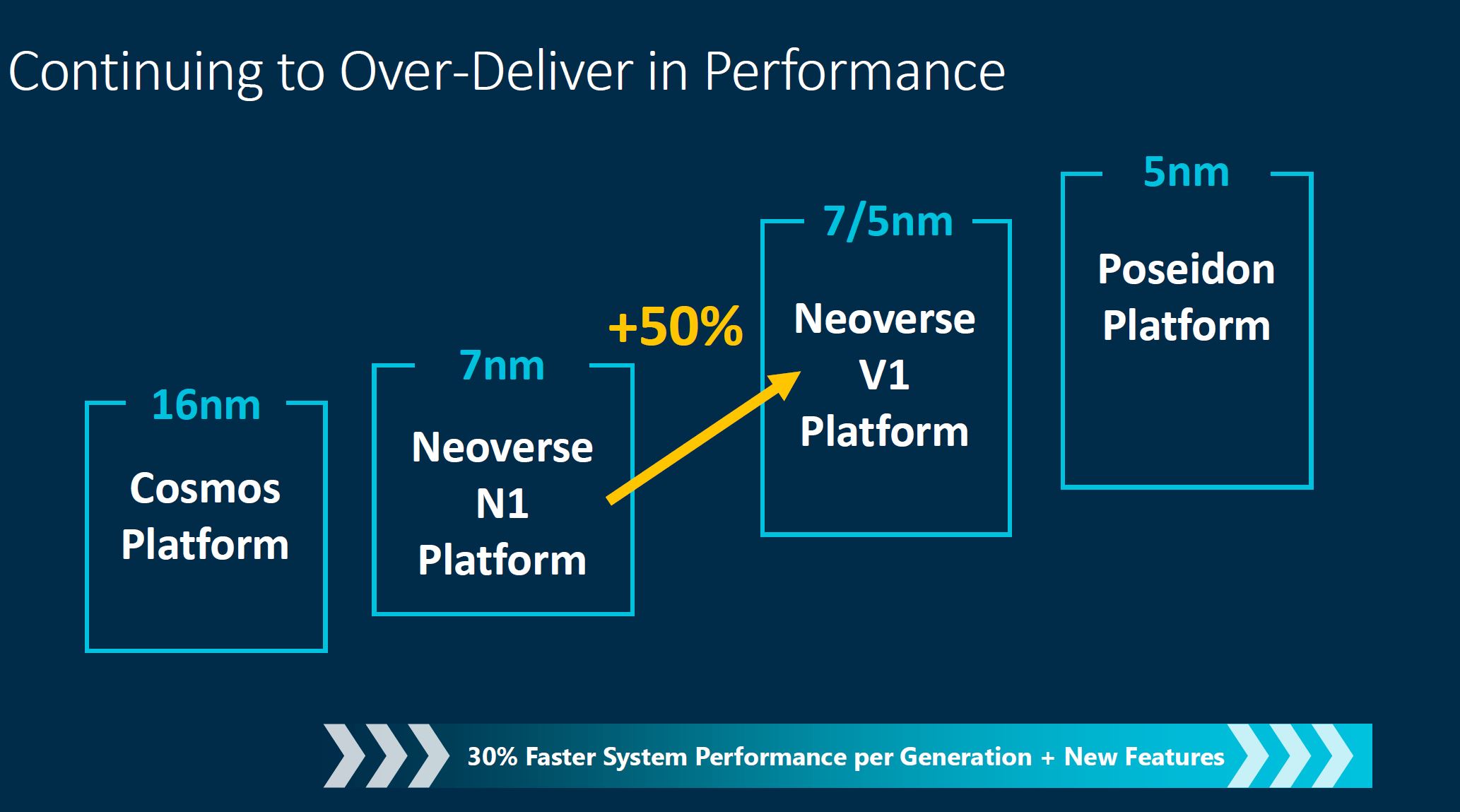
Arm was targeting 30% performance uplift, with this it has closer to 50% performance uplift, but this is a bit strange since the N2 is perhaps really the N1 successor (we will discuss this next.)
The next set of slides is getting into the microarchitectural details. We wrote quite a bit for each, but then realized we were basically re-wording the facts that were on the slides, so we are going to save our readers some time and simply suggest that if you are interested in the microarchitectural details, you go through these slides. The first in this section is around the front-end.

In the mid-core the focus is on width and depth.

Here, the inclusion of 2x 256b SVE means we get a lot more performance. This is one of, if not the most important features of the Neoverse N1.

Here is the back-end slide:

Arm had more comparing the V1 back end to the N1.

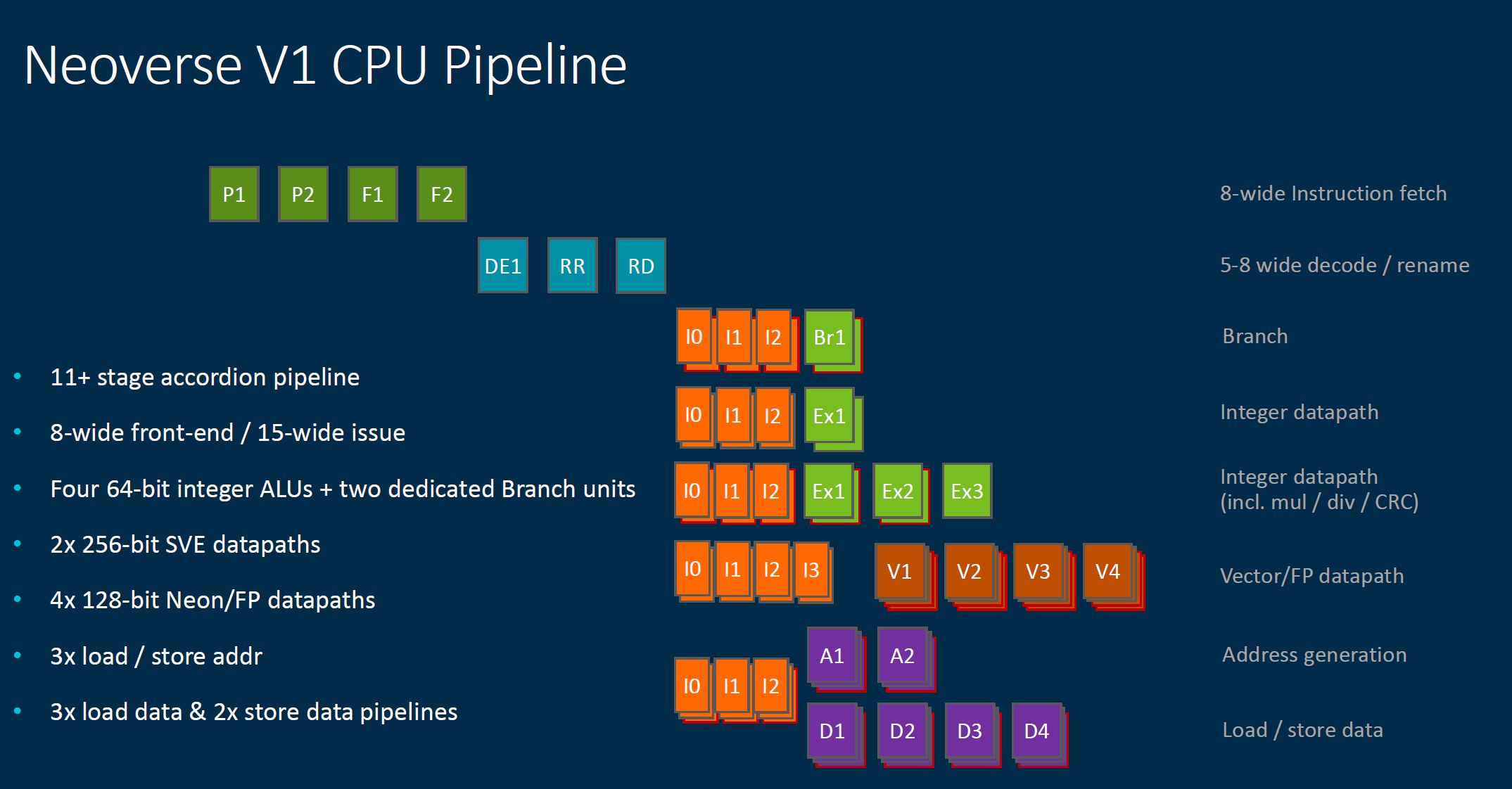
For those that want to see the pipeline breakdown, here is what that looks like:
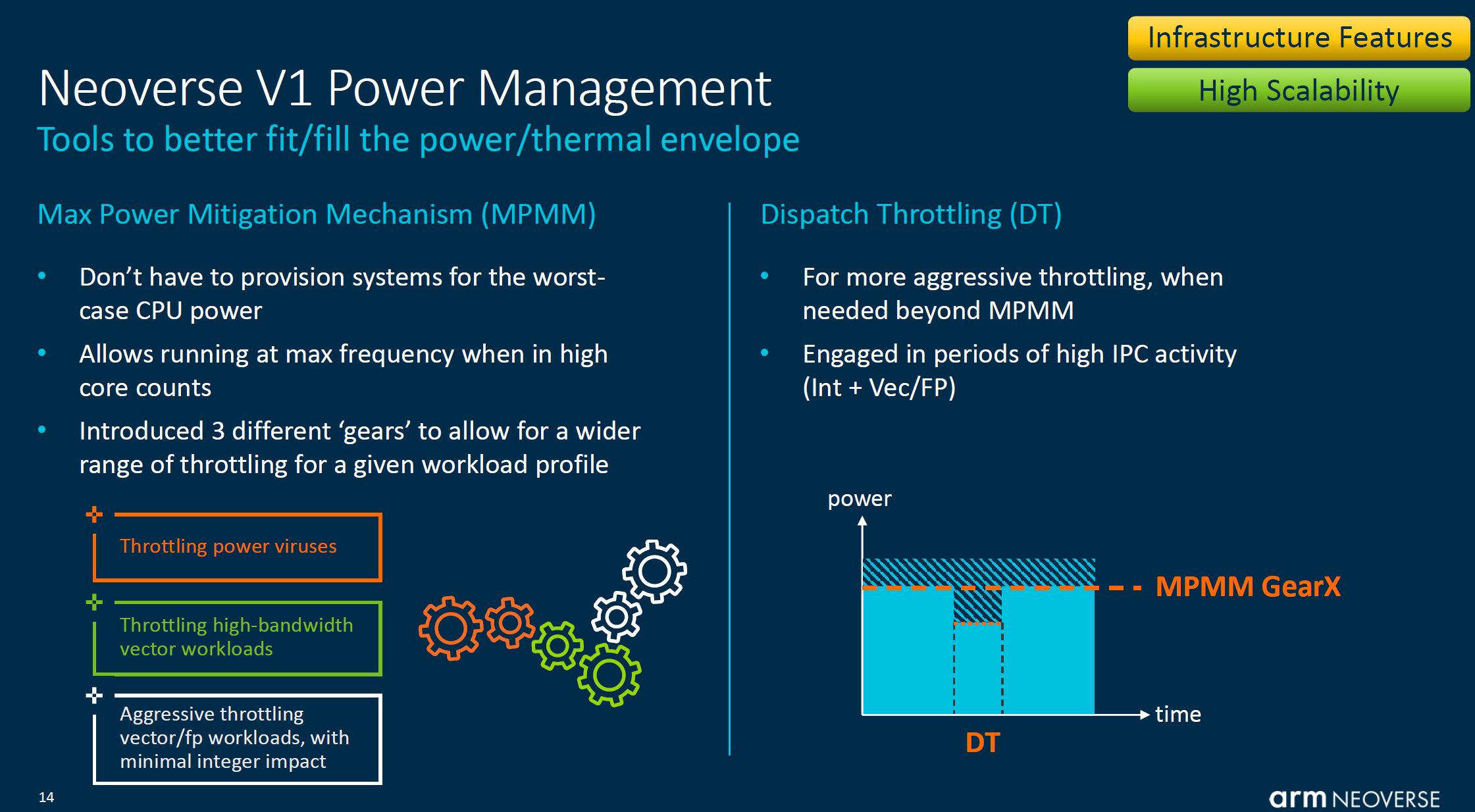
Part of what Arm is doing on V1 (along with other lines) is looking at how it can manage power contention across a chip. Sometimes one hears this in the context of “AVX-512 clock speed impact” or “noisy neighbors/ power viruses”. That is what Arm is addressing here:
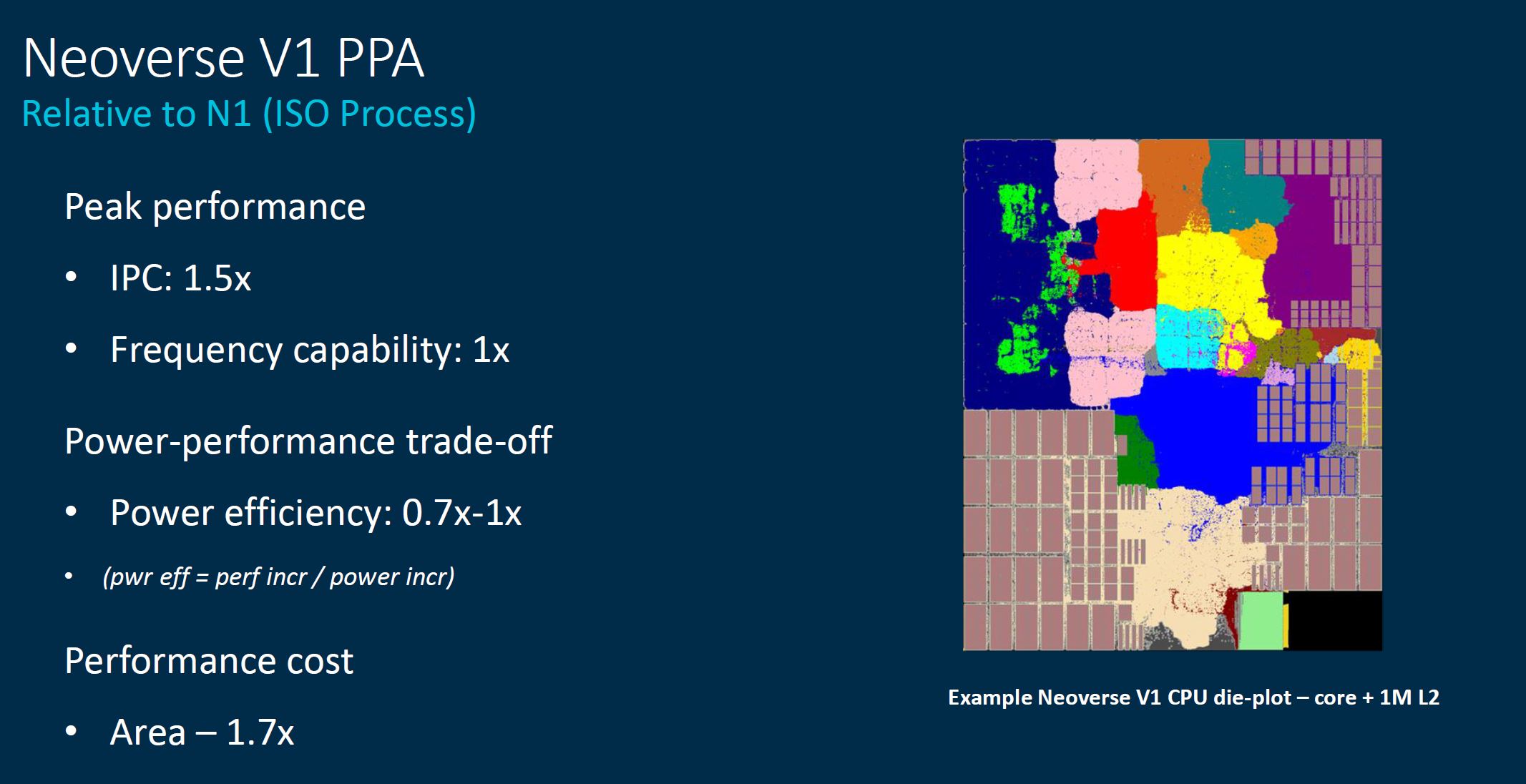
This Power Performance Area slide is important. One gets 1.5x the performance at lower power efficiency and more area than the N1 cores. Strapping big SVE units onto the core means that efficiency went down, similar to what we see on x86, although Arm will point out its future V1 design is still more efficient than current generation x86.
This is an extremely important slide. Since the Neoverse V1 is newer than N1, we get new architectural features. As an example, Arm is gaining Bfloat16 support that we saw about a year ago on the 3rd Generation Intel Xeon Scalable Cooper Lake line that Facebook is using. Facebook’s Yosemite front-end part is the Intel Xeon Platinum 8321HC 26C 88W TDP part so just to keep in mind here there are some fairly exotic and efficient custom parts being made for hyper-scalers on the x86 side as well.
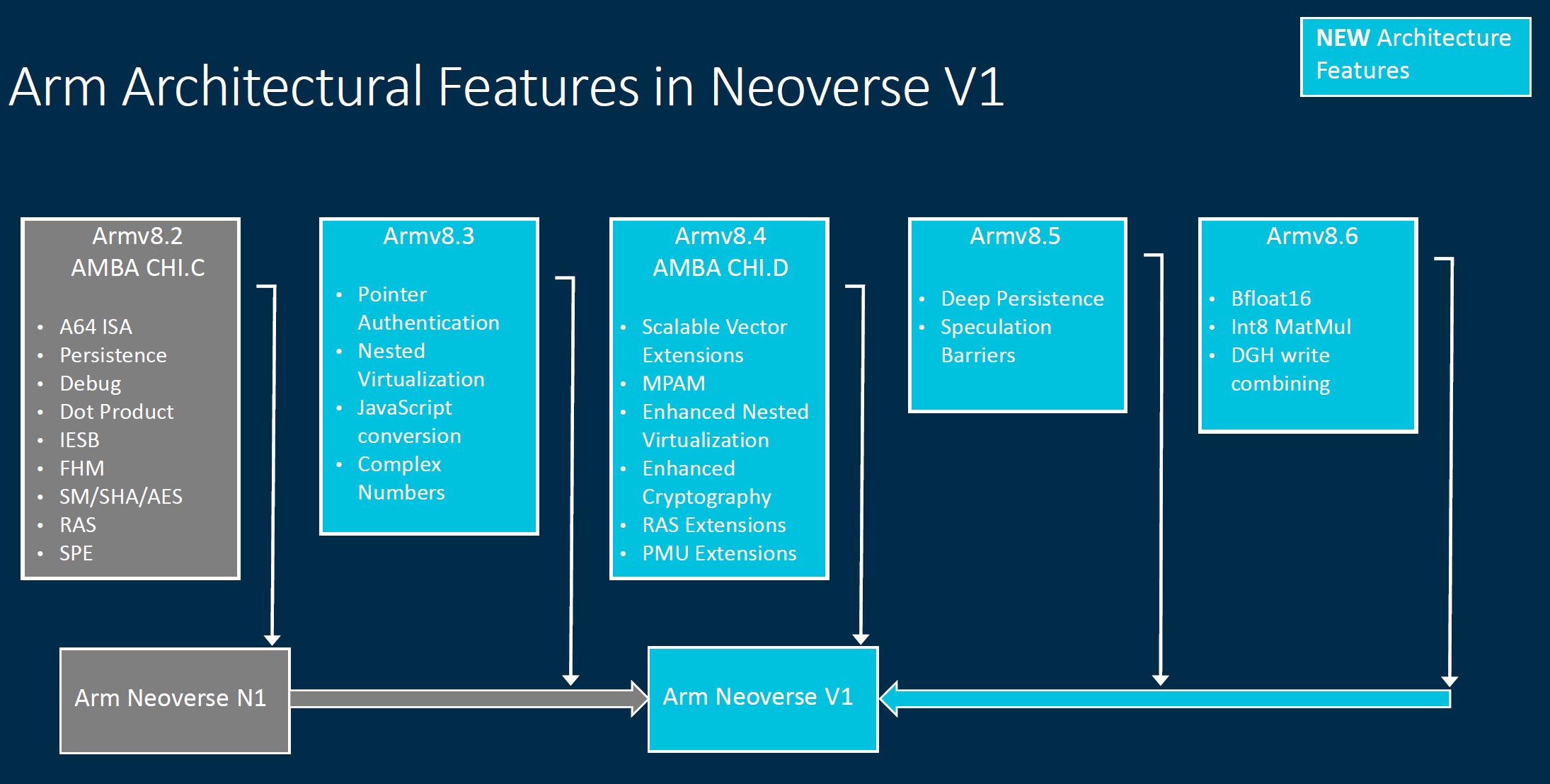
The more important part of this is that the V1 is still an Armv8 generation CPU. We recently covered Armv9 and the Neoverse N2 by being newer IP is leveraging Armv9.
If one wants to, one can use Memory Partitioning and Monitoring to manage memory bandwidth, but this requires extra effort to deploy.
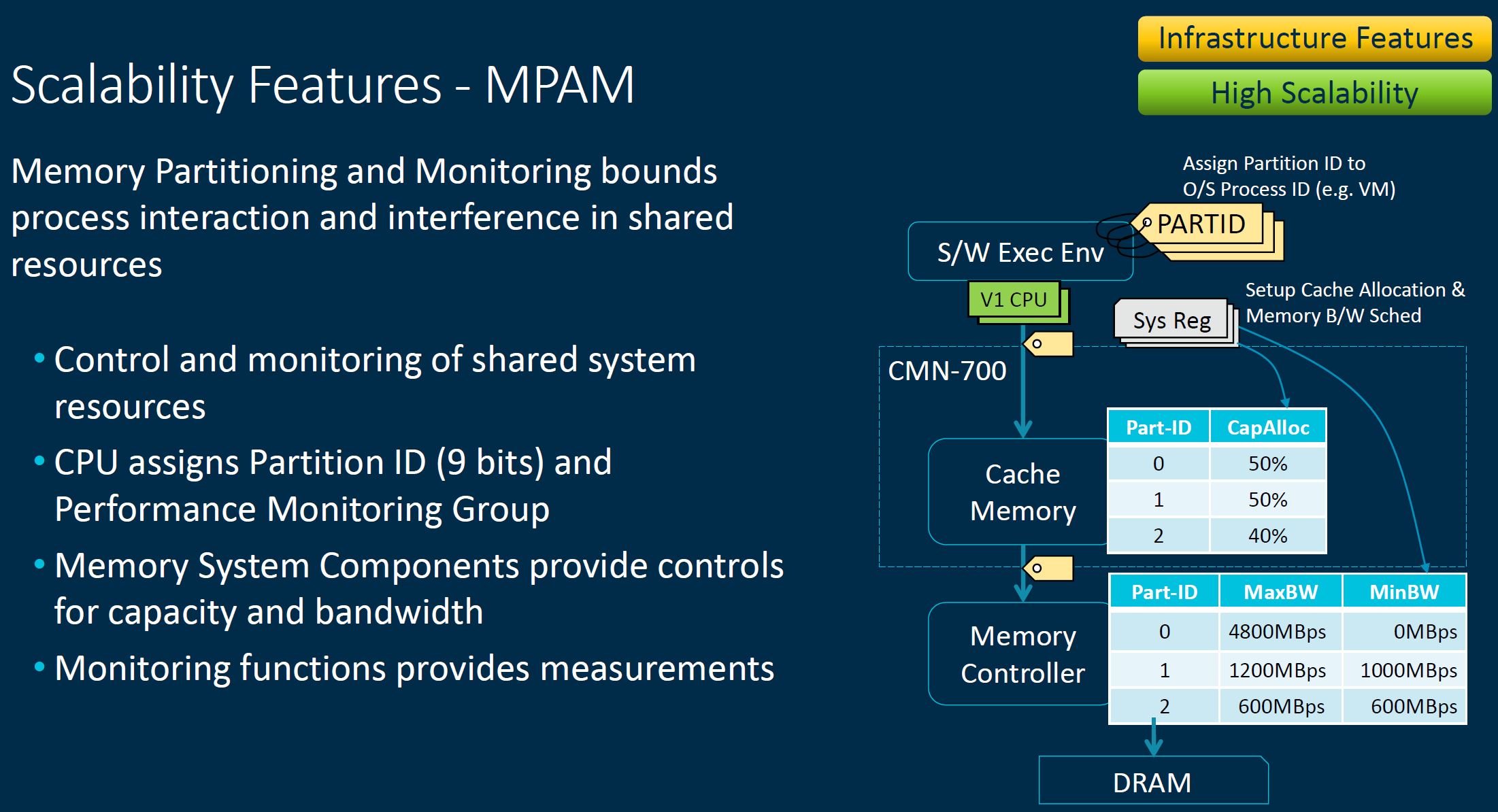
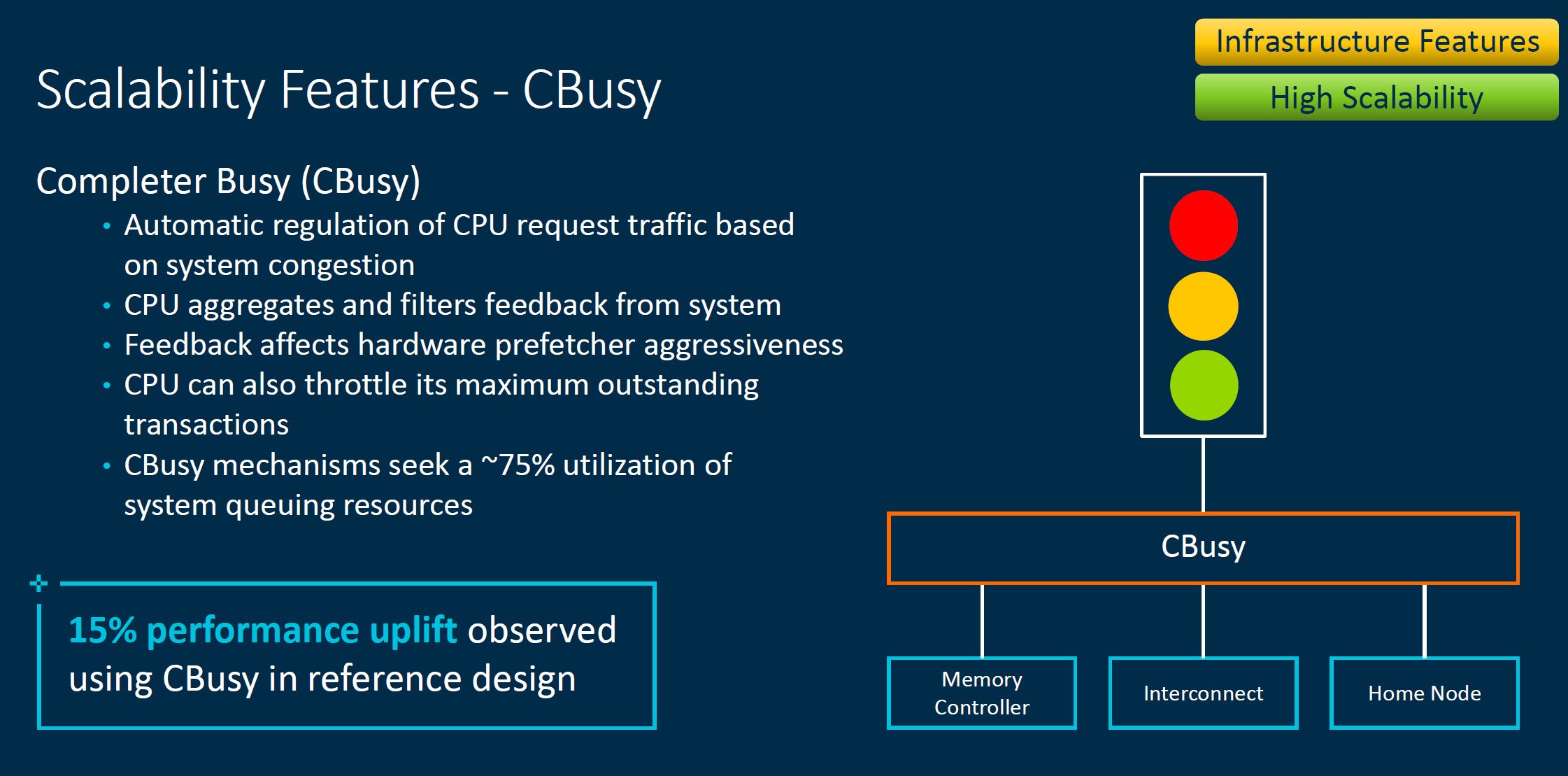
Likewise, there is also a CBusy feature to manage system congestion. This is important as systems get larger and more complex with more cores and more devices attached.
Here is a list of new performance features that we are going to let our readers skim.

Neoverse V1 is Arm’s SVE implementation. SVE stands for Scalable Vector Extension which allows for a scalable rather than a fixed vector length.
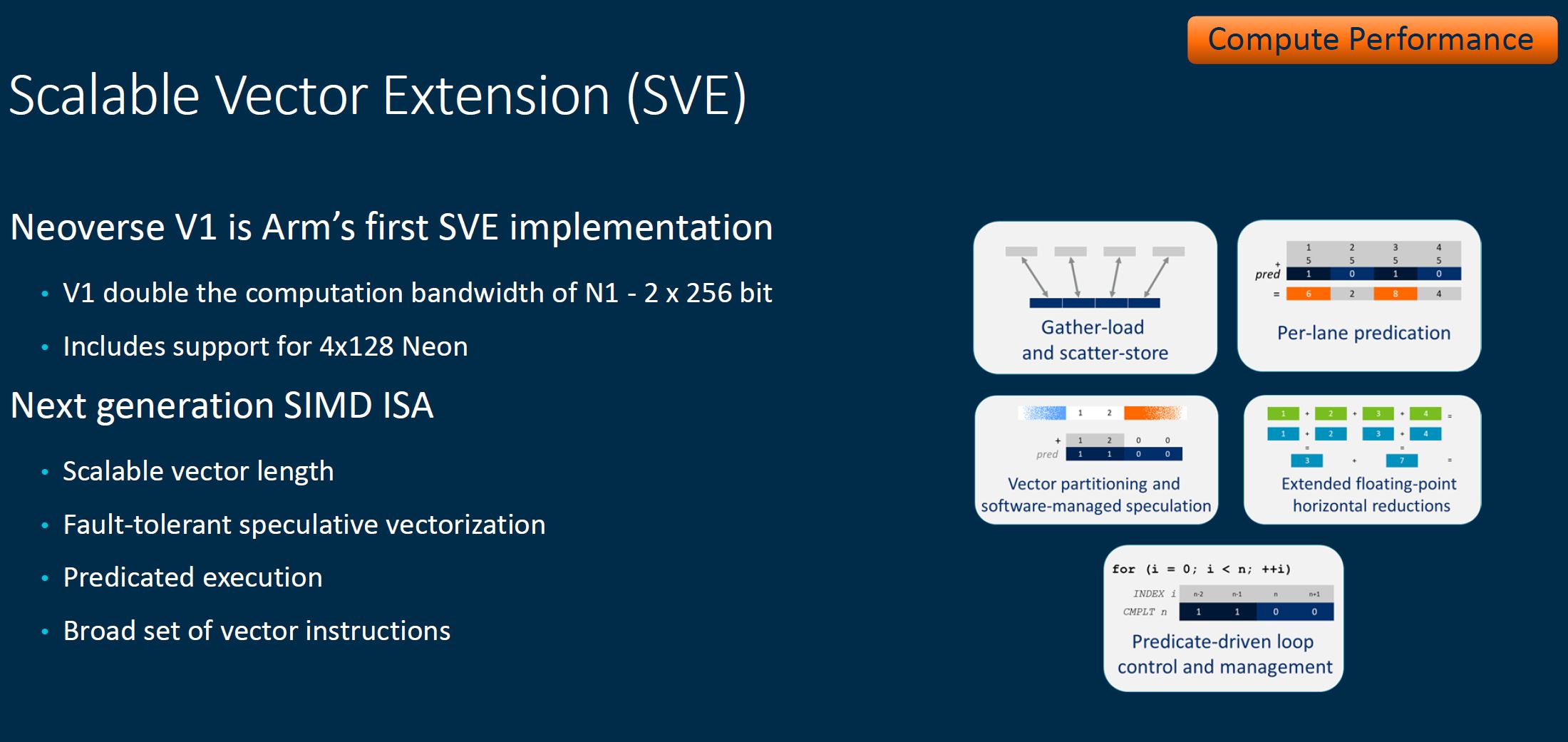
An advantage is that this in some respects is easier to implement and deploy across a range of processors. While Arm is focusing on V1 here, thinking more broadly, as SVE makes its way into DPUs and edge devices, potentially with different capabilities and needs, this model that helps scale from HPC cluster to the edge makes sense given Arm’s value proposition.

Along those lines of being scalable, that also means we can have a solution that can scale larger in the future as much as it can scale down to lower-power chips.

As one would expect, a solution designed to accelerate vector performance with hardware indeed accelerates vector performance.
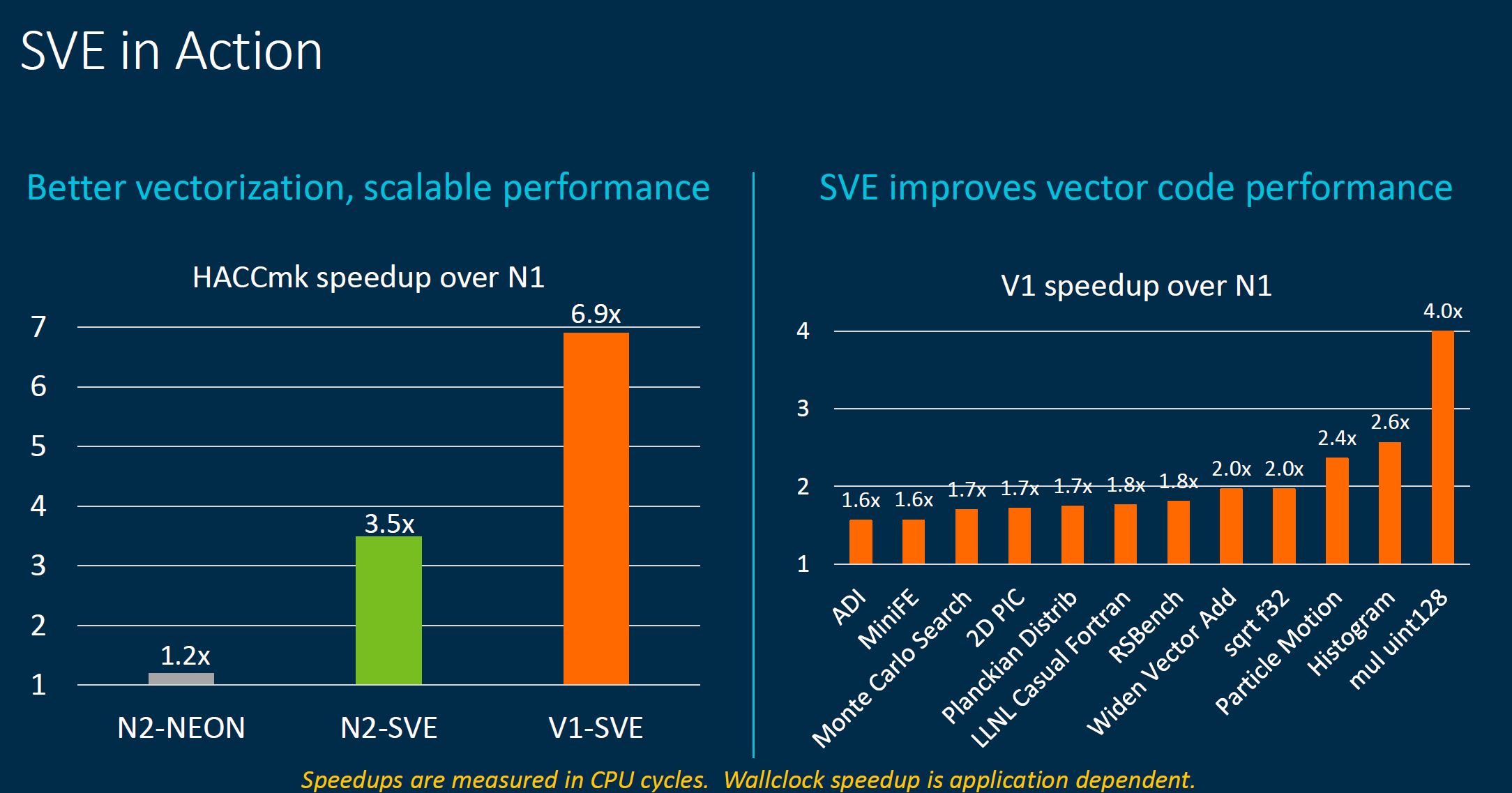
The big takeaway is that one gets a fairly massive speedup over the older NEON technology using SVE.
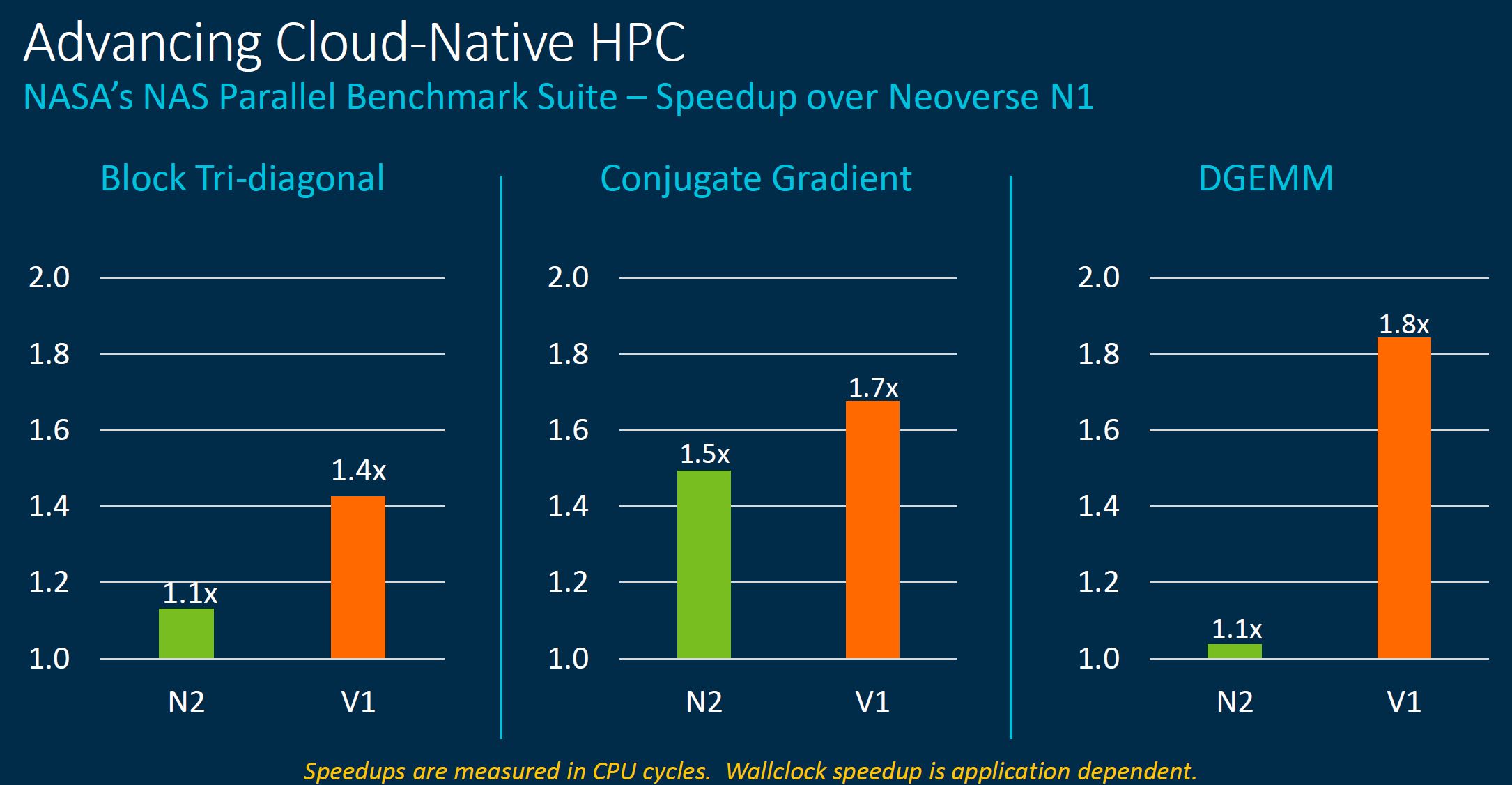
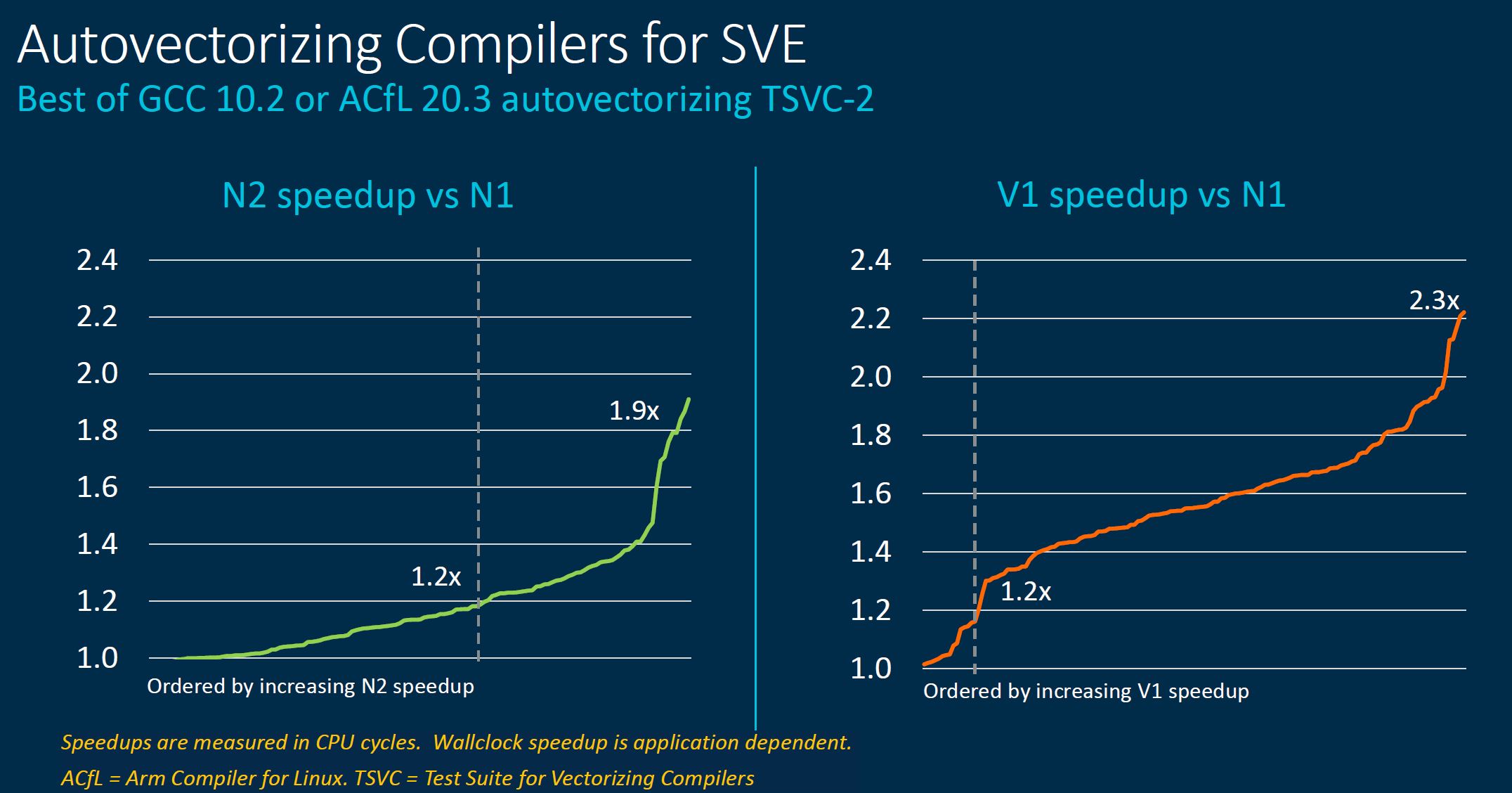
Autovectorization helps take advantage of this new hardware.
If it is not abundantly clear by now, the Neoverse V1 is designed largely for HPC style workloads. Arm likes to tout Supercomputer Fugaku by Fujitsu and RIKEN is No. 1 on the Top500 list using Arm-based processors.
Some question where HPC compute will happen, but the industry is set that HPC will continue so Arm going after this market, especially with a marquee proof-point makes sense.
Next, we are going to get to the Arm Neoverse N2 before covering the new CMN-700.


{kind=link}
It looks like a 64 core Epyc Milan offers over 2 TFLOPs (Source: https://www.microway.com/knowledge-center-articles/detailed-specifications-of-the-amd-epyc-milan-cpus/) per CPU and costs less than the 3.072 TFLOPs offered by the dual CPU PrimeHPC FX700 costing U$40K (Source: https://www.fujitsu.com/global/products/computing/servers/supercomputer/specifications/).
Excellent for ARM CPUs to hold the top Supercomputer spot, but cost / power / physical space / etc. all come into play – (highly capable) monkeys on typewriters.
If I wanted to pay almost 2x I could go with IBM’S POWER instead of AMD’s Milan.
Hurray for ARM, but I am skeptical about their ‘win’ (and I’m not talking about their placement in the TOP 500 spot, which I don’t dispute). Based on the FX700’s pricing and the software (even hardware) infrastructure I would choose the competition.
But, competition is great (for the customer); whichever team you prefer.
Comments are closed.