
The new AMD Xilinx VCK5000 is an accelerator specifically designed for AI development. For those who have not seen, we are going to be using AMD-Xilinx for some time post-acquisition. The card itself is designed to offer AI acceleration via Xilinx’s accelerators and programmable logic.
AMD Xilinx VCK5000 AI Accelerator Launched
In terms of the overview, this is a 7nm Versal ACAP. As part of the ACAP, we not only get traditional programmable logic, but we also get AI accelerators. Xilinx says its new solution is designed to hit up to 125 INT8 TOPS. INT8 is very popular and is something we specifically looked at in the AWS EC2 m6 Instances Why Acceleration Matters piece.

Beyond just the AI accelerators and programmable logic, Xilinx’s value proposition goes a step further. Xilinx can use the local FPGA memory and programmable logic to do multiple actions. For video, this may mean ingesting and decoding a 4K video stream, doing coarse object detection (determining which objects warrant further classification), then doing other data transformation and inference tasks.
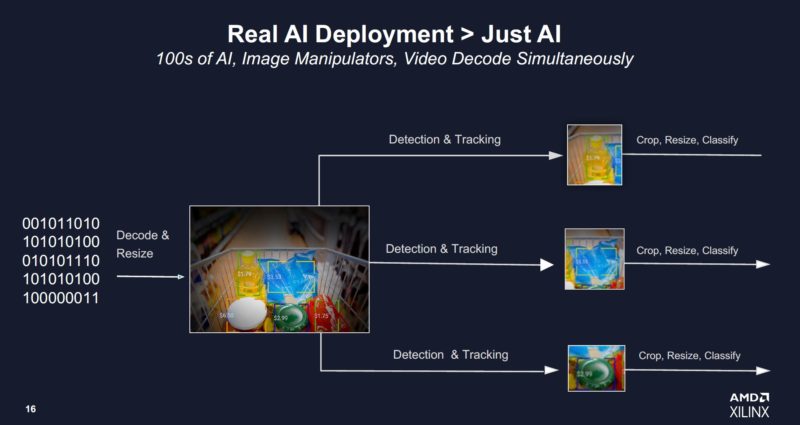
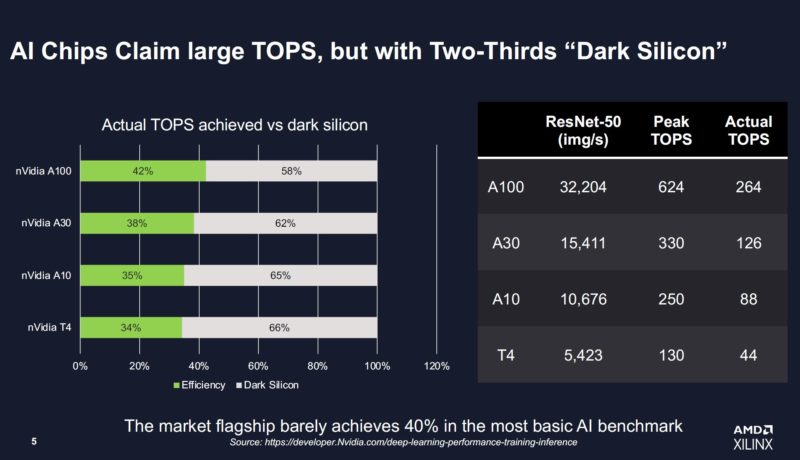
Since Xilinx can do all of that on its FPGA, it is able to claim a higher utilization. It is using the term “Dark Silicon” but the other way to think about it is claimed TOPS versus achieved TOPS. Xilinx took NVIDIA’s published numbers and performance claims and says that while theoretical TOPS may sound great, the cards are actually achieving less than half of that theoretical limit.
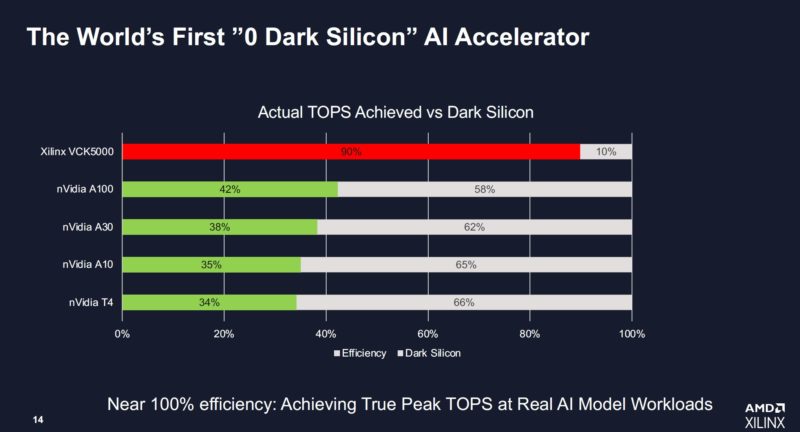
AMD Xilinx claims that the new VCK5000 can hit up to 90% of its theoretical TOPS. Further, it thinks that there is room to get that percentage even higher.
This is one that it worth it to view critically. For example, many would use the A100 PCIe for inference at lower power and the SRP versus street pricing is always different. The VCK5000 is in lower power and performance mode here since it can scale to 225W.
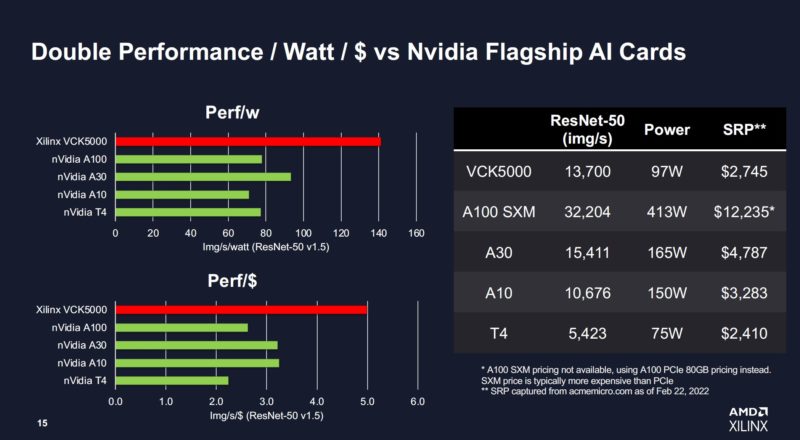
Still, this is a key development in showing Xilinx’s story in the AI space, and a big value that we expect AMD to drive further.
Final Words
Xilinx also has its Vitis frameworks and other development tools so that it can be plugged into Tensorflow, Pytorch, and other frameworks. There are also companies like Aupera building video analytics frameworks to help with some of the tasks like ingesting and processing the video, getting it ready for the inferencing pipeline.
These should be available on the Xilinx website for $2,745, however, we suspect Xilinx will have some sort of developer program around them as well.



{kind=link}
One of the amazing things about AMDs current GPU offerings (other than the hardware itself) is the fully open-source ROCm stack. My suspicion is that being able to customize the open source was an important feature for the recent national exascale supercomputer contracts.
To what extent is the Xilinx software open source? Are there plans to follow the same open-source model as with the AMD GPUs?
Is ROCm currently focused only on GPUs? I recall that Xilinx developed a triSYCL project, and someone was attempting to make it work as a dpc++ backend. Would AMD duplicate all that effort to make it work with ROCm, or just move to oneAPI/dpc++?
Comments are closed.