
In a big win for Arm computing, the Chinese LineShine supercomputer has taken over the #1 spot on the most recent Top500 supercomputer list. The new entrant from China’s National Supercomputing Centre in Shenzhen (NSCS), and the first non-Lenovo Chinese system submitted for quite some time, is the first to publicly surpass 2 ExaFLOPS on Linpack. At just under 2.2EF measured, it is roughly 22% faster than El Capitan, which we toured about a year and a half ago before it started its classified mission. See They Let Me Bring a Camera Into a Top Classified US Supercomputer El Capitan for that.
LX2 Compute CPU
Immediately, the most notable aspect of the LineShine system (besides its overall performance) is the hardware it is comprised of. Whereas the previous #1 El Capitan and Frontier systems have both been based around GPUs (or rather GPUs driven by CPUs), LineShine is purely a CPU system – there are no GPUs to be found here.
The fundamental building block of LineShine is the LX2 CPU. Thought to be designed by Huawei, the LX2 CPU comprises two compute dies and has onboard HBM. Each die has 152 Armv9-architecture CPU cores with both SVE and SME – so even without GPUs, the system is still making heavy use of vector and matrix accelerator blocks. Here is the architectural diagram that we found in a paper:
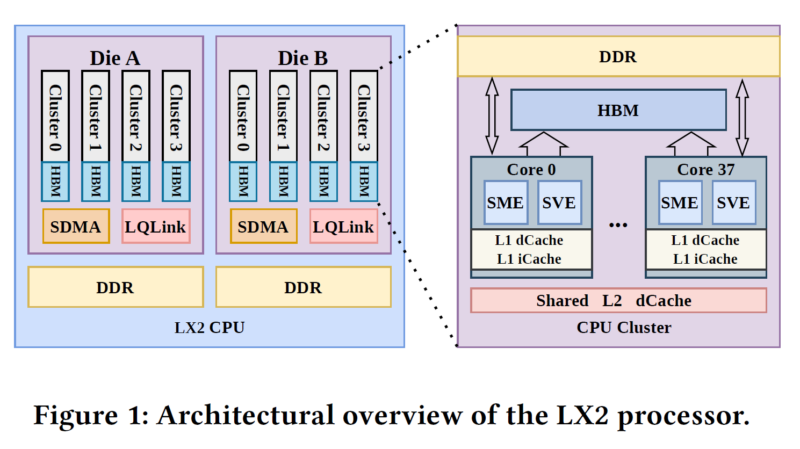
A single LX2 die is further broken up into four NUMA domains of 38 cores each, each with its own 4GB of HBM and 32GB of DDR5. From the papers we have read, this can be configured as either a flat topology with capacity equal to HBM plus DDR, or as a cache topology with HBM caching for DDR. With eight NUMA domains in total across the entire chip, there are 304 cores and 32GB of HBM on each CPU, which is further fed by 256GB of DDR5. This is not an official diagram. I just noted what I could find and put some blocks in PowerPoint to make some sort of visual for folks.
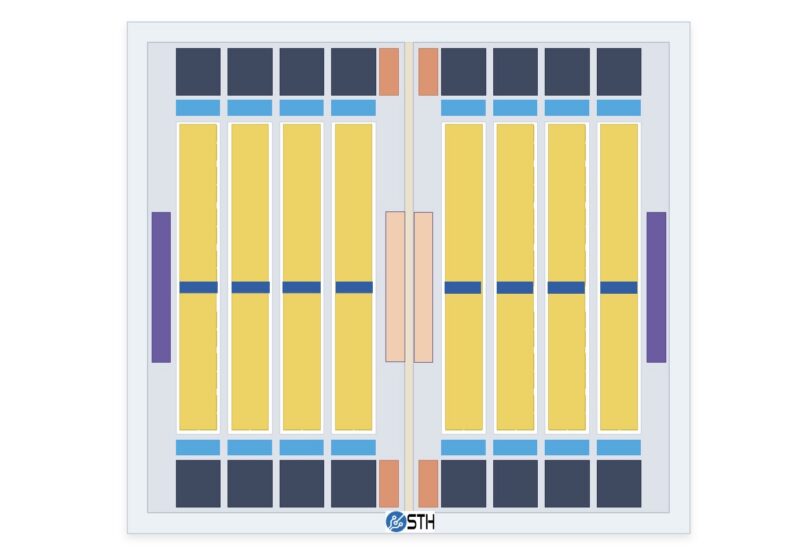
With NSCS aiming for GPU-like performance with the LX2, the chip also has GPU-like power consumption. According to a presentation made earlier this year at the International Forum for HPC & AI Co-driven Innovation (HACI), each LX2 processor consumes 690 Watts of power.
800Gbps NICs are integrated on chip as well, which is something that we have not really seen much of since the Intel Xeon with OmniPath days, but this seems to be another level of integration.
Building a LineShine Supercomputer
Taking the building blocks of the 304 core CPUs, two CPUs are placed in a node. There are eight nodes in a blade (sixteen CPUs), similar to how we saw 8 CPUs in 81920 Cores Per Rack with AMD EPYC Venice at HPE Discover 2026. Sixteen blades go into a compute frame (256 CPUs). Two compute frames go into a cabinet (512 CPUs). Then there are said to be roughly 89-90 compute cabinets. Assuming that math is correct, then that is around 13.79M cores with each cabinet over 155K cores.
There is also the LingQi 1.6Tbps network going to each node. This has been described as a 4-layer fat-tree topology that has one optical layer.
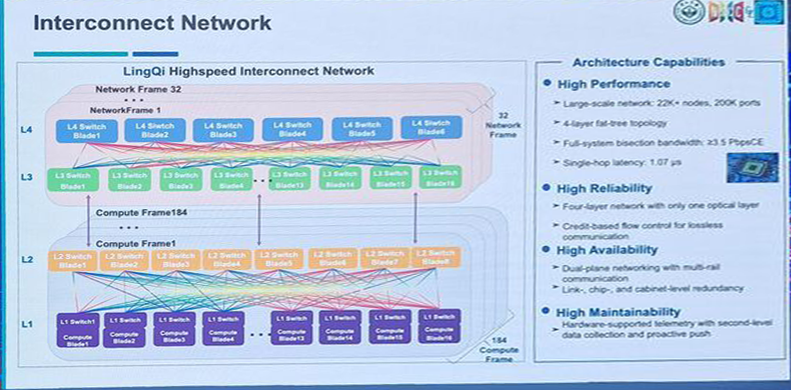
The full system was measured as delivering 2.2 EFLOPs of performance under Linpack, versus a theoretical max of 2.74 EFLOPs. At 80% of its peak performance, this notably puts the all-CPU system ahead of all of its closest GPU competitors in that regard, as all three of the US exascale computers are in the 50% to 65% range for sustained performance.
Still, the entire system is reported to be very power-hungry. The official Top500 submission for LineShine has it listed as consuming 42MW of power, for about 52 GFLOPs/watt. This is a bit below other exascale systems (e.g. El Capitan at 60 GFLOPs/watt), tracking what we would expect from the lower compute density of a CPU versus a GPU. Fittingly, the system is also liquid-cooled to keep up with the cooling needs of such a high TDP system.
Top500 Top10 Shake-Up
A few other items we wanted to note. With the addition of a new exascale computer to the TOP500 list, to get into the top 5 you now need over 1 ExaFLOPS of performance. Germany’s JUPITER Booster, which is Europe’s sole exascale computer, now holds the #5 spot at just over the 1EF mark.
The addition of LineShine to the list also means that, for the first time in 4 years, an AMD-powered supercomputer is no longer at the top. In the last few editions of the list, the MI300A-powered El Capitan was the top system, and before that, the list was topped by the world’s first exascale system, the EPYC and MI250X-based Frontier. Those AMD-based computers now hold the #2 and #3 spots, respectively.

Speaking of AMD systems, a new AMD system has also taken the #6 spot on the list. The Italian Eni S.p.A. HPC7 is an AMD MI300A-based system that offers 571 PFLOPs of performance. The system is effectively a smaller version of El Capitan, using the same HPE Cray EX255a racks as the US’s top supercomputer, but on a smaller scale and with considerably lower power requirements to match (8.7MW).
Altogether, AMD is now responsible for providing the chips behind 4 of the top 10 computers in the list. NVIDIA has three Hopper-architecture systems on the list at #5, #7, and #10. Aurora (now at #4) remains the sole Intel GPU-powered system on the list, though the company’s CPUs are also backing the GPU-based Eagle system at #7.
Finally, LineShine is joining the world’s previous fastest CPU-only supercomputer, Fugaku, which is still on the list. The Armv8-based system from Fujitsu now holds the #9 spot after the most recent system additions.
Final Words
This week, I am attending Qualcomm’s Investor Day instead of ISC in Hamburg. Part of that was because Intel, AMD, and NVIDIA told me they were not doing anything big for ISC. I also saw a well-known HPC industry analyst at HPE Discover 2026 last week, and he told me that he thought the EuroHPC initiative was going to be the big ISC focus.
With all of this said, it is probably worth remembering that there are some enormous systems out there that are not being benchmarked for Linpack and the Top500. What is also happening, however, is that the AI hardware is starting to shed FP64 support to further improve mixed-precision performance.



{kind=link}