Arm CMN-700
Intel is describing its vision as the “xPU” era and “tiles” of IP blocks being integrated. Heterogeneous computing is coming in a major way. Arm has a great position to take advantage of this megatrend in the industry and that is why the Arm CMN-700 is so important. This coherent mesh interconnect is how Arm plans to tie together the next generation of heterogeneous computing.

For context, Arm showed this slide a few times depicting a cloud-to-edge vision. What is on this slide focuses on Arm’s IP. What is not well defined on this slide is how Arm’s cores can be combined with accelerators.
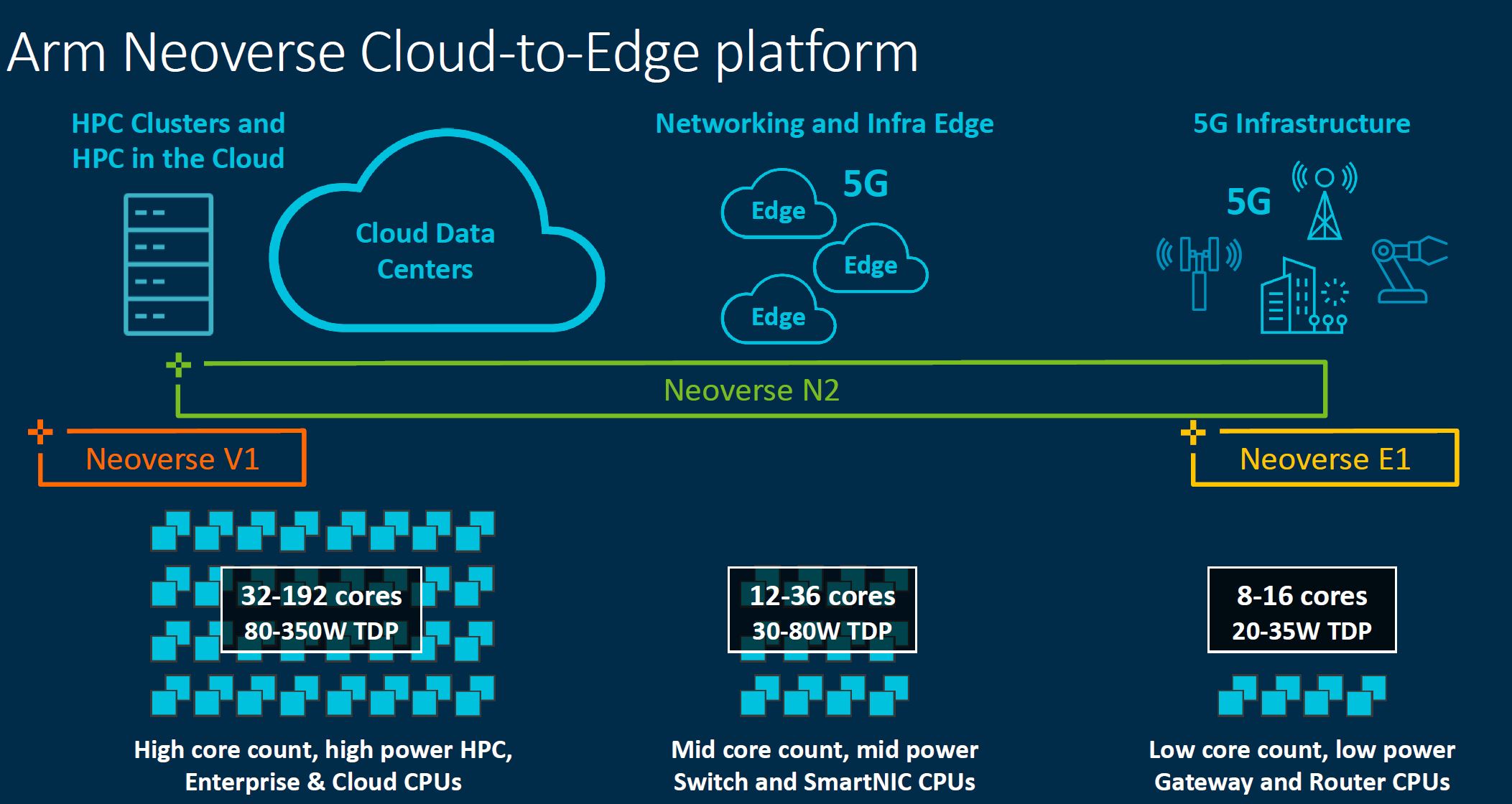
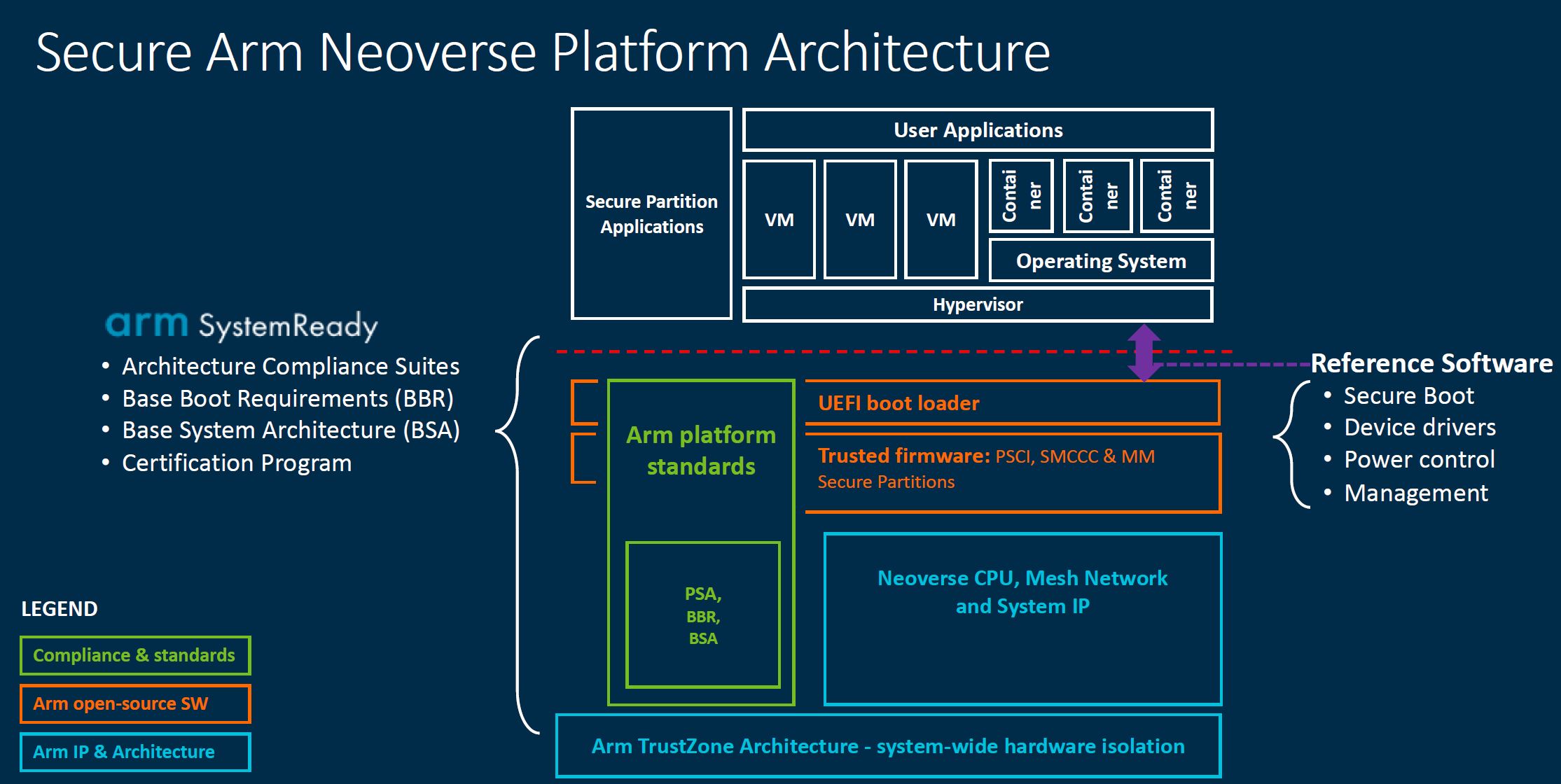
One domain that Arm hopes to focus on is being the security provider for systems. That means having a strong platform with standards. Indeed, AMD EPYC CPUs have a secure enclave onboard powered by a small Arm core. Arm has been positioning for this role for many years. It is important since if Arm becomes the standard for security processors, the other accelerators will gravitate toward building around Arm’s IP.
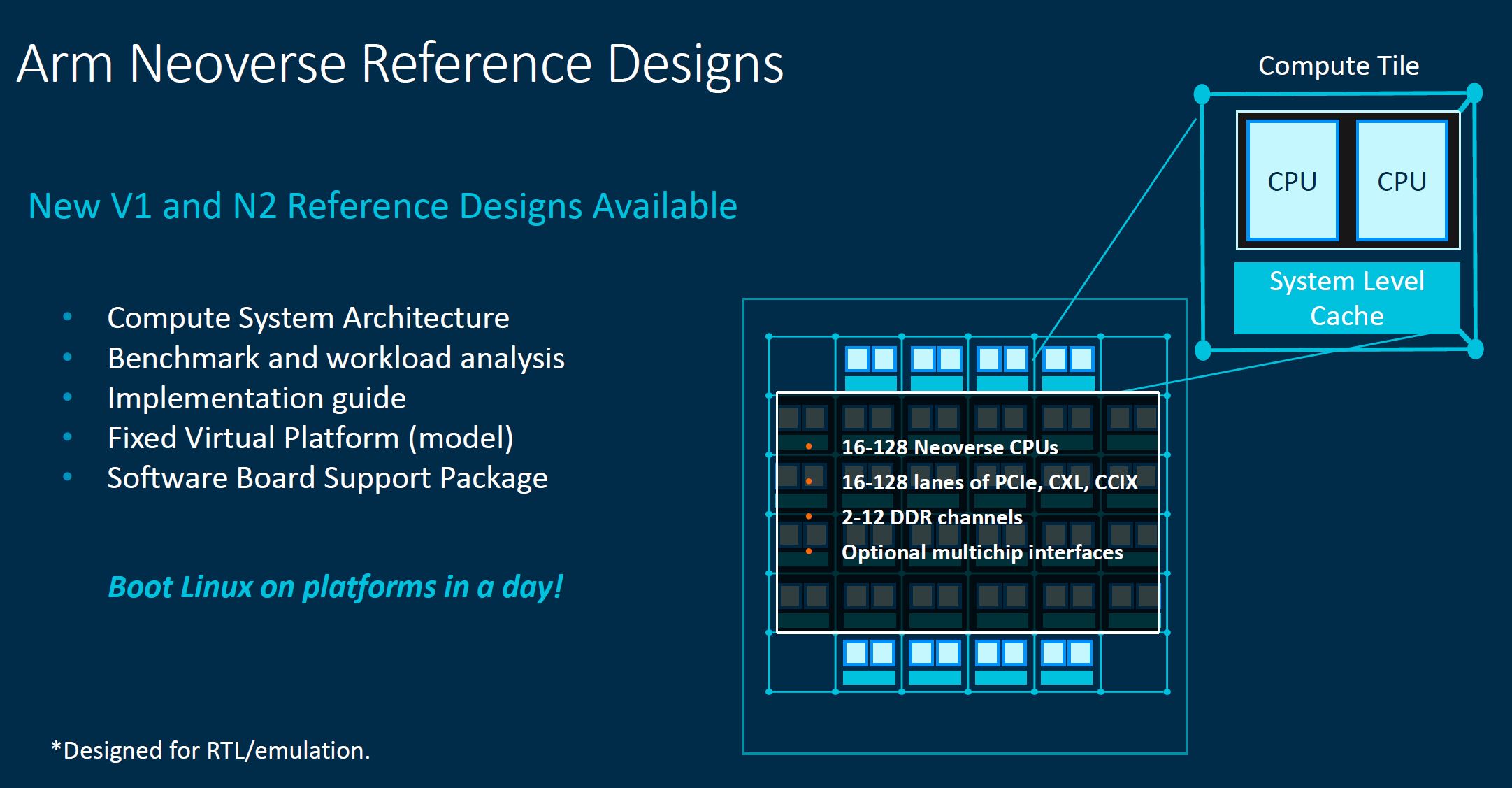
Arm has reference platforms that we discussed earlier. The goal of these platforms is to scale up and down to meet the needs of various markets. Something that is conspicuous in these slides is that we have effectively witnessed the end of <8 core CPUs. AMD did not launch low core count EPYC 7003 parts. Intel did not launch low core count Ice Lake Xeons. Arm’s slides all start with 8-16 cores at a minimum. There is an industry theme at play here, and that is scaling to much larger SoCs.
Beyond scaling to more cores, Arm is also focused on becoming the heterogeneous SoC leader. To be clear here, Intel and AMD are also in heterogeneous compute mode as well. Still, Arm needs to define for its customers a standard way to interface between Arm’s cores and other IPs with a broader system. That is where the CMN-700 comes in.
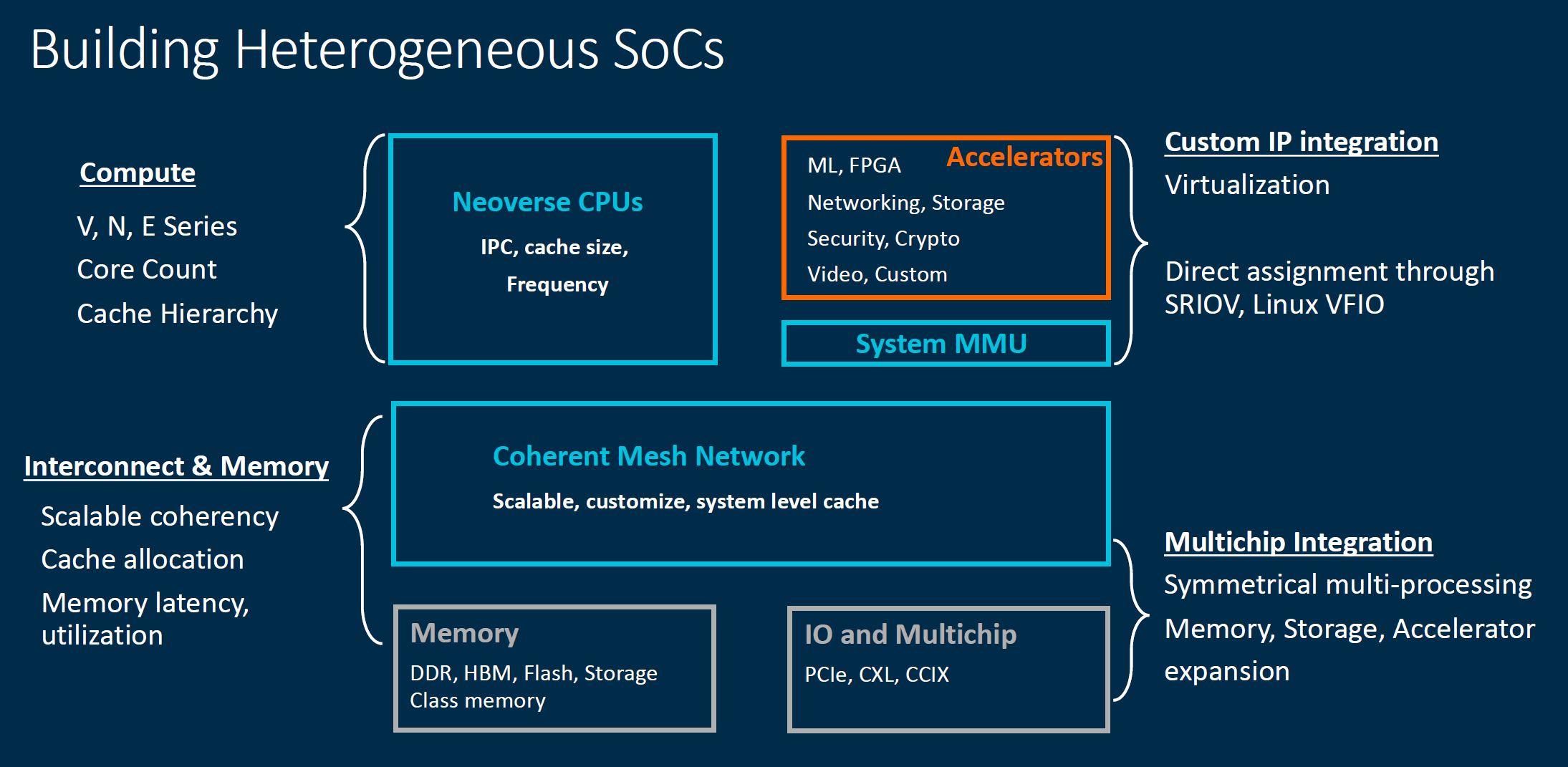
We almost did not use this slide, but it does show some of the key trends we have been discussing on STH.
The CMN-700 is designed to offer bigger SoCs. One can see that the solution is designed for more cores, more cache, and more devices being attached. We asked Arm and the majority of designs are not focused on being 256 core/ 512MB designs at this point, but the scalability is there.

The new CMN-700 has more bandwidth which means that SoC designers can build bigger and faster packages. This is designed for next-generation technologies such as HBM3, PCIe Gen5, and DDR5 that we will see more of in late 2021/ early 2022. With more bandwidth, more cores, and more devices, pressure is levied on the interconnect fabric.

Arm is looking at a future not just with the large DDR5 generational jump in performance, but also what happens when SoC designers want to use HBM3 for HPC SoCs. We discussed features on this slide such as CBusy earlier in this piece so we are not going to go over them again.
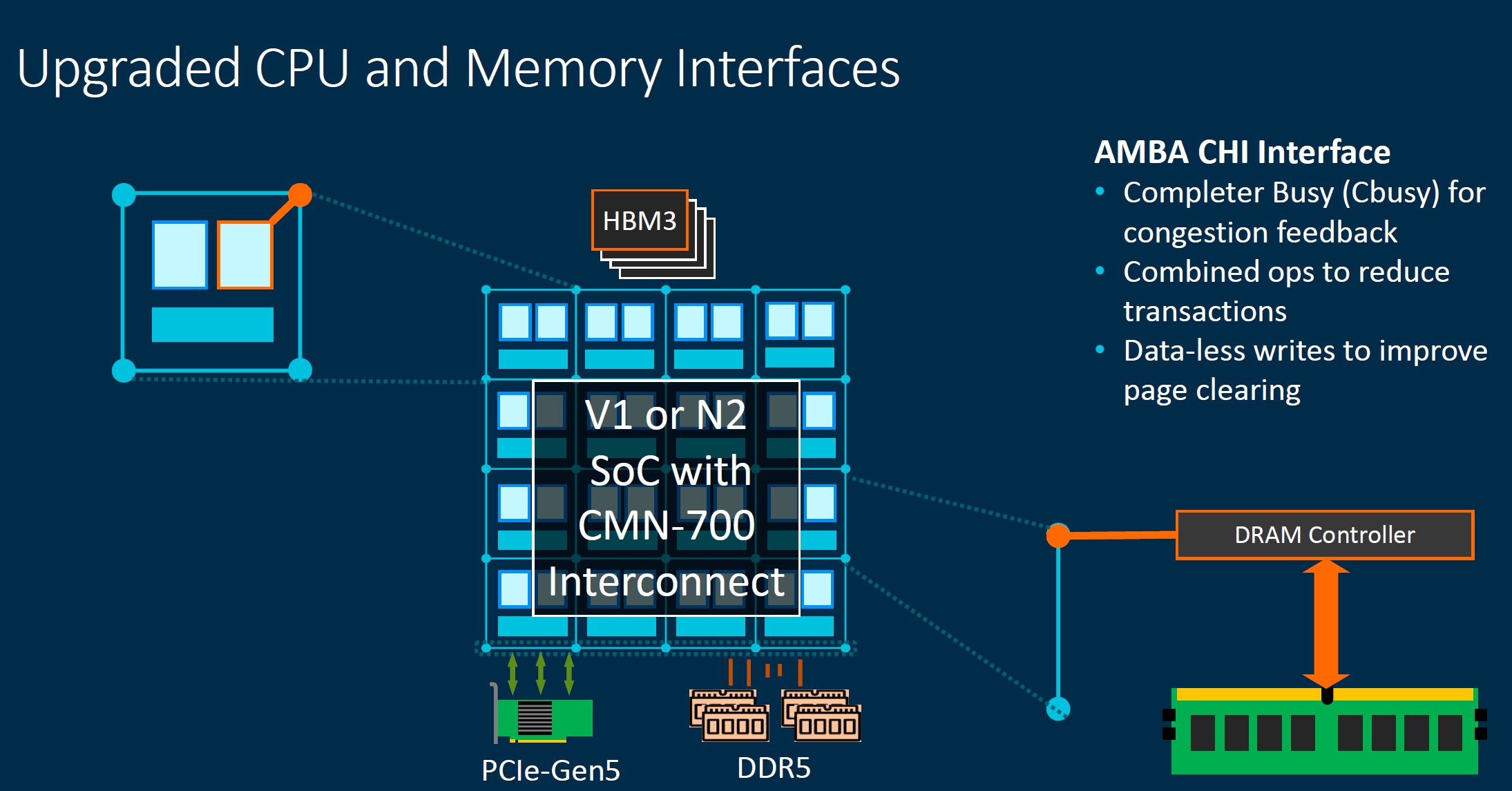
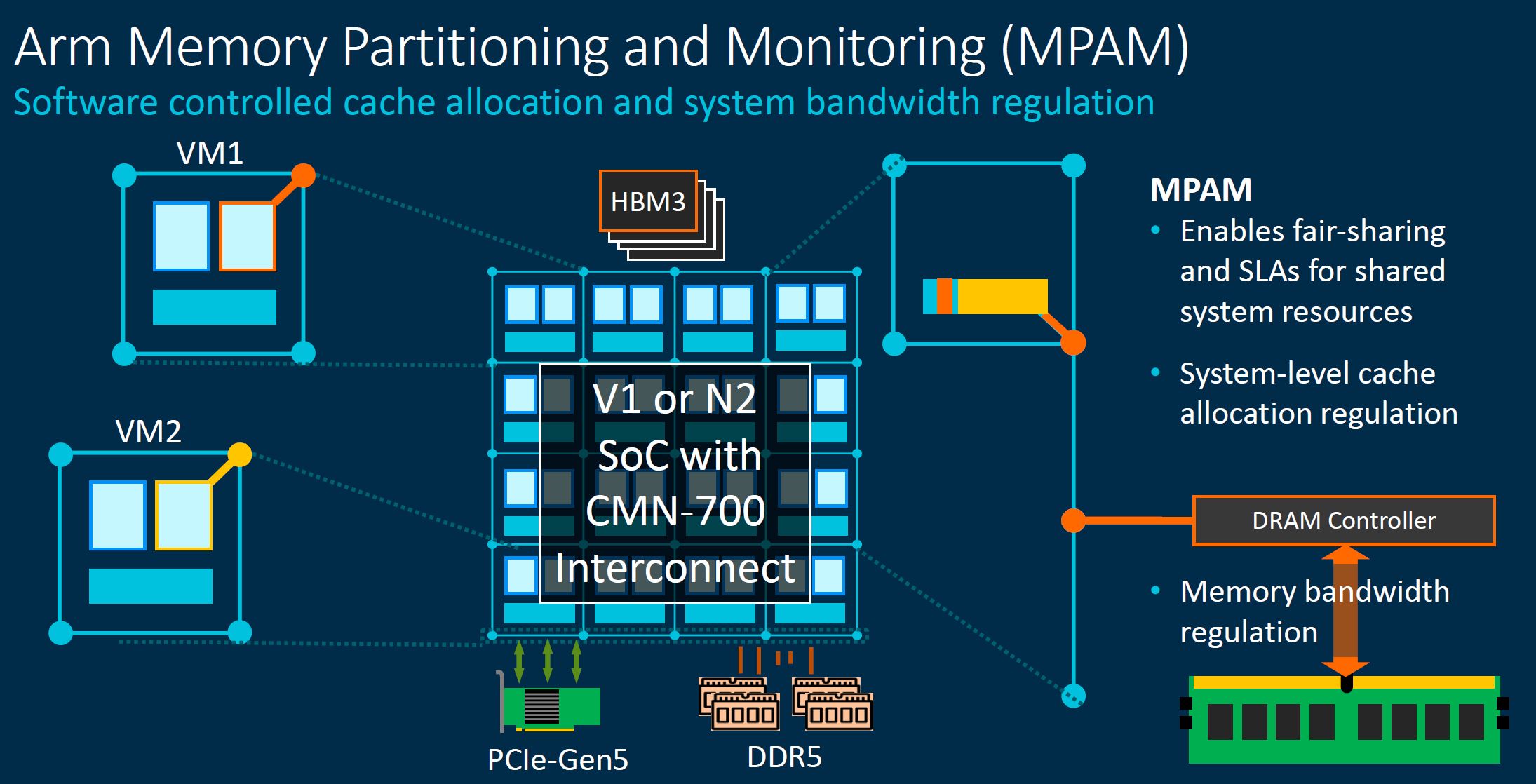
MPAM is important because in a larger system, congestion and contention can be a challenge. Arm is building tools to manage these challenges.
As PCIe Gen5 and CXL are introduced, we will see a key enabler for next-generation heterogeneous compute. We are also seeing a push for heterogeneous packaging on SoCs, all which Arm needs to help customers manage.
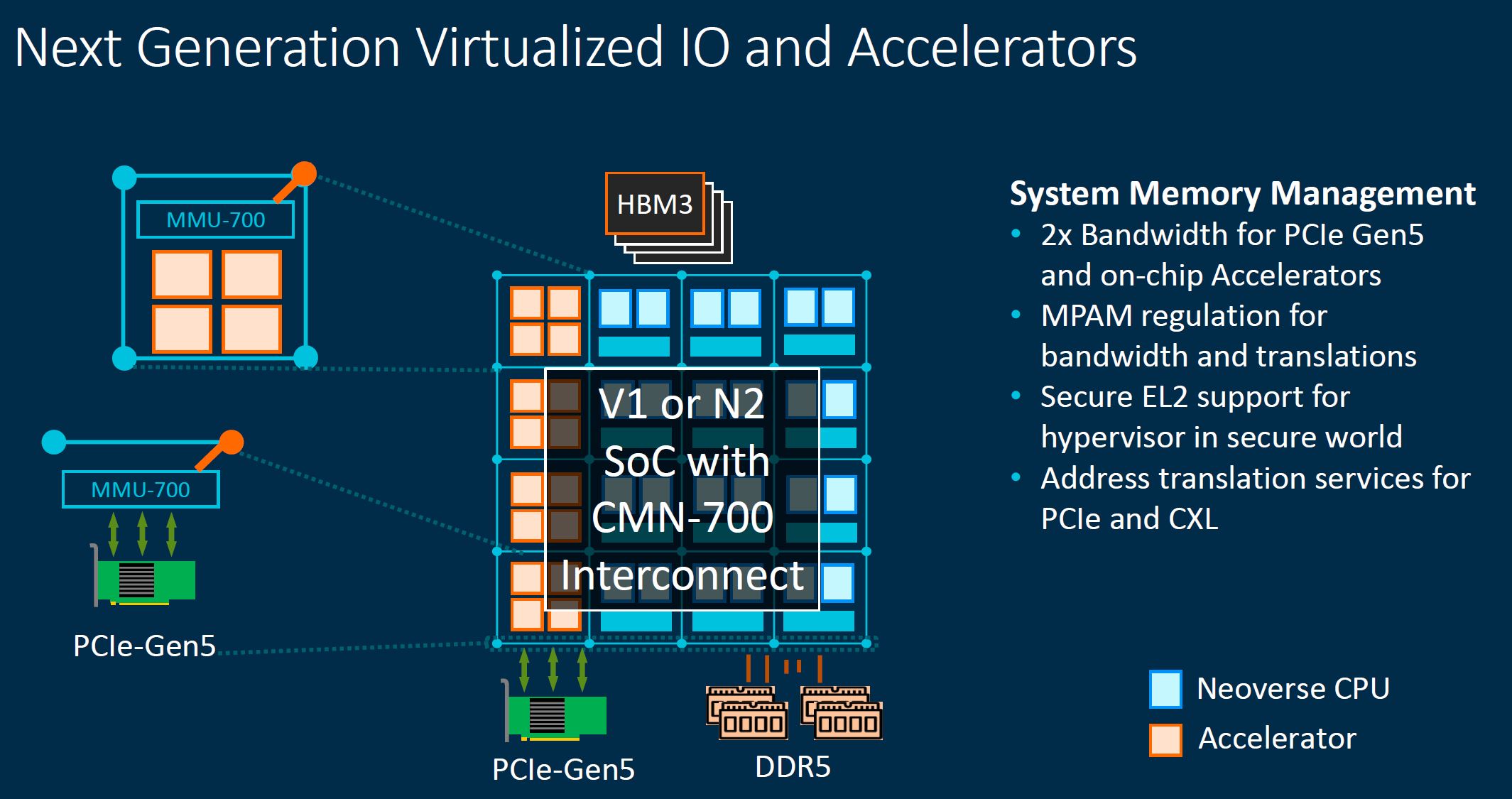
Arm is a proponent of CCIX, but the industry is also adopting CXL for part of what CCIX was originally intended for. Arm is rectifying this tension by using CCIX for on-package interconnect and multi-socket, while CXL is designed for memory expansion, pooling, and accelerators. The two use cases that Arm is showing for CXL are being driven by the broader industry.
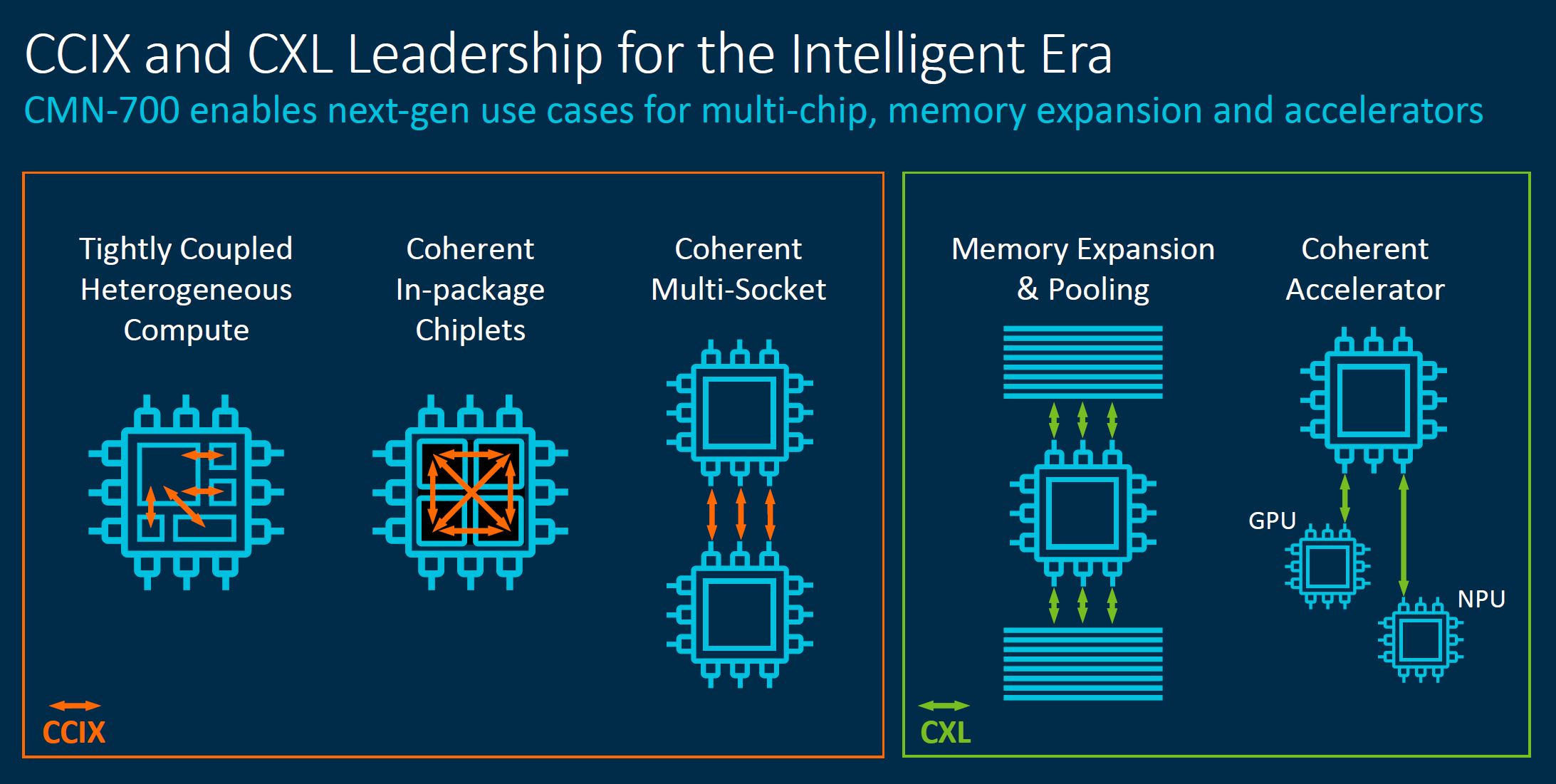
We are omitting a current state slide here, instead, we are showing the outcome. One of the big promises of CXL in early generations is being able to put pools of CXL memory into a system and then accessing those pools from CPUs or other accelerators like GPUs. In future CXL versions, we get switching and other features, but this is one of the often-cited early use cases.
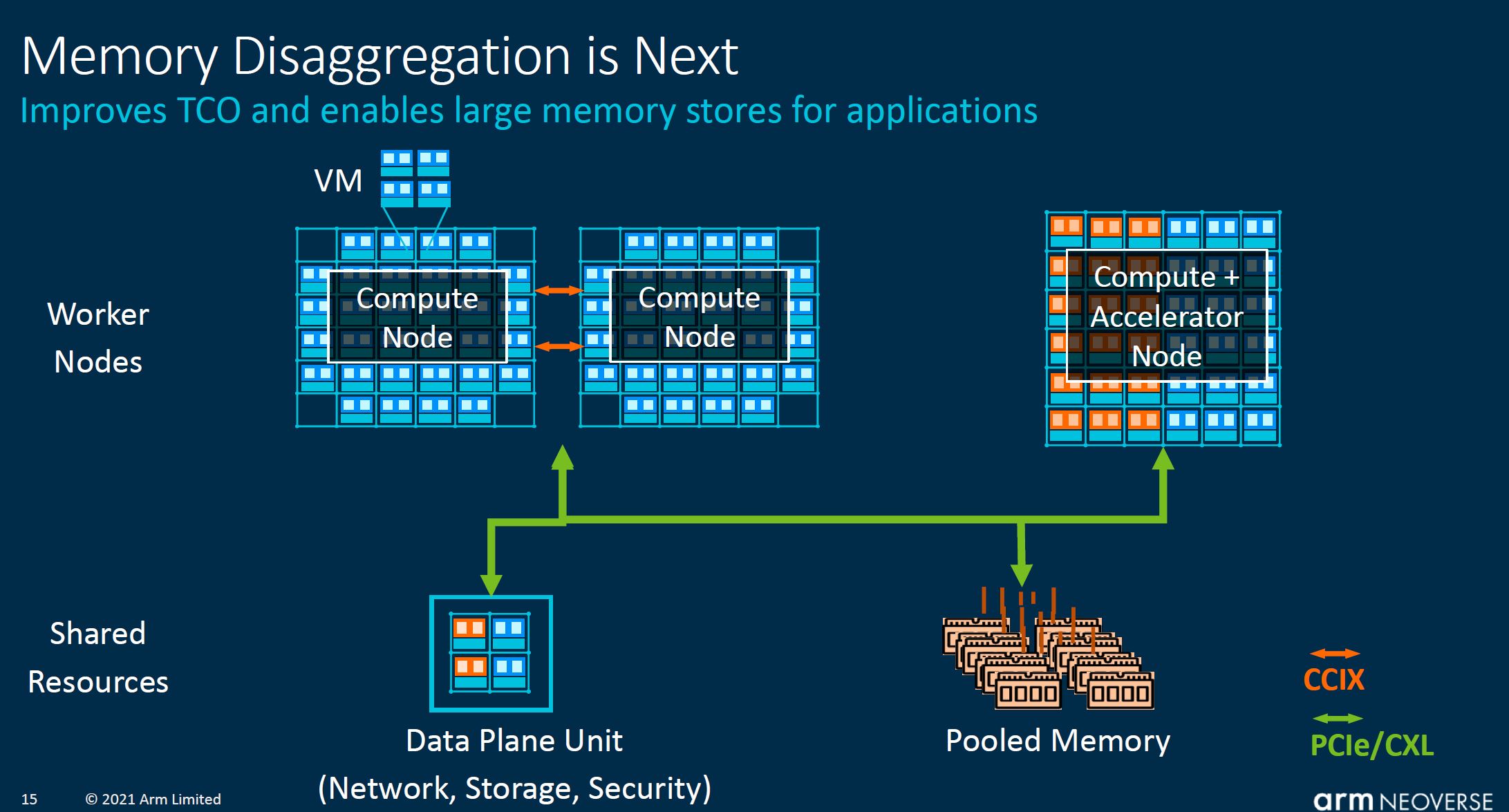
Effectively, Arm with CMN-700 is focusing on how to build multi-chip solutions that are designed for the reality that there will be many chips in a system, potentially with many sources for memory.
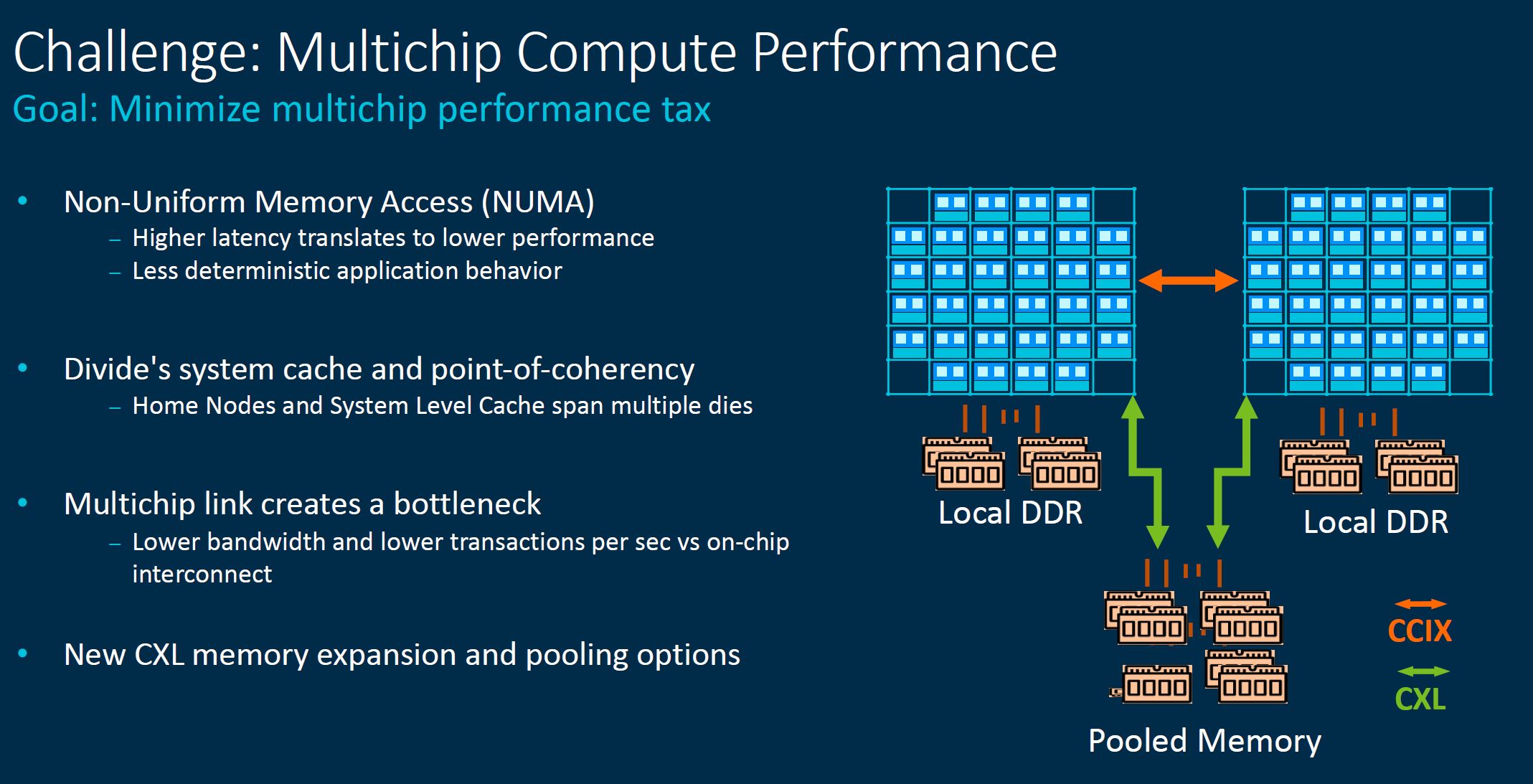
As a result, CMN-700 has a multi-protocol gateway that can facilitate chip-to-chip, chip-to-accelerator, and chip-to-memory connectivity along with an optimized CCIX 2.0 gateway for chip-to-chip or die-to-die connectivity.
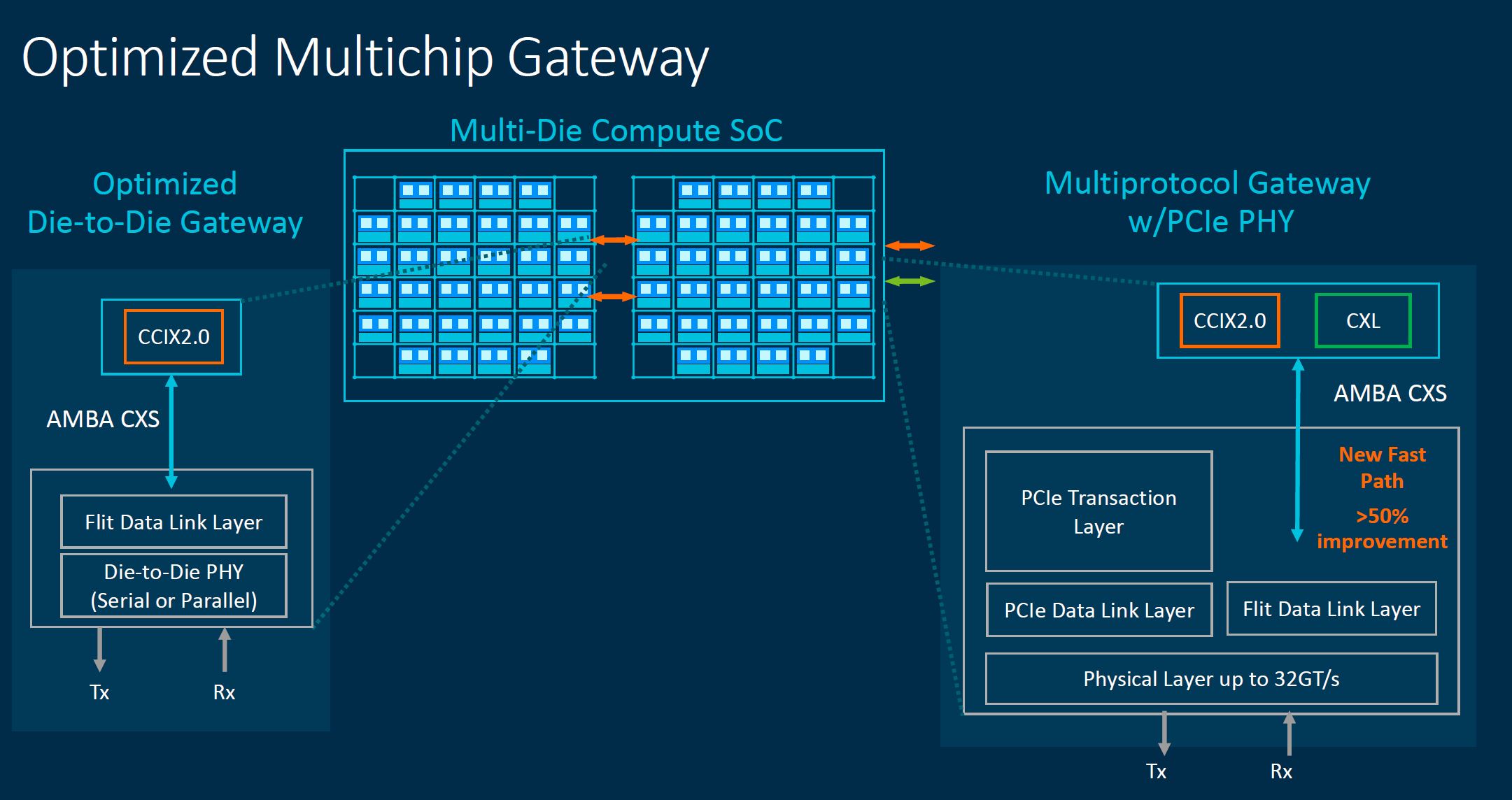
The Super Home Node helps enable the caching and allocations that need to happen in these larger and more complex systems.
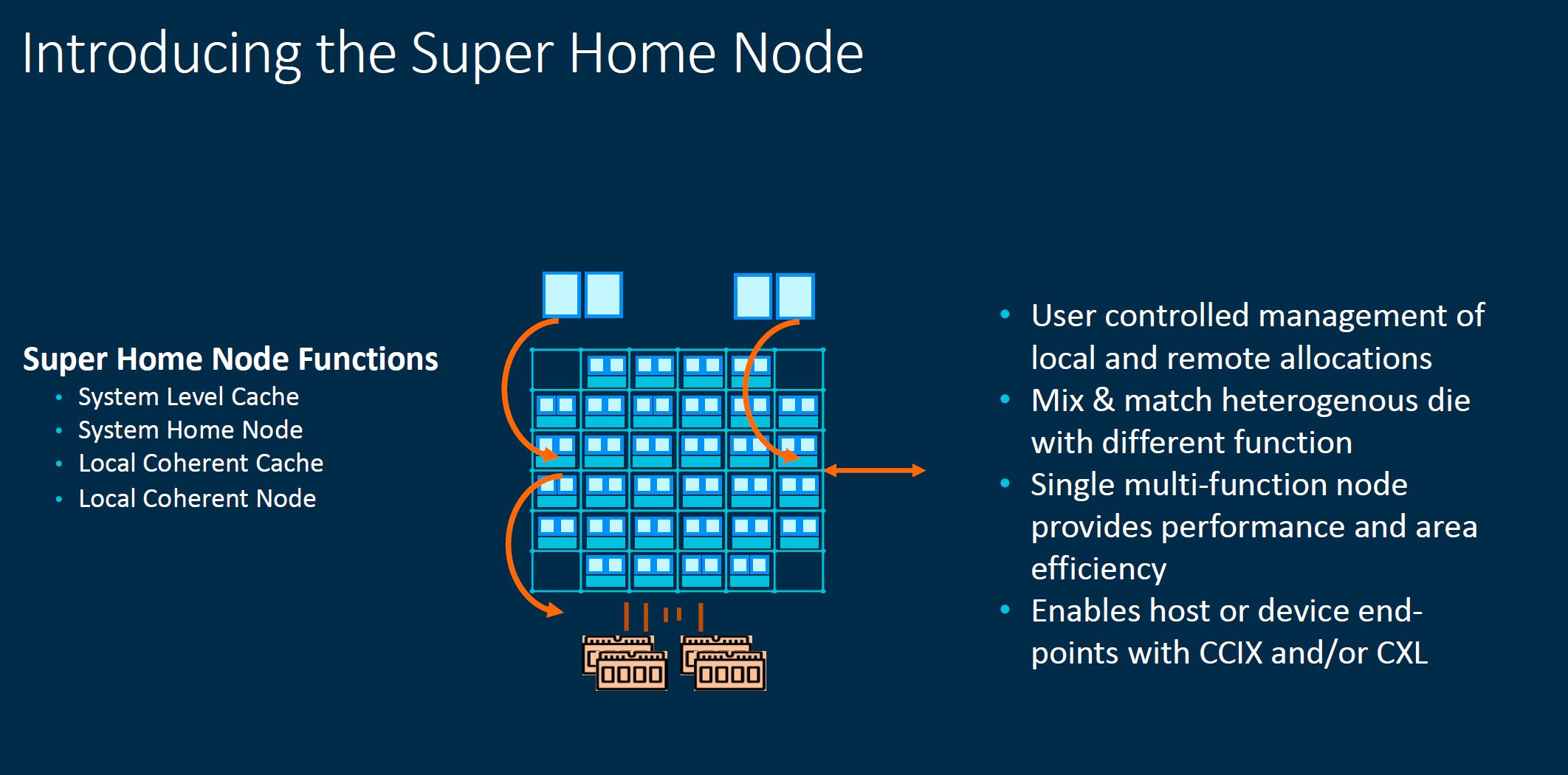
Perhaps my favorite slide of the Arm Tech Day 2021 was this one. CMN-700 will enable a die-to-die or hub-and-spoke heterogeneous designs.
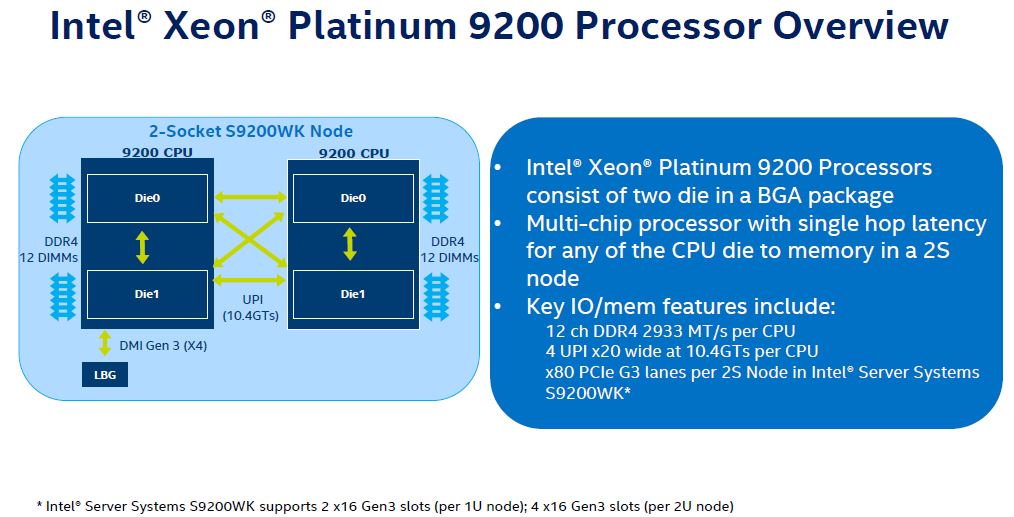
Although Intel said that “glue” was not the right answer years ago, just before releasing a die-to-die design with the less than extremely popular Platinum 9200 series, it seems like Intel’s new directions more glue and more heterogeneous compute.
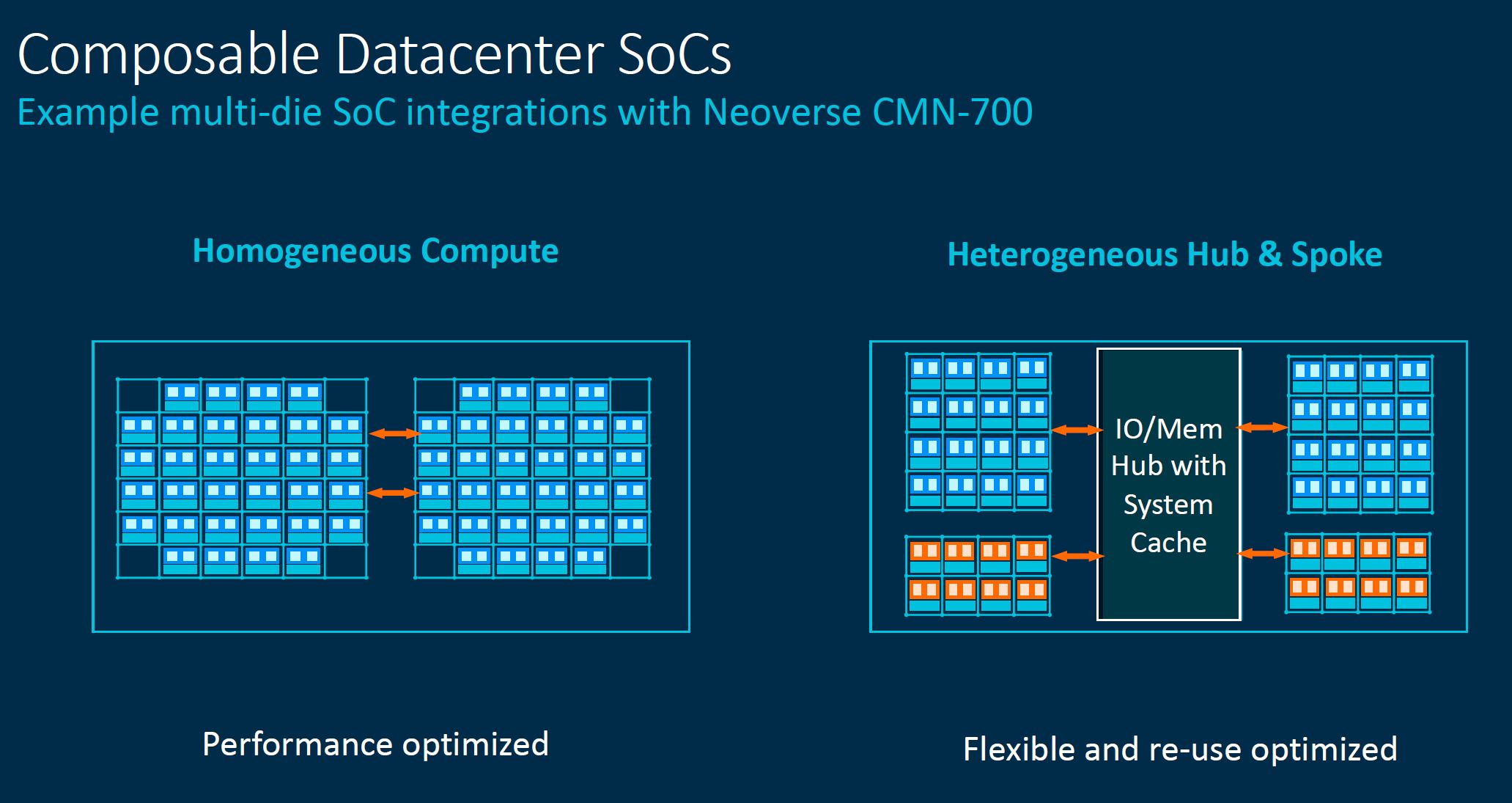
On the hub and spoke design, that is a very thinly veiled attempt to say Arm’s customers will be able to build SoCs like current AMD designs, and also with heterogeneous computing in mind.
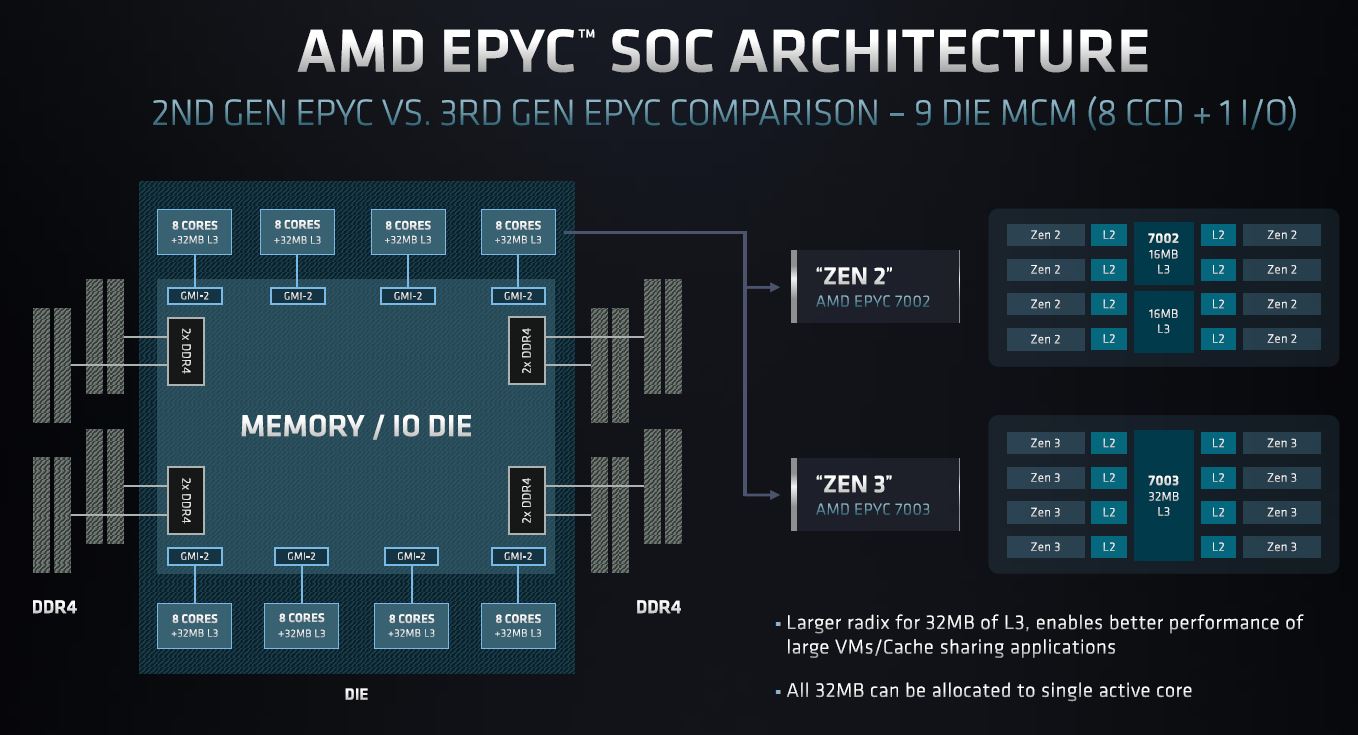
That one CMN-700 slide was so simple, yet said so much around what Arm is enabling for its customers.
With the CMN-700, Arm is making a clear signal though. It is showing that the company is serious about enabling the next generations of technologies and has a solution for heterogeneous computing. Cores are one aspect of Arm’s value proposition. In the future, having the ability to integrate CPU cores with other accelerators and memory is going to be one of the company’s biggest value drivers.
Final Words
That was absolutely a ton to go over. In hindsight, it should have been several pieces. At the same time, we tried to strike a balance between getting information at a high level and doing a bit more around the more technical pieces.
Perhaps the biggest takeaway is that the Arm ecosystem is moving. Arm will be a big ecosystem in the server space. The question is when and not if. If you look at a modern AMD EPYC server there are already likely several devices in the system with Arm cores already (Intel too.) On the other side, companies like Intel have realized that they enabled their customers such as Amazon to build competing solutions based on Arm by subsidizing the cloud players with SMB and enterprise margins. At some point, companies like Intel will start to move and evolve to become more competitive based on these threats from Arm.


{kind=link}
It looks like a 64 core Epyc Milan offers over 2 TFLOPs (Source: https://www.microway.com/knowledge-center-articles/detailed-specifications-of-the-amd-epyc-milan-cpus/) per CPU and costs less than the 3.072 TFLOPs offered by the dual CPU PrimeHPC FX700 costing U$40K (Source: https://www.fujitsu.com/global/products/computing/servers/supercomputer/specifications/).
Excellent for ARM CPUs to hold the top Supercomputer spot, but cost / power / physical space / etc. all come into play – (highly capable) monkeys on typewriters.
If I wanted to pay almost 2x I could go with IBM’S POWER instead of AMD’s Milan.
Hurray for ARM, but I am skeptical about their ‘win’ (and I’m not talking about their placement in the TOP 500 spot, which I don’t dispute). Based on the FX700’s pricing and the software (even hardware) infrastructure I would choose the competition.
But, competition is great (for the customer); whichever team you prefer.
Comments are closed.